山软智读SDSE_AIR(六)
2025年4月21日 —— 2025年4月27日山软智读SDSE_AIR工作周记本周继续编写SpringBoot后端代码,主要包括MinerULocalBatchService、MinerUGetUrlsResponse Entity、MinerUExtractResultResponse Entity、ZipService等代码的编写。
2025年4月21日 —— 2025年5月4日 山软智读SDSE_AIR工作周记
本周继续编写SpringBoot后端代码,主要包括MinerULocalBatchService、MinerUGetUrlsResponse Entity、MinerUExtractResultResponse Entity、ZipService等代码的编写。
一、MinerULocalBatchService
上周完成了MinerUService代码的编写,但是经过测试之后发现,MinerUService 所依赖的官方API只能够解析公网链接的PDF文档(即你的PDF文档必须拥有可访问的公网链接,而不能是本地链接,比如你的PDF文档链接必须是https://csdn.sdse_air_pdf213516237.pdf而不能是http://localhost:8080/sdse_air_pdf213516237.pdf或者D:\sdse_air\sdse_air_pdf213516237.pdf).所以对于有大量本地pdf上传需求的本项目而言,MinerUService不能满足项目功能需求,需要编写新的代码,而MinerU API也提供了相应接口可以使用。

1. MinerUGetUrlsResponse Entity
首先需要向 https://mineru.net/api/v4/file-urls/batch 发送http请求,该API接口会返回一个包含batch_id的 json 对象,后续查询下载PDF解析结果压缩文件都要依赖batch_id,为了方便解析获取数据,我们定义一个实体类 MinerUGetUrlsResponse ,具体属性如下:
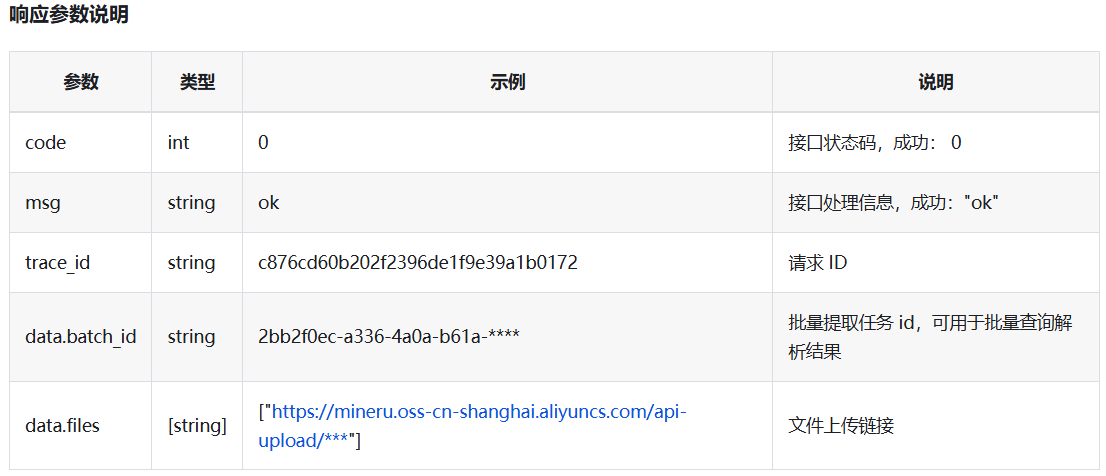
@Data
public class MinerUGetUrlsResponse {
private int code;
private String msg;
@JsonProperty("trace_id")
private String traceId;
private Data data;
// 内部的 Data 类
@lombok.Data
public static class Data {
@JsonProperty("batch_id")
private String batchId;
@JsonProperty("file_urls")
private List<String> fileUrls;
}
}2. MinerUExtractResultResponse Entity
然后根据拿到的batch_id 和 fileUrls,定时轮询查看解析结果,将解析成功的文件的ZipUrl加入数组,当全部文件解析成功或者超时返回已经解析的文件的ZipUrls,然后下载对应的所有zip。为了方便解析获取数据,我们定义一个实体类 MinerUExtractResultResponse ,具体属性如下:
@Data
public class MinerUExtractResultResponse {
private int code;
private String msg;
@JsonProperty("trace_id")
private String traceId;
private Data data;
// 内部的 Data 类
@lombok.Data
public static class Data {
@JsonProperty("batch_id")
private String batchId;
@JsonProperty("extract_result")
private List<extract_result_single> extractResult;
}
// extract_result内部的extract_result_single
@lombok.Data
public static class extract_result_single {
@JsonProperty("file_name")
private String fileName;
private String state;
@JsonProperty("err_msg")
private String errMsg;
@JsonProperty("full_zip_url")
private String fullZipUrl;
}
}3. MinerULocalBatchService
3.1 getUrlsAndUploadFileBatch(List<Map<String, Object>> uploadFiles)函数
首先构造List uploadFiles用于存储所有上传PDF的路径,然后构造http请求的请求头和请求体,随后向 https://mineru.net/api/v4/file-urls/batch 发送http请求,获得 batch_id ,然后上传所有PDF到MinerU(实际上是上传到阿里云,MinerU使用了阿里云的服务,至于为什么会知道,当然是因为遇到了坑!!!)
public String getUrlsAndUploadFileBatch(List<Map<String, Object>> uploadFiles) {
NUM_OF_FILES = uploadFiles.size();
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
headers.setBearerAuth(AUTHORIZATION_TOKEN);
Map<String, Object> body = new HashMap<>();
body.put("enable_formula", true);
body.put("enable_table", false);
body.put("layout_model", "doclayout_yolo");
body.put("language", "auto");
List<Map<String, Object>> files = new ArrayList<>();
for (Map<String, Object> uploadFile : uploadFiles) {
Map<String, Object> file = new HashMap<>();
file.put("name", uploadFile.get("fileName"));
file.put("is_ocr", false);
files.add(file);
}
body.put("files", files);
HttpEntity<Map<String, Object>> requestEntity = new HttpEntity<>(body, headers);
try {
ResponseEntity<MinerUGetUrlsResponse> response = restTemplate.postForEntity(
BATCH_TASK_URL, requestEntity, MinerUGetUrlsResponse.class);
if (response.getStatusCode() == HttpStatus.OK && response.getBody() != null
&& response.getBody().getCode() == 0 && response.getBody().getMsg().equals("ok")) {
String batchId = response.getBody().getData().getBatchId();
List<String> urls = response.getBody().getData().getFileUrls();
// 开始上传文件!!!
for (int i = 0; i < urls.size(); i++) {
String filePath = (String) uploadFiles.get(i).get("filePath");
String fileUrl = urls.get(i);
System.out.println(filePath);
System.out.println(fileUrl);
uploadFile(filePath, fileUrl);
}
return batchId;
} else {
throw new RuntimeException("获取文件Url(s)失败,响应状态码:" + response.getStatusCodeValue() +
" 接口状态码:" + response.getBody().getCode() + " msg:" + response.getBody().getMsg());
}
} catch (Exception e) {
throw new RuntimeException("调用 MinerU API 出错:" + e.getMessage(), e);
}
}
private void uploadFile(String filePath, String uploadUrl) {
try {
URL url = new URL(uploadUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(true);
conn.setRequestMethod("PUT");
conn.setConnectTimeout(10000);
conn.setReadTimeout(10000);
// 不要设置Content-Type
conn.setRequestProperty("Content-Length", String.valueOf(Files.size(Paths.get(filePath))));
try (OutputStream os = conn.getOutputStream();
InputStream is = Files.newInputStream(Paths.get(filePath))) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = is.read(buffer)) != -1) {
os.write(buffer, 0, bytesRead);
}
}
int responseCode = conn.getResponseCode();
if (responseCode / 100 == 2) { // 2xx 成功
System.out.println(filePath + " uploaded successfully.");
} else {
System.out.println("Failed to upload " + filePath + ", responseCode: " + responseCode);
}
} catch (Exception e) {
e.printStackTrace();
}
}3.2 fetchExtractResultWithPolling(String batchId)函数
根据拿到的 batch_id 轮询PDF处理状态,将状态为 “done” 的 fileUrl 存储起来,并标记该PDF,在下次轮询时跳过所有标记的PDF,继续存储所有状态为 “done” 的未被标记的PDF的fileUrl,直至所有PDF完成处理或者超时。具体代码如下:
public List<String> fetchExtractResultWithPolling(String batchId) throws InterruptedException {
// 拼接URL
String url = String.format(EXTRACT_RESULT_URL, batchId);
// 设置请求头
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
headers.setBearerAuth(AUTHORIZATION_TOKEN);
HttpEntity<Void> requestEntity = new HttpEntity<>(headers);
int retryCount = 0;
boolean allDone = false;
List<String> zipUrls = new ArrayList<>();
Set<String> processedFileNames = new HashSet<>();
while (!allDone && retryCount < MAX_RETRIES * NUM_OF_FILES) {
ResponseEntity<MinerUExtractResultResponse> response = restTemplate.exchange(
url, HttpMethod.GET, requestEntity, MinerUExtractResultResponse.class);
if (response.getStatusCode() == HttpStatus.OK && response.getBody() != null) {
if (response.getBody().getCode() == 0 && response.getBody().getMsg().equals("ok")) {
List<MinerUExtractResultResponse.extract_result_single> extractResults = response.getBody().getData().getExtractResult();
allDone = true; // 默认认为都完成,发现有pending再改
for (MinerUExtractResultResponse.extract_result_single extractResult : extractResults) {
String fileName = extractResult.getFileName();
String state = extractResult.getState();
if ("done".equals(state) && !processedFileNames.contains(fileName)) {
String zipUrl = extractResult.getFullZipUrl();
if (zipUrl != null) {
zipUrls.add(zipUrl);
processedFileNames.add(fileName);
}
} else if (!"done".equals(state) && !"failed".equals(state)) {
allDone = false;
} else if ("failed".equalsIgnoreCase(state)) {
throw new RuntimeException("MinerU获取full_zip_url失败,错误信息:" + fileName + " " + extractResult.getErrMsg());
}
}
} else {
throw new RuntimeException("Failed to fetch extract results, reason: " + response.getBody().getMsg());
}
} else {
throw new RuntimeException("API request failed with status: " + response.getStatusCode());
}
if (!allDone) {
retryCount++;
Thread.sleep(RETRY_DELAY_MS);
}
}
if (!allDone) {
String message = retryCount >= MAX_RETRIES * NUM_OF_FILES
? "任务超时:超过最大重试次数,仍有未完成文件,batchId: " + batchId
: "部分文件未完成处理,batchId: " + batchId;
throw new RuntimeException(message);
}
return zipUrls;
}二、ZipService
第一步 MinerULocalBatchService 只是拿到了所有解析成功的PDF文件的 下载链接,接下来需要把解析的结果Zip文件下载到本地、解压缩、删除无用的文件。
2.1 downloadZip 下载文件到本地
首先需要根据拿到的 fileUrl 将Zip文件下载到本地,创建不存在的文件夹。具体代码如下:
public File downloadZip(String fileUrl, Integer pdf_id) throws IOException {
URL url = new URL(fileUrl);
Pdf pdf = pdfService.getById(pdf_id);
PARENT_FOLDER_NAME = pdf.getParentFolderName();
ZIP_NAME = FileUtil.mainName(pdf.getName());
String zipFileName = ZIP_NAME + ".zip";
String targetDir = ROOT_PATH + File.separator + PARENT_FOLDER_NAME;
Path targetPath = Paths.get(targetDir, zipFileName);
try (InputStream in = url.openStream()) {
Files.copy(in, targetPath, StandardCopyOption.REPLACE_EXISTING);
}
return targetPath.toFile();
}2.2 unzip 解压zip文件到指定文件夹
紧接着需要解压zip文件,首先需要递归确认确保父目录存在,然后再进行解压。具体代码如下:
public File unzip(File zipFile) throws IOException {
String destDir = ROOT_PATH + File.separator + PARENT_FOLDER_NAME;
File originFolder = new File(destDir);
File destFolder = new File(destDir, ZIP_NAME);
if (!destFolder.exists()) {
destFolder.mkdirs();
}
try (ZipInputStream zis = new ZipInputStream(Files.newInputStream(zipFile.toPath()))) {
ZipEntry entry;
while ((entry = zis.getNextEntry()) != null) {
File newFile = new File(destFolder, entry.getName());
if (entry.isDirectory()) {
newFile.mkdirs();
} else {
// 确保父文件夹存在
String new_file_parent = newFile.getParent();
File parentDir = new File(newFile.getParent());
if (!parentDir.exists()) {
parentDir.mkdirs();
}
try (FileOutputStream fos = new FileOutputStream(newFile)) {
byte[] buffer = new byte[1024];
int len;
while ((len = zis.read(buffer)) > 0) {
fos.write(buffer, 0, len);
}
}
}
zis.closeEntry();
}
}
// 递归删除解压缩文件夹中不需要的文件
deleteUnwantedFiles(originFolder);
return destFolder;
}2.3 deleteUnwantedFiles 递归删除压缩文件夹中不需要的文件
解压后的文件夹中有一些不需要的文件(比如.json、.pdf文件),我们只保留.md文件和相应的图片(.png文件),并将markdown文件及其父文件夹重命名。具体代码如下:
public void deleteUnwantedFiles(File folder) {
// 遍历文件夹,删除不需要的文件
if (folder.isDirectory()) {
for (File file : Objects.requireNonNull(folder.listFiles())) {
if (file.isDirectory()) {
deleteUnwantedFiles(file); // 递归删除子文件夹
} else {
String mainName = FileUtil.mainName(file); // 文件名
String extName = FileUtil.extName(file); // 文件拓展名
if (("pdf".equals(extName) && !ZIP_NAME.equals(mainName)) || "json".equals(extName) || "zip".equals(extName)) {
FileUtil.del(file);
} else if ("md".equals(extName)) {
String newName = ZIP_NAME + ".md";
FileUtil.rename(file, newName, true);
}
}
}
}
}---------------------------------------------------------------------------------------------------------------------------------
以上为本周山软智读SDSE_AIR的全部工作内容
SDSE_AIR山软智读项目研发小组 AlondonZnm

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)