AIGC工具平台-CosyVoice多语言语音合成
摘要: CosyVoice提供一站式多语言语音合成解决方案,整合诊断、训练、推理与可视化功能,简化本地部署流程。其模块化设计包含GPU检测、Web UI启动、音频管理及参数调节等功能,支持SFT、零样本等多种推理模式。用户可通过图形界面快速配置文本、情感、语种及参考音频,实现音色融合与风格控制。但当前版本缺乏音频预处理和实时反馈,建议未来解耦前后端、优化API接口并增强交互体验以提升稳定性和扩展性
CosyVoice 为多语言语音合成提供了一站式解决方案,集成诊断、训练、推理与可视化交互于同一整合包,用户无需繁琐环境配置即可启动模型服务并体验多种合成模式。
本文将解析 CosyVoice 模块中的脚本配置逻辑与功能分区,重点剖析 GPU 检测、Web UI 启动、参考音频管理与参数调节等核心流程,帮助自学者快速掌握本地部署与可视化操作方法。
操作使用
进入软件后在 整合包 里可以直接搜索 CosyVoice 进入该模块。
点击【下载选项卡】可获取完整项目整合包的下载地址,或直接使用下方链接下载。将文件保存至项目目录下后,点击解压按钮,等待解压完成即可开始使用。
| - | 说明 |
|---|---|
| 源码使用教程 | 基于CosyVoice的多语言语音合成 |
| 整合包下载地址 | 基于CosyVoice的多语言语音合成 |
项目脚本配置
通过 Gradio 或其他本地可视化工具提供图形化界面,用户可上传视频与音频并实时查看唇形同步效果,适合在本地测试与调整模型效果。只需运行脚本,待界面加载完成后即可在浏览器中访问操作界面,无需手动配置环境或命令行调用。
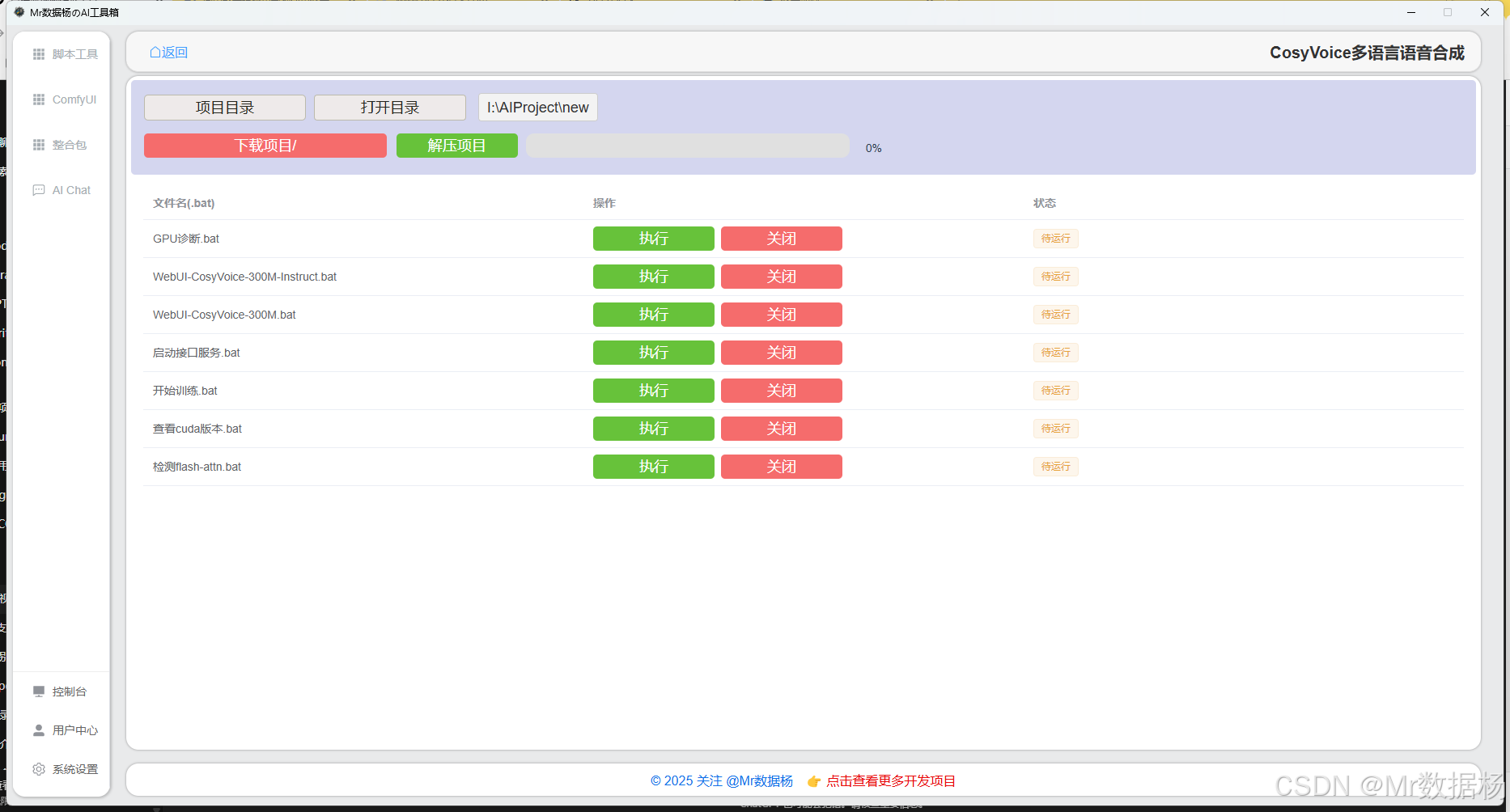
| 脚本名称 | 功能说明 |
|---|---|
GPU诊断.bat |
检测本机是否正确识别到 NVIDIA 显卡及其 CUDA 驱动状态,便于判断是否支持推理或训练环境 |
WebUI-CosyVoice-300M.bat |
启动 CosyVoice 300M 模型的 Web UI 可视化界面,支持标准语音合成与语者控制交互 |
WebUI-CosyVoice-300M-Instruct.bat |
启动带有 Instruct 控制指令支持的 Web UI 界面,适合以提示词方式控制风格与情绪等合成参数 |
查看cuda版本.bat |
输出当前系统安装的 CUDA 版本信息,确保与模型运行要求兼容 |
检测flash-attn.bat |
检查是否已成功安装 flash-attn 加速库,该组件可显著提升多头注意力模块的推理速度 |
开始训练.bat |
启动训练流程脚本,自动加载配置文件、数据路径并执行训练逻辑,适合已有数据集情况下开始微调模型 |
启动接口服务.bat |
启动后端推理 API 服务(为 Flask 或 FastAPI),用于外部调用模型生成音频数据 |
应用示例
可以使用Web演示页面快速熟悉CosyVoice。在Web演示中支持SFT、零样本、跨语言和指令式推理。有关详细信息,请访问演示网站。
# 运行Web演示页面以支持不同的推理模式
# 使用 "speech_tts/CosyVoice-300M-SFT" 进行SFT推理,或 "speech_tts/CosyVoice-300M-Instruct" 进行指令式推理
python3 webui.py --port 9886 --model_dir ./pretrained_models/CosyVoice-300M
该命令将启动Web用户界面,监听端口9886,并加载存储在./pretrained_models/CosyVoice-300M中的预训练模型。在Web界面中,用户可以在不同模式间切换,以体验CosyVoice的各项推理功能。在浏览器中访问 http://localhost:9886。

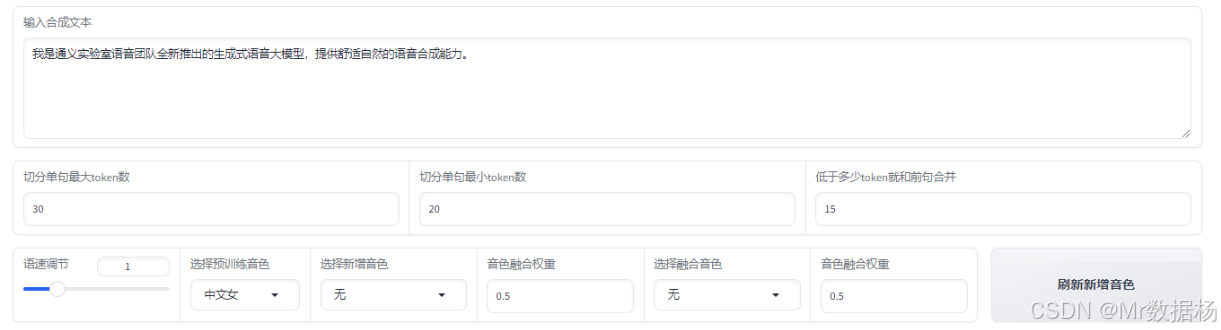
文本与语音参数配置区
用于输入要合成的文本及调整语音合成相关参数,包括音色融合、角色设定与节奏控制,是整个页面的核心配置区域。
| 模块名称 | 功能说明 |
|---|---|
| 输入合成文本 | 填写需要转换成语音的内容,支持多句文本。 |
| 保存步数token相邻的联合阈值 | 控制语音生成中步长 token 的合并敏感度。 |
| 保存步数token采样步数 | 设置生成时的 token 采样范围,影响发音节奏。 |
| 情感设置 | 控制语音的情感类型(如平静、激动)。 |
| 选择说话角色 | 选择预设说话人音色或语者模型。 |
| 角色融合权重 | 控制主/辅音色混合程度,值越高偏向主音色。 |
| 重新加载角色 | 强制刷新当前角色参数,避免加载不完整。 |
语言模式与合成策略区
主要负责语种选择、语音合成方式设定(如预训练、3-shot、指令控制),以及参考音频调用方式,是影响语音风格与质量的关键区块。

| 模块名称 | 功能说明 |
|---|---|
| 语种选择 | 设定语音输出的语言类型,支持中英文。 |
| 语言模式切换 | 选择语音合成模式,如 zero-shot、预训练等。 |
| 参考音频上传方式 | 设定参考音频的使用方式,支持单次或持久调用。 |
| 加载参考音频按钮 | 将上传音频绑定为当前语音风格模板。 |
文件上传与角色管理区
用于上传参考音频、配置文件或调用预训练角色向量,实现快速加载与角色复用,是进行声音拟合与指令风格迁移的入口区域。

| 模块名称 | 功能说明 |
|---|---|
| 上传参考音频文件 | 导入本地音频作为语音风格参考源。 |
| 上传 config 配置文件 | 加载自定义模型或角色配置参数。 |
| 选择角色向量 / STAR语者 | 快速调用公开角色音色向量或明星语者数据。 |
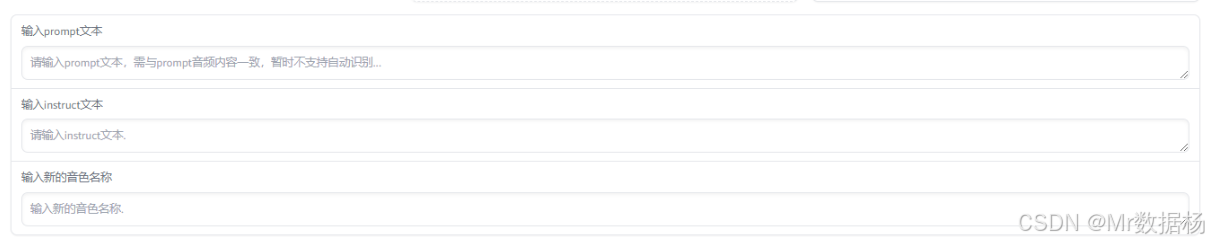
Prompt 与 Instruct 引导输入区
支持通过 prompt 或 instruct 风格文本指导模型调整语气、语境或表达方式,是实现情景引导或对话式风格合成的核心区域。
| 模块名称 | 功能说明 |
|---|---|
| 输入 Prompt 文本 | 设定背景或语境提示,用于语音语气引导。 |
| 输入 Instruct 文本 | 使用指令式语言控制语音风格(适用于 instruct 模型)。 |
| 输入角色的自定义名称 | 命名当前角色配置,便于管理与保存。 |
执行与预览模块
控制语音生成过程,包括试听预览、正式输出与播放器操作,也是最终语音合成与回放的控制区域。

| 模块名称 | 功能说明 |
|---|---|
| 保存推理角色 zero-shot 音色 | 将当前参考音频保存为角色,供后续复用。 |
| 生成预览音频 | 快速输出语音片段用于试听调整。 |
| 正式生成 | 生成最终语音结果,保存到本地或输出目录。 |
| 播放器区 | 显示音频波形并提供播放、暂停、音量调节等功能。 |
总结部分
CosyVoice 模块通过整合包形式将多语言语音合成、模型诊断与推理流程封装为一键部署体验,脚本配置涵盖显卡检测、训练启动、Web UI 调用与后端接口服务,分区式的界面设计令文本输入、情感控制与参考音频管理各司其职。该设计在简化环境依赖与提升本地测试效率方面表现突出,但对输入文本与参考音频的质量无预处理机制支持,合成稳定性易受噪音影响,界面交互虽直观却缺少实时渲染反馈与自定义扩展入口。
若重构该模块,可将前端界面与后端推理服务以 API 形式解耦,前端引入状态管理与动态渲染框架,实现参数调节后即时效果预览;后端提供标准化 RESTful 接口,并内置音频预处理与质量评估流程以提升合成稳定性,同时开放插件机制以便日后扩展多模型或定制功能。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 26
26 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)