Color-Neus复现
-exp_id用于指定实验的名称,如color_Neus_dtu_83。然后由于修改了配置文件Color_NeuS_zhiwu.yml中的INCLUDE_MASK为False,那么就应该进行无掩码计算,需要修改训练代码autodl-tmp/Color-NeuS/lib/models/NeuS_Trainer.py中的。又由于配置文件Color_NeuS_zhiwu.yml中指定的数据集类型zhiw
1、配置环境
下述命令是官方提供的配置环境的命令,但是我不建议这么做,因为国内的安装源非常慢。
git clone https://github.com/Colmar-zlicheng/Color-NeuS.git cd Color-NeuS conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia pip install -r requirements.txt pip install "git+https://github.com/facebookresearch/pytorch3d.git"
以下是我配置环境的步骤:
首先按照下述配置,创建autodl实例:

然后按照以下步骤设置本autodl实例的安装源为清华源:
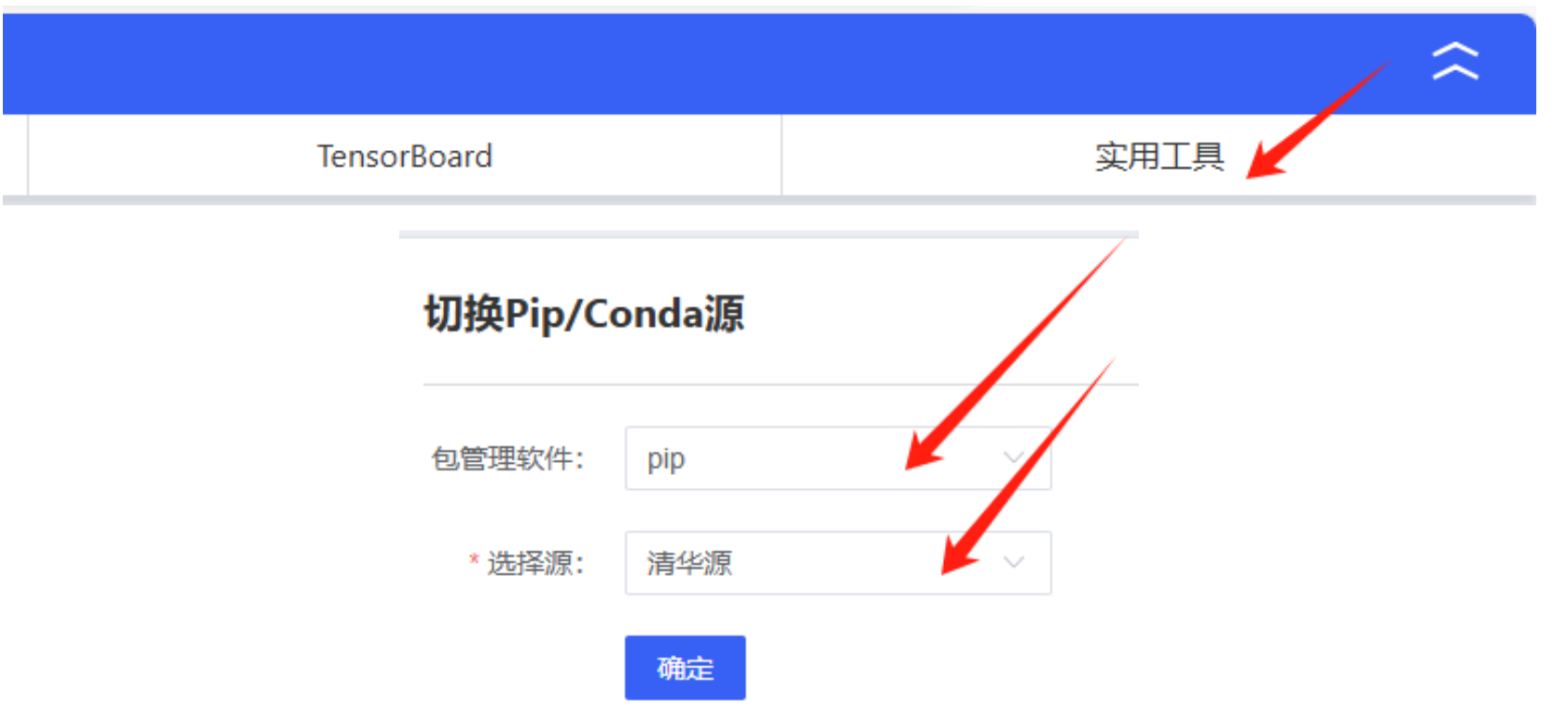
然后输入以下命令,验证环境中安没安装PyTorch 2.0.0+cu118、TorchVision 0.15.1+cu118、Torchaudio 2.0.0+cu118、CUDA 11.8这四个包:
python
import torch
import torchvision
import torchaudio
print("PyTorch version:", torch.__version__)
print("TorchVision version:", torchvision.__version__)
print("Torchaudio version:", torchaudio.__version__)
print("CUDA available:", torch.cuda.is_available())
print("CUDA version:", torch.version.cuda)
本autodl实例环境得到以下输出:
root@autodl-container-8cee4dbe08-5cf1cc7e:~/autodl-tmp/Color-NeuS# python
Python 3.8.10 (default, Jun 4 2021, 15:09:15)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> import torchvision
>>> import torchaudio
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'torchaudio'
>>> print("PyTorch version:", torch.__version__)
PyTorch version: 2.0.0+cu118
>>> print("TorchVision version:", torchvision.__version__)
TorchVision version: 0.15.1+cu118
>>> print("Torchaudio version:", torchaudio.__version__)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'torchaudio' is not defined
>>> print("CUDA available:", torch.cuda.is_available())
CUDA available: True
>>> print("CUDA version:", torch.version.cuda)
CUDA version: 11.8
[1]+ Stopped python
root@autodl-container-8cee4dbe08-5cf1cc7e:~/autodl-tmp/Color-NeuS# nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
成功验证了 CUDA 和 PyTorch 的安装,并且 PyTorch 和 TorchVision 的版本也是正确的。然而,Torchaudio 还没有安装。因此,需要在当前环境中安装 Torchaudio。运行下述命令安装与当前各个包版本兼容的Torchaudio:
pip install torchaudio==2.0.0+cu118 -f https://download.pytorch.org/whl/cu118/torch_stable.html
再次运行下述命令验证Torchaudio的安装:
python
import torchaudio
print("Torchaudio version:", torchaudio.__version__)
输出以下信息即正确安装Torchaudio:
root@autodl-container-863d4c8631-73aa9f78:~/autodl-tmp/Color-NeuS# python
Python 3.8.10 (default, Jun 4 2021, 15:09:15)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torchaudio
>>>
>>> print("Torchaudio version:", torchaudio.__version__)
Torchaudio version: 2.0.0+cu118
然后依次运行下述命令:
cd autodl-tmp/Color-NeuS pip install -r requirements.txt pip install "git+https://github.com/facebookresearch/pytorch3d.git"
2、数据集
IHO视频下载链接:Color-NeuS – Google Drive
BlendedMVS数据集链接、DTU数据集链接:neus - Dropbox
OmniObject3D数据集链接:数据集-OpenDataLab
本次实验训练的是DTU数据集,将以下两个DTU数据集下载下来后上传至autodl:
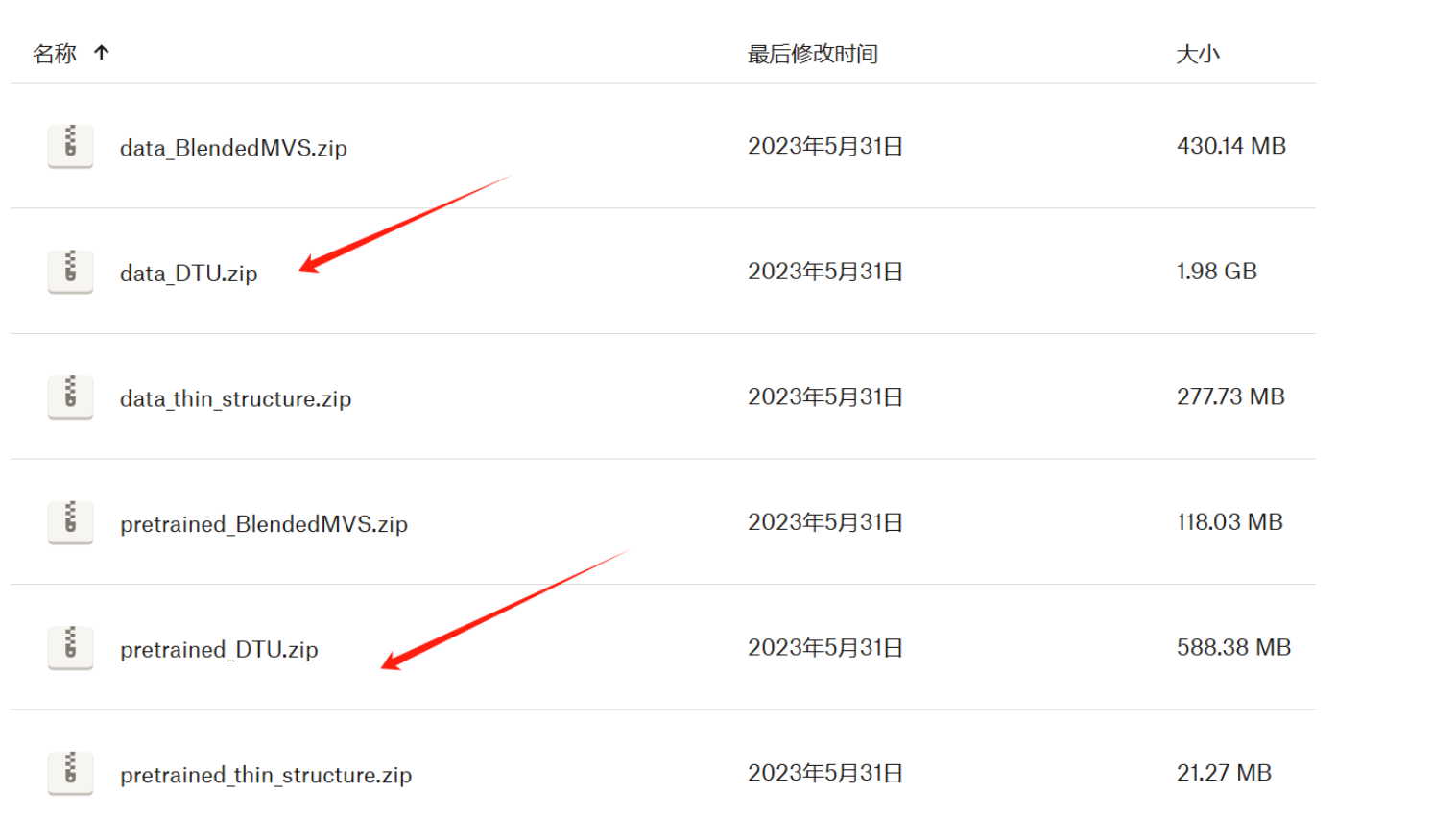
在autodl-tmp/Color-NeuS下创建文件夹data,又在autodl-tmp/Color-NeuS/data下创建文件夹DTU,然后将data_DTU.zip解压至目录autodl-tmp/Color-NeuS/data/DTU,随后将data_DTU.zip压缩包删除:
然后将pretrained_DTU.zip解压至autodl-tmp/Color-NeuS目录下,随后将pretrained_DTU.zip压缩包删除。
3、训练(dtu数据集)
以下是训练命令,其中-g, --gpu_id,用于训练的可见 GPU,例如 -g 0仅支持单个 GPU;${DATASET}中填数据集的名称,即[iho, dtu, bmvs, omniobject3d]中的一个;${OBJECT_NAME}为手动设置的数据集中对象的名称,如dtu_83;--exp_id用于指定实验的名称,如color_Neus_dtu_83。
#训练命令
python train.py -g 0 --cfg config/Color_NeuS_${DATASET}.yml -obj ${OBJECT_NAME} --exp_id ${EXP_ID}
#例子
# IHO Video: ghost_bear
python train.py -g 0 --cfg config/Color_NeuS_iho.yml -obj ghost_bear --exp_id Color_NeuS_iho_ghost_bear
# DTU: dtu_scan83
python train.py -g 0 --cfg config/Color_NeuS_dtu.yml -obj 83 --exp_id Color_NeuS_dtu_83
# BlendedMVS: bmvs_bear
python train.py -g 0 --cfg config/Color_NeuS_bmvs.yml -obj bear --exp_id Color_NeuS_bmvs_bear
# OmniObject3D: doll_002
python train.py -g 0 --cfg config/Color_NeuS_omniobject3d.yml -obj doll_002 --exp_id Color_NeuS_omniobject3d_doll_002所有训练结果都保存在exp/${EXP_ID}_{timestamp}/。
所有训练检查点都保存在exp/${EXP_ID}_{timestamp}/checkpoints/。
该项目还提供了Neus的实现,要训练 NeuS,可以在上面的命令行中替换为 :
# DTU: dtu_scan83
python train.py -g 0 --cfg config/NeuS_dtu.yml -obj 83 --exp_id NeuS_dtu_834、评估
以下是评估的命令,其中${DATASET}、${OBJECT_NAME}设置为和上面训练命令一样的值;设置${PATH_TO_CHECKPOINT}为要加载的检查点的路径:
cd autodl-tmp/Color-NeuS
#评估命令
python evaluation.py -g 0 --cfg config/Color_NeuS_${DATASET}.yml -obj ${OBJECT_NAME} -rr 512 --reload ${PATH_TO_CHECKPOINT}
#例子
python evaluation.py -g 0 --cfg config/Color_NeuS_dtu.yml -obj 83 -rr 512 --reload exp/Color_NeuS_dtu_40_2024_0719_2027_34/checkpoints/checkpoint_100001/NeuS_Trainer.pth.tar其中-rr,(--recon_res)是重构网格的分辨率,默认值为 512。
所有评估结果都保存在exp/eval_Color_NeuS_dtu_65_{timestamp}/。
5、在color-Neus上训练植物数据集
参考网址neus - Dropbox中的BlendedMVS数据集知道color-neus要处理的的数据集格式和Neus一摸一样,并且其中的pretrained_BlendedMVS就是Neus处理过数据集的检查点文件。
那么Neus预处理数据的步骤如下(color-Neus照做):
首先在Ubuntu系统中安装colmap。这一步按照网上的教程一步一步试错出来的,中间出现了很多版本不兼容和依赖库的问题,但是都解决了,过程过于繁琐,没有记录。
然后就开始进行数据预处理
根据网址NeuS/preprocess_custom_data 在主 ·龙猫97/NeuS ·GitHub上就可以按照Neus项目的方式自制数据集,然后用自制的数据集来训练Color-NeuS。
这里我选择制作DTU格式的N3植物数据集:
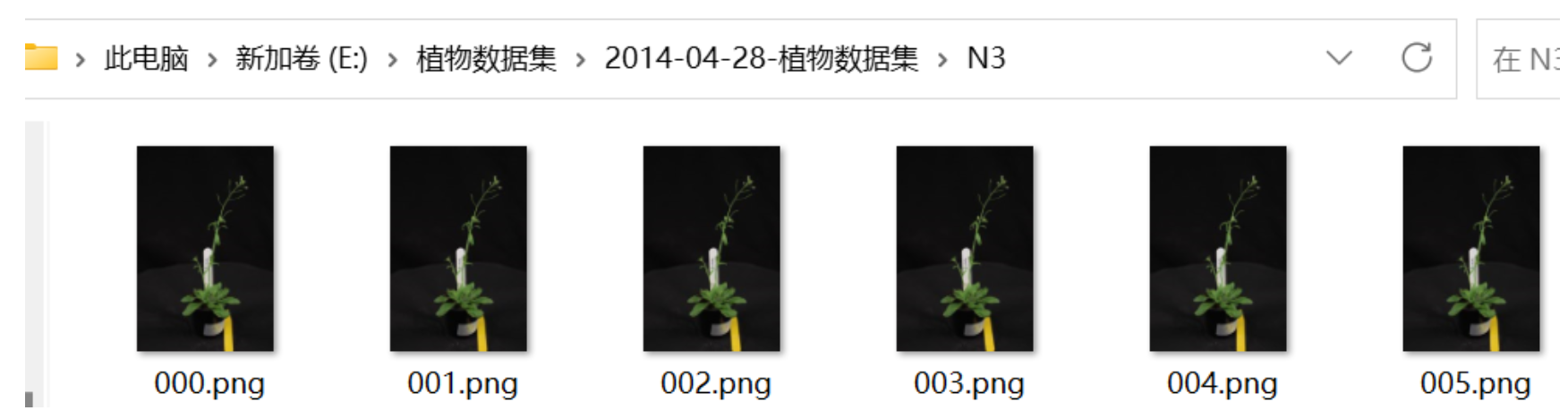
在正式制作DTU格式的数据集之前,先对N3植物数据集做一些预处理,首先将所有的图片名称改为000.png、001.png、……、100.png、……这样的格式,批量修改文件名和图片的尺寸用软件IrfanView。(注意:图片格式大小都要统一,每张图片分辨率要一样,如果感觉图片原尺寸大,可以把图片分辨率改为原来的一半试试,或者减少图片数量。)
然后将预处理好的N3数据集压缩成压缩包,传入autodl,然后用unzip解压至如下路径:
然后在N3文件夹中创建images文件夹(运行colmap时,它是在指定的路径下去找images文件夹里面存储的图片),然后把图片全部放入images文件夹中 
到这一步就可以按照Neus项目自制数据集的步骤开始操作了。
这里我选择根据Neus项目的option2做,也就是使用colmap自制数据集。
首先运行colmap,注意运行下述命令需要在autodl-tmp/NeuS目录下跑(不然会因为路径报错),也就是运行如下命令
python preprocess_custom_data/colmap_preprocess/imgs2poses.py public_data/N3运行上述命令后,稀疏点云将保存在autodl-tmp/NeuS/public_data/N3/sparse_points.ply中。
将sparse_points.ply下载下来,如下图所示:

然后去定义感兴趣的区域,原始稀疏点云可能很嘈杂,可能不适合定义感兴趣区域(白框表示点云的边界框):

可能需要自己清洁它(这里我们使用 Meshlab 手动清洁它)。清洗后:
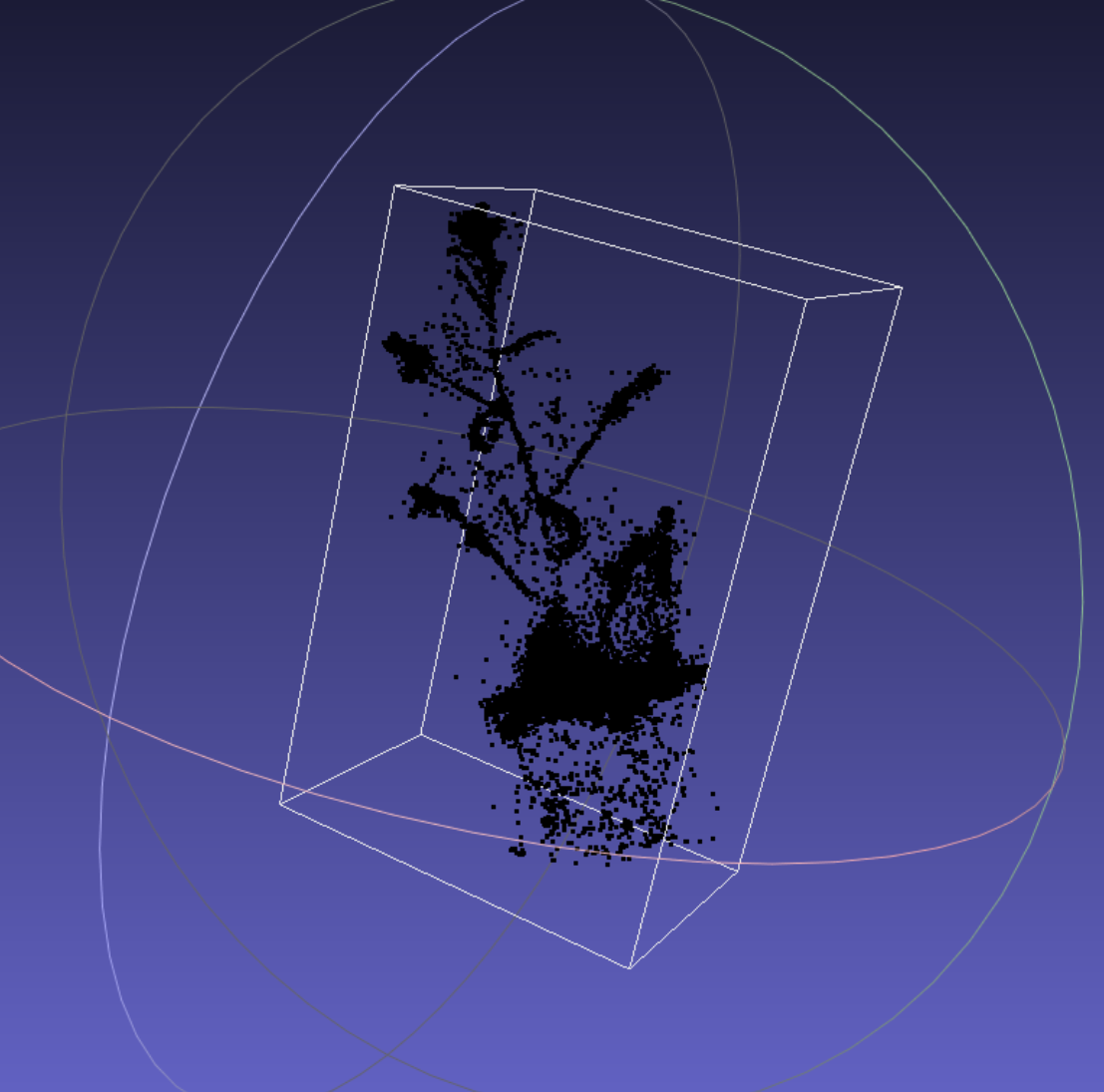
然后将其另存为sparse_points_interest.ply,上传至autodl的目录autodl-tmp/NeuS/public_data/N3/sparse_points_interest.ply中。
然后又运行如下命令(注意在autodl-tmp/Neus目录下),对colmap处理的结果进行预处理,从而得到满足格式要求的数据集(数据集里面就包含三个东西:①image;②npz;③mask)
python preprocess_custom_data/colmap_preprocess/gen_cameras.py public_data/N3然后预处理的数据可以在autodl-tmp/NeuS/public_data/N3/preprocessed中找到,至此就制作完成。
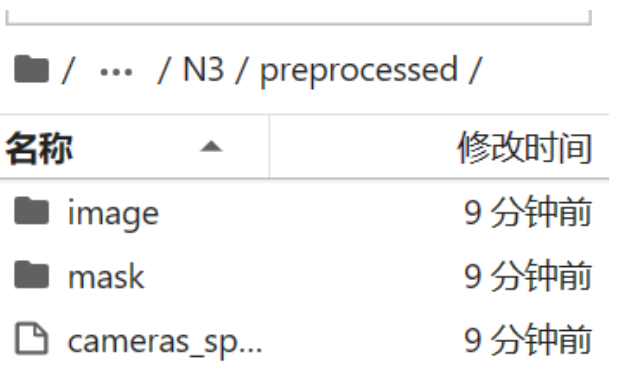
上述预处理的步骤都是之前跑Neus记录的,按照上述的步骤预处理多个植物数据集,然后存于autodl-tmp/Color-NeuS/data/Zhiwu目录下,且每个植物数据集前面都要加个zhiwu和下划线(代码中规定):
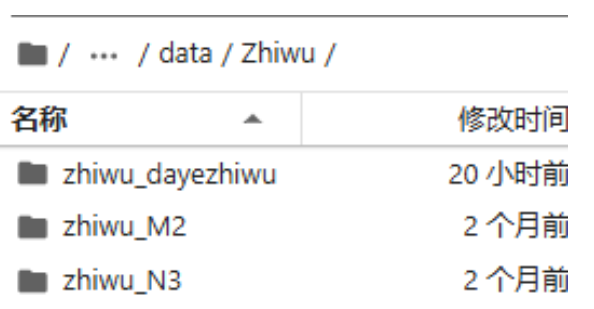
然后把之前跑Neus的环境中的N3数据集的检查点文件夹下载下来,上传至autodl-tmp/Color-NeuS/pretrained_zhiwu(pretrained_zhiwu文件夹为自己创建),有M2、N3、大叶植物:
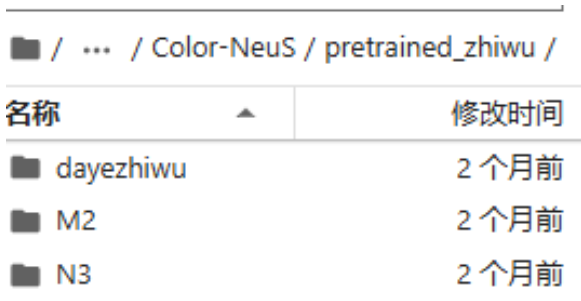
每个植物数据集里面都有一个无掩码(womask)的文件:
确保有里面checkpoints文件。
最后需要到目录autodl-tmp/Color-NeuS/config下创建一个名为Color_NeuS_zhiwu.yml的文件,该文件内容模拟了Color_NeuS_bmvs.yml的内容,因为两个数据集结构类似,下述是Color_NeuS_zhiwu.yml的内容:
DATASET:
TYPE: zhiwu
DATA_ROOT: ./data
DATA_PRESET:
FX_ONLY: False
INCLUDE_MASK: False#师姐论文都是跑的无掩码,所以我将这里改为了False
OPENGL_SYS: False
MODEL:
TYPE: NeuS_Trainer
PRETRAINED: null
N_RAYS: 1024
EVAL_RAY_SIZE: 1024
NORMALIZE_DIR: True
FOCAL_ORDER: 2
LEARN_FOCAL: False
LEARN_R: False
LEARN_T: False
MASK_RATE: [0.5, 0.8]
POSE_MODE: 6d
RENDERER:
TYPE: Color_NeuS
N_SAMPLES: 64
N_IMPORTANCE: 64
UP_SAMPLE_STEPS: 4
PERTURB: 1.0
SDF:
D_IN: 3
D_OUT: 257
D_HIDDEN: 256
N_LAYERS: 8
SKIP_IN: [4]
MULTIRES: 6
BIAS: 0.5
SCALE: 3.0
GEOMETRIC_INIT: True
WEIGHT_NORM: True
INSIDE_OUTSIDE: False
COLOR:
D_FEATURE: 256
MODE: no_view_dir
D_IN: 6
D_OUT: 3
D_HIDDEN: 256
N_LAYERS: 4
WEIGHT_NORM: True
MULTIRES_VIEW: 0
SQUEEZE_OUT: True
RELIGHT:
D_IN: 6
D_OUT: 3
D_HIDDEN: 256
N_LAYERS: 4
Y_IN_LAYER: 3
MULTIRES_VIEW: 4
INCLUDE_GRAD: True
INV_SIGMOID: True
DEVIATION:
INIT_VAL: 0.3
LOSS:
RGB_LOSS_TYPE: mse
LAMBDA_FINE: 1.0
LAMBDA_EIKONAL: 0.1
LAMBDA_MASK: 0.1
LAMBDA_RELIGHT: 1.0
TRAIN:
BATCH_SIZE: 8
ITERATIONS: 100000
OPTIMIZE:
TYPE: adam
LR: 0.0005
SCHEDULER_TYPE: NEUS
WARM_UP: 5000
LR_ALPHA: 0.05
LOG_INTERVAL: 10
SAVE_INTERVAL: 10000
VIZ_IMAGE_INTERVAL: 10000
VIZ_MESH_INTERVAL: 10000
MANUAL_SEED: 1
CONV_REPEATABLE: True
GRAD_CLIP_ENABLED: True
GRAD_CLIP:
TYPE: 2
NORM: 1.0又由于配置文件Color_NeuS_zhiwu.yml中指定的数据集类型zhiwu未注册到数据集注册表中,需要在代码中注册这个数据集,找到植物数据集注册的相关代码文件,通常在lib/datasets/__init__.py或lib/utils/builder.py中,然后添加植物数据集。
首先创建一个新的数据集类 ZhiwuDataset ,并将其放入 autodl-tmp/Color-NeuS/lib/datasets/zhiwu_dataset.py(zhiwu_dataset.py为自己创建)中,如下:
import os
import cv2
import imageio
import torch
import numpy as np
import torchvision.transforms.functional as tvF
from termcolor import colored
from lib.utils.builder import DATASET
from lib.utils.etqdm import etqdm
from lib.utils.logger import logger
from lib.utils.transform import load_K_Rt_from_P
@DATASET.register_module()
class ZhiwuDataset(torch.utils.data.Dataset):
def __init__(self, cfg) -> None:
super().__init__()
self.name = type(self).__name__
self.cfg = cfg
self.std = 0.5
self.data_root = cfg.DATA_ROOT
self.obj_id = cfg.OBJ_ID
self.fx_only = cfg.DATA_PRESET.get('FX_ONLY', False)
self.include_mask = cfg.DATA_PRESET.get('INCLUDE_MASK', True)
self.opengl_sys = cfg.DATA_PRESET.get('OPENGL_SYS', False)
self.data_path = os.path.join(self.data_root, 'Zhiwu', f"zhiwu_{self.obj_id}")
self.img_dir = os.path.join(self.data_path, 'image')
self.mask_dir = os.path.join(self.data_path, 'mask')
self.camera_path = os.path.join(self.data_path, 'cameras_sphere.npz')
images = sorted(os.listdir(self.img_dir))
self.image_paths = []
self.img_ids = []
for i in range(len(images)):
self.image_paths.append(os.path.join(self.img_dir, images[i]))
self.img_ids.append(torch.tensor([i]))
if self.include_mask:
masks = sorted(os.listdir(self.mask_dir))
if len(images) != len(masks):
raise ValueError(f"Number of images ({len(images)}) does not match number of masks ({len(masks)}).")
self.mask_paths = []
for i in range(len(masks)):
self.mask_paths.append(os.path.join(self.mask_dir, masks[i]))
self.img_ids = torch.cat(self.img_ids, dim=0)
self.n_imgs = len(self.image_paths)
self.origin = torch.tensor([0, 0, 0], dtype=torch.float32)
self.radius = torch.tensor(1, dtype=torch.float32)
if self.opengl_sys:
_coord_trans_OpenGL = np.array(
[
[1, 0, 0, 0],
[0, -1, 0, 0],
[0, 0, -1, 0],
[0, 0, 0, 1],
],
dtype=np.float32,
)
camera_dict = np.load(self.camera_path)
self.camera_dict = camera_dict
self.world_mats_np = []
self.scale_mats_np = []
for idx in range(self.n_imgs):
world_mat_key = f'world_mat_{idx}'
scale_mat_key = f'scale_mat_{idx}'
if world_mat_key in camera_dict and scale_mat_key in camera_dict:
self.world_mats_np.append(camera_dict[world_mat_key].astype(np.float32))
self.scale_mats_np.append(camera_dict[scale_mat_key].astype(np.float32))
else:
logger.warning(f"Missing keys for index {idx}: {world_mat_key} or {scale_mat_key}")
self.intrinsics_all = []
self.poses = []
for scale_mat, world_mat in zip(self.scale_mats_np, self.world_mats_np):
P = world_mat @ scale_mat
P = P[:3, :4]
intrinsics, pose = load_K_Rt_from_P(None, P)
self.intrinsics_all.append(intrinsics)
if self.opengl_sys:
pose = _coord_trans_OpenGL @ pose
self.poses.append(torch.from_numpy(pose).float())
if self.fx_only:
self.focal = np.array([self.intrinsics_all[0][0, 0]], dtype=np.float32)
else:
self.focal = np.array([self.intrinsics_all[0][0, 0], self.intrinsics_all[0][1, 1]], dtype=np.float32)
object_bbox_min = np.array([-1.01, -1.01, -1.01, 1.0])
object_bbox_max = np.array([1.01, 1.01, 1.01, 1.0])
object_scale_mat = np.load(self.camera_path)['scale_mat_0']
object_bbox_min = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_min[:, None]
object_bbox_max = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_max[:, None]
self.object_bbox_min = object_bbox_min[:3, 0]
self.object_bbox_max = object_bbox_max[:3, 0]
logger.info(f"{self.name}: zhiwu_{self.obj_id}, Got {colored(self.n_imgs, 'yellow', attrs=['bold'])}")
logger.info(f"{self.name}: zhiwu_{self.obj_id}, include_mask: {self.include_mask}")
def __len__(self):
return self.n_imgs
def get_image(self, idx):
path = self.image_paths[idx]
png = cv2.imread(path, cv2.IMREAD_UNCHANGED)
if png is None:
logger.error(f"Failed to read image from path: {path}")
raise ValueError(f"Image at path {path} is not readable or does not exist.")
image = png[:, :, :3].copy()
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = tvF.to_tensor(image)
assert image.shape[0] == 3
image = tvF.normalize(image, [0.5, 0.5, 0.5], [self.std, self.std, self.std])
image = image * 0.5 + 0.5 # [3, H, W] 0~1
if self.include_mask:
mask_path = self.mask_paths[idx]
mask = np.array(imageio.imread(mask_path, as_gray=True), dtype=np.uint8)
mask = tvF.to_tensor(mask).squeeze() # [H, W] 0 or 1
image = image * mask.unsqueeze(0)
return image, mask
else:
return image, None
def __getitem__(self, idx):
sample = {}
sample['pose'] = self.poses[idx]
sample['img_id'] = self.img_ids[idx]
if self.include_mask:
sample['image'], sample['mask'] = self.get_image(idx)
else:
sample['image'], _ = self.get_image(idx)
return sample
def get_init_data(self):
tmp_img, _ = self.get_image(0)
return {
'poses': torch.stack(self.poses, dim=0),
'focal': self.focal,
'H': tmp_img.shape[-2],
'W': tmp_img.shape[-1],
'n_imgs': self.n_imgs,
'origin': self.origin,
'radius': self.radius,
'scale_mats_np': self.scale_mats_np,
'object_bbox_min': self.object_bbox_min,
'object_bbox_max': self.object_bbox_max
}
def get_all_img(self):
logger.info("Loading all images ...")
all_img = []
if self.include_mask:
all_mask = []
for i in etqdm(range(self.n_imgs)):
img, mask = self.get_image(i)
all_img.append(img)
all_mask.append(mask)
all_mask = torch.stack(all_mask, dim=0)
else:
all_mask = None
for i in etqdm(range(self.n_imgs)):
img, _ = self.get_image(i)
all_img.append(img)
return {'images': torch.stack(all_img, dim=0), 'masks': all_mask, 'img_ids': self.img_ids}
def get_all_init(self, batch_size):
self.all_img_dict = self.get_all_img()
self.batch_size = batch_size
def get_rand_batch_smaples(self, device):
sample = {}
rand_index = torch.randperm(self.n_imgs)
use_index = rand_index[:self.batch_size]
sample['images'] = self.all_img_dict['images'][use_index].to(device)
sample['img_ids'] = self.img_ids[use_index]
if self.include_mask:
sample['masks'] = self.all_img_dict['masks'][use_index].to(device)
return sample然后打开 autodl-tmp/Color-NeuS/lib/datasets/__init__.py,并在文件中导入并注册新的数据集类,修改后的_init__.py如下:
from lib.utils.config import CN
from lib.utils.builder import build_dataset, DATASET, Registry # 添加 Registry
from .dtu import DTU
from .iho_video import IHO_VIDEO
from .omniobject3d import OmniObject3D
from .bmvs import BlendedMVS
from .zhiwu_dataset import ZhiwuDataset # 导入新数据集类
def create_dataset(cfg: CN, data_preset: CN):
"""
Create a dataset instance.
"""
return build_dataset(cfg, data_preset=data_preset)
# 注册新数据集
DATASET.register_module(name='zhiwu', module=ZhiwuDataset)然后由于修改了配置文件Color_NeuS_zhiwu.yml中的INCLUDE_MASK为False,那么就应该进行无掩码计算,需要修改训练代码autodl-tmp/Color-NeuS/lib/models/NeuS_Trainer.py中的 compute_loss 函数,使其在 include_mask 为 False 时跳过 mask_loss 的计算。此外还需要修改 render 函数,确保 render_dict['weight_sum'] 在没有掩码的情况下有合理的默认值。
下述为 compute_loss 函数修改后的结果:
def compute_loss(self, render_dict, **kwargs):
loss = 0
rgb_gt = render_dict['rgb_map_gt']
rgb_fine_render = render_dict['color_fine']
rgb_fine_loss = self.rgb_loss(rgb_fine_render, rgb_gt)
loss += self.lambda_fine * rgb_fine_loss
eikonal_loss = render_dict['gradient_error']
loss += self.lambda_eikonal * eikonal_loss
if self.include_mask and self.lambda_mask != 0:
mask_loss = F.binary_cross_entropy(render_dict['weight_sum'].squeeze().clip(1e-3, 1.0 - 1e-3),
render_dict['mask'])
loss += self.lambda_mask * mask_loss
if self.lambda_relight != 0:
if self.include_mask:
mask = render_dict['mask'].unsqueeze(-1)
if render_dict['delta_relight'].dim() == 3:
mask = mask.unsqueeze(-1)
delta_relight = render_dict['delta_relight'] * mask
else:
delta_relight = render_dict['delta_relight']
relight_loss = F.mse_loss(torch.mean(delta_relight),
torch.tensor(0, device=delta_relight.device, dtype=torch.float32))
loss += self.lambda_relight * relight_loss
loss_dict = {
'loss': loss,
'rgb_fine_loss': rgb_fine_loss,
'eikonal_loss': eikonal_loss,
}
if self.include_mask and self.lambda_mask != 0:
loss_dict['mask_loss'] = mask_loss
if self.lambda_relight != 0:
loss_dict['relight_loss'] = relight_loss
self.psnr_toshow = mse2psnr(rgb_fine_loss.detach().cpu()).item()
return loss, loss_dict下述为修改后的 render 函数:
def render(self, c2w, focal, image, img_id, step_idx, mask=None, **kwargs):
device = c2w.device
if self.mask_rate is not None:
mask_rate = self.mask_rate[0] + \
(self.mask_rate[1] - self.mask_rate[0]) * (step_idx / self.cfg.TRAIN.ITERATIONS)
else:
mask_rate = None
rays_o, rays_d, rgb_gt, mask_select = get_rays_multicam(
c2w=c2w,
focal=focal,
image=image,
n_rays=self.n_rays,
normalize=self.normalize_dir,
mask=mask,
mask_rate=mask_rate,
return_mask=True if self.include_mask else False,
opengl=self.opengl_sys,
)
rays_o = (rays_o - self.origin.detach().clone().to(device)).float()
rays_o = (rays_o / self.radius.detach().clone().to(device)).float()
near, far = near_far_from_sphere(rays_o, rays_d)
render_output = self.renderer(rays_o, rays_d, near, far)
render_output['rgb_map_gt'] = rgb_gt
render_output['mask'] = mask_select if self.include_mask else torch.ones_like(rgb_gt[..., :1])
return render_output由于修改了代码和相关的配置文件,该项目的代码要求开始实验之前,必须进行 Git 提交,运行下述命令:
git config --global user.email 2452839033@qq.com git config --global user.name XSL316 git add . git commit -m "Commit before running the experiment"
运行下述训练命令,训练大叶植物数据集:
python train.py -g 0 --cfg config/Color_NeuS_zhiwu.yml -obj dayezhiwu --exp_id Color_NeuS_zhiwu_dayezhiwu
经过上述一系列操作,有以下输出信息,代表训练成功:
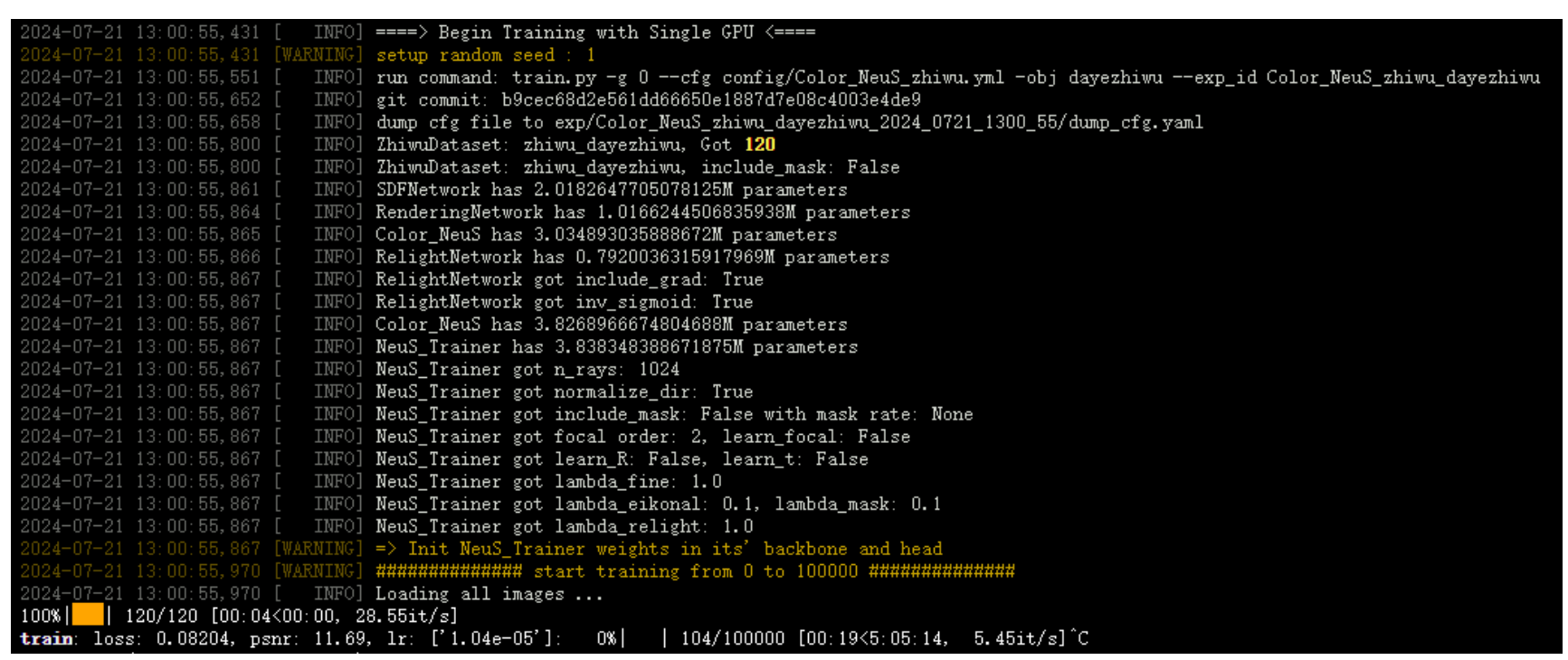
训练完之后,运行下述命令进行评估:
python evaluation.py -g 0 --cfg config/Color_NeuS_zhiwu.yml -obj dayezhiwu -rr 1024 --reload exp/Color_NeuS_zhiwu_dayezhiwu_2024_0720_2033_12/checkpoints/checkpoint_100001/NeuS_Trainer.pth.tar
效果:

6、在color-Neus上训练衣服数据集
由于之前未在Neus上跑过服装数据集,因此需要用之前跑Neus的环境先对服装数据集进行预处理,预处理的步骤如上,这里就不再赘述。
上述预处理的步骤都是之前跑Neus记录的,按照上述的步骤预处理服装数据集,然后存于autodl-tmp/Color-NeuS/data/Fuzhuang目录下,且服装数据集前面都要加个fuhzuang和下划线(代码中规定):
最后需要到目录autodl-tmp/Color-NeuS/config下创建一个名为Color_NeuS_fuzhuang.yml的文件,该文件内容模拟了Color_NeuS_bmvs.yml的内容,因为两个数据集结构类似,下述是Color_NeuS_fuzhuang.yml的内容:
DATASET:
TYPE: FuzhuangDataset
DATA_ROOT: ./data
DATA_PRESET:
FX_ONLY: False
INCLUDE_MASK: True # 服装数据集里面自带掩码,所以跑的有掩码的代码
OPENGL_SYS: False
MODEL:
TYPE: NeuS_Trainer
PRETRAINED: null
N_RAYS: 1024
EVAL_RAY_SIZE: 1024
NORMALIZE_DIR: True
FOCAL_ORDER: 2
LEARN_FOCAL: False
LEARN_R: False
LEARN_T: False
MASK_RATE: [0.5, 0.8]
POSE_MODE: 6d
RENDERER:
TYPE: Color_NeuS
N_SAMPLES: 64
N_IMPORTANCE: 64
UP_SAMPLE_STEPS: 4
PERTURB: 1.0
SDF:
D_IN: 3
D_OUT: 257
D_HIDDEN: 256
N_LAYERS: 8
SKIP_IN: [4]
MULTIRES: 6
BIAS: 0.5
SCALE: 3.0
GEOMETRIC_INIT: True
WEIGHT_NORM: True
INSIDE_OUTSIDE: False
COLOR:
D_FEATURE: 256
MODE: no_view_dir
D_IN: 6
D_OUT: 3
D_HIDDEN: 256
N_LAYERS: 4
WEIGHT_NORM: True
MULTIRES_VIEW: 0
SQUEEZE_OUT: True
RELIGHT:
D_IN: 6
D_OUT: 3
D_HIDDEN: 256
N_LAYERS: 4
Y_IN_LAYER: 3
MULTIRES_VIEW: 4
INCLUDE_GRAD: True
INV_SIGMOID: True
DEVIATION:
INIT_VAL: 0.3
LOSS:
RGB_LOSS_TYPE: mse
LAMBDA_FINE: 1.0
LAMBDA_EIKONAL: 0.1
LAMBDA_MASK: 0.1
LAMBDA_RELIGHT: 1.0
TRAIN:
BATCH_SIZE: 8
ITERATIONS: 100000
OPTIMIZE:
TYPE: adam
LR: 0.0005
SCHEDULER_TYPE: NEUS
WARM_UP: 5000
LR_ALPHA: 0.05
LOG_INTERVAL: 10
SAVE_INTERVAL: 10000
VIZ_IMAGE_INTERVAL: 10000
VIZ_MESH_INTERVAL: 10000
MANUAL_SEED: 1
CONV_REPEATABLE: True
GRAD_CLIP_ENABLED: True
GRAD_CLIP:
TYPE: 2
NORM: 1.0又由于配置文件Color_NeuS_fuzhuang.yml中指定的数据集类型fuzhuang未注册到数据集注册表中,需要在代码中注册这个数据集,找到服装数据集注册的相关代码文件,通常在lib/datasets/__init__.py或lib/utils/builder.py中,然后添加服装数据集。
首先创建一个新的数据集类 FuzhuangDataset ,并将其放入 autodl-tmp/Color-NeuS/lib/datasets/fuzhuang_dataset.py(fuzhuang_dataset.py为自己创建)中,如下:
import os
import cv2
import imageio
import torch
import numpy as np
import torchvision.transforms.functional as tvF
from termcolor import colored
from lib.utils.builder import DATASET
from lib.utils.etqdm import etqdm
from lib.utils.logger import logger
from lib.utils.transform import load_K_Rt_from_P
@DATASET.register_module()
class FuzhuangDataset(torch.utils.data.Dataset):
def __init__(self, cfg) -> None:
super().__init__()
self.name = type(self).__name__
self.cfg = cfg
self.std = 0.5
self.data_root = cfg.DATA_ROOT
self.obj_id = cfg.OBJ_ID
self.fx_only = cfg.DATA_PRESET.get('FX_ONLY', False)
self.include_mask = cfg.DATA_PRESET.get('INCLUDE_MASK', True)
self.opengl_sys = cfg.DATA_PRESET.get('OPENGL_SYS', False)
self.data_path = os.path.join(self.data_root, 'Fuzhuang', f"fuzhuang_{self.obj_id}")
self.img_dir = os.path.join(self.data_path, 'image')
self.mask_dir = os.path.join(self.data_path, 'mask')
self.camera_path = os.path.join(self.data_path, 'cameras_sphere.npz')
images = sorted(os.listdir(self.img_dir))
self.image_paths = []
self.img_ids = []
for i in range(len(images)):
self.image_paths.append(os.path.join(self.img_dir, images[i]))
self.img_ids.append(torch.tensor([i]))
if self.include_mask:
masks = sorted(os.listdir(self.mask_dir))
if len(images) != len(masks):
raise ValueError(f"Number of images ({len(images)}) does not match number of masks ({len(masks)}).")
self.mask_paths = []
for i in range(len(masks)):
self.mask_paths.append(os.path.join(self.mask_dir, masks[i]))
self.img_ids = torch.cat(self.img_ids, dim=0)
self.n_imgs = len(self.image_paths)
self.origin = torch.tensor([0, 0, 0], dtype=torch.float32)
self.radius = torch.tensor(1, dtype=torch.float32)
if self.opengl_sys:
_coord_trans_OpenGL = np.array(
[
[1, 0, 0, 0],
[0, -1, 0, 0],
[0, 0, -1, 0],
[0, 0, 0, 1],
],
dtype=np.float32,
)
camera_dict = np.load(self.camera_path)
self.camera_dict = camera_dict
self.world_mats_np = []
self.scale_mats_np = []
for idx in range(self.n_imgs):
world_mat_key = f'world_mat_{idx}'
scale_mat_key = f'scale_mat_{idx}'
if world_mat_key in camera_dict and scale_mat_key in camera_dict:
self.world_mats_np.append(camera_dict[world_mat_key].astype(np.float32))
self.scale_mats_np.append(camera_dict[scale_mat_key].astype(np.float32))
else:
logger.warning(f"Missing keys for index {idx}: {world_mat_key} or {scale_mat_key}")
self.intrinsics_all = []
self.poses = []
for scale_mat, world_mat in zip(self.scale_mats_np, self.world_mats_np):
P = world_mat @ scale_mat
P = P[:3, :4]
intrinsics, pose = load_K_Rt_from_P(None, P)
self.intrinsics_all.append(intrinsics)
if self.opengl_sys:
pose = _coord_trans_OpenGL @ pose
self.poses.append(torch.from_numpy(pose).float())
if self.fx_only:
self.focal = np.array([self.intrinsics_all[0][0, 0]], dtype=np.float32)
else:
self.focal = np.array([self.intrinsics_all[0][0, 0], self.intrinsics_all[0][1, 1]], dtype=np.float32)
object_bbox_min = np.array([-1.01, -1.01, -1.01, 1.0])
object_bbox_max = np.array([1.01, 1.01, 1.01, 1.0])
object_scale_mat = np.load(self.camera_path)['scale_mat_0']
object_bbox_min = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_min[:, None]
object_bbox_max = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_max[:, None]
self.object_bbox_min = object_bbox_min[:3, 0]
self.object_bbox_max = object_bbox_max[:3, 0]
logger.info(f"{self.name}: fuzhuang_{self.obj_id}, Got {colored(self.n_imgs, 'yellow', attrs=['bold'])}")
logger.info(f"{self.name}: fuzhuang_{self.obj_id}, include_mask: {self.include_mask}")
def __len__(self):
return self.n_imgs
def get_image(self, idx):
path = self.image_paths[idx]
png = cv2.imread(path, cv2.IMREAD_UNCHANGED)
if png is None:
logger.error(f"Failed to read image from path: {path}")
raise ValueError(f"Image at path {path} is not readable or does not exist.")
image = png[:, :, :3].copy()
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = tvF.to_tensor(image)
assert image.shape[0] == 3
image = tvF.normalize(image, [0.5, 0.5, 0.5], [self.std, self.std, self.std])
image = image * 0.5 + 0.5 # [3, H, W] 0~1
if self.include_mask:
mask_path = self.mask_paths[idx]
mask = np.array(imageio.imread(mask_path, as_gray=True), dtype=np.uint8)
mask = tvF.to_tensor(mask).squeeze() # [H, W] 0 or 1
image = image * mask.unsqueeze(0)
return image, mask
else:
return image, None
def __getitem__(self, idx):
sample = {}
sample['pose'] = self.poses[idx]
sample['img_id'] = self.img_ids[idx]
if self.include_mask:
sample['image'], sample['mask'] = self.get_image(idx)
else:
sample['image'], _ = self.get_image(idx)
return sample
def get_init_data(self):
tmp_img, _ = self.get_image(0)
return {
'poses': torch.stack(self.poses, dim=0),
'focal': self.focal,
'H': tmp_img.shape[-2],
'W': tmp_img.shape[-1],
'n_imgs': self.n_imgs,
'origin': self.origin,
'radius': self.radius,
'scale_mats_np': self.scale_mats_np,
'object_bbox_min': self.object_bbox_min,
'object_bbox_max': self.object_bbox_max
}
def get_all_img(self):
logger.info("Loading all images ...")
all_img = []
if self.include_mask:
all_mask = []
for i in etqdm(range(self.n_imgs)):
img, mask = self.get_image(i)
all_img.append(img)
all_mask.append(mask)
all_mask = torch.stack(all_mask, dim=0)
else:
all_mask = None
for i in etqdm(range(self.n_imgs)):
img, _ = self.get_image(i)
all_img.append(img)
return {'images': torch.stack(all_img, dim=0), 'masks': all_mask, 'img_ids': self.img_ids}
def get_all_init(self, batch_size):
self.all_img_dict = self.get_all_img()
self.batch_size = batch_size
def get_rand_batch_smaples(self, device):
sample = {}
rand_index = torch.randperm(self.n_imgs)
use_index = rand_index[:self.batch_size]
sample['images'] = self.all_img_dict['images'][use_index].to(device)
sample['img_ids'] = self.img_ids[use_index]
if self.include_mask:
sample['masks'] = self.all_img_dict['masks'][use_index].to(device)
return sample然后打开 autodl-tmp/Color-NeuS/lib/datasets/__init__.py,并在文件中导入并注册新的数据集类,修改后的_init__.py如下:
from lib.utils.config import CN from ..utils.builder import build_dataset from .dtu import DTU from .iho_video import IHO_VIDEO from .omniobject3d import OmniObject3D from .bmvs import BlendedMVS from .fuzhuang_dataset import FuzhuangDataset # 添加这一行 def create_dataset(cfg: CN, data_preset: CN): """ Create a dataset instance. """ return build_dataset(cfg, data_preset=data_preset)
由于服装数据集自带掩码图片,因此进行有掩码的计算,不需要对训练代码autodl-tmp/Color-NeuS/lib/models/NeuS_Trainer.py中的 compute_loss 函数和 render 函数进行修改。
由于修改了代码和相关的配置文件,该项目的代码要求开始实验之前,必须进行 Git 提交,运行下述命令:
git config --global user.email 2452839033@qq.com git config --global user.name XSL316 git add . git commit -m "Commit before running the experiment"
运行下述训练命令训练服装320数据集:
python train.py -g 0 --cfg config/Color_NeuS_fuzhuang.yml -obj 320 --exp_id Color_NeuS_fuzhuang_320
经过上述一系列操作,有以下输出信息,代表训练成功:
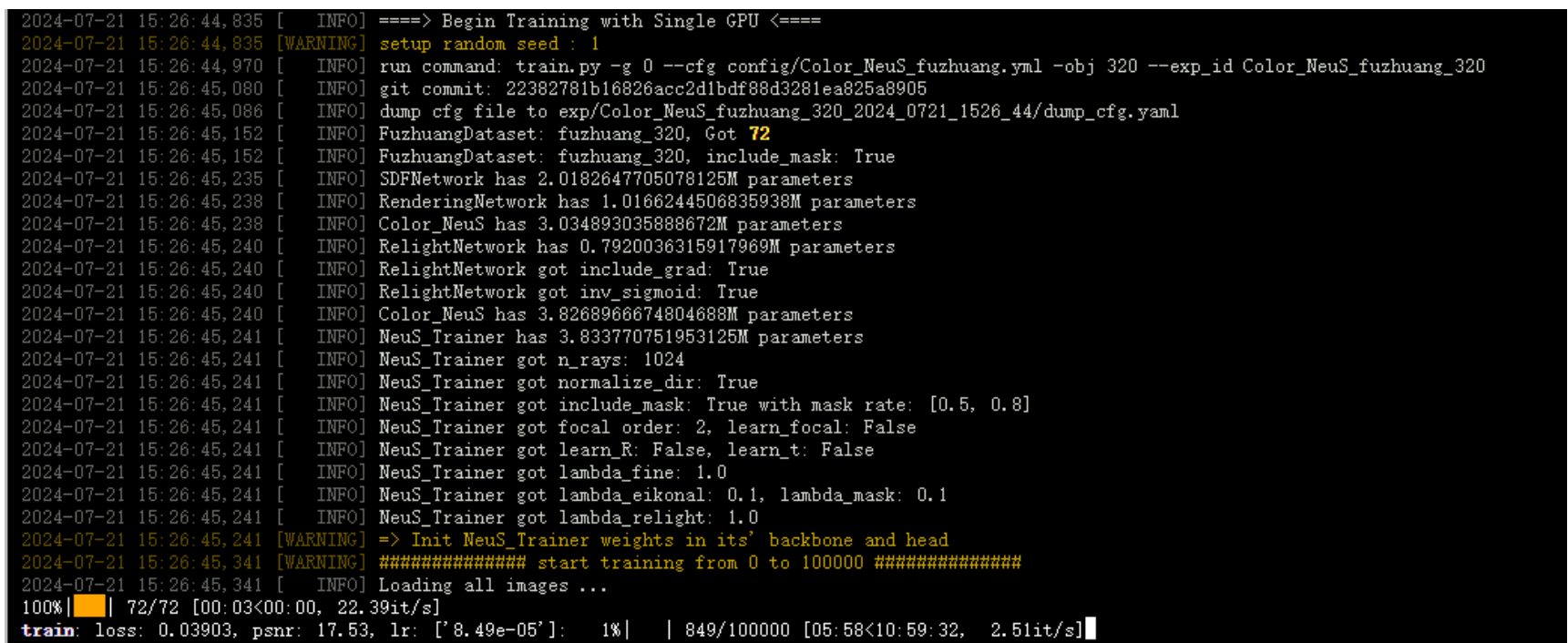
训练完之后,运行下述命令进行评估:
python evaluation.py -g 0 --cfg config/Color_NeuS_fuzhuang.yml -obj 320 -rr 1024 --reload exp/Color_NeuS_zhiwu_dayezhiwu_2024_0720_2033_12/checkpoints/checkpoint_100001/NeuS_Trainer.pth.tar
效果:

7、在color-Neus上训练IHO_Video数据集
在autodl-tmp/Color-NeuS/data目录中上传IHO_Video数据集(这里我只上传了pink_peach一个数据集):
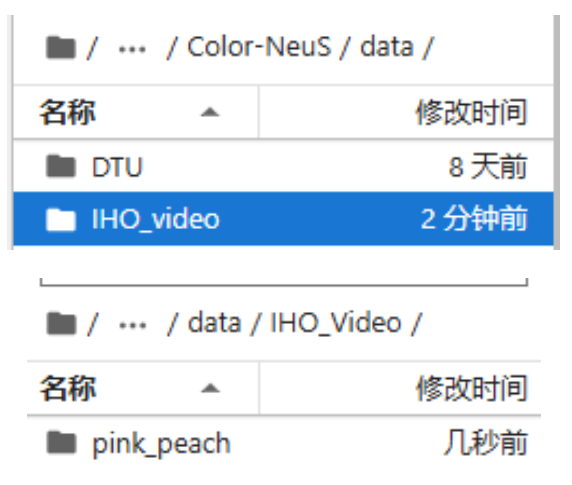
以下是训练命令:
# IHO Video: pink_peach python train.py -g 0 --cfg config/Color_NeuS_iho.yml -obj pink_peach --exp_id Color_NeuS_iho_pink_peach
所有训练结果都保存在exp/${EXP_ID}_{timestamp}/。
所有训练检查点都保存在exp/${EXP_ID}_{timestamp}/checkpoints/。
该项目还提供了Neus的实现,要训练 NeuS,可以在上面的命令行中替换为 :
# IHO Video: pink_peach python train.py -g 0 --cfg config/NeuS_dtu.yml -obj pink_peach --exp_id Color_NeuS_iho_pink_peach
4、评估
以下是评估的命令,其中${DATASET}、${OBJECT_NAME}设置为和上面训练命令一样的值;设置${PATH_TO_CHECKPOINT}为要加载的检查点的路径:
cd autodl-tmp/Color-NeuS
#评估命令
python evaluation.py -g 0 --cfg config/Color_NeuS_${DATASET}.yml -obj ${OBJECT_NAME} -rr 512 --reload ${PATH_TO_CHECKPOINT}
#例子
python evaluation.py -g 0 --cfg config/Color_NeuS_iho.yml -obj pink_peach -rr 1024 --reload exp/Color_NeuS_iho_pink_peach_{timestamp}/checkpoints/checkpoint_100001/NeuS_Trainer.pth.tar
其中-rr,(--recon_res)是重构网格的分辨率,默认值为 512。
所有评估结果都保存在exp/eval_Color_NeuS_dtu_65_{timestamp}/。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)