哨兵:基于代理模型注意力探测的LLM上下文压缩的理解视角
检索增强生成(RAG)通过外部上下文增强了大语言模型(LLMs),但检索到的段落通常过长、噪声过多或超出输入限制。现有的压缩方法通常需要对专用压缩模型进行监督训练,增加了成本并降低了便携性。我们提出了哨兵(Sentinel),一种轻量级的句子级压缩框架,将上下文过滤重新定义为基于注意力的理解任务。与训练压缩模型不同,哨兵通过一个轻量级分类器从现成的0.5B代理LLM中探测解码器注意力,以识别句子相
张勇 1{ }^{1}1, 黄彦文 1,2{ }^{1,2}1,2, 程宁 1,∗{ }^{1, *}1,∗,
郭洋 1{ }^{1}1, 朱云 1{ }^{1}1, 王艳萌 1{ }^{1}1, 王少军 1{ }^{1}1, 肖静 1{ }^{1}1,
1{ }^{1}1 平安科技(深圳)有限公司,中国
2{ }^{2}2 电子科技大学
zhangyong203@pingan.com.cn
摘要
检索增强生成(RAG)通过外部上下文增强了大语言模型(LLMs),但检索到的段落通常过长、噪声过多或超出输入限制。现有的压缩方法通常需要对专用压缩模型进行监督训练,增加了成本并降低了便携性。我们提出了哨兵(Sentinel),一种轻量级的句子级压缩框架,将上下文过滤重新定义为基于注意力的理解任务。与训练压缩模型不同,哨兵通过一个轻量级分类器从现成的0.5B代理LLM中探测解码器注意力,以识别句子相关性。经验上,我们发现查询-上下文相关性估计在不同模型规模之间是一致的,0.5B代理与更大模型的行为紧密匹配。在LongBench基准测试中,哨兵实现了高达5×5 \times5×的压缩,同时与7B规模压缩系统的QA性能相匹配。我们的结果表明,探测原生注意力信号可以实现快速、有效且问题感知的上下文压缩。1{ }^{1}1
1 引言
大型语言模型(LLMs)在开放域问答、推理和对话任务中取得了令人印象深刻的性能(Brown等人,2020;OpenAI,2024)。为了将其能力扩展到知识密集型应用,检索增强生成(RAG)作为一种强大的范式出现,通过从外部语料库中检索证据来增强模型输入(Lewis等人,2020;Guu等人,2020;Shi等人,2024)。然而,检索到的长上下文通常包含噪声、冗余或超过模型输入限制,使得上下文压缩对于效率和有效性至关重要(Liu等人,2024;Yoran等人,2024)。
这一挑战促使人们从粗略的文档级重排序(Karpukhin等人,2020)转向细粒度的上下文压缩,大致分为基于标记和基于句子的选择策略。基于标记的方法(如LLMLingua 1/2(Jiang等人,2023;Pan等人,2024),QGC(Cao等人,2024))通过困惑度或查询感知信号估计标记的重要性,但通常会破坏话语连贯性。基于句子的方法(如RECOMP,EXIT(Xu等人,2024;Hwang等人,2024))通过选择完整句子来保留句法结构,但通常需要生成器反馈或特定任务调整。尽管取得进展,现有方法仍与监督或生成信号紧密耦合——突显了对轻量级替代方案的需求。
在这些挑战中,越来越多的研究表明,LLMs在推理过程中内在地揭示了内部语义和相关性信号。具体而言,解码器注意力模式已被证明能够捕捉事实归属和接地行为(Wu等人,2024;Huang等人,2025),而特殊提示下的最终隐藏状态可作为有效的压缩语义嵌入,如PromptEOL(Jiang等人,2024b)所示。这些发现指向了一个新兴共识:LLMs自然地将上下文理解聚合到其最终推理步骤中,提供了无需明确生成即可提取轻量级信号的机会。
基于这些发现,我们假设查询-上下文理解在不同模型规模下趋于稳定,即使生成能力有所不同。小型模型可能表现出与大型LLMs密切一致的注意力模式,尽管其生成能力有限。这指出了一个有希望的方向:与其依赖于全规模生成或重排序,我们可以直接从紧凑模型的原生注意力行为中解码相关性信号。我们采用这种观点设计了一种轻量且高效的
* 对应作者
* ${ }^{1}$ 我们的代码可在https://github.com/ yzhangchuck/Sentinel获取。
* 图1:哨兵框架概述。给定一个查询-上下文对,一个现成的代理模型提供最终标记的解码器注意力。探测分类器解释句子级别的注意力特征以选择相关上下文,从而为下游LLMs实现轻量且与模型无关的压缩。
方法进行上下文压缩。
然而,现有方法通常以浅层或启发式的方式使用注意力。许多方法依赖于对解码器注意力的原始阈值处理,这往往具有噪声、脆弱性,并且与句子级别语义对齐不佳 Wang等人(2024);Fang等人(2025)。这些方法未能提供一种轻量且可解释的压缩机制,无法稳健地利用原生模型行为。
在本研究中,我们提出了哨兵(Sentinel),这是一种基于注意力探测的轻量且与模型无关的句子级别上下文压缩框架。给定一个查询-上下文对,哨兵使用一个现成的0.5B规模代理LLM提取多层解码器注意力,指向输入句子。我们不是训练一个专用的压缩模型,而是将压缩视为一个探测任务:聚合跨头和层的注意力特征,并使用一个简单的逻辑回归分类器预测句子相关性。这种设计消除了训练特定任务压缩模型的需要,实现了高效、可解释且即插即用的压缩。
实证上,哨兵在LongBench Bai等人(2024) 上实现了高达5×\times×的输入压缩,同时仅使用一个0.5B代理模型就匹配了7B规模压缩系统的QA性能。它在不需要生成器监督或特定提示调整的情况下,有效推广到各种QA任务、语言和LLM主干。
我们的贡献如下:
- 我们将上下文压缩重新定义为基于注意力的理解任务,并通过一个探测分类器实现——无需训练专用的压缩模型。
-
- 我们提出了哨兵(Sentinel),一种轻量的句子级别压缩框架,该框架通过从现成的0.5B代理模型中探测原生注意力信号来识别查询相关的上下文以进行压缩。
-
- 我们实证观察到,查询-上下文相关性估计在不同模型规模下保持稳定,使紧凑代理能够近似大型模型的压缩行为。
-
- 在LongBench上,哨兵实现了高达5×\times×的输入压缩,同时在英语和中文任务中匹配了7B规模压缩系统的QA性能。
2 方法论
我们提出了哨兵(Sentinel),这是一种轻量框架,通过探测小代理模型中的原生注意力行为来识别查询相关的句子。我们不是端到端地训练一个压缩模型,而是解码已经嵌入在模型推理动态中的基于注意力的信号。我们的管道包括三个阶段:注意力特征提取、探测分类器训练以及与下游LLMs的集成。
2.1 任务公式化
给定一个查询 qqq 和一个由句子组成的检索上下文 C=C=C= {s1,s2,...,sn}\{s_{1},s_{2},...,s_{n}\}{s1,s2,...,sn},我们的目标是从 CCC 中选择一个子集 C′⊆CC^{\prime}\subseteq CC′⊆C,以保留回答 qqq 所需的关键信息。
我们将此视为一个探测任务:对于每个句子 sis_{i}si,我们训练一个二元分类器,根据来自紧凑代理模型的注意力信号预测相关性标签 yi∈{0,1}y_{i}\in\{0,1\}yi∈{0,1}。在推理时,我们使用预测概率作为句子选择的软相关性得分。
2.2 基于注意力的效用估计
哨兵的核心是一个特征提取器,它利用解码器注意力来估计句子效用。给定输入序列:
[q]⊕[s1]⊕[s2]⊕⋯⊕[sn][q]\oplus[s_{1}]\oplus[s_{2}]\oplus\cdots\oplus[s_{n}][q]⊕[s1]⊕[s2]⊕⋯⊕[sn]
我们将其输入到一个具有指令跟随能力的小型解码器语言模型中。为了在最后位置鼓励语义压缩,我们应用了一个请求一词答案的提示模板,类似于PromptEOL Jiang等人(2024b) 的精神。我们从最后一个解码器标记中提取注意力张量 A∈RL×H×T\mathbf{A}\in \mathbb{R}^{L \times H \times T}A∈RL×H×T,捕获跨层、头和输入标记的注意力分数。
为什么注意力反映效用。解码器注意力已被证明反映了对齐和归属信号 Huang等人(2025)。特别是,最后一个标记收到的注意力通常编码哪些输入段最相关于生成。从信息理论的角度来看,Barbero等人(2024) 显示解码器模型将先前的上下文压缩到最终标记表示中 —— 过度挤压。
特征表示。对于每个句子 sis_{i}si,我们计算一组从其标记接收自最后一个解码器标记的注意力衍生出的基于注意力的特征。具体来说,我们从每个层和头中提取指向上下文标记的注意力权重,并通过上下文跨度上的总注意力质量进行归一化。这种归一化去除了非上下文元素(如查询或提示)的影响。
然后我们在 sis_{i}si 的标记上平均归一化的注意力权重,独立于每个注意力头和层,得到一个特征向量 vi∈RLH\mathbf{v}_{i} \in \mathbb{R}^{L H}vi∈RLH,其中 LLL 是解码器层数,HHH 是注意力头数。vi\mathbf{v}_{i}vi 的每个元素反映了通过特定注意力通道测量的 sis_{i}si 的相对贡献。
2.3 句子相关性的探测分类器
为了从注意力特征中解码相关性,我们训练了一个轻量级的逻辑回归(LR)探测器。探测器计算:
y^i=σ(w⊤vi+b) \hat{y}_{i}=\sigma\left(\mathbf{w}^{\top} \mathbf{v}_{i}+b\right) y^i=σ(w⊤vi+b)
其中 σ\sigmaσ 是sigmoid函数。模型为每个句子输出一个概率分数,该分数直接用于句子排名。
2.4 弱监督和鲁棒探测
为了有效地探测模型的内部相关性行为,我们使用来自QA数据集的弱监督结合检索过滤和鲁棒性增强来训练分类器。
2.5 探测数据构建
我们从广泛使用的QA数据集中构建初始训练数据,涵盖单跳和多跳问答场景。具体来说,我们使用来自SQuAD、Natural Questions(单跳)和HotpotQA(多跳)的例子,其中答案跨度在检索到的上下文中被标注。对于每个QA示例,包含黄金答案跨度的句子被标记为正类,而所有其他句子被标记为负类。这种弱监督允许我们在不需要手动注释句子相关性的情况下构建大规模训练数据,并确保分类器暴露于简单事实问题和复杂的多跳推理模式。
2.5.1 选择依赖上下文的样本
为了净化监督,我们仅保留那些需要检索到的上下文才能正确回答的QA示例。具体来说,我们仅保留那些模型在没有检索到的上下文时无法正确回答但在提供上下文时成功的QA示例。这种过滤概念上呼应了之前通过干预引起的输出变化来探测模型行为的工作 Meng等人(2022)。这一标准确保了正类句子真正提供了回答所需的关键信息,并减少了来自模型记忆或幻觉知识的污染。通过过滤检索依赖性,我们专注于那些从上下文中解码相关性至关重要的情况,与上下文理解而非内部回忆的目标一致。
2.5.2 通过句子打乱提高鲁棒性
为了减轻位置偏差 Liu等人(2024),特别是在多文档检索设置中常见的位置偏差,我们在训练期间通过随机排列每篇文档内的句子顺序来应用句子打乱。这种简单的扰动鼓励分类器依赖于语义相关性而不是固定位置,提高了对真实世界RAG输入的泛化能力,这些输入可能具有噪声或多样化的结构。
2.6 通过注意力探测进行推理
在推理时,给定一个查询-上下文对 (q,C)(q, C)(q,C),我们运行代理模型并使用固定的QA样式提示,提取最终标记的解码器注意力,并计算句子级别的注意力特征。探测分类器为每个句子分配一个相关性得分,并选择排名最高的子集以适应长度预算。这个压缩的上下文被传递给下游LLM进行生成。
由于哨兵仅操作代理模型注意力,它是模型无关的,可以在不修改或微调目标LLM的情况下集成到任何RAG管道中。
3 实验
数据集 我们在LongBench(Bai等人,2024)的英语子集上评估我们的方法,该数据集涵盖了六个任务类别:单文档问答、多文档问答、摘要、少量推理、合成检索和代码补全。
为了确保与先前工作的可比性(例如GPT-3.5-Turbo基线),我们在比较表中包括所有原始任务。然而,在我们的通义千问实验中,我们排除了LCC和PassageCount,因为它们的输入格式和任务目标与上下文压缩冲突(见附录A)。在我们的通义千问表格中,我们在Synth.和Code列中标注了一个星号(*)以指示修改后的类别组成。
探测数据 我们从NewsQA(50%)、SQuAD(20%)和HotpotQA(30%)中抽取3,000个QA示例构建训练集,涵盖了单跳和多跳推理任务。对于每个QA示例,我们提取一个支持黄金答案跨度的正面句子,以及来自同一段落的一个负面句子,共得到6,000个句子级别的训练实例。
在NewsQA中,30.1%的示例包含0-500个标记(使用通义千问-2.5进行标记化),69.9%的示例包含500-1,000个标记。在SQuAD中,99.3%的示例落在0−5000-5000−500标记范围内。对于HotpotQA,我们通过限制不相关内容将所有示例限制在0−5000-5000−500标记范围内。
每个上下文使用spaCy的句子分隔器分割成句子。为了提取特征,我们对每个示例应用一个QA样式的提示,并从最后一个标记收集解码器注意力。提示格式为:
鉴于以下信息:{context}
根据提供的信息回答以下问题,用一两个词作答:
{question}
回答:
从最后一个标记到每个句子的解码器注意力权重被聚合形成固定长度的特征向量用于分类。
上下文依赖样本选择 为了提高标签质量,我们仅保留那些上下文对正确回答必要的示例。对于NewsQA和SQuAD,我们保留那些基于记忆的答案错误而基于上下文的答案正确的示例,均由EM判断。对于HotpotQA,我们仅保留那些记忆F1 ≤0.2\leq 0.2≤0.2且上下文F1 ≥0.5\geq 0.5≥0.5的样本。
探测分类器训练 我们在注意力派生特征上训练一个逻辑回归(LR)模型,使用5折交叉验证和平衡准确率作为评分指标。我们在正则化强度C∈{0.01,0.1,1.0,10.0,100.0}C \in\{0.01,0.1,1.0,10.0,100.0\}C∈{0.01,0.1,1.0,10.0,100.0}上进行网格搜索,并使用liblinear求解器,带有ℓ2\ell_{2}ℓ2正则化、类别平衡加权和最多2,000次迭代。最佳模型基于验证集上的AUC选择。
压缩策略 我们根据目标LLM的分词器实施长度控制的压缩策略。对于给定的上下文x=x=x= s1,s2,…,sns_{1}, s_{2}, \ldots, s_{n}s1,s2,…,sn,我们的分类器对每个句子打分,并选择满足以下约束之一的子集:
- 标记长度预算:保留排名靠前的句子,直到它们的总标记计数(由目标模型的分词器测量)达到固定的预算BBB(例如,2000个标记)。
-
- 标记比率约束:保留排名靠前的句子,其累积标记计数不超过原始上下文标记化长度的某个比例τ\tauτ(例如,0.1至0.5)。
在这两种情况下,选定的句子按原始顺序连接以形成压缩输入。
代理模型设置 在我们的主要实验中,我们采用通义千问-2.5-0.5B-Instruct作为默认代理模型,用于提取基于注意力的特征并执行句子相关性分类。除非另有说明,所有报告的结果均使用1024个标记的块大小,其中检索到的上下文在传递给代理模型之前被分割为最多1024个标记的非重叠块。
- 标记比率约束:保留排名靠前的句子,其累积标记计数不超过原始上下文标记化长度的某个比例τ\tauτ(例如,0.1至0.5)。
评估模型 遵循LongBench和LLMLingua设置,我们使用ChatGPT(gpt-3.5-turbo)作为主要的QA评估模型。为了评估我们方法的一般性,我们还在主要结果中实验了通义千问-2.5-7B-Instruct。所有评估遵循LongBench的提示和解码设置(Bai等人,2024),详见附录J。
| 方法 | LongBench (GPT-3.5-Turbo, 2000-token constraint) | | | | | | | | | | 压缩统计 | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
强结果在Single-Doc上表现突出,并在Multi-Doc QA上显著超越Original Prompt。尽管其在FewShot和Summarization上的表现低于Original,Sentinel在Synth任务上的表现相当,表明尽管存在轻微的格式干扰,但仍对长上下文场景具有鲁棒性。
总体而言,这些结果表明Sentinel在多语言设置中具有良好的通用性,并在压缩高相关内容方面仍然有效。
学习 vs. 原始注意力 Sentinel (0.5B) 在大多数任务上优于Raw Attention (0.5B),尤其是在Single-Doc、Multi-Doc QA和Synthetic任务上。改进在英语中是一致的,而在中文中虽然较小,但通常是积极的,支持学习显式相关性优于使用原始注意力分数的价值。
3.2 代理模型尺寸鲁棒性
我们的框架基于这样一个假设:查询-上下文相关性,正如在注意力中所反映的那样,在不同的代理模型尺度上是相对稳定的。为了评估这一点,我们比较了三个通义千问-2.5模型(0.5B、1.5B、3B)在相同训练设置下的表现,使用1024-token块和2,000token输入预算进行评估。如表2所示,性能在各尺度上相对稳定,平均F1差异不到2点。0.5B模型已经在计算成本低得多的情况下达到了竞争性结果,支持使用较小的代理模型的效率。
为了进一步评估模型间的一致性,我们计算了所选句子的句子级重叠。句子级重叠随着预算增加而增加,从1000个标记的0.63-0.70到3000个标记的0.74-0.78,表明代理模型尺度上的一致相关性估计。完整结果见附录F。
这些发现确认了基于注意力的相关性估计在模型尺度上是稳定的。一个0.5B代理可以紧密近似较大模型的句子选择行为,从而实现准确且高效的压缩。
3.3 消融分析
我们对方法的三个方面进行了消融分析:注意力特征设计、块大小和句子选择策略。除非另有说明,所有实验都使用通义千问-2.5-7B-Instruct进行生成,并在LongBench上进行评估。
| 特征 | HotpotQA | SQuAD | NewsQA | 整体AUC | 整体AVG |
|---|---|---|---|---|---|
| All Layers | 0.9228 | 0.9987 | 0.9838 | 0.9700\mathbf{0 . 9 7 0 0}0.9700 | 51.23 |
| Selected | 0.9171 | 0.9943 | 0.9832 | 0.9662 | 50.20 |
| Last Layer | 0.8606 | 0.9538 | 0.9588 | 0.9121 | 49.04 |
表3:不同注意力特征提取策略及其在通义千问-2.5-7B-Instruct压缩评估中的有效性对比。
3.3.1 注意力特征消融分析
我们在通义千问-2.5-0.5B-Instruct上评估了三种基于注意力的特征构造策略。
- All Layers: 聚合所有解码层的注意力分数。
-
- Last Layer: 仅使用最终解码层的注意力分数。
-
- Selected: 使用mRMR(Ding和Peng,2005)选择一组紧凑的注意力头,限制为不超过一个解码层中的数量。详情见附录C。
如表3所示,All Layers策略实现了最高的AUC和下游性能,而Selected变体在紧凑性和准确性之间提供了强有力的权衡。
- Selected: 使用mRMR(Ding和Peng,2005)选择一组紧凑的注意力头,限制为不超过一个解码层中的数量。详情见附录C。
3.3.2 块大小变体
我们在不同的块大小(512、1024、2048、4096)下评估Sentinel,所有这些都在推理时受限于2000标记预算。较大的块允许注意力覆盖更广泛的连续上下文,同时减少输入段的数量。如图2(顶部)所示,Sentinel在所有块大小下始终优于Raw Attention基线。
尽管代理是在短于1024标记的序列上训练的,但随着块大小的增大,性能继续改善,在4096标记时达到最佳结果。这种改善可能源于模型在推理时能够在更大的上下文窗口内进行注意力分配,从而促进更有效的上下文压缩。完整的任务级结果见附录D。
3.3.3 压缩比变体
我们进一步评估了在压缩约束τ∈{0.1,0.2,0.3,0.4,0.5}\tau \in\{0.1,0.2,0.3,0.4,0.5\}τ∈{0.1,0.2,0.3,0.4,0.5}下的鲁棒性,其中较低的τ\tauτ表示更激进的上下文修剪。如图2(底部)所示,Raw attention在更严格的约束下急剧退化,特别是在τ<0.3\tau<0.3τ<0.3时。相比之下,Sentinel在所有压缩级别上保持稳定的性能,即使在τ=0.1\tau=0.1τ=0.1时也仅有轻微退化。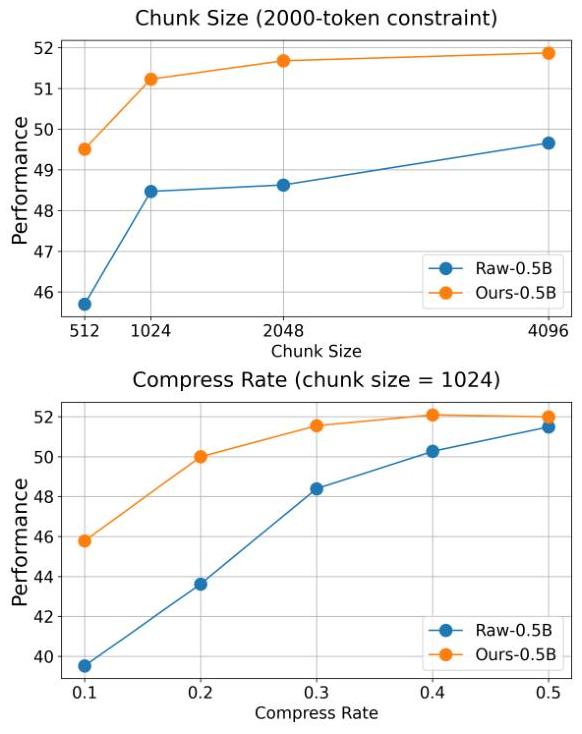
图2:在通义千问-2.5-7B-Instruct与0.5B代理上的消融结果。顶部:在2000-token约束下的块大小消融。底部:在块大小为1024时的压缩比消融。
这些结果突显了Sentinel在低资源场景下的鲁棒性及其在强烈标记预算下提取语义丰富信号的能力。完整的任务级结果见附录D。
3.3.4 延迟和推理效率
我们评估了不同Sentinel配置下的端到端推理延迟,重点关注块大小和注意力特征设计的影响。表4报告了在英语LongBench数据集上的每个样本的平均和中位延迟,测量于单个A100 GPU上。2
在块大小为1024和All Layers注意力特征下,Sentinel比LLMLingua-2快1.13倍,同时达到51.23 F1。将块大小增加到2048可以提高准确率(51.68 F1)并略微加快推理速度(0.65秒平均),展示了推理时间更长跨度注意力的好处。有趣的是,使用更大的块(4096)可以达到最佳的整体准确率(51.87 F1),但延迟回到0.78秒——与LLMLingua-2相当。这是由于计算更长范围注意力时GPU内存压力增加,这在该规模下成为主要瓶颈。
为了进一步提高运行时间,我们评估了SENTINEL(SELECTED),它使用紧凑的mRMR选择特征。在块大小为1024的情况下,该变体将延迟减少到0.60秒(1.30倍),仅带来轻微的性能下降(50.20 F1),为低延迟场景提供了高效的替代方案。
4 分析与讨论
4.1 在不同数据集和规模上的探测特征分布
我们通过t-SNE可视化探测特征(见附录G)。在SQuAD和NewsQA中,正/负样本分离良好,但在HotpotQA中重叠——突显了多跳压缩的挑战。特征分布在代理规模上保持一致,强化了基于注意力的相关性的稳定性。我们还改变了探测样本的数量(见附录??),并在训练规模上观察到稳定的性能。
4.2 注意力行为和句子选择
为了更好地理解Sentinel如何解码句子级别的相关性,我们在LongBench中的一个多跳QA任务2WikiMultihopQA的一个例子上可视化注意力行为。输入使用通义千问-2.5-0.5B-Instruct代理模型处理,块大小为1024。
我们比较了三种可视化句子重要性的策略:(1)标记级别注意力,直接显示最终解码器标记到每个输入标记的注意力权重;(2)平均句子注意力(对应于我们的Raw Attention基线),通过平均每个句子的标记的注意力权重计算句子级别的得分;以及(3)Sentinel探测预测,使用训练好的分类器基于注意力派生特征输出句子相关性概率。
如附录I所示,原始标记级别注意力显示出强烈的注意力汇效应(Bondarenko等人,2021;Son等人,2024),大部分权重集中在输入的最后一个标记上。因此,句子级别平均(即Raw Attention基线)严重偏斜,经常无法反映真正的语义相关性。虽然注意力分布确实编码了有用的信号,但它们是嘈杂和无结构的。相比之下,Sentinel的探测分类器避免了注意力汇,并更有效地解码嵌入在模型行为中的相关性模式。
压缩作为理解 不同于以前需要使用大规模标注数据训练专用的压缩模型的方法,我们将压缩视为一个纯粹的理解问题:识别上下文中哪些部分与问题相关。关键在于,我们并不直接训练压缩模型——相反,我们探测一个小代理LLM的注意力行为,以提取已嵌入其内部计算中的相关性信号。这种设计利用了模型的原生理解能力,而不是其生成能力。我们的实验表明,这种相关性行为在不同模型规模上是稳定的:即使是一个0.5B代理也能产生与较大模型相似的句子级别决策。虽然探测分类器是在一小部分外部QA数据(3,000个示例)上训练的,但它在LongBench的多样化下游任务中有效推广。这使得一个轻量且可解释的框架得以实现查询感知压缩,无需特定任务的调整或大规模监督。
5 相关工作
标记级压缩 标记级方法旨在精细粒度地修剪无关或冗余内容。LLMLingua 1/2 Jiang等人(2023);Pan等人(2024) 通过自信息和使用小型LM的标记选择蒸馏来估计标记重要性。QGC Cao等人(2024) 通过池化和嵌入细化将标记表示与查询对齐来进行查询引导压缩。虽然这些方法实现了高压缩比,但它们通常会破坏话语连贯性。
句子级压缩 句子级压缩通过选择完整句子而非标记来保留语义单元。抽取方法如RECOMP Xu等人(2024) 和EXIT Hwang等人(2024) 将压缩公式化为一个二元分类任务,由生成器反馈或对比信号监督。相比之下,CPC Liskavets等人(2024) 学习一个句子编码器,通过检索风格目标按查询相关性对句子进行排名。结构增强方法如Refiner Li等人(2024) 和FineFilter Zhang等人(2025) 进一步重组或重新排序选定的内容以支持多跳推理和长上下文理解。虽然这些方法是有效的,但它们通常需要大规模监督或特定任务调整,这限制了它们在任务和模型间的适应性。
基于注意力的压缩 最近的工作探索了利用解码器注意力作为原生相关性信号。QUITO Wang等人(2024) 引入触发标记以引导基于注意力的标记评分,而ATTENTIONRAG Fang等人(2025) 将QA重新表述为掩码预测并使用注意力修剪低效用句子。然而,这些方法通常依赖于提示工程或原始注意力的直接阈值处理,限制了通用性和鲁棒性。
我们的方法 与以前的工作不同,我们提出了Sentinel,这是一种轻量且与模型无关的框架,通过探测小型代理模型的原生注意力信号来预测句子相关性。我们不是训练一个压缩模型或依赖于原始评分机制,而是将压缩视为一个理解问题——解码在回答问题时内部关注的输入部分。通过实证验证注意力相关性在模型规模上的稳定性,我们的方法在没有生成监督或特定任务训练的情况下实现了高效且可解释的压缩。
6 结论
我们提出了Sentinel,这是一种轻量且可解释的句子级别压缩框架,通过从现成的0.5B代理模型中探测多层注意力来解码句子相关性——无需监督或特定任务调整。在LongBench上,Sentinel实现了高达5×5 \times5×的压缩,同时在英语和中文任务中匹配了7B规模系统的QA性能。这些结果表明,注意力探测为监督压缩提供了一种有效的替代方案,小型模型可以有效地支持大型语言系统中的上下文理解。
局限性
FewShot和代码任务中的格式敏感性。我们的方法使用通用的句子分割,并不考虑特定任务的结构约束。因此,在FewShot和代码任务中,由于格式破坏(如FewShot提示中的输入-输出对断裂或代码中的行边界错位),性能可能会下降。这些任务本质上对布局和结构敏感,当前压缩并未明确保留。
代理模型范围。所有探测实验使用通义千问-2.5-Instruct模型作为代理。尽管通义千问提供了强大的对齐和开放可用性,我们尚未测试跨架构的通用性到其他系列如LLaMA、Mistral或GPT基础模型。未来工作可以探索是否注意力模式在不同架构中同样可探测。
有限的评估主干。我们的评估是在两个解码器LLM上进行的——GPT-3.5Turbo和通义千问-2.5-7B-Instruct。虽然这些提供了开源和专有系统的良好覆盖,但在其他模型(如LLaMA、Mistral、Claude)上的额外测试将更好地建立跨架构和指令风格的通用性。
参考文献
虞世白,吕欣,张嘉杰,吕宏昌,唐建凯,黄志典,杜政晓,刘潇,曾傲涵,侯磊等。2024。Longbench:一个双语、多任务基准用于长上下文理解。在第62届计算语言学协会年会论文集(第一卷:长论文),第3119-3137页。
费德里科·巴贝罗,安德里亚·巴尼诺,史蒂文·卡普特罗夫斯基,达什扬·库马兰,若昂·马代拉·阿劳霍,奥列克桑德尔·维特维茨基,拉兹万·帕斯卡努,彼得·维利奇科维奇。2024。变压器需要眼镜!语言任务中的信息过度挤压。神经信息处理系统进展,37:98111-98142。
叶莱塞伊·邦达伦科,马库斯·纳格尔,蒂曼·布兰克沃特。2021。理解和克服高效变压器量化面临的挑战。在2021年经验方法在自然语言处理会议论文集,第7947-7969页。计算语言学协会。
汤姆·布朗,本杰明·曼,尼克·赖德,梅勒妮·苏比亚,贾里德·D·卡普兰,普拉富拉·达里瓦尔,阿尔温德·尼拉卡坦,普拉纳夫·夏姆,吉里什·萨斯特里,艾曼达·阿斯科尔等。2020。语言模型是少量学习者。神经信息处理系统进展,33:1877-1901。
曹志伟,曹倩,卢宇,彭宁新,黄璐阳,程山波,苏锦松。2024。在高压缩比下保留关键信息:面向LLMs的查询引导压缩器。在第62届计算语言学协会年会论文集(第一卷:长论文),第12685-12695页。
克里斯·丁,钱慧川,林钦岳,杨玉青,邱丽丽。2005。从微阵列表达数据中选择最小冗余特征。生物信息学与计算生物学杂志,3(02):185-205。
方逸雄,孙天然,石玉玲,顾晓东。2025。AttentionRAG:检索增强生成中的注意力引导上下文剪枝。arXiv预印本arXiv:2503.10720。
凯尔文·顾,肯顿·李,佐拉·通,帕努帕特·帕苏帕特,常鸣伟。2020。检索增强语言模型预训练。在国际机器学习会议论文集,第3929-3938页。PMLR。
黄彦文,张勇,程宁,李志涛,王少军,肖静。2025。动态注意力引导上下文解码以缓解大型语言模型中的上下文忠实性幻觉。arXiv预印本arXiv:2501.01059。
崔虎黄,赵淑民,郑素英,宋何妍,韩胜允,朴钟成。2024。EXIT:用于增强检索增强生成的情境感知抽取压缩。arXiv预印本arXiv:2412.12559。
江辉强,吴倩辉,林钦岳,杨玉青,邱丽丽。2023。LLMLingua:加速大型语言模型推理的提示压缩。在2023年经验方法在自然语言处理会议论文集,第13358−1337613358-1337613358−13376页。
蒋廷,黄少翰,栾忠志,王德清,庄福振。2024b。使用大型语言模型扩展句子嵌入。在计算语言学协会发现:EMNLP 2024论文集,第3182-3196页。
弗拉基米尔·卡尔普欣,巴拉什·奥古兹,谢翁·敏,帕特里克·刘易斯,雷德尔·武,谢尔盖·埃杜诺夫,丹琪·陈,温陶·伊。2020。开放领域问答的密集段落检索。在2020年经验方法在自然语言处理会议论文集(EMNLP),第6769-6781页。
帕特里克·刘易斯,伊森·佩雷斯,阿莱克桑德拉·皮克图斯,法比奥·佩特罗尼,弗拉基米尔·卡尔普欣,纳米安·戈亚尔,海因里希·库特勒,迈克·刘易斯,温陶·伊,提姆·洛克塔施尔等。2020。检索增强生成用于知识密集型NLP任务。神经信息处理系统进展,33:9459-9474。
刘宇成,李博,顾林,林承华。2023。压缩上下文以增强大型语言模型的推理效率。在2023年经验方法在自然语言处理会议论文集,第6342-6353页。
李钟浩,胡旭明,刘爱伟,郑可宁,黄思蕊,熊辉。2024。Refiner:有效重构检索内容以提升问答能力。在计算语言学协会发现:EMNLP 2024论文集,第8548−85728548-85728548−8572页。
巴里斯·利斯卡维茨,马克西姆·乌沙科夫,舒文德·罗伊,马克·克里班诺夫,阿里·埃特马德,肖恩·卢克。2024。带有情境感知句子编码的提示压缩以实现快速和改进的LLM推理。arXiv预印本arXiv:2409.01227。
尼尔森·F·刘,凯文·林,约翰·休伊特,阿什温·帕兰贾佩,米歇尔·贝维拉夸,法比奥·佩特罗尼,珀西·梁。2024。迷失在中间:语言模型如何使用长上下文。计算语言学协会交易,12:157-173。
凯文·孟,大卫·鲍,亚历克斯·安多尼安,尤纳坦·贝尔英科夫。2022。定位和编辑GPT中的事实关联。神经信息处理系统进展,35:17359-17372。
OpenAI。2024。GPT-4技术报告。
潘珠石,吴倩辉,江辉强,夏梦琳,罗旭芳,张觉,林清威,鲁赫勒,杨玉青,林钦岳,赵海薇,邱丽丽,张东梅。2024。LLMLingua-2:用于高效且忠实的任务无关提示压缩的数据蒸馏。在计算语言学协会发现:ACL 2024论文集,第963-981页。
施卫佳,敏申,米希亚洛·雅苏纳加,孙民俊,理查德·詹姆斯,迈克·刘易斯,卢克·泽特勒莫耶,温陶·伊。2024。REPLUG:检索增强的黑盒语言模型。在2024年北美计算语言学协会会议论文集:人类语言技术(第一卷:长论文),第8371-8384页。
孙胜武,朴元铉,韩伍铉,金奎永,李载镐。2024。添加注意力汇可以缓解大型语言模型量化中的激活异常。arXiv预印本arXiv:2406.12016。
王文山,王一航,范逸行,廖华明,郭嘉峰。2024。QUITO:通过查询引导上下文压缩加速长上下文推理。arXiv预印本arXiv:2408.00274。
吴文豪,王义忠,萧广轩,彭浩,傅瑶。2024。检索头机制解释长上下文事实性。arXiv预印本arXiv:2404.15574。
徐方远,施卫佳,崔恩索。2024。RECOMP:通过上下文压缩和选择性增强改进检索增强的语言模型。在第十二届国际学习表示会议论文集。
约里·尤兰,托默·沃尔夫森,奥里·拉姆,乔纳森·贝朗特。2024。使检索增强的语言模型对无关上下文具有鲁棒性。在第十二届国际学习表示会议论文集。
张千池,张海南,庞亮,郑宏伟,童永新,郑治铭。2025。Finefilter:一种细粒度噪声过滤机制用于检索增强的大规模语言模型。arXiv预印本arXiv:2502.11811。
A 数据集详情
我们根据LongBench(Bai等人,2024)的英语子集提供了实验中使用的数据集的详细描述。LongBench是一个长上下文基准,涵盖了多样化任务,旨在评估语言模型在理解和推理扩展文本输入方面的能力。它由六个任务类别组成,每个类别包含多个代表性数据集:
- 单文档问答:
- NarrativeQA:基于单个叙事文档回答问题,例如故事或电影剧本。
-
- QASPER:基于科学论文回答问题。
-
- MultiFieldQA-EN:从长结构化百科全书条目中回答事实问题。
- 多文档问答:
- HotpotQA、2WikiMultihopQA和MuSiQue:需要跨多个段落进行推理以回答复杂事实问题的多跳问答任务。
- 摘要:
- GovReport:总结长政府报告。
-
- QMSum:总结会议记录。
-
- MultiNews:总结多源新闻文章。
-
- 少样本推理:
-
- TREC:分类问题类型。
-
- TriviaQA:回答琐事风格的事实问题。
-
- SAMSum:总结简短对话。
-
- LSHT:将中文新闻标题分类为主题类别。
-
- 合成检索:
-
- PASSAGECOUNT:统计潜在重复输入中唯一段落数量。
-
- PASSAGERETRIEVAL-EN:识别与给定摘要对应的源段落。
-
- 代码补全:
-
- LCC:预测给定代码块的下一行代码,没有明确的自然语言查询。
-
- REPOBENCH-P:预测多文件代码上下文和函数签名下的函数下一行。
数据集过滤。我们从评估中排除了两个任务——LCC和PASSAGECOUNT,因为它们与基于查询的压缩不兼容。LCC缺乏明确的查询,要求模型仅根据前面的行完成最后一行代码。如果没有查询来锚定注意力,我们的方法可能会修剪看似语义上无信息的关键行。虽然这可以通过将指令“下一行代码”视为合成查询来解决,但我们将其留给未来工作。PASSAGECOUNT任务涉及计数精确副本,这与有损压缩不兼容:看似冗余段落之间的微小差异可能导致计数错误。
- REPOBENCH-P:预测多文件代码上下文和函数签名下的函数下一行。
B 基线描述
我们将Sentinel与以下基线方法进行比较,按其设计范式分组:
- LLMLingua-1/2(Jiang等人,2023;Pan等人,2024):基于通过困惑度和LLM蒸馏估计显著性的标记级别压缩方法。这些方法是任务无关的,并不基于查询。
-
- Selective-Context(Li等人,2023):一个句子级别的、任务无关的方法,根据一般的有用性对上下文段落进行评分,独立于问题。
-
- LongLLMLingua(Jiang等人,2024a):一个基于查询的、多阶段压缩系统,使用基于查询的困惑度评分、文档重新排序和自适应压缩比率。
-
- CPC(Liskavets等人,2024):一个对比训练的句子排名模型,根据嵌入空间中与查询的语义相似性选择句子。它是基于查询的,并在合成QA数据上进行训练。
-
- Raw Attention(Wang等人,2024;Fang等人,2025):一个非学习基线,通过平均最终解码器标记的注意力权重选择句子。这模仿了先前工作中如QUITO和AttentionRAG使用的基于注意力的启发式方法。
-
- 随机选择:直到标记预算用完之前随机采样句子。作为下限参考。
-
- 空上下文:模型仅接收问题而不带任何检索到的上下文,作为零上下文基线。
所有基线都在相同的标记预算和LLM生成设置下进行评估以确保公平比较。
- 空上下文:模型仅接收问题而不带任何检索到的上下文,作为零上下文基线。
C mRMR特征选择细节
为了构建紧凑的基于注意力的特征集,我们使用最小冗余最大相关性(mRMR)算法。我们首先计算每个特征(即注意力头统计信息)与二进制相关性标签之间的互信息,选择最有信息量的一个。然后我们迭代地添加最大化相关性同时最小化冗余的特征,通过与已选特征的皮尔逊相关性测量冗余。特征数量限制为单个解码层中的头数,以确保紧凑性和可解释性。
D 块大小和压缩比细节
我们提供了一部分表2的内容,以突出块大小和压缩比在消融研究中的影响。以下表格报告了使用0.5B代理模型的详细任务级性能。
块大小。表5报告了不同块大小(512到4096个标记)的结果,在固定2000个标记约束下。尽管是在短上下文中训练的,但该模型在推理时从更长的块中受益,表明通过保持更广泛的块内连贯性获得收益。
压缩比。表6报告了在固定块大小为1024的情况下,不同压缩比(τ∈{0.1,0.2,0.3,0.4,0.5})(\tau \in\{0.1,0.2,0.3,0.4,0.5\})(τ∈{0.1,0.2,0.3,0.4,0.5})的结果。即使在高压缩下,Sentinel仍然保持稳健,而Raw attention显著退化。
E 使用GPT-3.5-Turbo的额外中文结果
为了评估我们方法的跨语言鲁棒性,我们在LongBench-Zh上使用GPT-3.5-Turbo作为推理模型评估Sentinel。我们与LLMLingua和LLMLingua-2基线进行比较,这些基线在3,000个标记输入约束下进行评估。Sentinel仅使用2,000个标记,但在所有任务类别中始终优于基线。
F 不同代理模型间的句子级重叠
为了检查不同代理模型规模间基于注意力的相关性信号的一致性,我们计算了所选句子的句子级重叠。图3显示了在不同标记预算(1000、2000和3000)下0.5B、1.5B和3B模型之间的重叠热图。标记级重叠随着预算增加而增加,从1000个标记的0.63−0.700.63-0.700.63−0.70到3000个标记的0.74−0.780.74-0.780.74−0.78,表明在不同代理模型规模上一致的相关性估计。
G t-SNE探测特征可视化
为了研究从不同数据集和代理模型大小派生的句子特征如何变化,我们使用tSNE可视化探测特征。每个点代表一个句子级别的示例(无论是正类还是负类),基于来自不同代理模型的解码器注意力:通义千问-2.5-0.5B-Instruct、1.5B和3B。可视化是从SQuAD、NewsQA和HotpotQA中的6,000个样本生成的。
图4a显示了来自0.5B代理的特征空间。我们观察到SQuAD和NewsQA中的正类和负类形成可区分的簇,而HotpotQA特征更加纠缠——可能由于多跳监督的分散性质。这与我们的观察一致,即多跳句子相关性更难单独从注意力中学习。
图4b和4c描绘了在更大代理下的相同投影。值得注意的是,整体结构保持一致,支持我们关于基于注意力的相关性行为在不同模型规模上稳定的假设。
H 额外结果:训练规模消融
探测数据规模的影响。我们评估了训练规模如何影响探测质量。如表8所示,性能在500到3000个训练示例之间保持稳定,只有边际增益。这表明即使是一个小的探测集也可以支持有效的压缩。
I 注意力可视化示例
我们提供了来自一个2WikiMultihopQA示例的两个相邻块的定性可视化,这些块由通义千问-2.5-0.5B-Instruct代理模型处理,块大小为1024。每个可视化说明了三种相关性估计策略:
- 顶部:解码器最终标记的标记级别注意力权重。
-
- 中部:平均句子注意力,通过平均每个句子的标记级别注意力计算(Raw Attention基线)。
-
- 底部:我们基于探测的分类器输出的句子级别相关性预测。
如图5和6所示,标记级别注意力显示出强烈的汇效应,大部分权重集中在输入的最后一个标记上。句子级别平均稍微减少了噪音,但仍对这种汇效应敏感并且缺乏语义对齐。相比之下,Sentinel的探测
| 方法 | LongBench-En (通义千问-2.5-TB-Instruct, 2000-token constraint) | | | | | | | | LongBench-Zh (通义千问-2.5-TB-Instruct, 2000-token constraint) | | | | | | 整体AVG |
| — | — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| | SingleDoc | MultiDoc | Summ. | FewShot | *Synth. | *Code | En-AVG | SingleDoc | MultiDoc | Summ. | FewShot | Synth. | Zh-AVG | |
| Raw Attention (512) | 31.67 | 36.01 | 24.19 | 64.37 | 72.92 | 62.93 | 48.68 | 46.50 | 19.32 | 12.77 | 39.25 | 55.90 | 34.75 | 45.70 |
| Raw Attention (1024) | 33.11 | 38.39 | 24.22 | 63.27 | 77.67 | 62.14 | 49.80 | 56.24 | 20.99 | 13.61 | 44.50 | 72.76 | 41.62 | 48.47 |
| Raw Attention (2048) | 34.51 | 36.54 | 24.17 | 65.21 | 77.50 | 61.35 | 49.88 | 56.17 | 23.14 | 13.36 | 40.50 | 75.39 | 41.71 | 48.63 |
| Raw Attention (4096) | 34.79 | 41.17 | 24.20 | 65.59 | 77.08 | 62.46 | 50.88 | 56.90 | 23.94 | 13.42 | 43.50 | 75.70 | 42.69 | 49.66 |
| Sentinel (512) | 36.97 | 40.60 | 24.73 | 64.80 | 78.42 | 63.71 | 51.54 | 57.88 | 23.17 | 13.50 | 42.50 | 68.40 | 41.09 | 49.51 |
| Sentinel (1024) | 37.11 | 44.98 | 25.02 | 64.88 | 85.54 | 63.04 | 53.43 | 59.18 | 24.15 | 13.19 | 43.00 | 74.68 | 42.84 | 51.23 |
| Sentinel (2048) | 36.15 | 43.20 | 25.09 | 65.03 | 90.50 | 61.67 | 53.60 | 61.41 | 25.07 | 13.06 | 42.50 | 80.26 | 44.46 | 51.68 |
| Sentinel (4096) | 37.79 | 44.36 | 25.13 | 65.88 | 88.33 | 61.66 | 53.86 | 59.07 | 25.14 | 12.81 | 41.50 | 81.12 | 43.93 | 51.87 |
- 底部:我们基于探测的分类器输出的句子级别相关性预测。
表5:在固定2000-token约束下的不同块大小的性能。
| 方法 | LongBench-En (通义千问-2.5-TB-Instruct, 块大小 =1024=1024=1024 ) | | | | | | | | LongBench-Zh (通义千问-2.5-TB-Instruct, 块大小 =1024=1024=1024 ) | | | | | | | 整体AVG |
| — | — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| | SingleDoc | MultiDoc | Summ. | FewShot | *Synth. | *Code | En-AVG | SingleDoc | MultiDoc | Summ. | FewShot | Synth. | Zh-AVG | |
| Raw Attention (ratio 0.1) | 24.83 | 33.73 | 21.84 | 60.56 | 63.67 | 58.66 | 43.88 | 33.17 | 18.95 | 12.65 | 34.77 | 31.82 | 26.27 | 39.52 |
| Raw Attention (ratio 0.2) | 30.88 | 36.64 | 23.21 | 64.61 | 81.33 | 60.57 | 47.19 | 45.43 | 20.90 | 13.33 | 42.82 | 49.60 | 32.88 | 43.62 |
| Raw Attention (ratio 0.3) | 32.50 | 39.85 | 24.04 | 64.93 | 90.50 | 61.62 | 52.24 | 50.97 | 20.05 | 14.16 | 39.81 | 61.84 | 37.37 | 48.39 |
| Raw Attention (ratio 0.4) | 34.05 | 40.49 | 24.35 | 66.10 | 94.50 | 61.81 | 53.68 | 54.50 | 19.77 | 14.11 | 41.61 | 70.70 | 40.14 | 50.26 |
| Raw Attention (ratio 0.5) | 35.44 | 38.87 | 24.86 | 67.54 | 94.83 | 62.48 | 54.00 | 57.33 | 20.52 | 14.31 | 45.13 | 78.51 | 43.16 | 51.48 |
| Sentinel (ratio 0.1) | 34.28 | 38.14 | 22.93 | 60.69 | 75.04 | 58.86 | 48.33 | 56.91 | 22.89 | 13.06 | 38.64 | 56.04 | 37.51 | 45.78 |
| Sentinel (ratio 0.2) | 36.22 | 42.70 | 24.17 | 64.72 | 85.17 | 61.08 | 53.34 | 58.71 | 21.68 | 13.84 | 42.84 | 71.51 | 41.72 | 49.99 |
| Sentinel (ratio 0.3) | 36.79 | 42.42 | 24.66 | 66.72 | 92.00 | 62.11 | 54.12 | 58.05 | 22.37 | 14.31 | 41.02 | 77.78 | 42.71 | 51.54 |
| Sentinel (ratio 0.4) | 37.31 | 41.35 | 24.89 | 66.82 | 92.92 | 61.71 | 54.17 | 57.66 | 22.40 | 14.31 | 43.55 | 83.51 | 44.29 | 52.09 |
| Sentinel (ratio 0.5) | 38.22 | 40.98 | 24.90 | 65.56 | 94.75 | 61.58 | 54.10 | 59.21 | 21.18 | 14.68 | 43.40 | 83.59 | 44.41 | 51.99 |
表6:在压缩比(块大小 =1024=1024=1024 )下的性能。
分类器产生稀疏且可解释的预测,可靠地高亮显示跨块支持答案的句子。
J LLM评估设置
对于基于LLM的评估,我们采用了LongBench(Bai等人,2024)中使用的官方提示模板和解码设置,以确保一致性和可比性。解码参数在所有数据集中固定如下:
- 温度:0.0
-
- top_p:1.0
-
- 种子:42
-
- n:1
-
- 流:False
-
- 最大标记数:数据集特定(见表9)
- | 方法 | LongBench-Zh (GPT-3.5-Turbo, 3000-token constraint) | | | | | | | 压缩统计 | |
- | — | — | — | — | — | — | — | — | — | — |
- | | SingleDoc | MultiDoc | Summ. | FewShot | Synth. | AVG | Tokens | 1/r | |
- | LLMLingua | 35.2 | 20.4 | 11.8 | 24.3 | 51.4 | 28.6 | 3,060 | 5x | |
- | LLMLingua-2 | 46.7 | 23.0 | 15.3 | 32.8 | 72.6 | 38.1 | 3,023 | 5x | |
- | 在2000-token约束下评估 | | | | | | | | | | |
- | Sentinel (通义千问-2.5-0.5B-Instruct) | 64.8 | 25.1 | 14.3 | 38.0 | 89.0 | 46.2 | 1,932 | 5x | |
- | Sentinel (通义千问-2.5-1.5B-Instruct) | 63.3 | 24.9 | 14.8 | 40.3 | 95.0 | 47.6 | 1,929 | 5x | |
- | Original Prompt | 61.2 | 28.7 | 16.0 | 29.2 | 77.5 | 42.5 | 14,940 | - | |
表7:在GPT-3.5-Turbo上的LongBench-Zh性能比较。LLMLingua基线在3,000-token预算下进行评估。Sentinel仅使用2,000 tokens,但始终优于基线,展示出跨语言的有效压缩。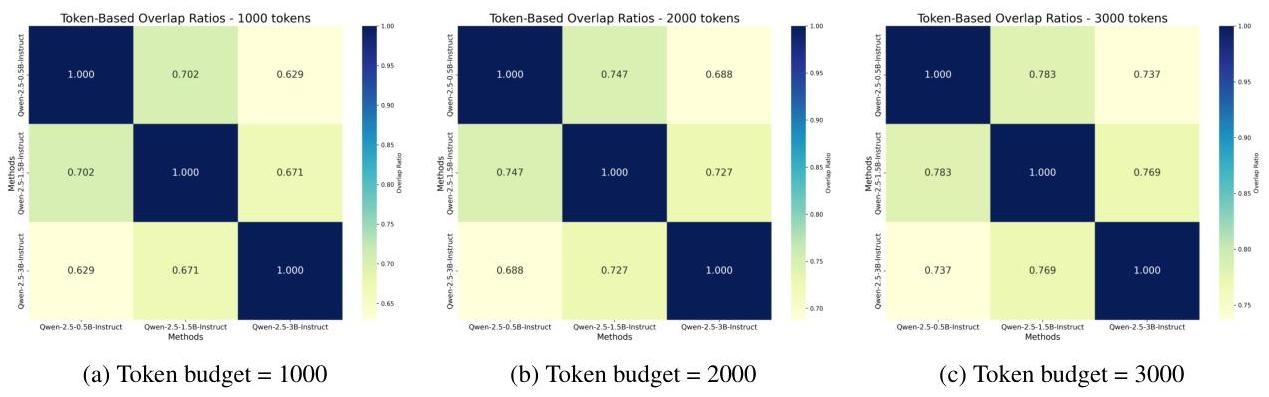
图3:在不同token预算下代理模型间的句子级重叠。更高的重叠表示在相关性估计上更强的一致性。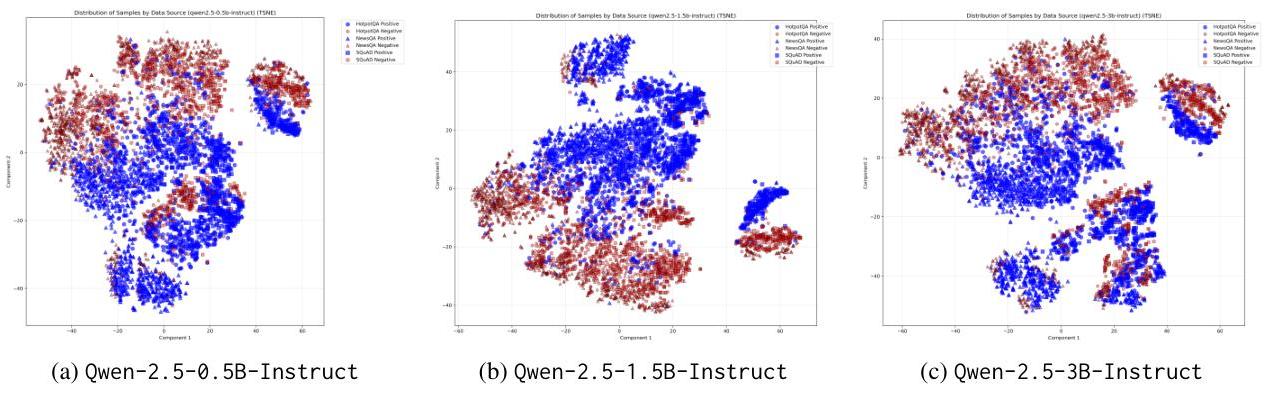
图4:在三个代理模型规模上的探测特征t-SNE可视化。每个点代表来自SQuAD、NewsQA或HotpotQA的句子。尽管模型大小不同,分布结构保持稳定——支持尺度不变的注意力行为。
| 方法 | LongBench-En (通义千问-2.5-7B-Instruct, 2000-token constraint) | LongBench-Zh (通义千问-2.5-7B-Instruct, 2000-token constraint) | 整体AVG | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SingleDoc | MultiDoc | Summ. | FewShot | *Synth. | *Code | En-AVG | SingleDoc | MultiDoc | Summ. | FewShot | |
| 通义千问-2.5-0.5B-Instruct (500) | 36.42 | 44.54 | 24.99 | 66.01 | 89.58 | 63.12 | 54.11 | 60.60 | 24.52 | 13.22 | 43.25 |
| 通义千问-2.5-0.5B-Instruct (1000) | 36.11 | 44.50 | 24.95 | 66.06 | 88.75 | 62.10 | 53.74 | 60.13 | 23.53 | 13.38 | 42.50 |
| 通义千问-2.5-0.5B-Instruct (2000) | 36.67 | 44.58 | 24.88 | 64.52 | 87.04 | 62.91 | 53.43 | 60.55 | 25.42 | 13.11 | 41.25 |
| 通义千问-2.5-0.5B-Instruct (3000) | 37.11 | 44.98 | 25.02 | 64.88 | 85.54 | 63.04 | 53.43 | 59.18 | 24.15 | 13.19 | 43.00 |
表8:在LongBench上不同探测规模(500, 1000, 2000, 3000)的0.5B模型的性能。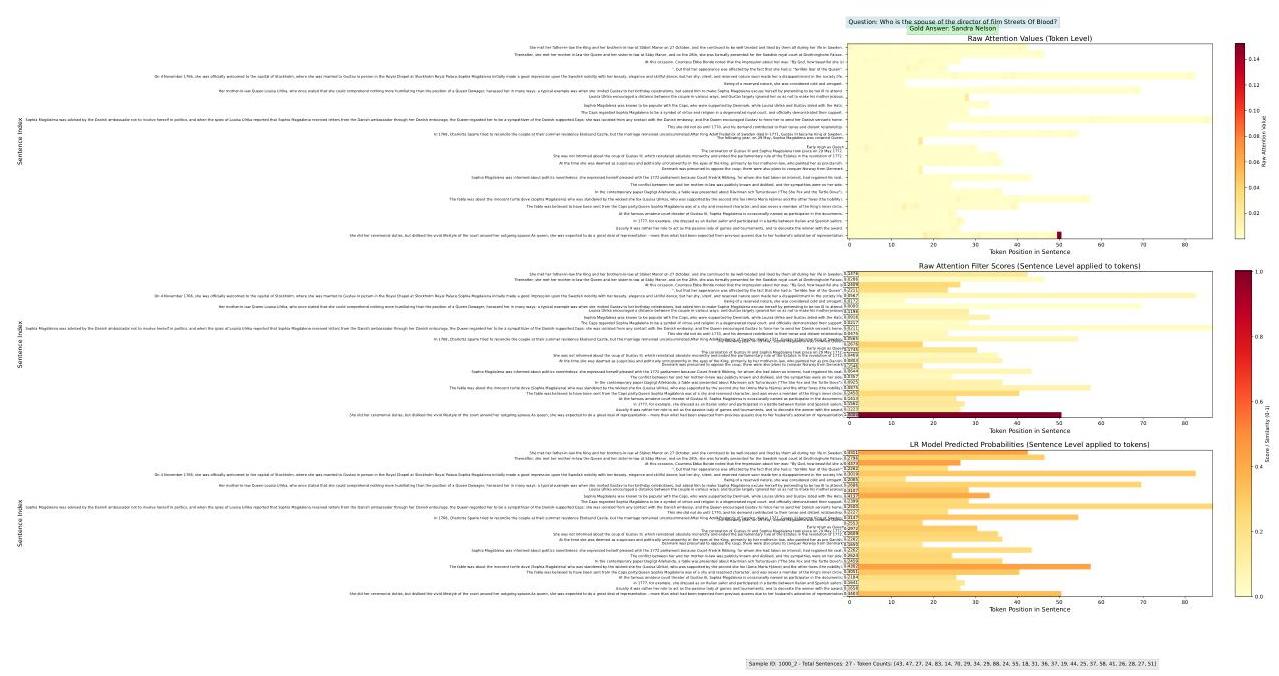
图5:2WikiMultihopQA示例中第二块的可视化。顶部:最终解码器标记的标记级别注意力权重。中部:平均标记注意力(Raw Attention基线)的句子级别得分。底部:基于探测的分类器的句子级别相关性预测。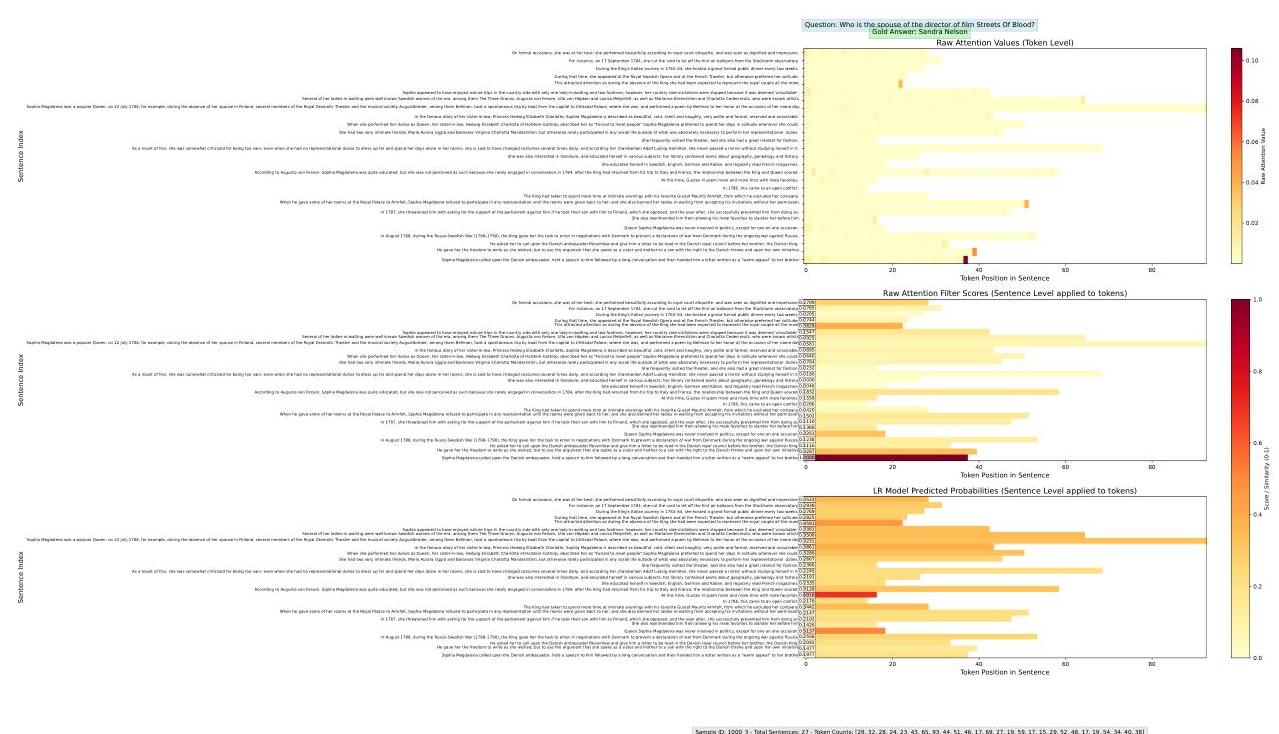
图6:2WikiMultihopQA示例中第三块的可视化。顶部:最终解码器标记的标记级别注意力权重。中部:平均标记注意力(Raw Attention基线)的句子级别得分。底部:基于探测的分类器的句子级别相关性预测。
| 数据集 | 最大标记数 |
|---|---|
| narrativeqa | 128 |
| qasper | 128 |
| multifieldqa_en | 64 |
| multifieldqa_zh | 64 |
| hotpotqa | 32 |
| 2wikimqa | 32 |
| musique | 32 |
| dureader | 128 |
| gov_report | 512 |
| qmsum | 512 |
| multi_news | 512 |
| vcsum | 512 |
| trec | 64 |
| triviaqa | 32 |
| samsum | 128 |
| lsht | 64 |
| passage_count | 32 |
| passage_retrieval_en | 32 |
| passage_retrieval_zh | 32 |
| lcc | 64 |
| repobench-p | 64 |
表9:每个数据集的最大生成标记数。
参考论文:https://arxiv.org/pdf/2505.23277

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 22
22 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)