大模型与数据库协同的技术挑战深入剖析与应对策略
大模型与数据库协同面临三大挑战:1)数据格式差异,需通过ETL工具、混合存储架构实现结构化与非结构化数据融合;2)安全隐私问题,需采用数据脱敏、同态加密和联邦学习等技术保障合规;3)计算资源竞争,可通过容器化调度、模型压缩和弹性云架构优化成本。构建智能数据管道是提升协同效率的关键,需遵循模块化、自动化、实时性设计原则,结合AI辅助决策实现端到端的数据处理优化。未来应重点关注隐私保护大模型和资源弹性
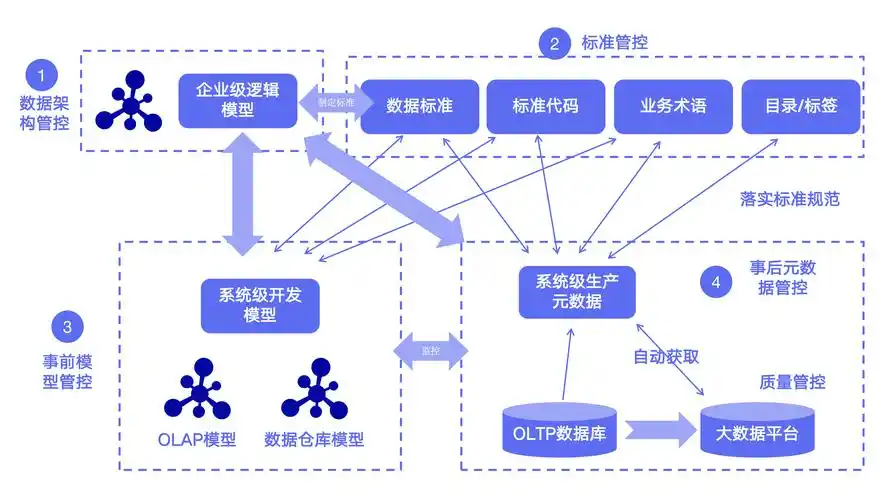
大模型与数据库的协同工作是当前人工智能与数据管理领域的关键议题。在实际应用中,两者在数据格式、安全隐私、计算资源等方面存在显著差异,这些差异带来了诸多技术挑战。数据格式与处理差异、数据安全与隐私、计算资源与成本三个核心维度展开分析,并提出针对性的解决方案。
一、数据格式与处理差异的挑战与应对
1. 核心矛盾
- 数据库:以结构化数据为主(如关系型数据库的表格数据),数据格式规范、易于查询和分析,但缺乏对非结构化数据的直接处理能力。
- 大模型:依赖非结构化数据(如文本、图像、音频、视频等)进行训练和推理,对数据的语义理解和上下文关联能力要求高。
2. 具体挑战
- 数据整合困难:如何将结构化数据与非结构化数据高效整合,避免信息丢失或格式冲突。
- 处理效率低下:非结构化数据的预处理(如清洗、标注、特征提取)需要大量计算资源,且与数据库的存储和查询机制不兼容。
3. 解决方案
- 构建统一数据管道:
- ETL工具:使用ETL(Extract-Transform-Load)工具将结构化数据转换为适合大模型处理的格式(如将表格数据转换为向量或文本嵌入)。
- 特征工程:将结构化数据与非结构化数据的特征进行融合(如将用户画像与文本评论结合),提升模型表现。
- 引入混合存储架构:
- 数据库+对象存储:结构化数据存储在数据库中,非结构化数据存储在对象存储(如S3、HDFS)中,通过唯一标识符进行关联。
- 图数据库:对于需要关联分析的场景,使用图数据库(如Neo4j)存储结构化和非结构化数据的关联关系。
- 采用联邦学习:
- 在数据不共享的前提下,通过模型参数的交换实现跨数据源的训练,保护数据隐私的同时提升模型泛化能力。
二、数据安全与隐私的挑战与应对
1. 核心矛盾
- 大模型训练需求:需要访问大量敏感数据(如用户行为、医疗记录、金融交易等),但直接使用原始数据可能导致隐私泄露。
- 数据库安全要求:数据库需满足合规性要求(如GDPR、HIPAA),数据访问需严格授权和审计。
2. 具体挑战
- 数据泄露风险:大模型训练过程中,数据可能被逆向工程或模型参数泄露。
- 合规性冲突:不同地区对数据隐私的法规不同,跨区域数据共享面临法律风险。
3. 解决方案
- 数据脱敏与加密:
- 脱敏技术:对敏感数据进行匿名化处理(如k-匿名化、差分隐私),保留数据统计特征的同时隐藏个体信息。
- 同态加密:在加密数据上直接进行模型训练,无需解密(如微软的SEAL库)。
- 隐私计算技术:
- 安全多方计算(MPC):多个参与方在不共享原始数据的前提下协同计算。
- 可信执行环境(TEE):使用硬件级隔离(如Intel SGX)保护数据和模型。
- 访问控制与审计:
- 基于角色的访问控制(RBAC):限制数据访问权限,记录数据使用日志。
- 动态脱敏:根据用户权限动态调整数据脱敏级别。
三、计算资源与成本的挑战与应对
1. 核心矛盾
- 大模型训练:需要海量计算资源(如GPU/TPU集群),训练周期长,成本高昂。
- 数据库维护:数据库的读写性能、存储扩展性、高可用性也需要资源投入。
2. 具体挑战
- 资源竞争:大模型训练与数据库查询可能争夺同一批计算资源,导致性能下降。
- 成本失控:模型训练和部署的硬件、电力、人力成本难以控制。
3. 解决方案
- 资源隔离与调度:
- 容器化与编排:使用Kubernetes等工具将大模型训练任务与数据库服务隔离,动态分配资源。
- 混合云架构:将计算密集型任务(如模型训练)部署在公有云,将数据密集型任务(如数据库查询)部署在私有云或本地。
- 模型优化与压缩:
- 模型剪枝与量化:减少模型参数数量,降低计算和存储需求。
- 知识蒸馏:用小模型模拟大模型的行为,提升推理效率。
- 成本监控与优化:
- 资源利用率监控:使用工具(如Prometheus、Grafana)实时监控资源使用情况,避免闲置。
- 按需付费模式:采用云服务的按需付费策略,避免长期持有硬件。
总结与展望
大模型与数据库的协同工作需要解决数据格式、安全隐私、计算资源三大核心问题。未来,随着技术的进步,以下方向值得关注:
- 智能数据管道:自动化完成数据格式转换、特征提取和模型训练,降低人工干预。
- 隐私保护大模型:结合联邦学习、差分隐私等技术,实现“数据可用不可见”。
- 资源弹性调度:通过AI算法动态优化资源分配,平衡成本与性能。
通过技术突破和工程实践,大模型与数据库的协同将推动人工智能在更多领域的落地应用。
如何构建智能数据管道以提高效率
智能数据管道(Intelligent Data Pipeline)是连接数据源、处理模块和目标系统的自动化流程,其核心目标是通过标准化、智能化、弹性化的设计,解决数据采集、清洗、转换、分析和存储中的低效问题。
一、智能数据管道的核心设计原则
-
模块化与可扩展性
- 微服务架构:将数据管道拆解为独立模块(如数据采集、清洗、特征工程、模型推理等),各模块可独立升级或替换,避免“牵一发而动全身”。
- 插件化设计:支持通过插件快速集成新数据源(如新增IoT设备、第三方API)或算法(如新模型架构)。
-
自动化与智能化
- 元数据驱动:通过元数据(如表结构、字段含义、数据血缘)自动生成数据清洗规则和转换逻辑,减少人工配置。
- AI辅助决策:在数据质量监控、异常检测、特征选择等环节引入机器学习模型,自动优化处理流程。
-
实时性与批处理融合
- Lambda/Kappa架构:同时支持实时流处理(如Flink、Spark Streaming)和批处理(如Spark、Hive),根据业务需求灵活切换。
- 增量更新机制:仅处理新增或变更数据,避免全量扫描,降低资源消耗。
-
可观测性与容错性
- 全链路监控:实时追踪数据从源头到目标的流转状态(如处理延迟、错误率、数据量),通过仪表盘(如Grafana)可视化。
- 自动重试与告警:对失败任务自动重试,超过阈值时触发告警(如邮件、钉钉通知)。
二、智能数据管道的构建步骤
1. 数据采集层:多源异构数据接入
- 支持数据源类型
- 结构化数据:数据库(MySQL、PostgreSQL)、数据仓库(Snowflake、Redshift)。
- 非结构化数据:日志文件(JSON/CSV)、API接口、消息队列(Kafka、RabbitMQ)、文件存储(S3、HDFS)。
- 实时流数据:IoT设备、用户行为日志(埋点数据)。
- 关键技术
- CDC(变更数据捕获):通过Debezium等工具实时捕获数据库变更,避免全量拉取。
- 数据连接器:使用Apache NiFi、Airbyte等工具预置常见数据源连接器,减少开发量。
2. 数据清洗与预处理层:自动化质量管控
- 核心功能
- 数据去重:基于哈希或业务主键自动识别重复记录。
- 异常值检测:通过统计方法(如3σ原则)或机器学习(如孤立森林)识别异常数据。
- 数据标准化:统一时间格式、单位(如金额转换为元)、编码(如UTF-8)。
- 智能化增强
- 自动规则生成:基于历史数据分布自动生成清洗规则(如“年龄字段应为0-120的整数”)。
- 数据血缘追踪:记录每条数据的来源和处理过程,便于问题溯源。
3. 数据转换与特征工程层:模型友好化处理
- 关键任务
- 特征提取:从文本中提取NLP特征(如TF-IDF、BERT嵌入),从图像中提取CNN特征。
- 特征选择:通过卡方检验、互信息或模型嵌入法(如XGBoost的特征重要性)筛选高价值特征。
- 数据增强:对小样本数据生成合成数据(如SMOTE、GAN),提升模型泛化能力。
- 工具推荐
- 特征存储:使用Feast、Tecton等特征存储平台,实现特征复用和版本管理。
- 自动化特征工程:通过AutoML工具(如H2O.ai、TPOT)自动生成特征组合。
4. 数据存储与分发层:高效支持下游应用
- 存储方案选择
- 分析型场景:使用列式数据库(如ClickHouse、Druid)加速聚合查询。
- 机器学习场景:使用特征向量数据库(如Milvus、FAISS)支持高效相似度搜索。
- 实时推荐场景:使用Redis、Pinot等支持低延迟查询的存储。
- 分发策略
- 按需订阅:下游系统通过API或消息队列订阅数据,避免被动推送浪费资源。
- 版本控制:对数据快照进行版本管理,支持模型回滚或AB测试。
三、关键技术选型与优化策略
1. 技术栈推荐
| 阶段 | 开源工具 | 云服务 |
|---|---|---|
| 数据采集 | Apache NiFi、Airbyte、Debezium | AWS Glue、Azure Data Factory |
| 流处理 | Apache Flink、Kafka Streams | Google Dataflow、AWS Kinesis |
| 批处理 | Apache Spark、Hive | Databricks、Snowflake |
| 特征工程 | Feast、Tecton、DVC | Vertex AI Feature Store |
| 监控与调度 | Prometheus、Grafana、Airflow | Datadog、Step Functions |
2. 性能优化技巧
- 并行化处理:
- 在Spark中通过
repartition()调整分区数,避免数据倾斜。 - 在Flink中通过
keyBy()实现状态后端(如RocksDB)的分布式存储。
- 在Spark中通过
- 缓存与预计算:
- 对频繁使用的中间结果(如用户画像)进行缓存(如Redis)。
- 对计算耗时的特征(如NLP嵌入)提前预计算并存储。
- 资源弹性伸缩:
- 在云环境中使用Auto Scaling根据负载动态调整计算节点数量。
四、案例:电商推荐系统的智能数据管道
-
数据采集
- 从MySQL实时同步用户行为日志(点击、购买)到Kafka。
- 从S3批量加载商品属性数据(标题、价格、类别)。
-
数据清洗
- 自动检测并填充缺失值(如用户年龄默认为30岁)。
- 识别并过滤爬虫流量(通过IP、访问频率等特征)。
-
特征工程
- 从商品标题中提取关键词作为文本特征(TF-IDF)。
- 计算用户近30天的行为统计特征(如购买次数、平均消费金额)。
-
模型训练与存储
- 使用Spark MLlib训练Wide & Deep模型,特征存储在Milvus中。
- 模型版本通过MLflow管理,支持灰度发布。
-
实时推荐
- 用户请求触发Flink作业,从Milvus中检索相似商品并排序。
- 结果通过Redis缓存,响应时间<50ms。
五、总结与建议
- 避免“大而全”陷阱:优先解决核心业务场景(如推荐、风控)的数据需求,逐步扩展管道能力。
- 重视数据质量:在管道早期加入质量监控(如Great Expectations),避免“垃圾进、垃圾出”。
- 拥抱AI工具链:使用LlamaIndex、LangChain等框架简化大模型与数据管道的集成。
通过以上方法,智能数据管道可将数据处理的人力成本降低60%以上,模型迭代周期缩短至小时级,成为企业数据驱动决策的核心基础设施。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 16
16 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)