大模型微调系列教程(二)——微调技术与开源微调工具推荐
开源微调工具的涌现极大地推动了LLM定制化的普及和发展。降低了技术门槛,使得更广泛的用户和组织能够根据自身需求调整和优化强大的预训练模型,从而催生了大量的创新应用 。
-
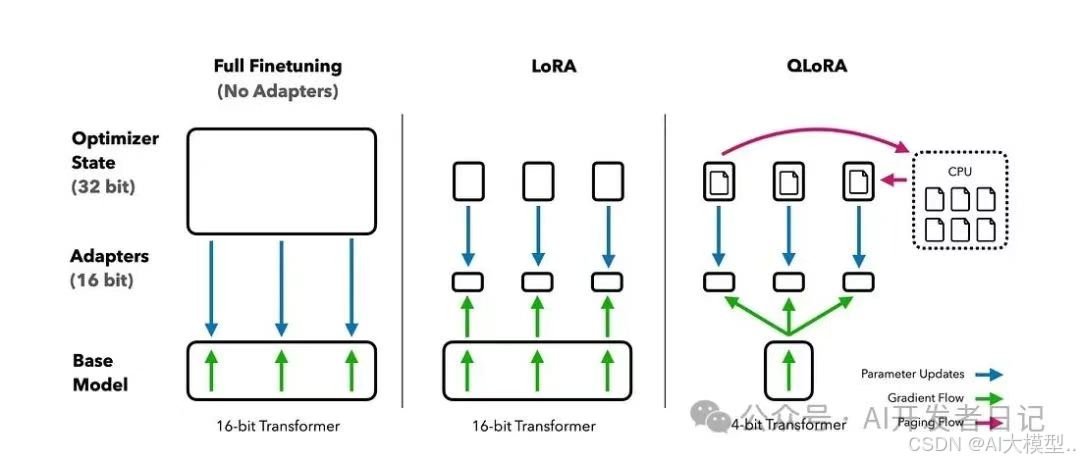
1. 起点:全参数微调 (Full Fine-Tuning)
- 做法: 对预训练模型的所有参数进行重新训练,以适应新任务。
- 关键: 早期LLM的主要适配方法,能充分利用模型潜力。
- 瓶颈: 随着模型参数量剧增,计算和存储成本变得难以承受。
-
2. 转折点:参数高效微调 (PEFT) 的兴起
- 早期尝试: Freeze部分层、Adapter Tuning (在层间插入小型可训练模块)。
- 输入端创新: Prompt Tuning、Prefix Tuning (学习添加到输入的“软提示”或“前缀”)。
- 重大突破与普及:LoRA (低秩适应) 及其变种 (如 QLoRA 结合量化技术)。LoRA通过训练低秩矩阵来近似权重更新,效果好且效率高,成为主流。
- 核心驱动: 解决全参数微调的成本问题。
- 核心思想: 冻结预训练模型绝大部分参数,仅微调一小部分参数或添加少量可训练模块。
-
3. 能力升级:指令遵循与人类对齐
- 指令微调 (Supervised Fine-Tuning, SFT): 使用大量“(指令, 理想输出)”格式的数据进行微调(可配合全参数或PEFT方法),让模型学会“听懂话、好好说话”。
- 对齐技术 (RLHF / DPO 等): 在SFT基础上,通过人类反馈的强化学习 (RLHF) 或直接偏好优化 (DPO) 等方法,进一步使模型的输出与人类的偏好和价值观对齐。
- 核心驱动: 使模型不仅能完成特定任务,更能理解复杂指令并生成有用、诚实、无害的回答。
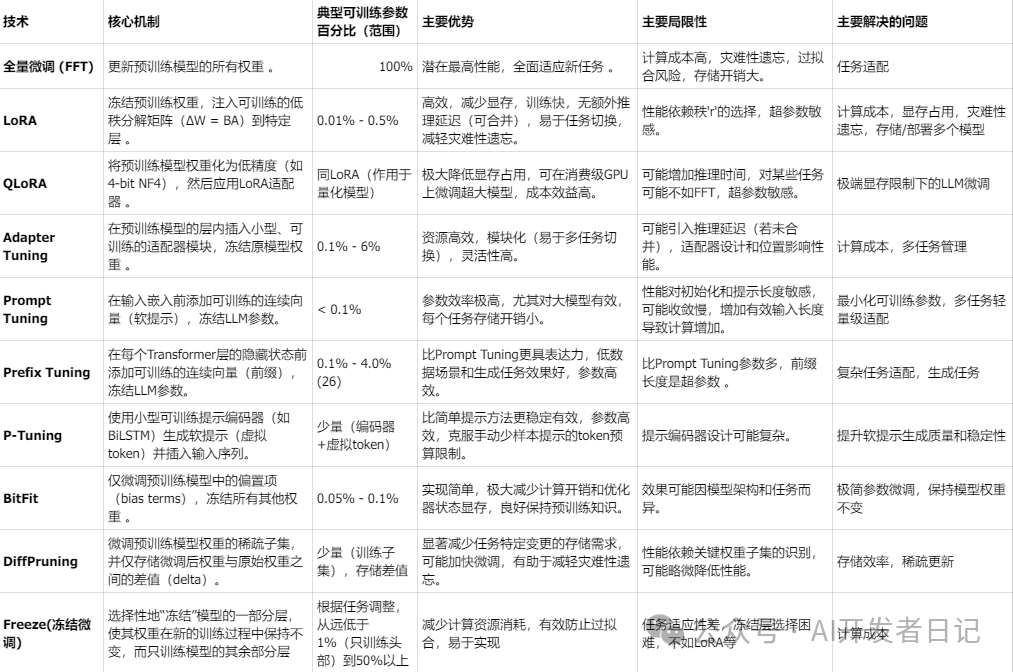
微调技术对比
微调工具选择
开源微调工具的涌现极大地推动了LLM定制化的普及和发展。降低了技术门槛,使得更广泛的用户和组织能够根据自身需求调整和优化强大的预训练模型,从而催生了大量的创新应用 。这一领域发展极为迅速,新的工具和技术层出不穷,不断提升微调的效率和效果 。
在众多开源LLM微调工具中,以下框架因其功能全面、社区活跃或性能卓越而备受关注。重点分析以下几款具有代表性的工具:LLaMA-Factory、Hugging Face AutoTrain Advanced、Axolotl、Unsloth、LitGPT (Lightning AI)、Torchtune (PyTorch) 以及 XTuner (InternLM)。
截至写稿时间2025年5月9日
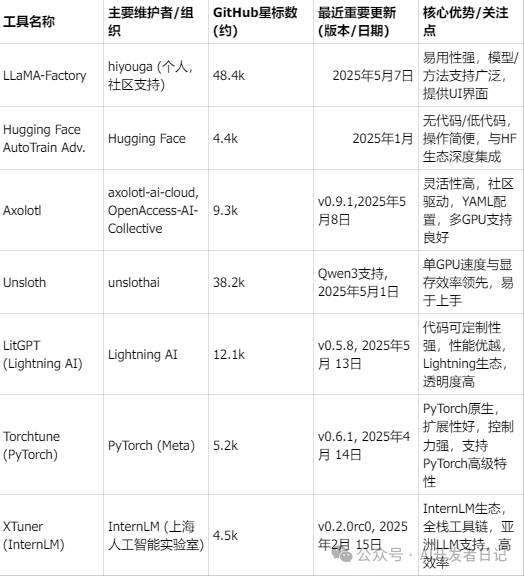
主流微调框架详细特性矩阵
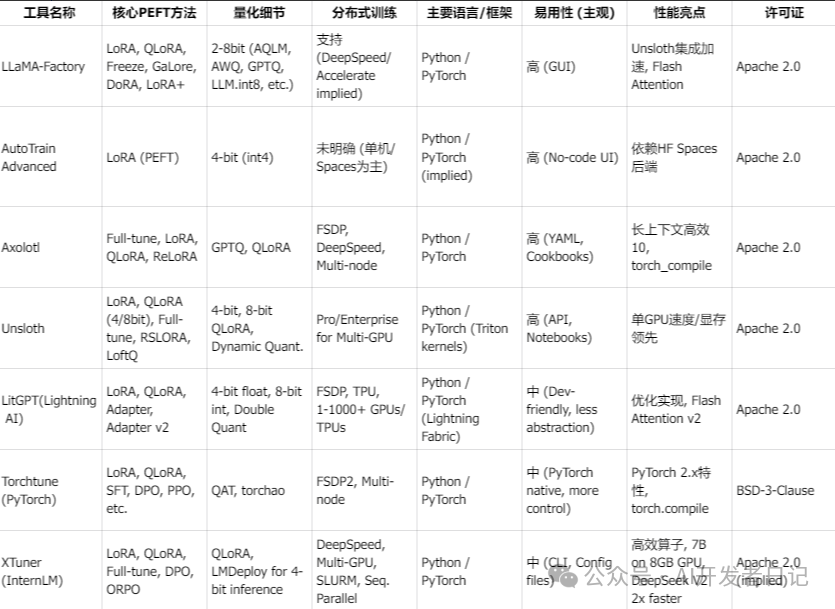
基于场景的工具选择
- 场景1:初学者,GPU资源有限,希望尝试微调。
- 推荐:LLaMA-Factory (提供GUI,并集成了Unsloth优化 )或Unsloth (提供Colab Notebooks,单GPU性能优异 ) 或。对于完全无代码的需求,可以看看AutoTrain,不过已经很久没更新了(相对其他项目),慎选 。
- 场景2:研究人员,需要高度灵活性以实验新方法和多样化模型。
- 推荐:Axolotl (模型支持广泛,社区驱动,能快速采纳新技术 ) 或 LitGPT (代码可定制性强,便于修改和实验 )。
- 场景3:身处PyTorch生态的机器学习工程师,需要为大型模型进行稳健的分布式扩展。
- 推荐:Torchtune (PyTorch原生,支持FSDP2和多节点训练 )。
- 场景4:开发者希望最大限度地控制和理解训练过程的每一个细节。
- 推荐:LitGPT (几乎无抽象层,代码透明 ) 或 Torchtune (抽象层最少,接近PyTorch底层 )
量化
量化(Quantization)可以被视为大模型微调生态系统中的一个重要组成部分,或者是一个与微调紧密配合的关键技术,尤其是在追求极致效率和在资源受限环境下部署模型时。
但是严格来说,量化本身是一种模型压缩技术,旨在降低模型权重和/或激活值的数值精度(例如,从32位浮点数FP32转换为8位整数INT8、4位整数INT4或更低位数)。

量化的基本原理
- 将高精度浮点数(如FP32)映射到低精度定点数(如INT8, INT4)或低精度浮点数(如FP8, BF16)。
- 这涉及到确定一个缩放因子 (scale) 和一个可选的 零点 (zero-point),用于在高精度和低精度之间进行转换。
主要的量化方法类型
- 训练后量化 (Post-Training Quantization, PTQ):
在模型已经训练或微调完成后进行量化,不需要重新训练。
- GPTQ (Generative Pre-trained Transformer Quantization): 一种精确的、逐层进行的PTQ方法,通过解决权重矩阵的量化重建误差来获得较好的精度,常用于将LLM量化到INT4/INT3。
- AWQ (Activation-aware Weight Quantization): 认为并非所有权重都同等重要,保护那些对激活值影响大的权重,从而在量化时损失更少性能。
- SmoothQuant: 通过平滑激活值的分布,使得权重和激活值都更容易被量化。
- 量化感知训练 (Quantization-Aware Training, QAT):
- 在训练或微调过程中引入伪量化节点 (fake quantization nodes),模拟量化操作对前向传播和反向传播的影响。
- 模型在训练时就学习适应量化带来的精度损失,因此通常能达到比PTQ更高的准确率,尤其是在需要量化到非常低的比特数(如INT4甚至更低)时。
- 缺点是需要重新训练或完整微调,计算成本较高。
GGUF
GGUF (GPT-Generated Unified Format) 是一种常见的格式,由 llama.cpp 项目推广和广泛使用。但GGUF本身不是一种全新的、独立的量化算法,而是一个文件格式,它被设计用来存储和分发经过量化(或其他转换)的大语言模型。
- 通常是微调后的步骤: 一般情况下,开发者会首先在较高精度(如FP16或BF16)下完成模型的微调(无论是全参数微调还是PEFT如LoRA)。
- 转换与量化: 微调完成后,模型需要以GGUF格式分发和在本地运行,可以使用 llama.cpp 提供的转换脚本,将微调后的模型(如果是LoRA,则通常先合并LoRA权重到基础模型)转换为GGUF格式,并在此过程中选择一种llama.cpp支持的量化类型进行量化。
- 部署与推理: 最终用户下载GGUF格式的模型文件,使用 llama.cpp 或其他兼容的推理引擎在本地加载并运行。
- 高效推理: 经过 llama.cpp 优化的量化方法,可以在CPU上实现惊人的推理速度,并有效利用GPU。
- 低资源占用: 大幅减小模型文件大小和运行时内存占用。
- 易于分发和使用: 单个文件,方便共享和加载。
最后
综合考虑,推荐使用LLaMA-Factory,后续也将作为微调案例工具。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 19
19 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)