OCR推理大模型全军覆没?OCR-Reasoning基准揭示多模态大模型推理短板
1.5-Vision-Pro、通义千问 Qwen2.5-VL、Kimi-VL-Thinking、GPT-4o、Claude-3.7、Gemini-2.0-flash、DeepSeek-R1 等。CoT 提示能持续提升大多数模型性能(如 Qwen2.5-VL-32B +3.2%, GPT-4o +4.2%)。Qwen2.5-VL-7B 进行 RL 训练的模型(如 VLAA-Thinker, MM-E

近年多模态推理模型在数学题、学科题上表现出色(MathVista, MMMU等),但 OCR 相关的复杂任务——比如看促销海报算计算最便宜买法、分析财务报表、规划最优路线、处理票据信息——它们的“真本事”到底如何?
长期以来,竟然没有一个系统性的评测标准来检验这些核心 OCR 推理能力!现在,填补这一巨大空白的基准——OCR-Reasoning——终于发布!

论文标题:
OCR-Reasoning Benchmark: Unveiling the True Capabilities of MLLMs in Complex Text-Rich Image Reasoning
论文链接:
https://arxiv.org/pdf/2505.17163
代码链接:
https://github.com/SCUT-DLVCLab/OCR-Reasoning
项目主页:
https://ocr-reasoning.github.io/

现有OCR评测的短板:主要是“看答案”,没有考验“真思考”
像 DocVQA、TextVQA、OCRBench 这些主流基准,主要考察多模态大模型的感知能力,考的是信息查找和提取(比如“发票总金额是多少?”)。
这种任务靠“快思考”就能搞定,无法准确的衡量模型在复杂 OCR 场景下需要的深度推理能力,比如:
1. 空间布局理解:版面元素之间的空间布局关系怎么看?关系图和树状图怎么看?
2. 数值计算与分析:购物怎么凑单才能最优惠?金融财报怎么分析?
3. 逻辑推理与批判思维:如何根据图文信息推导结论?
4. 多学科知识应用:怎么解决物理图、化学式的问题?

OCR-Reasoning基准:专为OCR推理而生!
为了系统地评测模型在 OCR 场景下的推理水平,研究者打造了 OCR-Reasoning 基准,三大核心亮点:
高质量 & 强推理导向数据集:
-
1069 道手工精标题目 + 1022 张图片
-
双重标注+质量评分+人工校验流程,确保数据可靠
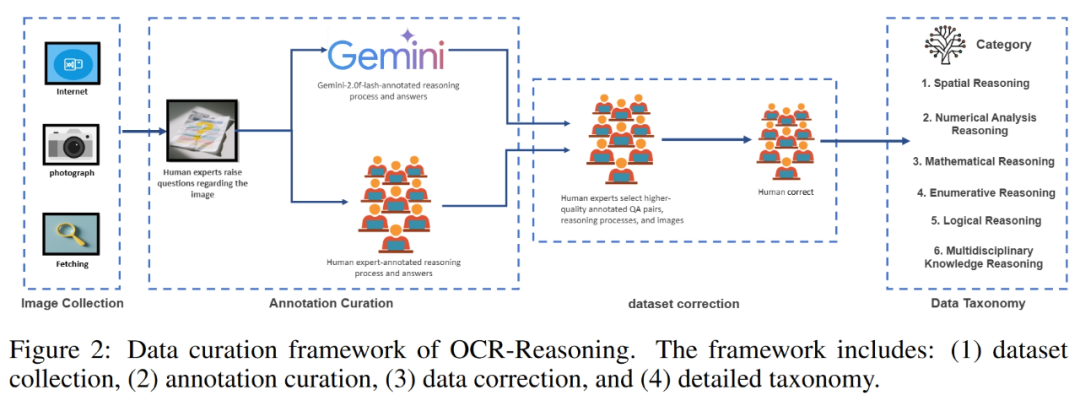
-
硬核要求:答案极少来自原文!OCR-Reasoning (仅 2.3%) vs. 现有基准(答案多可从图片中进行“复制”)。
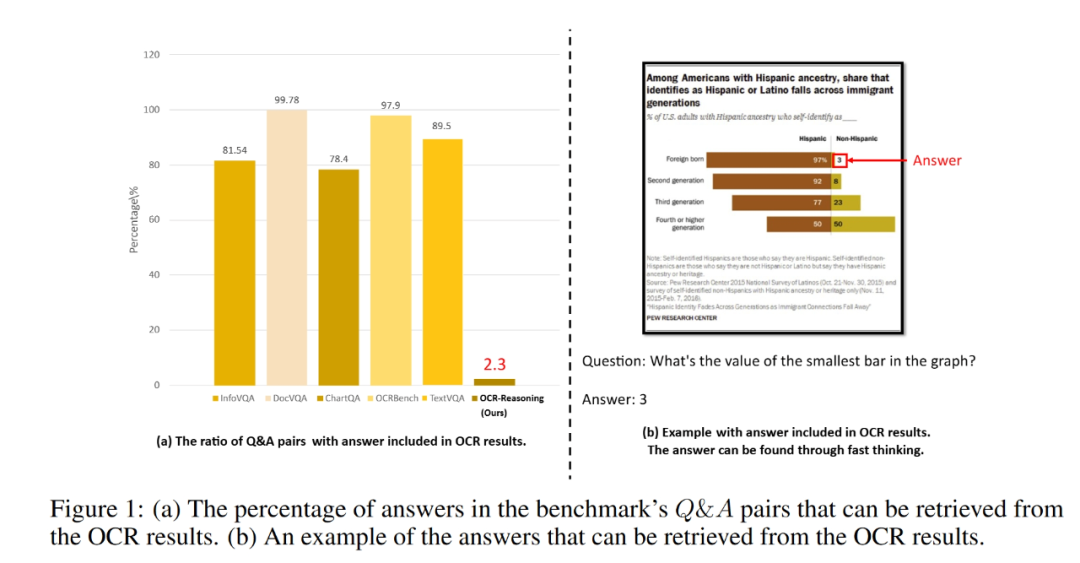
-
典型案例对比:
-
-
老基准:“这件衣服加个多少?” → 读取商标上的数字
-
OCR-Reasoning:“买衣服的时候 3 件可以打 6 折,那么某顾客买三件衣服打折后最低单价?” → 需整合价格、规则、商品信息,推理计算!
-
全覆盖六大核心推理能力:
-
空间推理:图文混排的布局、位置关系理解。
-
数值分析:计算成本效益、增长率、财报数据、日程规划。
-
枚举推理:按条件计数图文元素。
-
数学推理:解决函数图、几何题、统计问题(大多数题目是手抄获取,更贴合真实 OCR 场景!)。
-
逻辑推理:批判性思维,基于图文进行推论。
-
多学科推理:应用物理、化学知识解决图文问题(大多数题目手抄获取!)。


评测结果:顶尖模型也“不及格”,三大关键发现!
研究团队对主流开源 & 闭源模型进行了全面“大考”,包括:豆包-1.5-Vision-Pro、通义千问 Qwen2.5-VL、Kimi-VL-Thinking、GPT-4o、Claude-3.7、Gemini-2.0-flash、DeepSeek-R1 等。
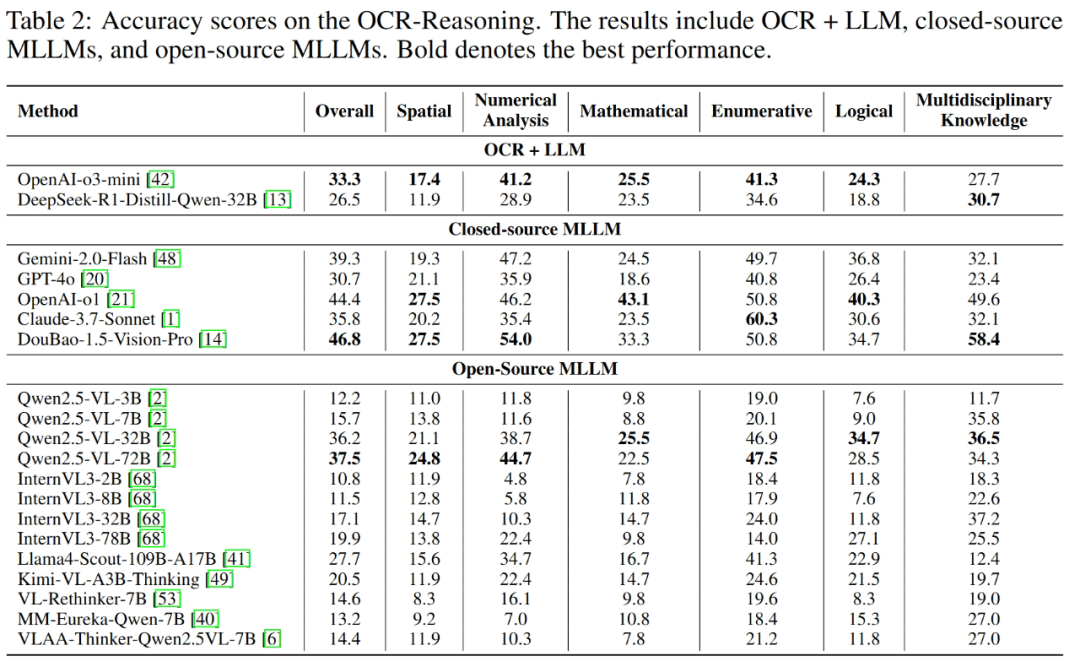
发现 1:没“眼睛”真不行!视觉信息是 OCR 推理的命脉
同一个语言模型(Qwen2.5-32B),纯文本版(DeepSeek-R1+OCR)准确率仅 26.5%,而多模态版(Qwen2.5-VL-32B)飙升至 36.2% —— 差距高达 9.7 个百分点!证明图像输入对文本丰富图像推理至关重要。
发现 2:RL 训练需针对 OCR 推理进行优化
基于 Qwen2.5-VL-7B 进行 RL 训练的模型(如 VLAA-Thinker, MM-Eureka),数学和逻辑推理能力显著提升,但空间和数值分析能力反而下降!这提示:亟需设计更适配 OCR 推理的 RL 算法。
发现 3:天花板还很高!现有技术远未成熟
-
文档理解“尖子生”豆包-1.5-Vision-Pro (DocVQA 96.7%, ChartQA 87.4%),在 OCR-Reasoning 上准确率竟不足 50% (46.8%)!
-
GPT-4o (44.4%)、Gemini-2.0-flash (39.3%) 同样表现挣扎。
-
结论:同步处理视觉文本、理解语义、进行逻辑推理,是当前模型面临的巨大挑战!
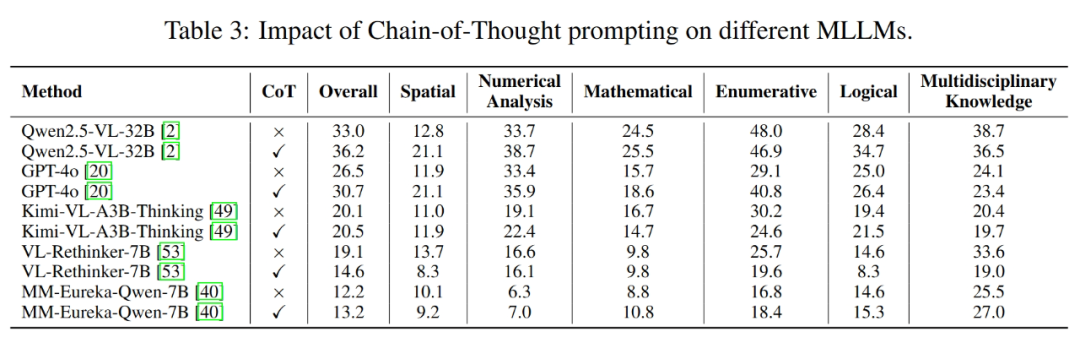
CoT(思维链)有用吗?
普遍有效:CoT 提示能持续提升大多数模型性能(如 Qwen2.5-VL-32B +3.2%, GPT-4o +4.2%)。特例是 VL-Rethinker-7B 用了 CoT 反而掉分!原因可能是其内置反思机制与额外 CoT 提示冲突,破坏了训练-测试一致性。
推理过程质量评估:

-
使用 LLM 评估模型推理路径质量。
-
整体排名与答案准确性排名相似,但 Gemini 和 Claude-3.7-Sonnet 的推理过程质量评分相对更高。
-
典型案例:Gemini-2.0-Flash 推理过程基本合理(获高分),但因微小计算错误导致答案错误。这说明高质量的推理过程同样重要!

便捷使用:一键评测,加速研究!
OCR-Reasoning 评测代码已无缝集成至 VLMevalkit 工具包,支持研究者一键进行评估,极大提升效率!

结语:OCR推理的新基准来了!
OCR-Reasoning 基准的发布,填补了 OCR 场景下复杂推理能力评估的空白,为多模态模型的研发与优化提供了关键标尺和方向指引。
评测结果揭示了一个事实:即使是当前最顶尖的模型,在面对真实世界复杂的 OCR 推理任务时,也才刚刚起步,挑战巨大,潜力无限!
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·



欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 24
24 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)