关于一次在离线环境(内网)下使用dify切换大模型的经历
兄弟们,坑已躺完,你们冲!!(不明之处+Q: 451560242)
1、背景
三月份的时候,deepseek快速成为AI行业的热点,由于国产化、开源等先天优势,企事业单位本地化部署deepseek一度成功各地宣传热点😂。为了赶这个时髦,我们也部署了一套。
当时的方案是deepseek+ragFlow+dify,实现本地知识库。其中deepseek采用的是xinference(ollama只是玩具,不适合实际使用。xinference的优缺点可以网上查)部署的14b模型(两块4090的卡),通过vllm架构运行(Transformer效率太低)。实施的时候,先通过互联网把模型、插件、环境安装好,再离线(转内网,后也不能再连互联网,why?,不解释,懂的都懂😃)制作知识库、发布智能体。
该方案一路顺畅,用户体验效果也蛮好(40+用户,人均token能做到30+/s)。所以,打算做知识库、智能体,但还没启动的可以参考此方案。
2、新需求
时间来到五月份,大模型领域阿里发力,开源版qwen3隆重上线,号称吊大其他开源,包括部分商业模型,加之其支持工具调用,想想通过一个模型既能实现知识库,又能支持MCP就很激动,尤其是能落地实际应用(打算尝试对已有业务系统进行“智能化升级”,通过MCP实现智能语言操作、查询、统计、分析、预测),赶紧尝鲜了。
3、问题
3.1、离线模式下咋更换模型
通过xinference部署大模型的一个好处是:xinference官方会推一些流行的模型到系统界面,官方能查询到的模型用户可以在线下载安装,对于官方没有的,也支持自定义,相当方便。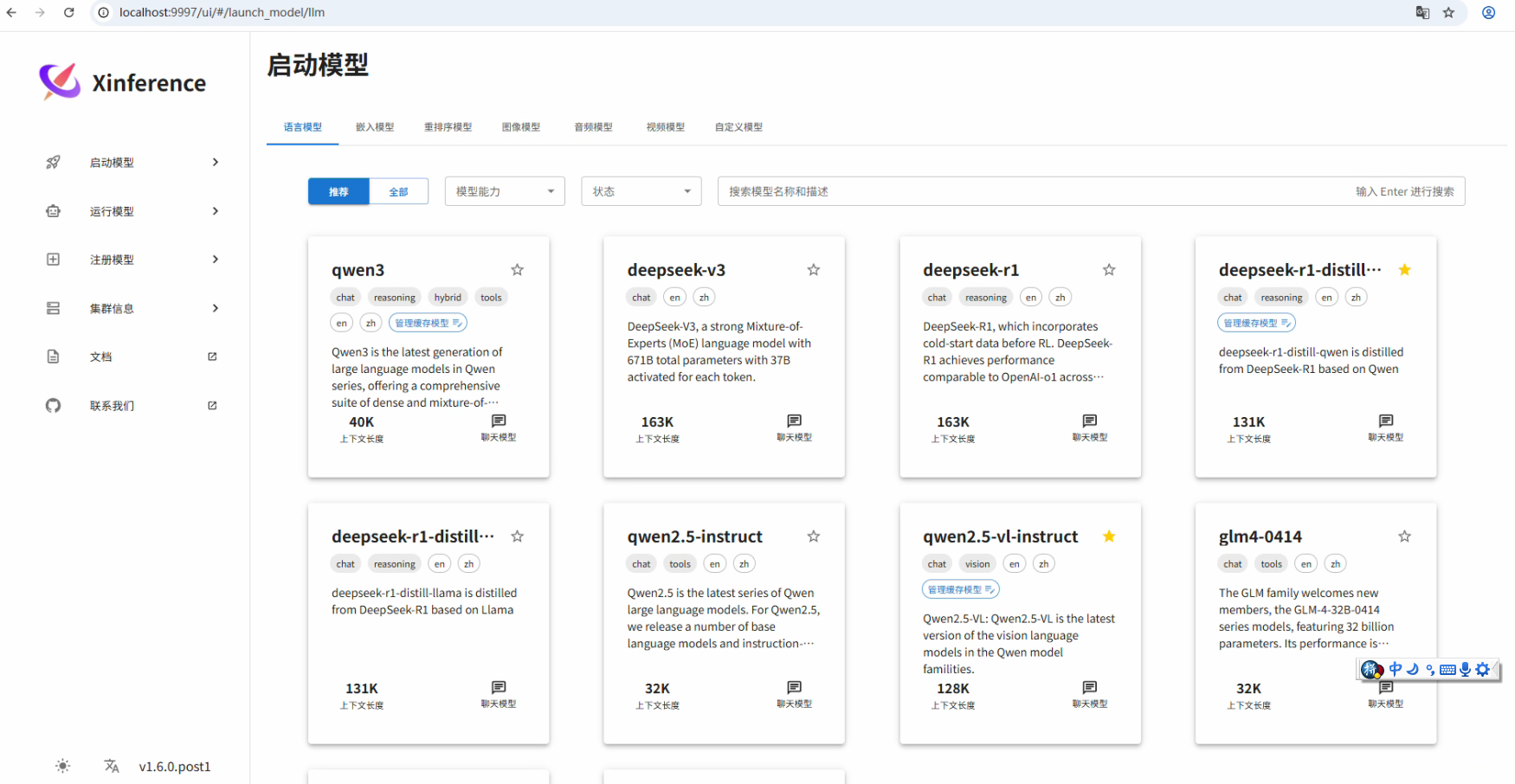
不足是:官方推的模型一般会慢几周、可选的版本有不多,且自定义要求很苛刻。
结合实际运行需要,所以选择了vllm框架进行部署,qwen3选用的是qwen3-30B-A3B-AWQ int4 量化版(两块4090,和官方说明能支持的版本差距比较大😂,大佬可以指点下。地址可以去魔搭社区下载https://modelscope.cn/models/cognitivecomputations/Qwen3-30B-A3B-AWQ。
部署过程是,下载vllm框架(docker镜像)、qwen3-30B-A3B-AWQ模型拷贝到内网,再docker上安装vllm框架,通过vllm运行qwen3-30B-A3B-AWQ,运行命令可以参考如下:
docker run -d --runtime nvidia --gpus all --ipc=host -p 8000:8000 -v /xinference/data/model:/root/models -e "PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128" --name=Qwen3-30B-A3B-AWQ vllm:latest --model /root/models/Qwen3-30B-A3B-AWQ --trust-remote-code --served-model-name Qwen3-30B-A3B-AWQ --tensor-parallel-size 1 --gpu_memory_utilization 0.95 --enforce-eager --disable-custom-all-reduce --enable-auto-tool-choice --tool-call-parser hermes --compilation-config 0 --enable-reasoning --reasoning-parser deepseek_r1
注:运行的时候可能会碰到 **“invalid diffID for layer 19: expected”**的错误(通过其他电脑导出的image都会出现),这个时候i就需要修改镜像文件了,解决方法可以参考知乎上的一篇文章https://zhuanlan.zhihu.com/p/30724080310,有几层改几层,直到运行不报错。测试代码如下:
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Qwen3-30B-A3B-AWQ",
"messages": [
{"role": "user", "content": "介绍一下你自己"}
],
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"max_tokens": 128,
"presence_penalty": 1.5,
"chat_template_kwargs": {"enable_thinking": false}
}'
正常输出回答即为模型运行正常。
3.2、离线模式下咋升级dify插件
看到标题就应该知道,本“旅途”并没到达目的地。dify和coze应用场景基本相同,相关功能也差不多,优势是开源,支持内网部署,💕。
可能当前的生态还不成熟,dify离线安装插件并不是很方便,应该说很不方便,希望官方后面能优化下。下面讲讲碰到的问题及如何解决的。
我们原来安装的是1.0版本,且已经预先安装了xinference模型插件(转内网前),现在需要指出vllm框架,需要安装对应的支撑插件。。。。经过查询有两款支持: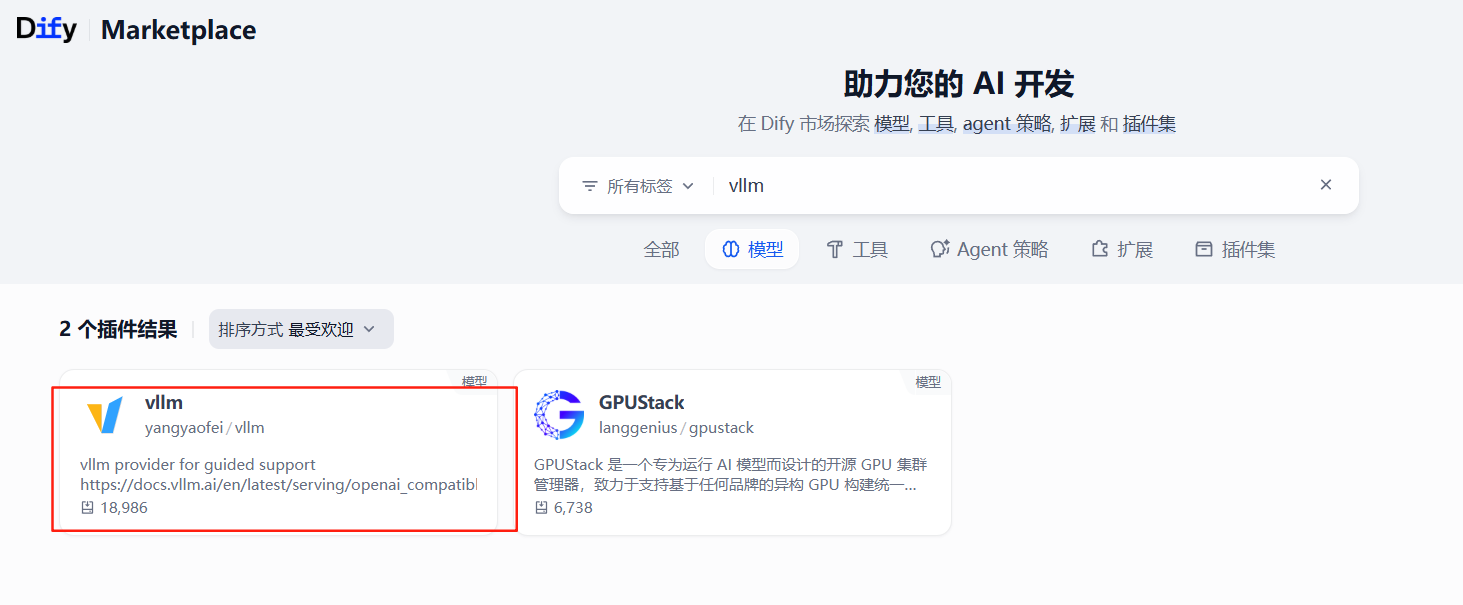
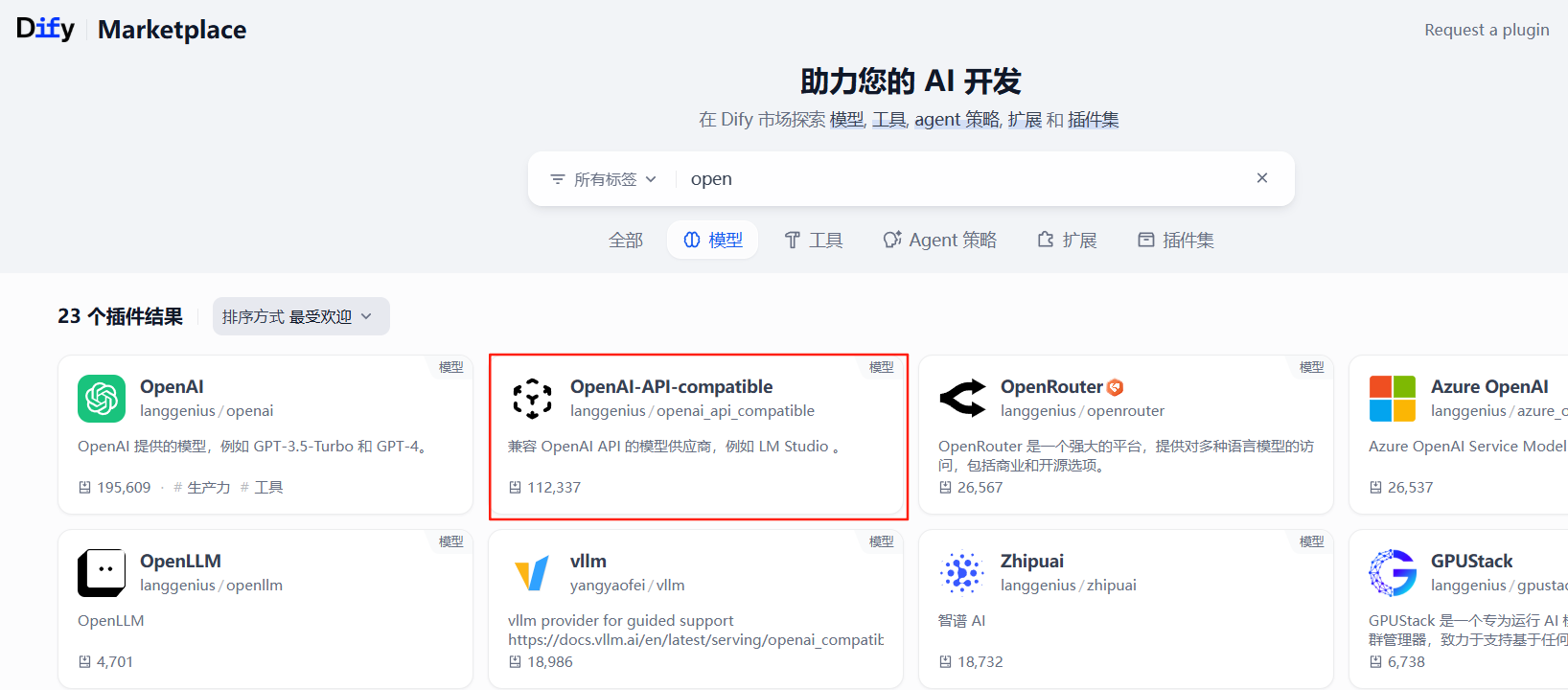
我们只能离线下载,拷贝到内网安装。(显然,如果这就成功了,那也不称为问题了)。
安装过程中(本地安装),从界面上看,第一次会安装很久,然后显示失败,再次安装,会显示安装成功。
查看后台日志,实际并没有成功,且服务一直报错。。。。。(这里记得最好删除该插件,避免影响服务,也为了下次成功安装)。
网上查了下https://blog.csdn.net/qq_32113055/article/details/148010759,说是需要用dify-plugin-repackaging进行打包,按照博客要求进行尝试,应该马上要成功了吧😂,然并卵。。。
这里还会出现两个问题,
(1)打包不上,提示找不到对应的包。——原因,你的python版本太低了,升级下。
(2).env没有,没法修改——有,只是没显示,可以先用mv修改下名字例如1.env,改完参数后再改回去。
到此,成功安装支持vllm的插件。。。✌
3.3、其他
应该没有问题了吧?,这里还有一个“其他”,是的,模型能用了,也不完全能用。通过dify调用模型,能成功回复,但每次都会报“Connection to openaipublic.blob.core.windows.net timed out.”错误,且会话不能连续,否则,回复失败。这里可以参考这篇文章
https://blog.csdn.net/weixin_42307664/article/details/146563797
记得.tiktoken_cache的修改方式和上面一样。
4、结语
兄弟们,坑已躺完,你们冲!!(不明之处+Q: 451560242)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 52
52 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)