「大模型学习」(10)LLM的量化(GPTQ、LLM.int8()、AWQ)不信你学不会!
本文介绍了神经网络模型量化技术及其应用。量化通过降低模型精度(如INT8/INT4)来减少存储和计算开销,提升推理速度。量化对模型精度影响较小的原因包括权重归一化、激活函数平滑误差以及分类任务对绝对值不敏感。文中对比了两种量化方法:PTQ(后训练量化)和QAT(量化感知训练),重点讲解了PTQ的四种代表性方法:ZeroQuant(块级重构与混合精度量化)、LLM.int8()(混合精度处理激活离群
前言
-
为什么要做量化?
- 减少模型的存储空间和显存的占用。
- 在显卡中,数据从HBM中加载到Tensor Core中计算,计算速度受限于数据加载的速度。通过对模型进行量化,减少HBM和Tensor Core之间的数值传输量,从而加快模型推理时间。
- 显卡对整数运算速度快于浮点型数据,从而加快模型推理时间。
-
为什么量化对神经网络精度影响不大?
1.权重和输入经过归一化,数值范围较小
➤ 通常神经网络训练后会对输入和权重做标准化(Normalization),避免极端值,使得量化误差变小。2.激活函数平滑误差影响
➤ 比如 ReLU、GELU 等非线性激活函数会压制或滤除部分噪声,量化带来的误差可能被自然平滑掉。3.分类任务对绝对值不敏感
➤ 多数神经网络用于分类任务,只要“正确类别”的输出概率比其他类别高即可,不需要特别精确的数值。
PTQ 和 QAT
流程
大模型INT8量化推理全流程解析
整个流程可以看作是将模型从“高精度模式”切换到“高性能模式”的转换与计算过程。
第1步:准备阶段
在推理开始之前,模型已经经过了量化预处理:
- 训练后量化(Post-Training Quantization, PTQ):在一个有代表性的数据集上分析模型中每一层权重和激活值的分布范围,为每一层确定合适的缩放因子(Scale) 和零点(Zero Point)。
- 量化感知训练(Quantization-Aware Training, QAT):在模型训练时就模拟量化的过程,让模型“提前适应”低精度计算,通常能获得更高的精度。
经过此步骤,原始的FP32(高精度浮点数)模型权重被转换成了INT8格式。
第2步:INT8推理计算流程
现在,我们按照您图片中的箭头方向,来看一次完整的推理计算:
-
int8输入 (Input)
- 是什么:模型的输入数据(例如一张图片、一段语音),已经从原始的FP32格式被量化成了INT8格式。
- 为什么:INT8数据体积更小,传输到计算单元的速度更快,占用内存更少。
-
int8权重 (Weights)
- 是什么:模型训练好的参数,已经预先从FP32转换并存储为INT8格式。
- 为什么:INT8权重占用的内存带宽仅为FP32的1/4,可以极大减少从内存中读取权重的时间,这是加速的关键。
-
int8计算 (Calculation)
- 是什么:这是核心计算环节。硬件(如CPU、GPU、NPU)的专用指令集(如Intel的VNNI、ARM的Dot Product)会高效地执行INT8输入和INT8权重的乘加运算(MAC Operations)。
- 为什么:硬件对INT8运算有极度优化,一次操作能处理的数据量是FP32的4倍,速度极快、能效极高。
-
反量化 + 量化 (Dequantization + Quantization) - 【最关键的一步】
- 为什么需要:这是您上一个问题的核心。纯粹在INT8下连续计算会导致误差累积,最终结果失真。必须引入高精度计算来“校准”。
- 发生了什么:
- 反量化 (Dequantize):将上一步INT8计算得到的中间结果,转换回高精度(如FP32或INT32)。公式通常是:
FP32_value = INT8_value * Scale + Zero_Point。 - 高精度处理:在FP32精度下执行一些非线性操作,如激活函数(ReLU, Sigmoid)、归一化LayerNorm等。这些操作在低精度下误差很大,必须在高精度下进行。
- 再量化 (Quantize):将高精度处理后的结果,再次转换回INT8格式。公式是:
INT8_value = round(FP32_value / Scale) + Zero_Point。
- 反量化 (Dequantize):将上一步INT8计算得到的中间结果,转换回高精度(如FP32或INT32)。公式通常是:
- 目的:在保证计算精度的前提下,将数据流重新拉回到高效的INT8轨道上,以便后续层继续进行INT8计算。
-
int8输出 (Output)
- 是什么:经过所有层的INT8计算和中间的反复校准后,得到的最终INT8结果。
- 后续:这个INT8输出可以直接使用,或者反量化回FP32格式,交付给应用程序。
PTQ(Post-Training Quantization,后训练量化)
训练后静态量化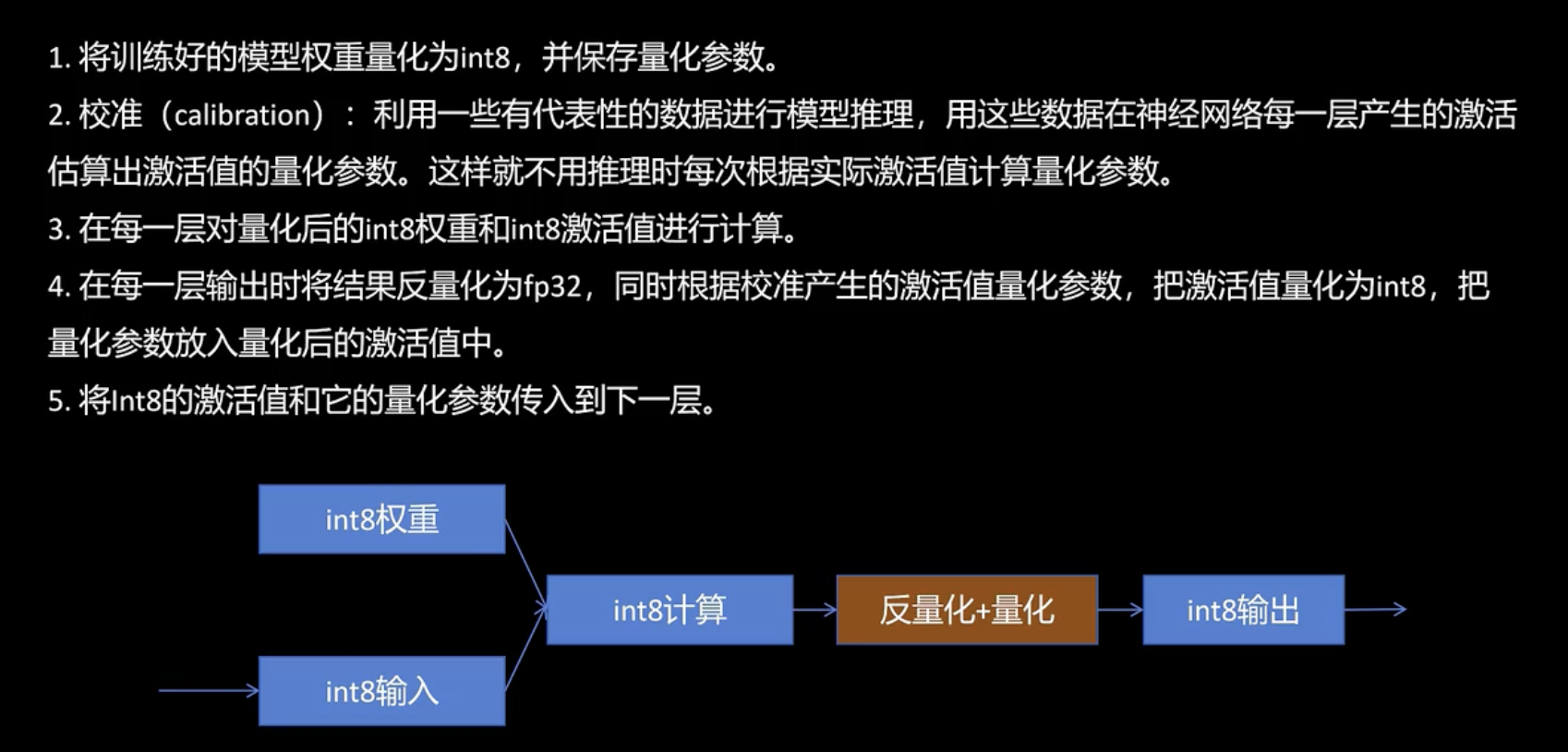
特点:
- 不需要训练,只需一段校准数据(少量样本)。
- 对于训练好的模型进行量化处理(如 int8、int4)。
- 常用于部署阶段,简单快速。
流程:
- 收集小规模代表性数据作为校准集。
- 对模型的权重和激活分布做分析,计算 scale / zero point。
- 逐层或逐通道量化,生成量化模型。
- 可选微调(如 GPTQ、OBQ、AWQ 引入的重构或优化过程)。
训练后动态量化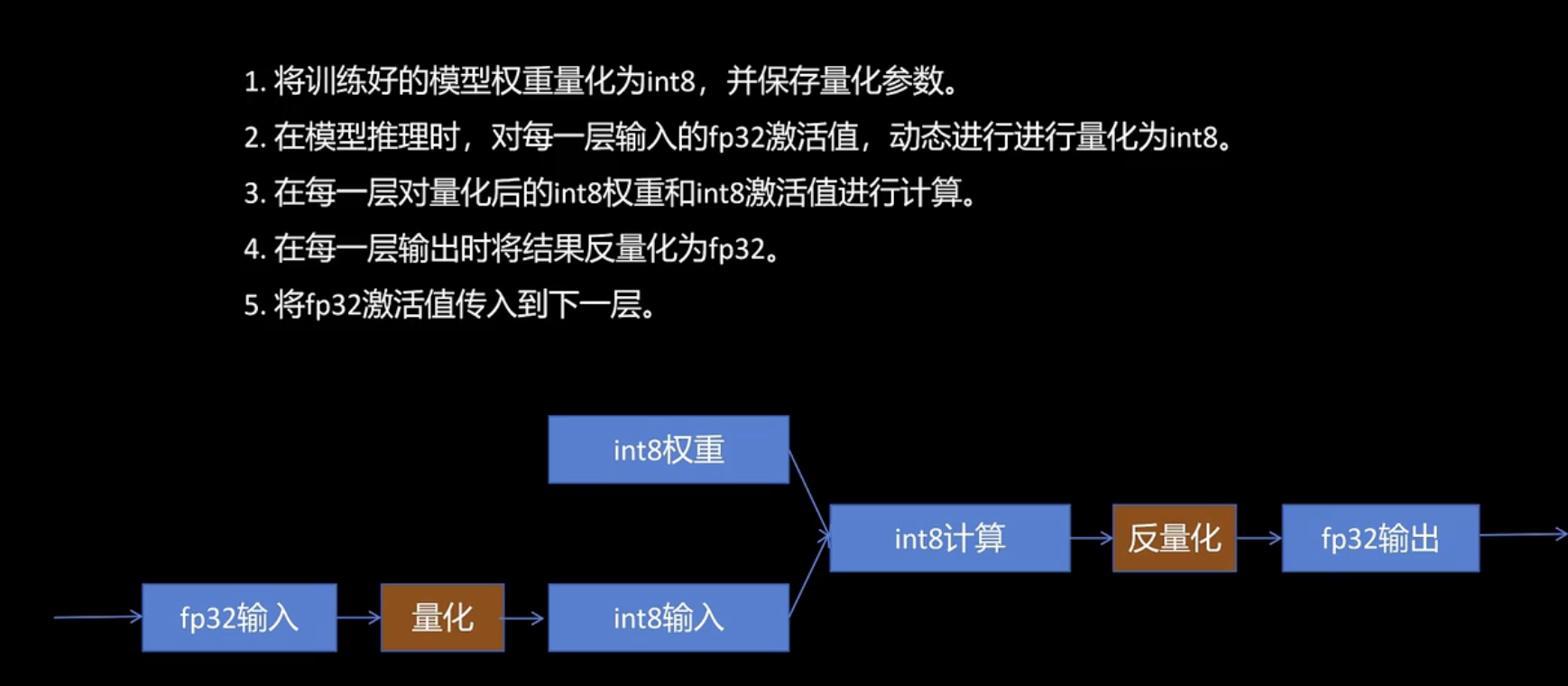
区别:
- 静态量化需要校准数据来预先确定所有参数的缩放比例,推理时全程INT8计算,速度极快,更适合激活值稳定的模型。
- 动态量化无需额外数据,运行时动态计算激活值的缩放比例,灵活性高但速度稍慢。
- 静态量化“先校准后固化”,动态量化“运行时现算”。
QAT(Quantization-Aware Training,量化感知训练)
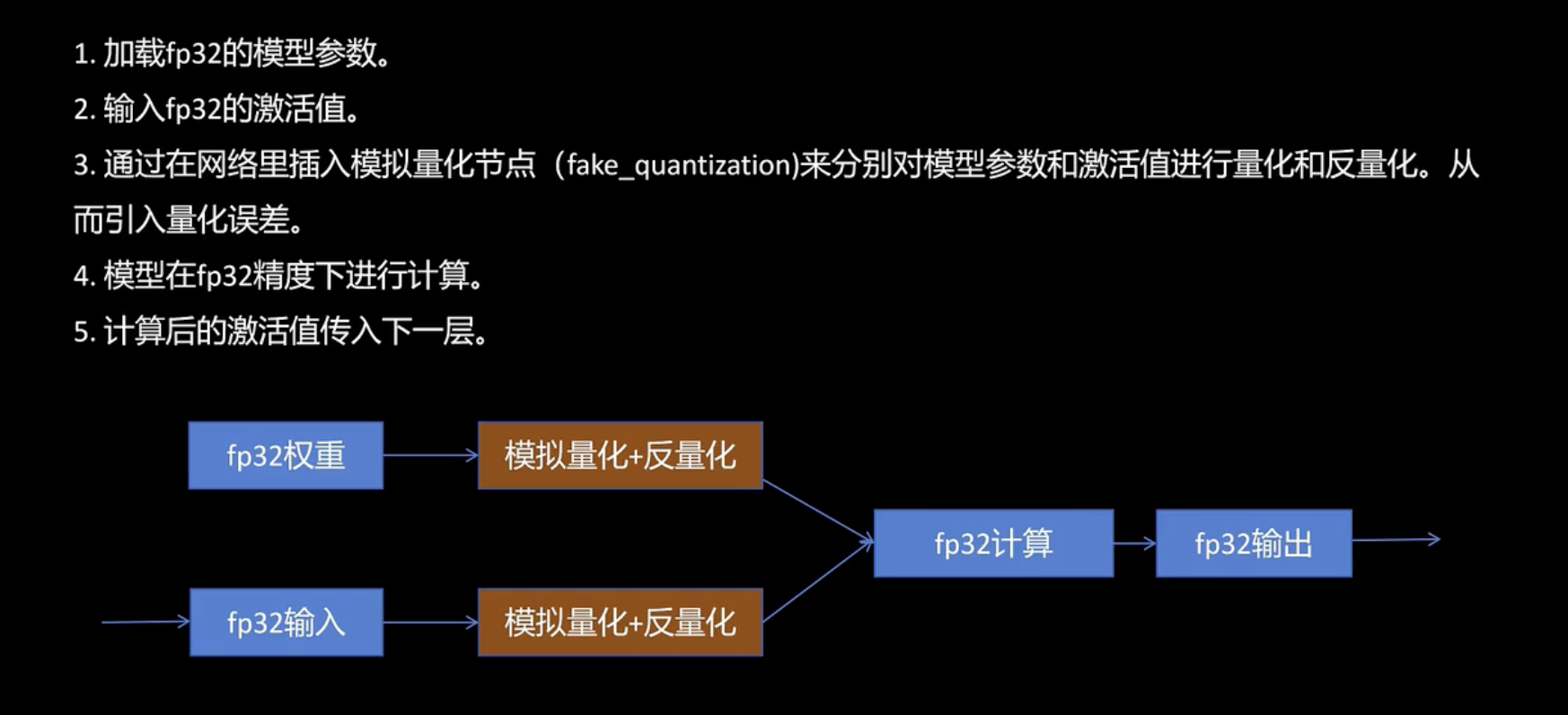
特点:
- 在训练阶段加入量化模拟。
- 用“伪量化(fake quantization)”来近似量化行为。
- 可以 fine-tune 模型,学会适应量化误差。
流程:
- 在训练图中插入量化节点(如权重、激活模拟量化)。
- 前向传播中模拟量化影响(例如对激活值做 clipping)。
- 反向传播仍然基于 FP32 权重更新(STE 技术)。
PTQ的代表方法讲解
1. ZeroQuant
ZeroQuant 是一种针对大语言模型(LLM)部署和推理阶段的训练后量化(PTQ)技术框架主要目的是在不重新训练的前提下大幅降低模型精度(如INT8甚至INT4)而仍保持高精度。
ZeroQuant提出了多个版本:
| 名称 | 主要特点 | 支持精度 |
|---|---|---|
| ZeroQuant | 基础版,首次提出 PTQ 精准方案 | INT8 |
| ZeroQuant-V2 | 引入 block-wise 重构与非对称量化 | INT4 |
| ZeroQuant-V3 | 更进一步,结合 GPT 结构优化 | INT4、NF4 |
ZeroQuant 的核心思想
以 ZeroQuant-V2 为例,主要包含以下关键点:
✅ 1. Block-wise Reconstruction(块级重构)
- 把模型中每层的 W(权重)矩阵分成多个小块,每个块单独量化并做重构。
- 比传统 layer-wise 更细粒度,有效减少精度损失。
- 使用重构损失,如 KL 散度作为度量标准来微调每块的 scale 和 zero-point。
- 混合精度量化(Mixed-Precision)
-
不强制所有模块都用 INT4:比如 LayerNorm 和某些 sensitive 层仍保留 FP16/INT8。
-
比如:
- Attention QKV → INT4
- Output projection → INT8
- LayerNorm → FP16
- 逐通道非对称量化
-
支持逐通道(per-channel)量化:为每个通道分配独立 scale。
-
使用 非对称量化(min-max 动态调整 zero point),更贴近实际权重分布。
- 逐层误差控制
-
引入 量化敏感性分析(sensitivity-aware),找到最容易失真层,给它更高精度。
-
基于统计数据对每一层的激活和权重做误差追踪。
-
观察:激活值的变化范围远大于权重,因此需要更细粒度。
-
方法:
- 激活值 X:Token-wise(即横向,seq dim)
- 权重 W:Group-wise(即列向量)
-
优化手段:层级蒸馏(Layer-wise Distillation),对每层输出做MSE匹配,减少精度损失。
-
优势:
- 高粒度激活值量化能保留更多细节。
- 矩阵乘法结构设计利于低精度加速。
2. LLM.int8()
-
发现问题:激活值中存在“离群值”(Outliers),极大影响量化。
-
解决方案:混合精度量化:
- 离群值:用 FP16 保存,避免精度损失;
- 其余值:使用 INT8 存储和计算。
-
离群值特点(6.7B以上模型尤为严重):
- 仅占 0.1%,但对 softmax 结果影响极大(top1下降20%)。
- 非对称分布(one-sided),幅值可达正常值的 20 倍。
** LLM.int8() 的核心思想**
混合精度量化(Mixed-Precision Quantization)
它 不是简单地把所有权重都压成 INT8,而是:
-
对每个线性层的每一列进行 重要性评估
-
对于 不重要的列(95%以上):
- 用 INT8 表示
-
对于 重要的列(~5%):
- 保留 FP16 精度
权重敏感性评估机制
通过小批量输入校准数据,计算量化误差对输出影响,识别:
哪些列量化后对模型输出影响大?哪些不影响?
这就是 LLM.int8() 的创新点 —— 量化选择机制!
实现
以一个 Linear 层为例:
-
权重矩阵 W∈Rn×mW \in \mathbb{R}^{n \times m}W∈Rn×m
-
将每一列 wjw_jwj 转换为:
-
INT8 表示 w^j\hat{w}_jw^j (若不重要)
-
保留 FP16 表示(若很重要)
整体表示为:
W=Wint8+Wfp16 W = W_{\text{int8}} + W_{\text{fp16}} W=Wint8+Wfp16
推理时:
Y=X⋅(Wint8+Wfp16) Y = X \cdot (W_{\text{int8}} + W_{\text{fp16}}) Y=X⋅(Wint8+Wfp16)
-
3. SmoothQuant
-
观察:激活值比权重要难量化。
-
方法:
-
引入缩放因子 sss,调整激活值和权重的数值范围:
- 激活值除以 sss,权重乘以 sss,保持矩阵乘结果不变。
-
通常 sj=∣Xj∣⋅∣Wj∣s_j = \sqrt{|X_j| \cdot |W_j|}sj=∣Xj∣⋅∣Wj∣,并设置超参 α=0.5\alpha = 0.5α=0.5
-
-
优点:
- 显著提高量化精度;
- 缩放常数可预先计算,避免运行时计算。
4. GPTQ(Groupwise Precision Training for Quantization)
前提:OBQ
Optimal Brain Quantization(OBQ)的流程,是一种以最小化模型输出误差为目标的后训练量化(PTQ)方法,其核心是通过最小化权重量化误差在整个模型输出(如 logits)上的影响,来实现高精度量化。OBQ逐层(Layer-wise)进行权重量化与输出拟合优化,依次处理每一层,直到整网完成。
下面是对 OBQ 流程的详细讲解(分步骤):
第 1 步:收集校准数据
- 从真实数据或模拟数据中收集少量样本(如 100 条)
- 前向传播,记录每一层的输入激活 XXX
目的:构造真实输入空间,捕捉量化对输出的实际影响。
第 2 步:获取原始输出(浮点精度)
- 对当前层(如 Linear 层)使用浮点权重 WWW 计算输出:
Y=XW Y = XW Y=XW
这作为参考输出。
第 3 步:初始化量化权重
- 对权重 WWW 进行线性量化,得到初始量化权重 WqW_qWq:
Wq=Quant(W,scale,zero-point) W_q = \text{Quant}(W, \text{scale}, \text{zero-point}) Wq=Quant(W,scale,zero-point)
- 可采用 per-channel、per-group 量化方式
- 支持 INT8 / INT4 等低位量化
第 4 步:误差重构优化(核心)
目标:找到最优的量化权重解,使得量化后的输出最接近原始输出 YYY。
数学表达为一个最小二乘优化问题:
minW^q∥XW^q−Y∥2s.t. W^q∈quantized space \min_{\hat{W}_q} \| X \hat{W}_q - Y \|^2 \quad \text{s.t. } \hat{W}_q \in \text{quantized space} W^qmin∥XW^q−Y∥2s.t. W^q∈quantized space
-
W^q\hat{W}_qW^q:在量化空间内逼近原始输出的最优解
-
这是一个 投影 + 修正问题,可用以下方式求解:
线性最小二乘 + clip 到量化区间 -
求解近似的连续最优 W∗W^*W∗:
W∗=(XTX)−1XTY W^* = (X^TX)^{-1} X^TY W∗=(XTX)−1XTY
- 将 W∗W^*W∗ 投影到量化空间,得到 W^q\hat{W}_qW^q
第 5 步:逐层更新模型
- 替换当前层的浮点权重为 W^q\hat{W}_qW^q
- 保留 scale 和 zero point(供推理阶段反量化)
第 6 步:全模型前向验证
- 将模型换成量化后的版本
- 在校准数据上跑一次完整前向,验证精度变化(如 logits 差异、Top-1 变化)
GPTQ量化算法
GPTQ 是一种无需训练的低比特后训练量化(Post-Training Quantization,PTQ)方法,广泛用于 LLaMA、OPT、BERT 等大型模型的 INT4 量化,尤其适合 Transformer 的 Linear 层权重量化。
核心思想:
GPTQ 的目标是对每一层的权重 WWW 进行逐列量化,使得:
量化后的输出 XWqXW_qXWq 尽可能接近原始输出 XWXWXW,且考虑量化误差对整体输出的影响最小。
对于一层线性变换(如 Linear 层):
Y=XW Y = XW Y=XW
- X∈Rn×dinX \in \mathbb{R}^{n \times d_{\text{in}}}X∈Rn×din:输入激活(采样的校准数据)
- W∈Rdin×doutW \in \mathbb{R}^{d_{\text{in}} \times d_{\text{out}}}W∈Rdin×dout:浮点权重
- WqW_qWq:INT4 或 INT8 量化权重
GPTQ 逐列处理权重矩阵 WWW 的每一列 wjw_jwj,以最小化:
minw^j∈quant space∥Xw^j−Xwj∥2 \min_{\hat{w}_j \in \text{quant space}} \| X \hat{w}_j - Xw_j \|^2 w^j∈quant spacemin∥Xw^j−Xwj∥2
但关键在于,它不仅考虑本列误差,还考虑误差对输出的影响,使用二阶信息(Hessian 近似)。
具体步骤
① 收集校准数据(X)
- 从样本集中抽取 XXX(输入激活)
- 一般为 128 ~ 1024 条样本
② 构造输入协方差矩阵 HHH
GPTQ 关键:使用输入协方差 H=XTXH = X^T XH=XTX 来估计量化误差的影响
- H∈Rdin×dinH \in \mathbb{R}^{d_{\text{in}} \times d_{\text{in}}}H∈Rdin×din
- 实际中使用近似的对角矩阵 H~=diag(H)\tilde{H} = \text{diag}(H)H~=diag(H),降低计算成本
③ 列优先贪心量化
对于权重矩阵 W=[w1,w2,…,wd]W = [w_1, w_2, \dots, w_d]W=[w1,w2,…,wd],每次处理一个列 wjw_jwj:
-
- 第 1 步:量化列向量
将 wjw_jwj 量化为 w^j\hat{w}_jw^j,在量化空间中选择最接近的向量:
w^j=Quant(wj) \hat{w}_j = \text{Quant}(w_j) w^j=Quant(wj)
可以是对称或非对称 INT4、INT8,支持 per-channel/group 量化。
-
- 第 2 步:误差补偿(Error Feedback)
将量化引入的误差反馈到后续列中:
Wj+1: d←Wj+1: d−(wj−w^j)THj+1: d,jHjj W_{j+1:\,d} \leftarrow W_{j+1:\,d} - \frac{(w_j - \hat{w}_j)^T H_{j+1:\,d, j}}{H_{jj}} Wj+1:d←Wj+1:d−Hjj(wj−w^j)THj+1:d,j
这类似于在正交方向上“修正”后续列,使误差不会积累。
这个步骤就是 GPTQ 的亮点:
💡 基于 Hessian 的权重误差传播修正,防止前面列的量化误差污染后面列
④ 重复直到所有列处理完毕
完成整层的量化,得到 WqW_qWq
⑤ 替换权重,验证模型输出
- 用 WqW_qWq 替换原始 WWW
- 在校准集上比较 logits 差异、Top-1 精度变化
🧪 PyTorch 框架中的 GPTQ 示例流程(简略)
X = collect_calibration_activations(layer, data) # shape [N, in_dim]
H = (X.T @ X) / N # Hessian approximation
for j in range(W.shape[1]):
w_j = W[:, j]
w_hat_j = quantize_column(w_j)
error = w_j - w_hat_j
W[:, j+1:] -= (error.T @ H[:, j+1:]) / H[j, j] # error feedback
W[:, j] = w_hat_j
5.AWQ
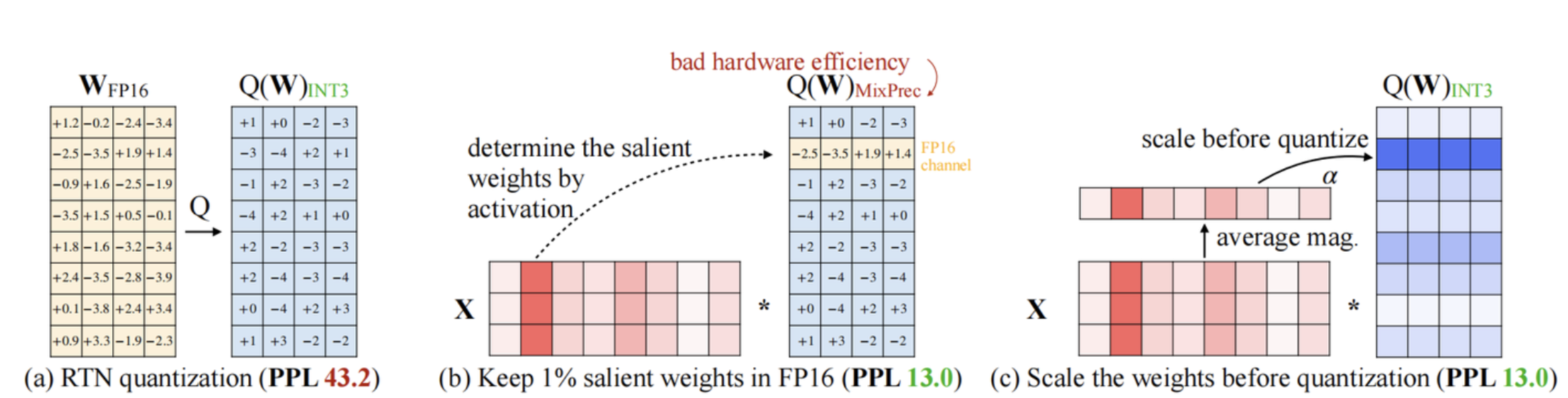
其核心思想是:通过分析激活值的分布动态调整权重量化策略,显著降低量化误差,尤其适合GPT、LLaMA等百亿参数级模型。
核心原理
1. 传统量化的问题
权重平等量化:普通INT8量化对所有权重统一缩放,但实际中不同权重对模型输出的影响差异极大。
激活值分布不均:某些通道(Channel)或注意力头的激活值范围更大,需要更高精度。
2. AWQ的解决方案
保护关键权重:
- 通过统计激活值的幅度,识别对输出影响大的权重(如某些注意力头的Key/Value矩阵),对其保留更高精度(如INT4→INT8)。
按通道缩放Per-channel Scaling:
-
对每个权重通道单独计算缩放因子,而非全局统一缩放。
-
如何做?
识别激活的“重要区域”(高幅值、高敏感性)- 比如通过观测校准样本输入,找出 activations 哪些维度影响最大
对重要的列或 group 的权重提前放大(scaling)
-
用一个缩放因子 sjs_jsj 缩放列 WjW_jWj:
Wj′=sj⋅Wj W'_j = s_j \cdot W_j Wj′=sj⋅Wj
-
然后对 Wj′W'_jWj′ 做量化:
W^j′=Quantize(Wj′) \hat{W}'_j = \text{Quantize}(W'_j) W^j′=Quantize(Wj′)
-
最后在推理时再除以 sjs_jsj,即:
XW≈X⋅(1sj⋅W^j′) X W \approx X \cdot \left( \frac{1}{s_j} \cdot \hat{W}'_j \right) XW≈X⋅(sj1⋅W^j′)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 63
63 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)