Qwen团队新发现:大模型推理能力的提高仅由少数高熵 Token 贡献
逻辑分叉、连词是提高推理能力的关键
论文标题
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
论文地址
https://arxiv.org/pdf/2506.01939
代码地址
https://shenzhi-wang.github.io/high-entropy-minority-tokens-rlvr
作者背景
Qwen Team,清华大学
前言
“二八定律”又称帕累托定律,它揭示了生活中常见的投入、产出不平衡现象,即少量(20%)原因主导(80%)了最终结果。而对于大模型推理能力而言,这一不平衡现象可能更加极端:作者发现仅使用20%的token进行推理训练,效果甚至能超越全梯度更新,这意味着我们可以更高效地分配计算资源而非对所有token一视同仁,同时也为探索大模型“思考”方式提供了有趣的线索
动机
当前的 LLM 训练方法一般都未考虑不同token之间的差异,没有探究不同 token 在推理过程中的贡献差异,这可能导致大模型错失性能提升的机会——模型可能把学习精力浪费在大量无关紧要的部分,而没有重点加强真正影响推理走向的步骤;此外,冗长的推理链路也让基于RL的推理训练方法更新困难
因此,本文从 “token 熵” 的视角出发,剖析了不同 token 对推理训练的贡献机制,以设计更高效的训练模式
本文方法
一、何为 token 熵
本文提到的 “token 熵” 并不是针对于某个特定 token,而是在特定位置 t,对解码不确定性的度量

二、推理中熵的模式
作者发现,生成推理链时每个位置的 token 熵值极度不均衡:只有少数 token 以高熵生成,而大多数 token 以低熵输出。具体地,80% 的token 熵低于0.67
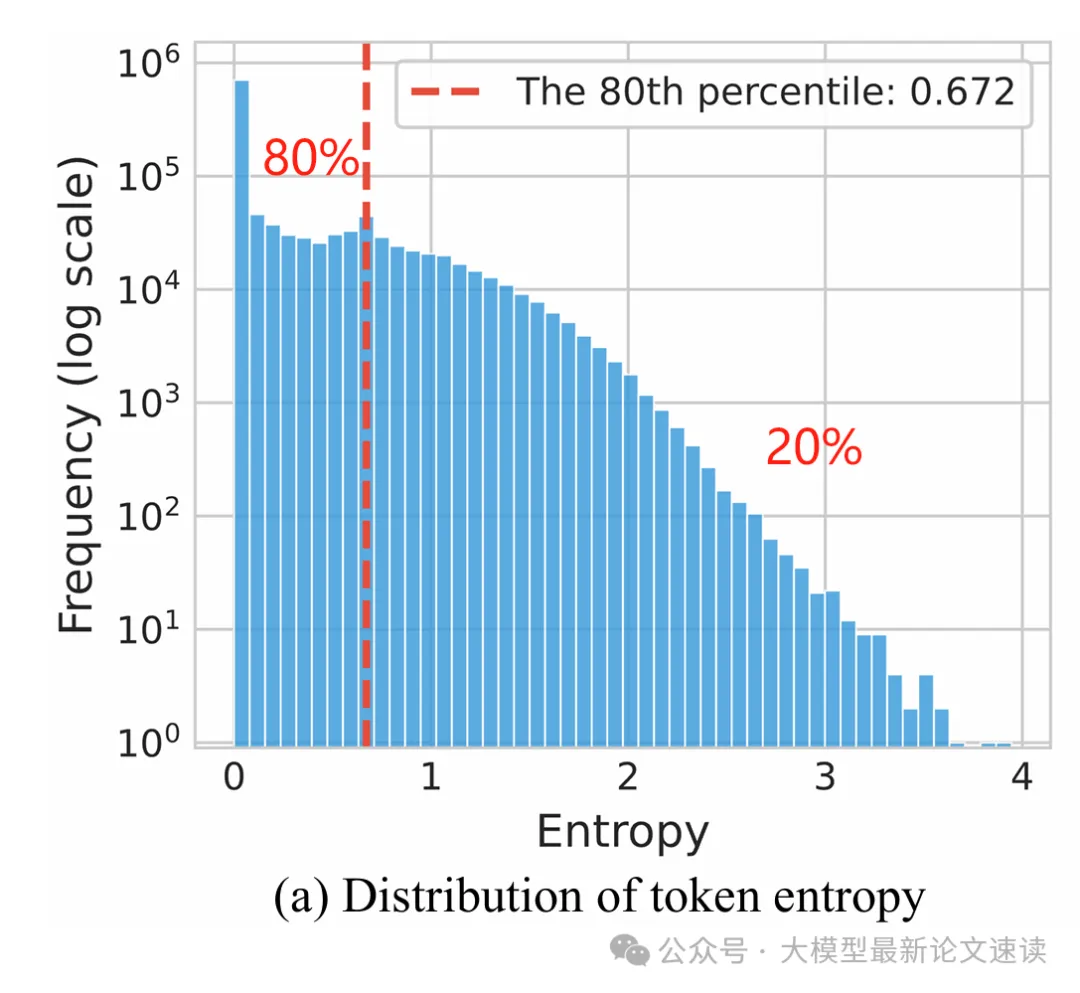
熵最高的 token 通常用于连接两个连续推理部分之间的逻辑关系,比如wait、however 和 unless 等(对比或转折),thus 和 also(递进或补充),since 和 because (因果关系);在数学推导中,suppose、assume、given 和 define 等 token 频繁出现,用于引入假设、已知条件或定义
熵最低的 token 则倾向于完成当前句子部分或结束单词的构建,均表现出高度的确定性
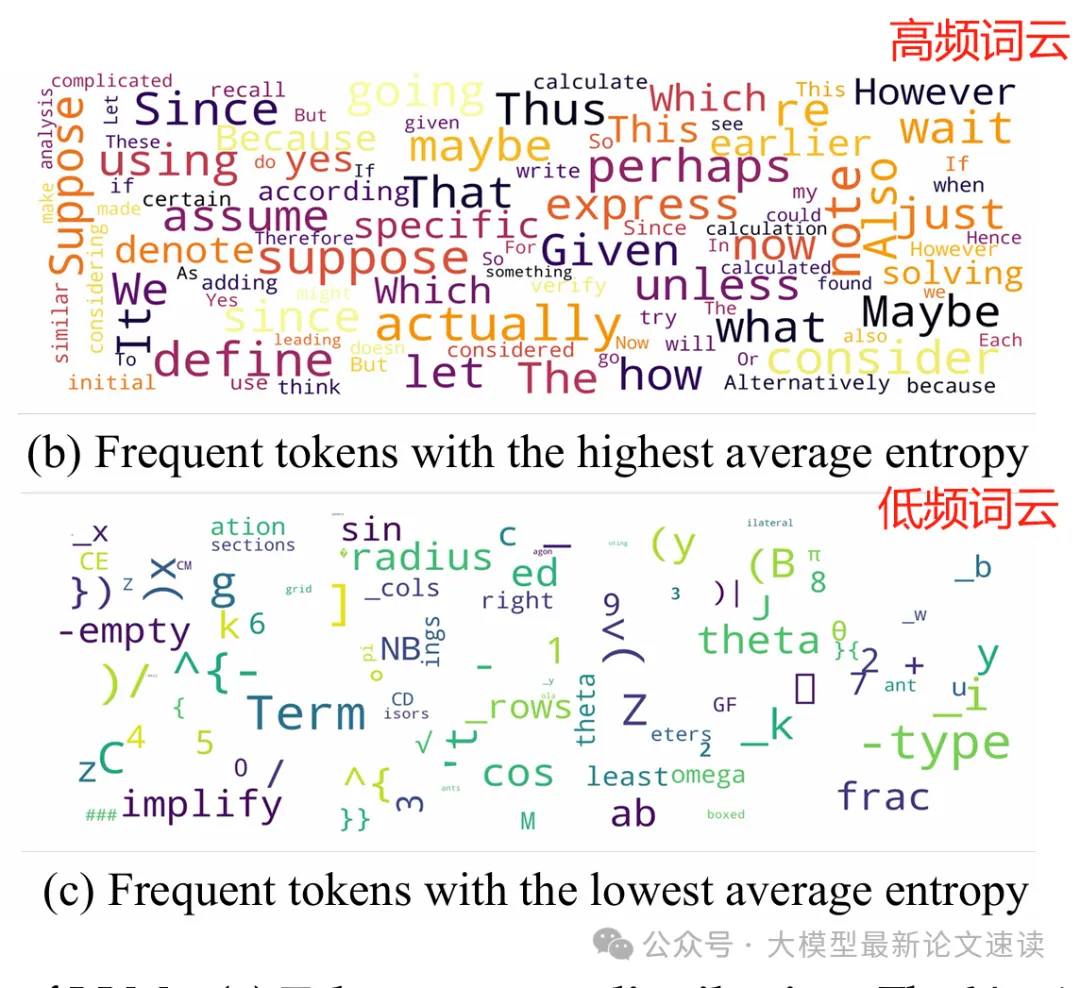
作者形象地将高熵 token 称为 “forking tokens”(分叉token),因为它们就像树状推理路径的分叉口,决定了后续推理走向
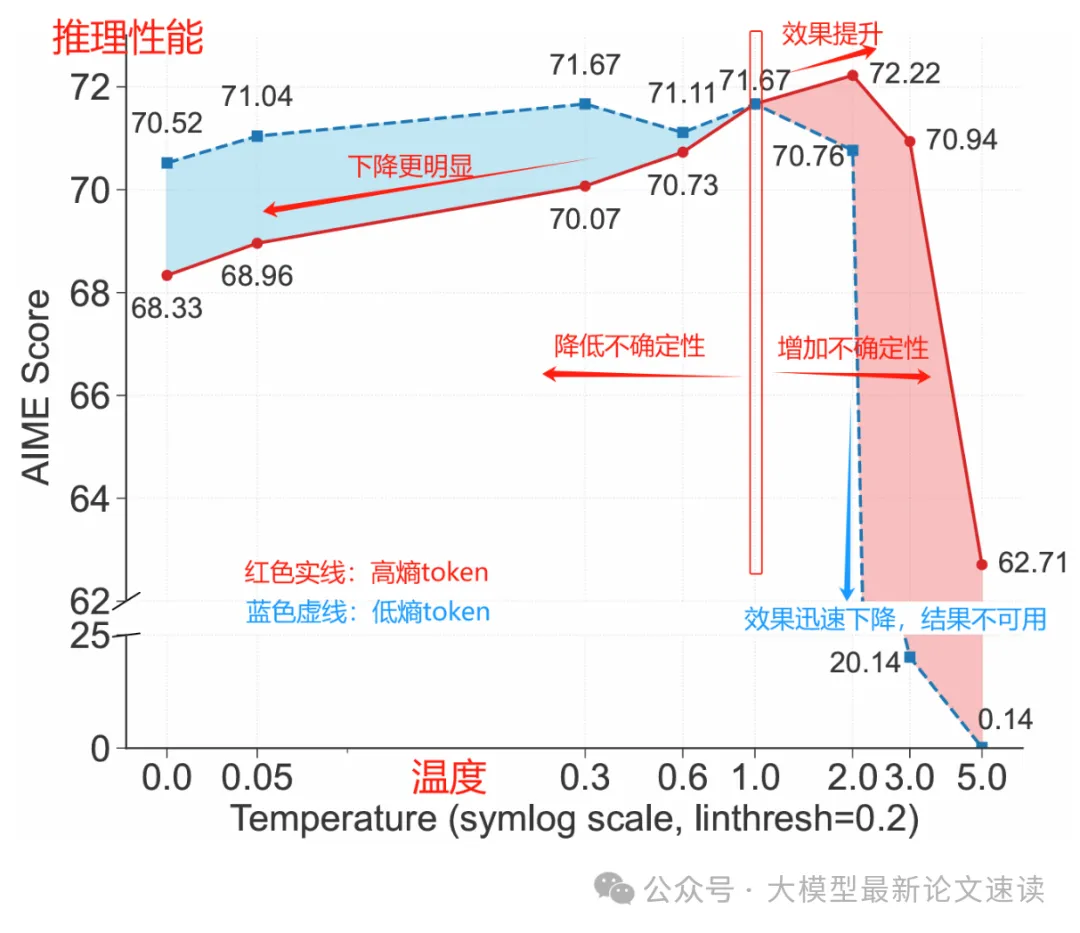
三、随机性控制实验
为了验证高熵 token 对推理性能的关键作用,作者通过控制解码温度来调整这些 token 在生成过程中的随机性。结果表明,适当提高高熵 token 的熵值可以提高推理正确率;反之,强行降低其熵值则会显著损害性能。这充分证明了在关键分叉 token 处保持较高的不确定性和探索度,对提高推理质量大有裨益。可见,少数高熵 token 确实是推理过程中应重点关注的“要害”
四、强化学习中的熵模式变化
RL 训练是当前提高大模型推理能力的常用方法,那么在 RL 过程中,熵的模式又是如何变化的呢?
作者设计了这样的实验:利用 DAPO 算法训练 Qwen3-14B 模型,保存不同训练阶段下的 checkpoint,分别在各种数学推理基准上进行采样,识别各中间模型的高熵 token,然后分别计算这些它们与原始模型、训练完毕后的模型对应的高熵 token 重叠率,结果如下:

可见在 RL 训练过程中,尽管与基础模型的重叠逐渐减少,但在收敛时(第 1360 步),基础模型的重叠率仍保持在 86% 以上,这表明 RL 训练在很大程度上保留了基础模型的高熵 token
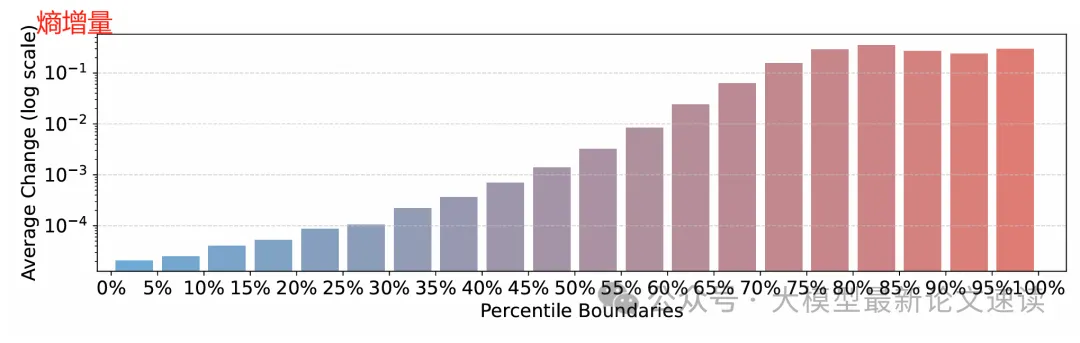
那么具体的熵值又是如何变化呢?下图是作者的统计结果,可见基础模型中初始熵较高的 token 在 RL 后往往表现出更大的熵增,这与三中的实验结论不谋而合,表明 RL 带来推理性能提升的原因之一,很可能就是因为高熵 token 的不确定性更强了,提高了大模型推理的灵活性
五、仅对高熵token做RL训练
既然这些高熵 token 是模型推理能力提升的关键,那么我们便可以尝试通过 RL 仅学习这些 token 产生的梯度,其余 token 统统 mask 掉,从而定量分析这些关键结点对推理能力的贡献程度,实验细节在下一章介绍
实验结果
一、推理性能测试
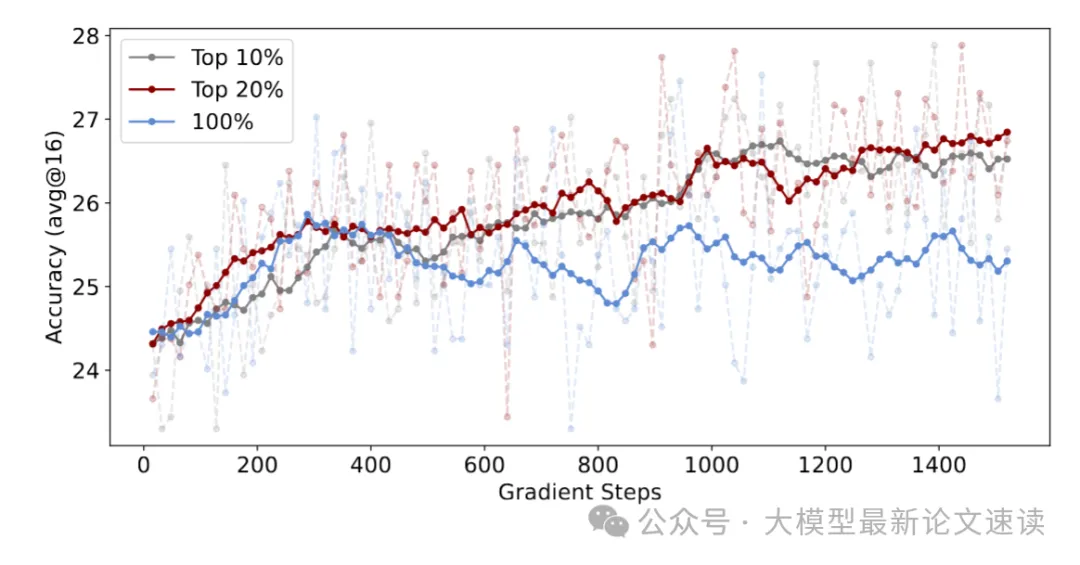
基于verl框架,使用相同超参数 DAPO 算法,分别对不同规模的Qwen模型做全梯度优化、不同熵阈值的部分token优化,然后在6 个常用于评估推理能力的标准数学推理基准上进行测试,并报告平均准确率及每个响应的平均 token 数量,结果如下:
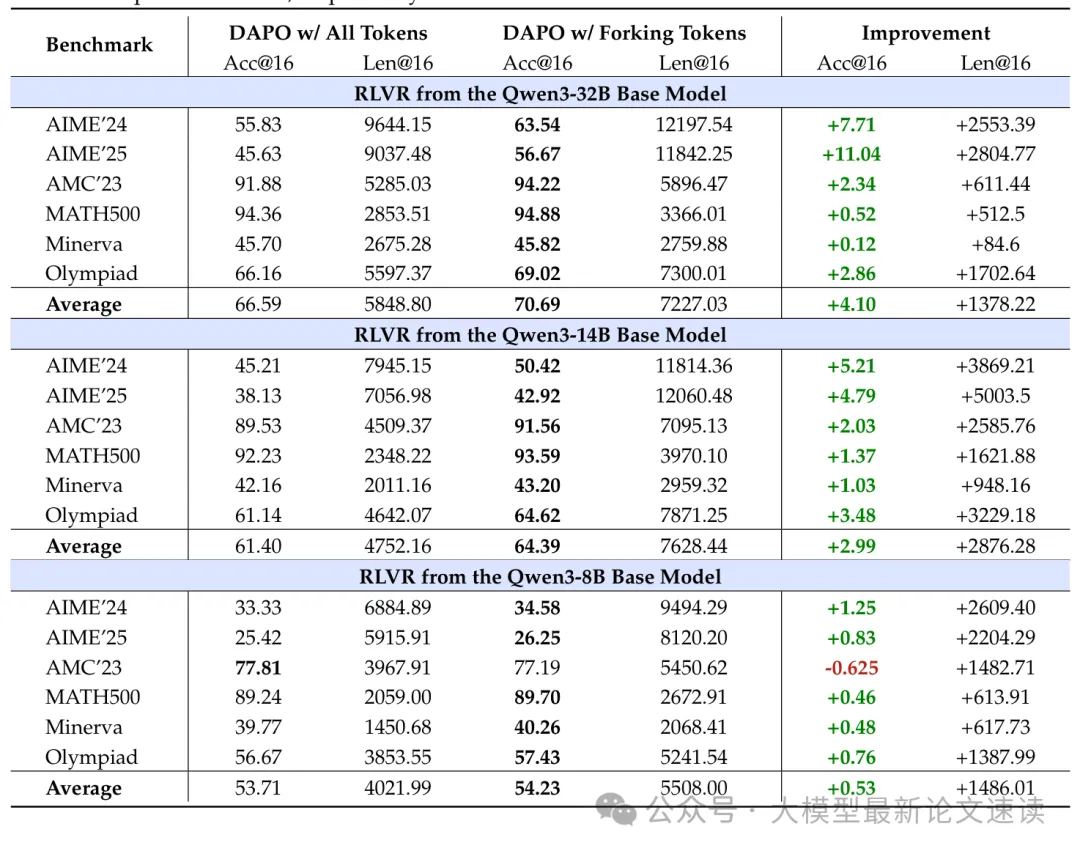
实验结果令人惊讶,丢弃底部 80% 的低熵 token 并不会降低推理性能,甚至可以在六个基准上带来提升,这表明在 RL 过程中推理能力的提升主要由高熵 token 驱动,而低熵 token 可能对推理性能影响甚微甚至有害。作者验证了判定是否为fork tokens的不同阈值,结果表明以20%作为判定标准效果最好
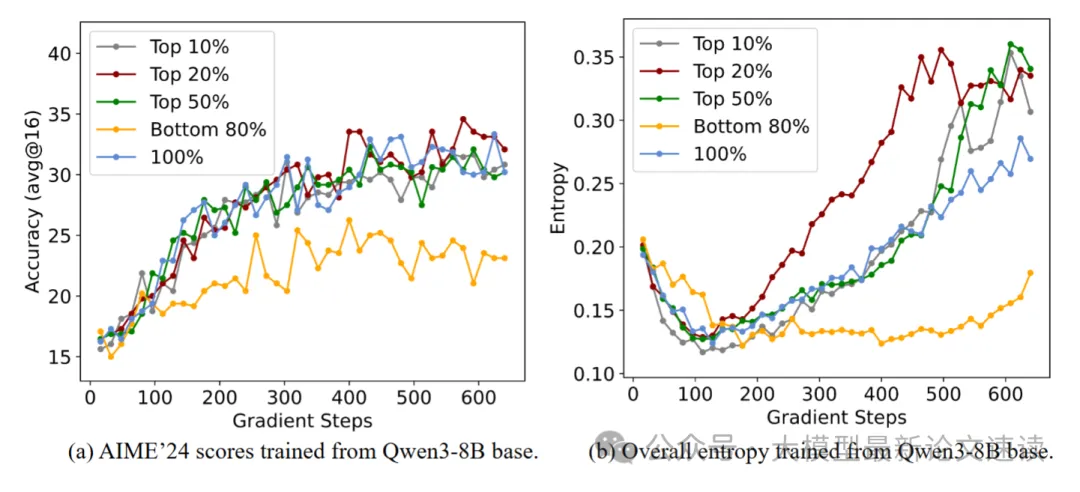
相反地,如果仅对低熵token做优化,模型的推理性能将明显下降
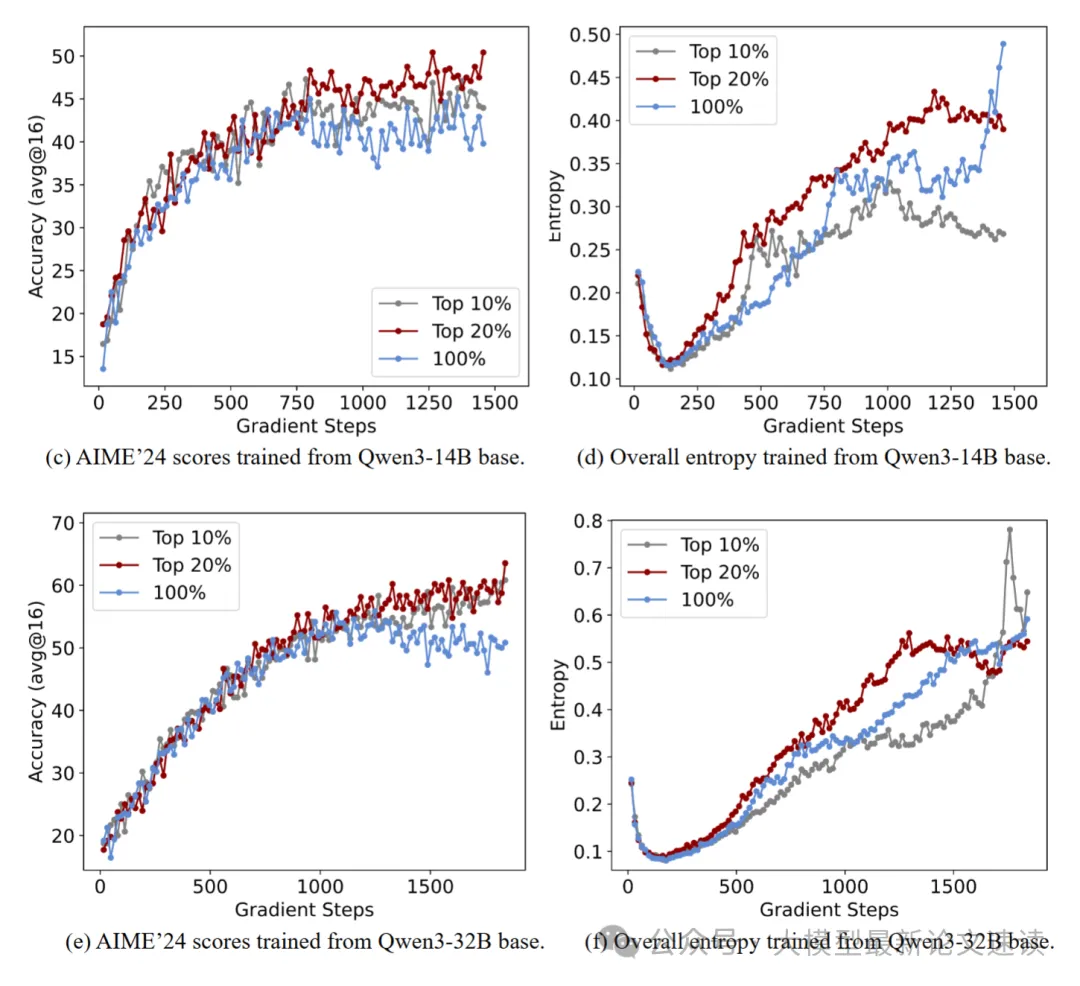
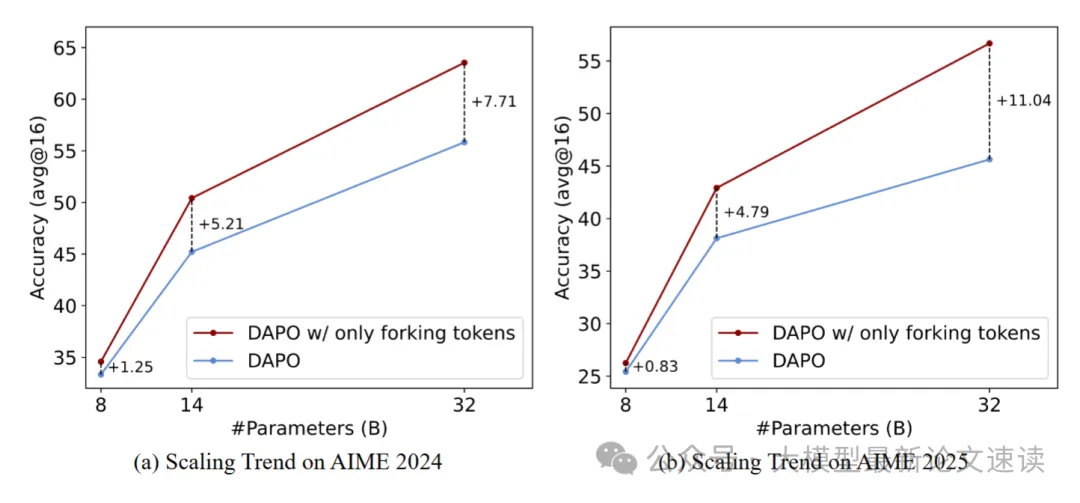
二、规模效应
在Qwen不同尺寸模型上进行测试,表现出了明显的规模效应
三、泛化能力测试
作者在域外基准(LiveCodeBench,代码任务)上进行测试,结果表明本文所提出的方法具有较好的泛化能力
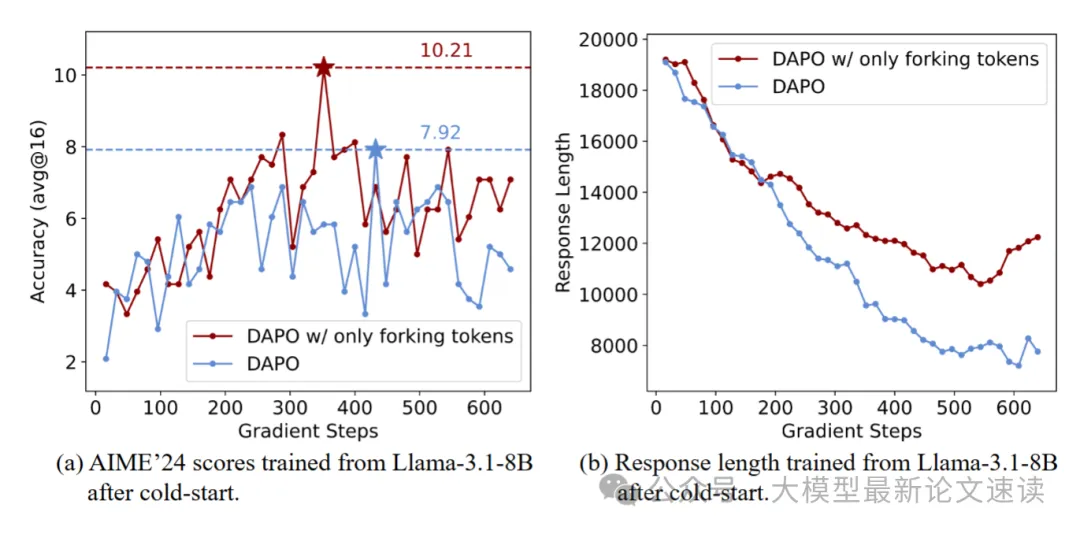
关于非Qwen模型的适配性,作者也在 llama-3.1 模型上做了测试

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 41
41 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)