Mamba论文研读笔记:从模型结构到写作思路的探索
本文深入解析了Mamba论文的核心创新与写作脉络。从模型结构出发,系统梳理了Mamba的关键技术突破:选择性状态空间(S6) 与硬件感知算法(核融合、并行扫描、重计算),以线性复杂度达成媲美Transformer的性能。笔记还拆解了论文的写作框架——从问题驱动、直觉引导(合成任务论证)到全面实验验证,赞其严谨性与技术深度。此外,也整理了相关术语,拓展了MLP知识,分享了自己的学习感受与方法(AI工
1. 论文信息
-
论文标题: Mamba: Linear-Time Sequence Modeling with Selective State Spaces
-
作者/团队: Albert Gu, Tri Dao
-
发表会议/期刊: arXiv(预印本平台)-2024
-
论文链接: [2312.00752] Mamba
2. 术语
2.1 通用术语
| 术语 | 中文释义 | 解释 |
|---|---|---|
| LLM (large language models) | 大型语言模型 | 一种非常庞大的人工智能模型,它能“读懂”文字、“写出”内容,还能回答问题、写代码、翻译语言等。 |
| FM (Foundation Model) | 基础模型 |
在大规模数据上预先训练好的、可以适应各种下游任务的通用大模型。包含 Backbone + 预训练任务头(如 LM head),强调零样本 / 少样本迁移能力。 |
| Backbone | 主干网络 | 模型的特征提取核心,负责将原始输入转化为高层特征表示。通常是深度网络的前几层(如 CNN 中的卷积层、Transformer 中的编码器),不包含任务特定头(如分类器、检测头)。 |
SOTA (State-of-the-Art) |
行业领先 | 指的是“当前最高技术水平”或“最佳实践”。它用来形容在特定任务或领域中性能最优的模型或方法。随着研究进展,SOTA 会不断被新的研究成果所超越 |
| Baseline | 基线 | 是指在实验中用来衡量模型性能的一种标准参照物。基线模型通常是已经被广泛验证并具有一定代表性的经典模型,如ResNet、VGGNet、AlexNet等。 |
| SSM (State Space Model) | 状态空间模型 |
一种特殊的序列模型,它内部维护一个隐藏状态 ( |
| S4 (Structured State Space) | (第四代)结构化状态空间 | SSM 的一种高效实现版本。通过给内部参数 A 矩阵加上特殊的结构(通常是对角线结构),使得计算(无论是循环还是卷积形式)可以变得非常快。它是 Mamba 的“前辈”。 |
| S6 (Selective State Space) | 选择性状态空间 | Mamba 的核心创新!在 S4 的基础上,让关键参数 Δ (步长), B (输入影响), C (输出影响) 不再是固定不变的,而是变成当前输入 x 的函数 (Δ, B, C = f(x))。这让模型能根据看到的内容动态决定记住什么、忽略什么、以及如何传播信息,解决了 S4 在内容理解上的弱点。它就是 Mamba 块里的“大脑”。 |
| Transformer | 变换器模型 | 用自注意力机制对序列中各位置进行信息路由,非常强大但计算成本高。 |
| RNN (Recurrent Neural Network) | 循环神经网络 | 一种带有时间记忆的神经网络,适合处理序列信息。 |
| CNN (Convolutional Neural Network) | 卷积神经网络 | 一种适合图像和时序数据的网络,通过滑动窗口提取局部特征。 |
| MHA (Multi-Head Attention) | 多头注意力 | Transformer 的核心模块,用多个注意力头来捕捉不同位置之间的依赖关系。 |
| MLP (Multi-Layer Perceptron) | 多层感知机 | 常规的前馈神经网络,由多个全连接层组成。具体可见 3.1.1.2.2 |
| GAU (Gated Attention Unit) | 门控注意单元 | 一种替代传统注意力机制的简化模块,结合注意力和门控机制。 |
| LTI (Linear Time Invariant) | 线性时不变 | S4 等早期 SSM 的核心限制。模型的参数在时间上不变,运算过程始终一致,效率高但灵活性差,无法根据内容做决策。 |
| Token | 令牌 | 是模型认知语言的基本单位; 模型处理的是 token 数,而不是“字”或“句子”。 |
2.2 Mamba 架构相关
| 术语 | 中文释义 | 解释 |
|---|---|---|
| Hardware-aware Algorithm / Selective Scan | 硬件感知算法 / 选择性扫描 |
Mamba 的“黑科技”引擎。因为 S6 不是 LTI,不能用高效的卷积,只能用循环计算。为了解决循环计算慢和内存大的问题,它通过并行扫描、内核融合与重计算让 S6 在 GPU 上跑得飞快,内存也省。 |
| Scan | 扫描(递推)操作 | 一种高效实现时间序列计算的方式,逐步计算每一时刻的状态。 |
| Kernel Fusion | 核融合 | 将多个计算步骤合并在一个 GPU 操作中,减少内存访问,提高速度。 |
| Recompute | 重计算 | 为了省内存,训练时不保存中间结果,而在反向传播时重新计算一遍。 |
| FlashAttention | 高效注意力实现 | 一种特别为 GPU 优化的注意力计算方式,用更少内存和更快速度实现自注意力。 |
2.3 硬件相关
| 术语 | 中文释义 | 解释 |
|---|---|---|
| HBM (High Bandwidth Memory) | 高带宽内存 | GPU 的主显存。容量大(如 80GB),但相对慢,访问耗能高。是存储模型参数和大型激活张量的地方。 |
| SRAM (Static Random-Access Memory) | 静态随机存取存储器 | GPU 芯片上的超高速缓存。容量很小(MB 级别),但速度极快,访问耗能低。Mamba 的硬件感知算法核心就是尽可能在 SRAM 里完成关键计算(扫描),避免和 HBM 反复搬运大数据。 |
2.4 任务 & 数据集
| 术语 | 中文释义 | 解释 |
|---|---|---|
| Induction Heads | 归纳头 | 另一个重要的合成测试任务。被认为是 LLM 上下文学习能力的核心机制之一。任务模式如:序列中出现过 A B ... A,模型需要预测下一个是 B(从上下文中回忆出 A 后面跟的是 B)。目的: 测试模型能否根据上下文关联进行回忆推理。Mamba (S6) 能完美解决并外推到百万长度,其他模型不行。 |
| The Pile | 一个大型的、开源的英文文本数据集,常用于训练和评估大型语言模型 (LLM)。论文在它上面做语言模型缩放实验。 | |
| HG38 | 人类基因组的参考序列版本。论文用它来训练和评估 DNA 序列模型。 | |
| SC09 | 一个语音命令数据集,包含说 0-9 十个数字的 1 秒录音片段。论文用它评估无条件语音生成质量。 | |
| YouTubeMix | 一个钢琴音乐数据集。论文用它评估长上下文音频建模能力。 |
2.5 评价指标
| 术语 | 中文释义 | 解释 |
|---|---|---|
| PPL (Perplexity) | 困惑度 | 语言模型最主要的评价指标。衡量模型预测下一个词的不确定性有多“困惑”。数值越低越好。例如,PPL=10 意味着模型平均在约 10 个可能的候选词中就能猜中下一个词。 |
| Downstream Task Accuracy | 下游任务准确率 | 模型在预训练后,不进行特定任务微调(零样本)或微调后,在具体应用任务(如常识推理:LAMBADA, HellaSwag, PIQA, ARC, WinoGrande;DNA分类;语音生成质量)上做对的比率。越高越好。 |
| BPB (Bits Per Byte) | 每字节比特数 | 用于评估连续数据(如音频、图像)生成模型的指标(可看作连续版本的困惑度)。表示模型压缩每个数据点(如音频样本)平均需要多少比特。越低越好,意味着模型对数据分布建模得越精准。 |
| FID (Fréchet Inception Distance) | 感知相似度距离 | 生成模型 (如图像、语音) 常用的评价指标。通过一个预训练网络(如 Inception Net)计算生成样本和真实样本在特征空间分布的距离。数值越低越好,表示生成样本的质量和多样性越接近真实数据。 |
| Throughput | 吞吐量 | 在推理(生成)场景下,指模型每秒能产生多少个词(token)。越高越好,代表推理速度越快。论文展示 Mamba 的吞吐量是同等大小 Transformer 的 5倍。 |
| Context Length | 上下文长度 | 模型一次能考虑和处理的序列长度 (L)。Transformer 通常受限于几 K (如 2K, 4K, 8K, 32K),而 Mamba 论文展示了处理高达 1M (一百万) 长度序列的能力和优势。 |
3. 理论解构
3.1 Mamba 架构图
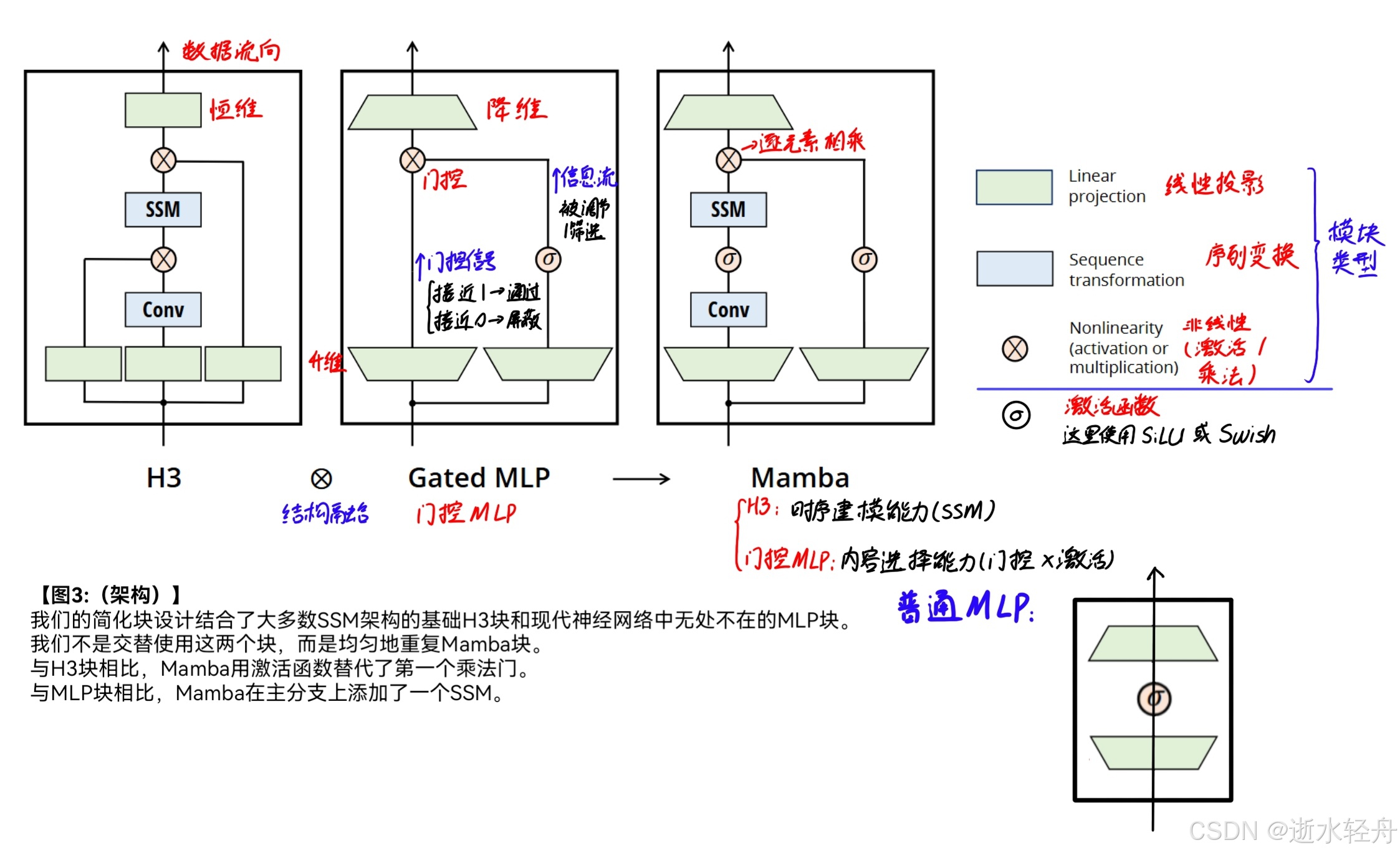
3.1.1 三个结构
3.1.1.1 H3
是早期将SSM 模块嵌入到语言模型中的一种结构设计。
3.1.1.2 门控 MLP(Gated MLP)
【门控 (Gating)】相当于一个“开关”机制用来控制信息的流动。
普通的 MLP 架构图如图中所示,相比门控 MLP 少了门控结构,而门控结构的位置与原理也已经在图中标示出来了。
3.1.1.2.1 什么是感知机(Perceptron)?
“感知机”这个词,源自 1958 年心理学家兼计算机科学家 Frank Rosenblatt 提出的模型,他当时试图模拟人脑中的“感知过程”,即:人类看到或听到某些刺激,经过大脑处理,作出判断或反应的过程。简而言之,感知机是人类感知机制的一个数学抽象,模拟了“多通道感知 → 综合判断 → 行动”的过程。
而感知机(Perceptron)的结构也只有输入层和输出层,不能表示非线性函数。
3.1.1.2.2 什么是 MLP?
MLP 是一种前馈型神经网络(Feedforward Neural Network),由多个神经元(或节点)按层连接组成,至少包含一层“隐藏层”,并使用非线性激活函数来建模复杂的输入-输出关系。它是深度学习中最基础的一种神经网络结构,通过引入隐藏层和非线性激活函数,它能逼近任意复杂函数,是现代神经网络的“起点”。
MLP 至少有三层,每一层的本质都是若干“神经元”(其实是数学函数)按矩阵方式连接。
输入层 → 隐藏层(1个或多个)→ 输出层
==> 隐藏层 = 线性变换 + 激活函数(使具备非线性表达能力)
MLP 的本质是函数逼近器,可以将 MLP 理解为一个复杂的数学函数:y=f(x;θ)。其中 x 是输入,y 是输出,θ 是参数(即权重和偏置),这个函数可以逼近任何连续函数(这叫做通用逼近定理)。
通用逼近定理(Universal Approximation Theorem):只要你有足够数量的隐藏层神经元,MLP 就能逼近任意的连续函数。
→ 网络越大、训练越好,MLP 就能“画出”任意复杂的曲线。
MLP 是如何逼近非线性函数的?这个过程有些类似微分思想。
神经元数量越多,就可以在更多点插值;→ “段数”
激活函数的选择影响拟合能力,因为不同的函数有不同的形状;→ “线段”形状
多层 MLP 更进一步,可以组合组合,再组合,学更高维的复杂结构。→ 拼接
→ 就像以前学习微分时,一个圆可以用无数小线段来拼接近似,只不过这里的小线段不再局限于线段,也可以是目前能够用函数表示的曲线。
3.1.1.2.3 感知机、MLP 与神经网络的关系
| 网络类型 | 特点 |
|---|---|
| 感知机(Perceptron) | 只有输入层和输出层,不能表示非线性函数 |
| MLP(多层感知机) | 增加隐藏层,引入非线性激活函数,能学习复杂映射 |
| CNN、RNN、Transformer | 都是在 MLP 基础上演化出来的结构 |
3.1.1.3 Mamba
![]()
这一表示的意思是: Mamba 是 H3 和门控 MLP 两者的结构融合。其中,H3 给了 Mamba 时序建模能力(SSM),门控 MLP 给了 Mamba 内容选择能力(门控×激活),但是 Mamba 的门控是经过优化升级的智能门控,能力更强。
这里对 Mamba 的门控部分进行进一步的理解:
(1)输入信息经过投影层之后,进入了两个分支流程,一支(A支)经过激活函数增强非线性表达之后作为信息流,即信息流是 SiLU(Linear(x));
(2)而另一支(B支)首先通过卷积捕获局部上下文,提取局部时序特征,以弥补 SSM 长程建模对局部敏感的不足;
(3)然后,B 支再经过 SiLU 函数激活后,进入选择性 SSM 生成最终的具备内容感知能力的智能门控信号,也就是 gate = SSM(Conv(SiLU(Linear(x)))),这个智能门控信号类似于 Transformer 的注意力权重;
(4)最后,用 B 支生成的智能门控信号对 A 支的信息流进行调控与筛选。
将类注意力和 MLP 块融合成一个单一的、同质的块,每个 Mamba 块包含以下内容:
(1)对输入进行扩展投影(扩大维度);
(2)应用 1D 卷积(捕获局部模式);
(3)应用 SiLU / Swish 激活;
(4)应用选择性 SSM 层 (S6) —— 这是核心!
(5)应用残差连接和层归一化 (LayerNorm)。
每个块里没有注意力机制 (Attention),也没有独立的 MLP 层。多个相同的 Mamba 块堆叠起来,构成整个模型。
3.1.2 三种模块类型
3.1.2.1 线性投影 (Linear Projection)
操作仅在特征维度 (D) 上进行,不涉及时序/空间维度 (L)。本质是矩阵乘法 (y = xW + b)。
【核心功能】(特征重组 / 维度管理)
1. 改变特征维度: 扩展(D→E*D) 增加表达能力,压缩(E*D→D) 匹配后续输入。
2. 特征空间变换: 学习如何组合、加权输入特征。
【可学习参数】权重 W,偏置 b
【对照原图说明】绿色的矩形和梯形都属于线性投影,只是维度变化方向不同,用形状来区分。
3.1.2.2 序列变换 (Sequence Transformation)
操作主要在序列/时间维度 (L) 上进行,捕获元素间的依赖关系 (局部或全局)。
【核心功能】(上下文建模)
1. 建模依赖关系: 理解序列中元素如何相互影响。
2. 信息传播/聚合: 沿序列方向传递、整合信息。
【可学习参数】卷积核 / SSM 参数
3.1.2.3 非线性操作 (Nonlinearity)
引入非线性变换,不改变数据维度,逐元素操作。
3.1.2.3.1 乘法操作 / 门控 ⊗
两个或多个输入信号进行逐元素相乘。
【核心功能】
1. 条件化信息流:使用一个门控信号 g (通常由输入计算得来,值域如 [0,1]) 与主特征信号 x 逐元素相乘,实现动态的、输入相关的特征选择与调制。
2. 特征交互与调制:乘法不仅是开关,它允许两个不同的信息源 (x 和 g) 进行交互。
【可学习参数】无
3.1.2.3.2 激活函数 ○+σ
对单个输入信号应用一个逐元素的非线性函数。
【核心功能】
1. 引入非线性变换:使模型能拟合复杂函数,学习非线性的决策边界和复杂的特征组合。
2. 特征选择/门控(隐式):自身的数学形式就包含了一个自门控 (Self-Gating) 的乘法效应,可以看作是一种动态的、依赖于自身值的特征缩放。
【可学习参数】无
3.2 选择性SSM概述图
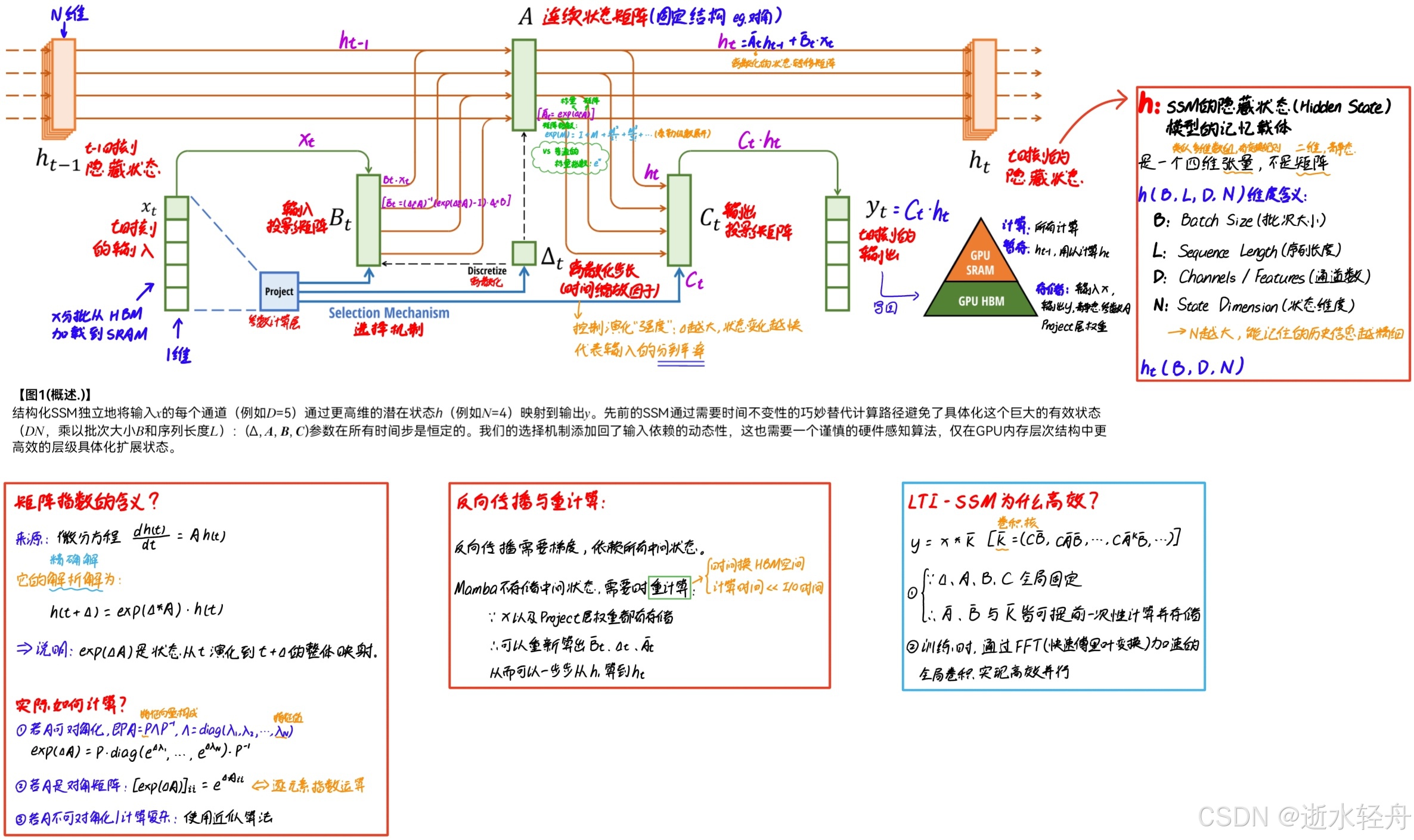
3.2.1 选择性SSM vs 普通SSM:区别表
| 特性 | 选择性SSM (S6, Mamba) | 普通SSM (LTI, eg. S4) |
|---|---|---|
参数 (Δ, B, C) |
依赖输入 → 选择性 | 固定 (常量) |
|
离散参数 (barA, |
动态 (需在每个时间步 t 实时计算) |
常量 (可预先计算) |
| 主要计算模式 | 训练 & 推理:循环 (强制) | 训练:卷积 (高效并行) 推理:循环 |
状态 h 的依赖 |
当前 h_t 仅依赖 h_{t-1} (理论) |
当前 h_t 仅依赖 h_{t-1} (理论) |
中间状态 h 的存储需求 |
理论: 只需存 h_{t-1} (常数内存)Mamba实现: 绝不存整个 h,SRAM暂留 h_{t-1} |
理论: 只需存 h_{t-1} (常数内存)实际传统实现: 有些存整个 h (B, L, D, N) |
| 硬件瓶颈 | 循环计算需处理 h,引发内存墙 (若存HBM) |
卷积模式下无 h 存储问题 |
| Mamba的硬件感知突破 | 算法:仅在SRAM计算 h,不写回HBM重计算:反向传播时在SRAM重算 h |
不需要 (卷积高效) |
| 任务支持 | 内容感知推理 | 仅时序建模 |
3.2.2 选择性SSM vs 普通SSM:算法对比表

3.2.3 选择性 SSM 的两个主要升级点
(1)核心区别在于参数动态性,也就是让 SSM 的关键参数 Δ (步长)、B (输入投影)、C (输出投影) 不再是固定的,而是当前输入 x_t 的函数。选择机制 → 无法使用卷积
关键选择参数的作用:
①Δ 控制信息传播/遗忘: 在关注或忽略当前输入的多少之间进行平衡,大的 Δ 相当于“重置状态,关注新输入”,小的 Δ 相当于“保持状态,忽略当前输入”。
② B 控制输入影响状态的程度: 根据输入内容决定让多少信息流入隐藏状态 h_{t}(上下文)。
③ C 控制状态影响输出的程度: 根据状态内容决定让多少信息从 h_{t} 流出到输出 y_{t}。
(2)革命性在于硬件感知算法:(核心思想:空间换时间、计算换 I/O)
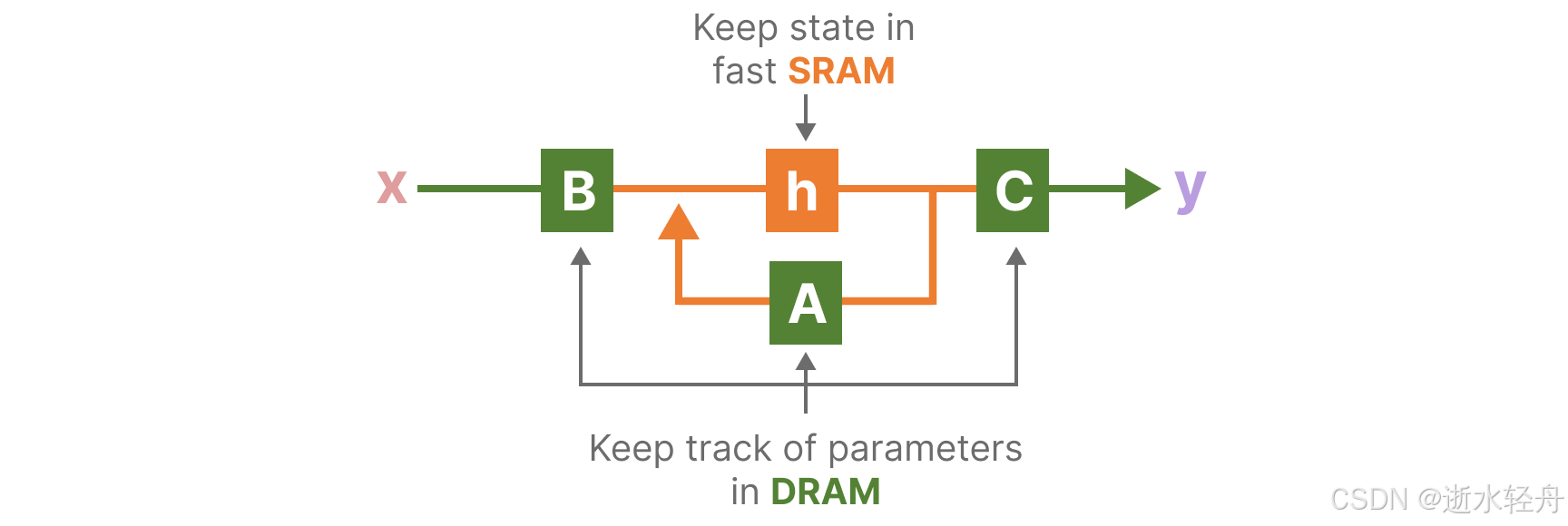
A. 核融合 (Kernel Fusion):将 Project → Discretize → Scan → Output 四个计算步骤合并为 单个 CUDA 内核,也就是所有中间结果(如离散化后的 bar A, bar B 及扫描状态 h_{t} )仅在 SRAM 中计算,不写回 HBM,从而将原本需多次启动的独立 CUDA 内核合并为一次内核启动。→ 减少内存读写次数,提升 IPC(Instructions Per Cycle,每个时钟周期内GPU核心执行的指令数)
注:① CUDA 内核是 GPU 上可并行执行的最小任务单元(类似 CPU 的线程)。
② 这里借助文章《A Visual Guide to Mamba and State Space Models》(这是朋友给推的一个可视化讲解 Mamba 模型的文章,讲得确实挺好的)中的一张图,从这张图中可以很直接地看出,核融合就是将计算都集中在中间,而涉及 I/O 的操作都集中在两端,尽量不在中间的过程涉及 I/O 操作,从而实现用计算时间换 I/O 时间。
B. 并行扫描 (Parallel Scan):利用GPU千级线程并行,加速计算。原本的隐藏状态递推式可以重写成如下公式:
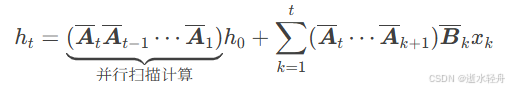
【关键】矩阵乘满足结合律,允许并行扫描加速。
【并行对象】所有时间步 t=1~L 的状态 h_{t} 被同时计算。
【并行化实现示例】(以 t=8 为例,其中 ⊕ 是满足结合律的操作)
Step 1(并行): 计算所有相邻对
[ A1⊕A2, A3⊕A4, A5⊕A6, A7⊕A8 ]
Step 2(并行): 计算跨度2的聚合
[ A1⊕A2⊕A3⊕A4, A5⊕A6⊕A7⊕A8 ]
Step 3(并行): 计算跨度4的聚合
[ A1⊕...⊕A4⊕A5⊕...⊕A8 ]
Step 4(并行): 补全中间结果(反向传播)
( e.g. 计算 A1⊕A2⊕A3 = (A1⊕A2) ⊕ A3 )
C. 重计算 (Recomputation):反向传播时在 SRAM 内按需重算 h_{t}。→ 用计算换 HBM 存储,彻底规避 HBM 存储与 IO 瓶颈
3.3 选择性复制与归纳头
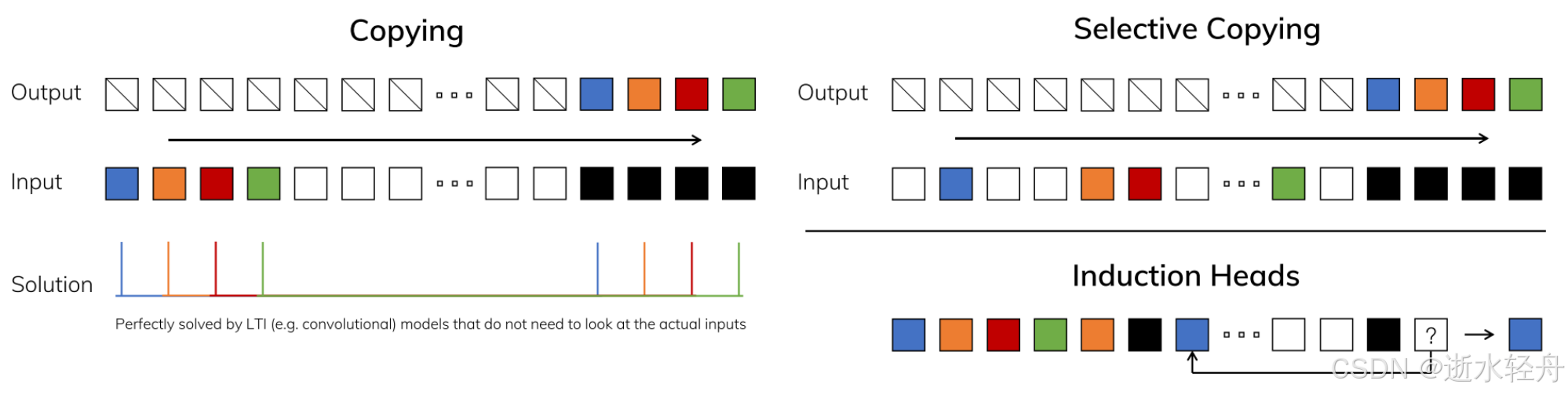
这张图光看标题就知道选择性复制以及归纳头任务是什么,那么这两个任务的实现与选择性 SSM 有什么关系呢?具体关联大致如下:
3.3.1 选择性复制任务 → 动态 Δ 的过滤作用
-
任务要求:仅记忆彩色 token,忽略白色噪声 token。
-
实现方式:
-
当输入为噪声时:
Δt→0 → 离散化后 bar A_{t} ≈ I(单位矩阵)
状态更新:h_{t} ≈ h_{t−1} + 微小扰动 → 忽略当前输入 -
当输入为关键token时:
Δt 增大 → bar A_{t} 变小,bar B_{t} 增大
状态更新:h_{t} ≈ 新状态 → 写入当前值
-
3.3.2 归纳头任务 → 动态 B/C 的关联检索
-
任务要求:当出现 "Harry" 时,输出历史中紧随其后的 "Potter"。
-
实现方式:
-
记忆阶段(首次出现 "Harry Potter" ):
B_{t} 在 "Potter" 处增大 → 将 "Potter" 值强写入状态 h_{t} -
检索阶段(再次出现 "Harry" ):
C_{t} 在 "Harry" 处增大 → 输出 y_{t} = C_{t}·h_{t} ≈ 存储的 "Potter"
-
-
关键创新:B/C 的选择性使模型在序列维度实现类似 KV 缓存的检索,而无需显式存储历史。
4. 行文思路
4.1 问题驱动
开篇直指 Transformer 在长序列上的瓶颈(计算效率低下)和现有线性模型的不足(无法进行内容感知推理),清晰地定义了要解决的核心问题。
4.2 层层递进
- 先介绍背景知识(SSM 是什么,LTI 是什么,计算模式:循环 vs 卷积等)。
- 然后指出 LTI 是现有 SSM 高效的原因,但也是其弱点(没有选择性)。
- 提出“选择性”机制作为解决方案。
- 紧接着指出选择性带来的新问题(无法卷积,循环计算慢 / 耗内存)。
- 再提出硬件感知算法来解决效率问题。
- 最后介绍简化架构封装这一切。
4.3 直觉引导
大量使用合成任务如“选择性复制”和“归纳头”来直观地说明问题(LTI 失败)和展示解决方案(选择性 SSM 成功)。这让读者先理解“为什么需要这个技术”,再去看数学细节。
4.4 技术细节深入
在建立了直觉后,论文深入数学公式(公式 1-5)、算法伪代码(Algorithm 1 & 2)和硬件优化细节(图1,3.3节,附录 D)。这种叙述方式适合想真正理解底层原理的读者。
4.5 实验全面论证
论文实验的高密度论证(5 大任务 + 16 组对比 + 3 种模态)为 “SSM 替代 Attention” 提供了非常完整的证据链。下面是论文所做实验的总结表:
| 任务类型 | 实验设计 | 核心结果 | 论证目标 |
|---|---|---|---|
| 合成任务 (验证选择机制) |
• 选择性复制:L=4096,16 token 词汇表 • 归纳头:训练 L=256,测试外推至 L=1M |
• 选择性复制:Mamba 99.8% vs H3 57.0%(表1) • 归纳头:Mamba 100% 外推至1M,其它模型崩溃(表 2 / 11) |
证明选择性 SSM 是解决内容感知推理的关键,LTI 模型存在根本缺陷 |
| 语言建模 (核心能力) |
• 规模:125M~2.8B 参数 • 数据:300B tokens (The Pile) • 基线:Transformer++ / RWKV / RetNet |
• Mamba-3B > Transformer-6B(零样本推理) • 相同参数量下平均准确率 +4~8点(表3) • 上下文增长时性能持续提升(图4) |
首个线性模型匹敌 Transformer 质量,且效率更高 |
| DNA建模 (超长序列) |
• 数据:人类基因组(4.5B tokens) • 序列长度:1K~1M bp • 任务:预训练 + 物种分类 |
• 1M 长度预训练:Mamba PPL ↓15% vs HyenaDNA(图5右) • 物种分类(1M长度):Mamba 81.31% vs HyenaDNA 54.87%(表13) |
证明百万级序列建模能力,且性能随长度单调提升 |
| 音频建模 (连续信号) |
• 任务:Waveform 预训练(YouTubeMix) • 生成:SC09 语音合成 • 长度:8K~1M 采样点 |
• 语音生成 FID:Mamba 0.67 vs SaShiMi 1.99(表4) • 长音频建模:Mamba BPB ↓0.02 且随长度持续改进(图7) |
验证在连续模态的通用性,超越扩散模型 / GAN |
| 效率验证 (硬件优势) |
• 扫描操作:序列长度 2^9~2^19 • 端到端:推理吞吐量测试 • 硬件:A100 GPU |
• 扫描速度:40 倍于朴素实现(图8左) • 推理吞吐量:5 倍于同规模 Transformer(图8右) • 内存:等同 FlashAttention 优化版(表15) |
证实硬件感知算法的实战优势 |
4.6 消融研究严谨
第 4.6 节和附录进行了大量消融实验,验证每个组件(架构选择、哪些参数需要选择性、状态维度大小、初始化方式、实数 / 复数)的重要性(表 6, 7, 8, 9, 10),证明了设计选择的有效性。
4.7 坦诚讨论局限
在讨论部分和附录(E.4.1)坦诚指出选择性 SSM 在连续均匀信号(如原始音频波形)上可能不如 LTI SSM(图 10),体现了科学研究的严谨性和实事求是的真诚态度。
4.8 图表示意清晰
关键图表(图 1 硬件扫描、图 2 合成任务、图 3 架构、图 4 / 5 / 6 / 7 缩放与性能、图 8 效率)设计精良,直观传达了核心信息。
4.9 附件补充细节
真正的论文内容只有 23 页,剩下的 13 页都是补充信息的附录,包含附录 A(对选择机制的讨论)、B(相关工作)、C(选择性 SSM 机制)、D(选择性 SSM 的硬件感知算法)和 E(实验细节和附加结果)。
5. 总结
5.1 Mamba是什么?
是一个基于选择性状态空间模型 (S6) 构建的、简化的、无注意力机制的序列模型架构。
5.2 核心目标
解决 Transformer 在处理超长序列时的效率问题( O(L²) 的计算和内存开销),同时保持甚至超越其在语言等复杂模态上的强大性能。之前的线性复杂度模型(如线性注意力、门控卷积、早期 SSM)在长序列上效率高,但在语言任务上效果不如 Transformer。
5.3 关键洞察
(1)Transformer 的优势在于“内容感知推理”: 它能根据当前词(Token)动态决定关注序列中的哪些部分(注意力机制)。
(2)早期 SSM 的弱点在于“线性时不变”: 它们的内部状态转移规则(A, B, C 参数)是固定的,与输入内容无关。这导致它们无法像 Transformer 那样根据内容选择性地记住或忘记信息,尤其在处理像文本、DNA 这种信息密集、依赖上下文的离散数据时表现不佳。
5.4 Mamba 核心创新
(1)选择性 (Selectivity): Δ, B, C 参数动态依赖于输入,实现内容感知推理(记住/忘记/传播)。
(2)硬件感知算法: 高效的并行扫描 + 内核融合 + 重计算,解决了选择性带来的计算效率问题,实现真正的 O(L) 训练和推理。
(3)简化架构: 融合了类注意力和 MLP 功能,架构极简、同质,移除了注意力机制和独立的 MLP 块。参数效率高(大部分在投影层),易于实现和扩展。
5.5 效果
在语言、DNA、音频等多个模态上达到 SOTA 或极具竞争力水平,是首个在语言建模上全面匹敌 Transformer 的线性复杂度模型,且具有 5 倍于 Transformer 的推理速度和处理百万级上下文的能力。
5.6 论文叙述特点
问题驱动 → 直觉解释 → 技术深挖 → 全面实验验证 → 严谨消融 → 讨论局限。这种方式更侧重于解释“为什么”和“怎么做”,特别是底层原理和效率优化,适合深入理解模型本质。
5.7 研读感受
Mamba 不愧是最新火起的可以匹敌甚至超越 Transformer 的序列模型,有望成为新一代强大的、高效的 FM 主干。虽然这篇论文只是发表在预印本平台上,但通过研读,我感受到了真正做科研的态度,论文写作的思路清晰,一步步推进地发现问题并解决问题,实验验证也非常严谨,就连对最基本的概念都有典型和流行观点的对比以及本文术语的选择和概念的详细说明,比如对“门控”与“选择”两个词的推敲,说明了“门控”一词在历史上的不同含义,也解释了为什么使用“选择”而不是“门控”一词。
Mamba 本身的出现就已经工程科学上的突破,Mamba 的有效性不仅仅被它的创造者进行了验证,目前出现的大量关于 Mamba 的相关研究与拓展应用也侧面说明了其有效性与突破性。
而除去 Mamba 本身的科学价值,讲述 Mamba 的这篇论文也有很多亮点,它不仅仅展示了一篇好的论文应该如何撰写,更展示了科研的求索精神与严谨态度。本篇博文对 Mamba 的学习虽然已经结束,但这篇论文值得我以后反复地阅读与学习。
学习方法与工具探索
1. AI 小课堂——秘塔 AI 搜索
还没太深功底的我一般来说直接阅读论文原文是有一定难度的,所以我会先用 AI 以讲课的方式带领我对论文进行通俗地理解和通篇的了解。之前是用 AI 总结,但现在这个 AI 讲课的感受会更好一些,因为有 PPT、声音,也能倍速,还有动图讲解、互动以及课后练习。
前段时间新发现了一款 AI 工具,这款 AI 主要是搜索能力比较强,不仅能检索大量信息,而且能检索到比较新的信息,也会给出原链接,甚至能给出可以获取到的 PDF 文件的原文件,可以预览原文件,也可以下载,还能对 PDF 文件进行阅读、翻译与讲解等操作。
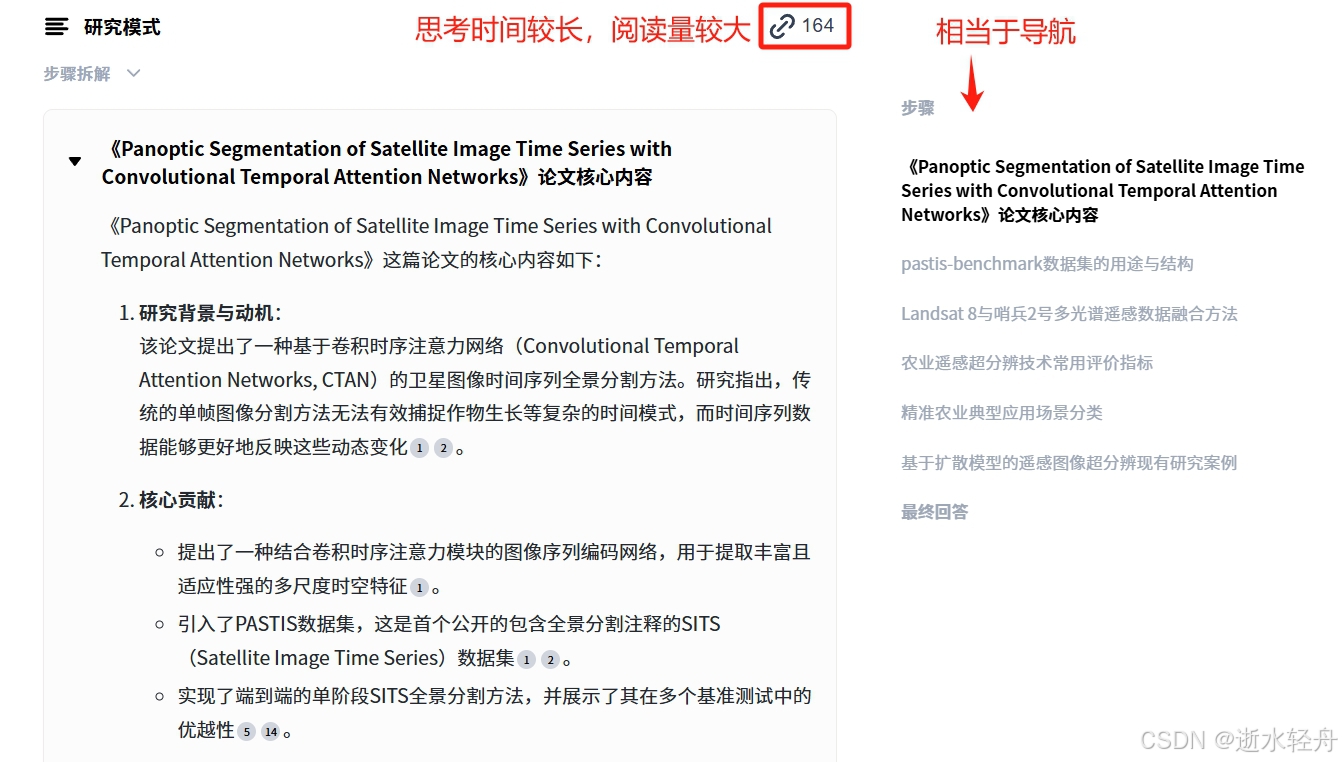

1.1 AI 讲课
除了信息搜索能力,我觉得 AI 讲课是秘塔最强大的功能,至少是我目前还没在其它 AI 上发现的功能。秘塔 AI 不仅可以讲解文档形式的信息,也可以对一些链接中的信息进行讲解。
首先,可以选择自己的角色、讲解风格以及 AI 的声音,这里只展示了知识掌握程度和讲解风格,往下滑就会发现其它设置。

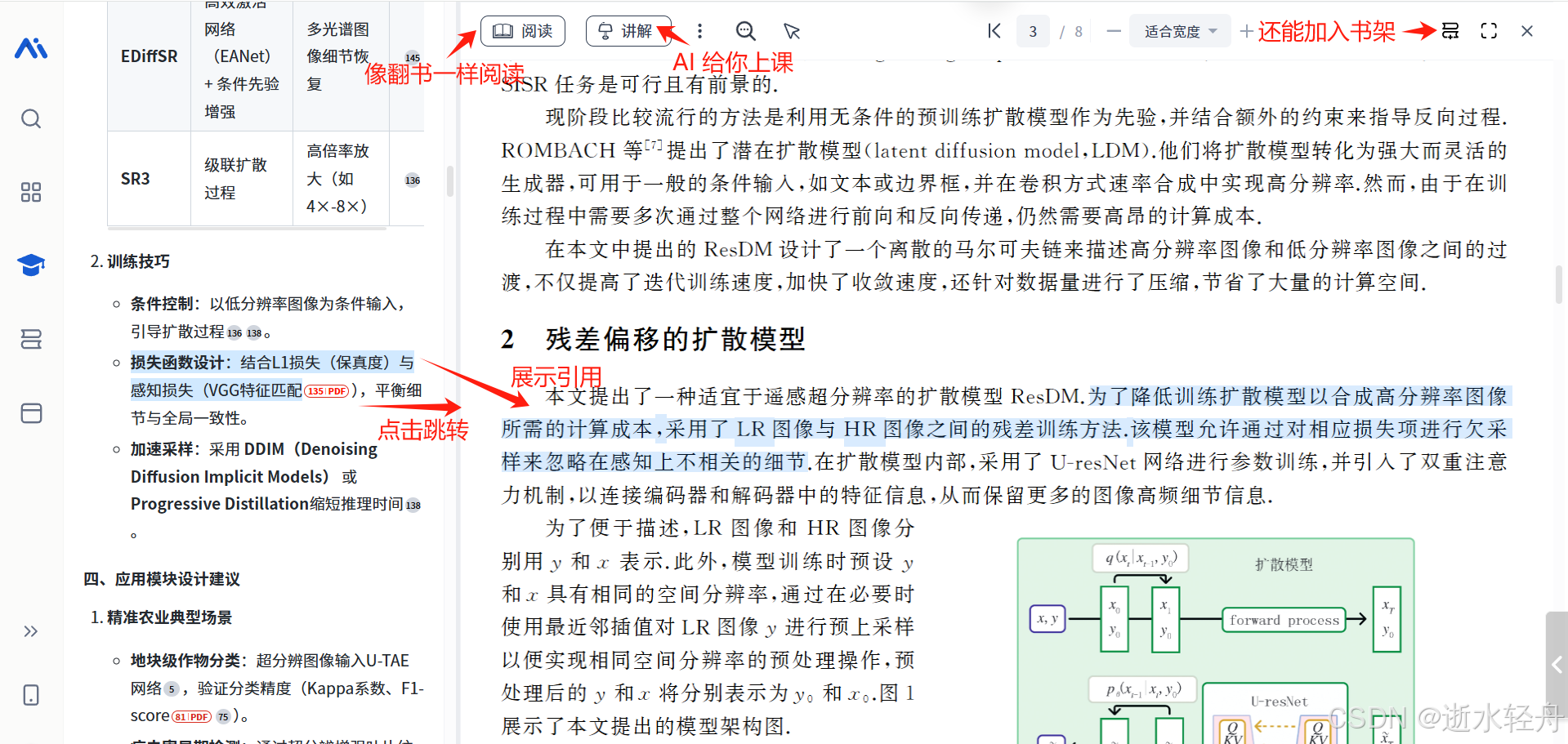
然后就是 AI 开始备课了,备完课就进入了上课模式,上课是有 PPT 的,一边有 AI 声音讲解,一边还配有字幕。此外,我们也可以控制讲课的进度,可以暂停、前进、倒退和倍速,也可以通过翻动 PPT 来控制 AI 从哪里开始讲解。有时候,还会在 PPT 至上再弹出小框展示一些动态过程。

讲课的过程中,我们也可以选择“讲解对照原文”的模式,从而边看原文件,边听课。
在 AI 讲解过程中, 我们还可以进行鼓掌以及向老师提问等互动,AI 还会感谢你的鼓掌,这就有点儿娱乐化了,哈哈哈。
 最后就是课后练习了,听完课,我们还可以让 AI 考考我们,它会给我们一些题目,通过做题来看我们的学习掌握程度。
最后就是课后练习了,听完课,我们还可以让 AI 考考我们,它会给我们一些题目,通过做题来看我们的学习掌握程度。

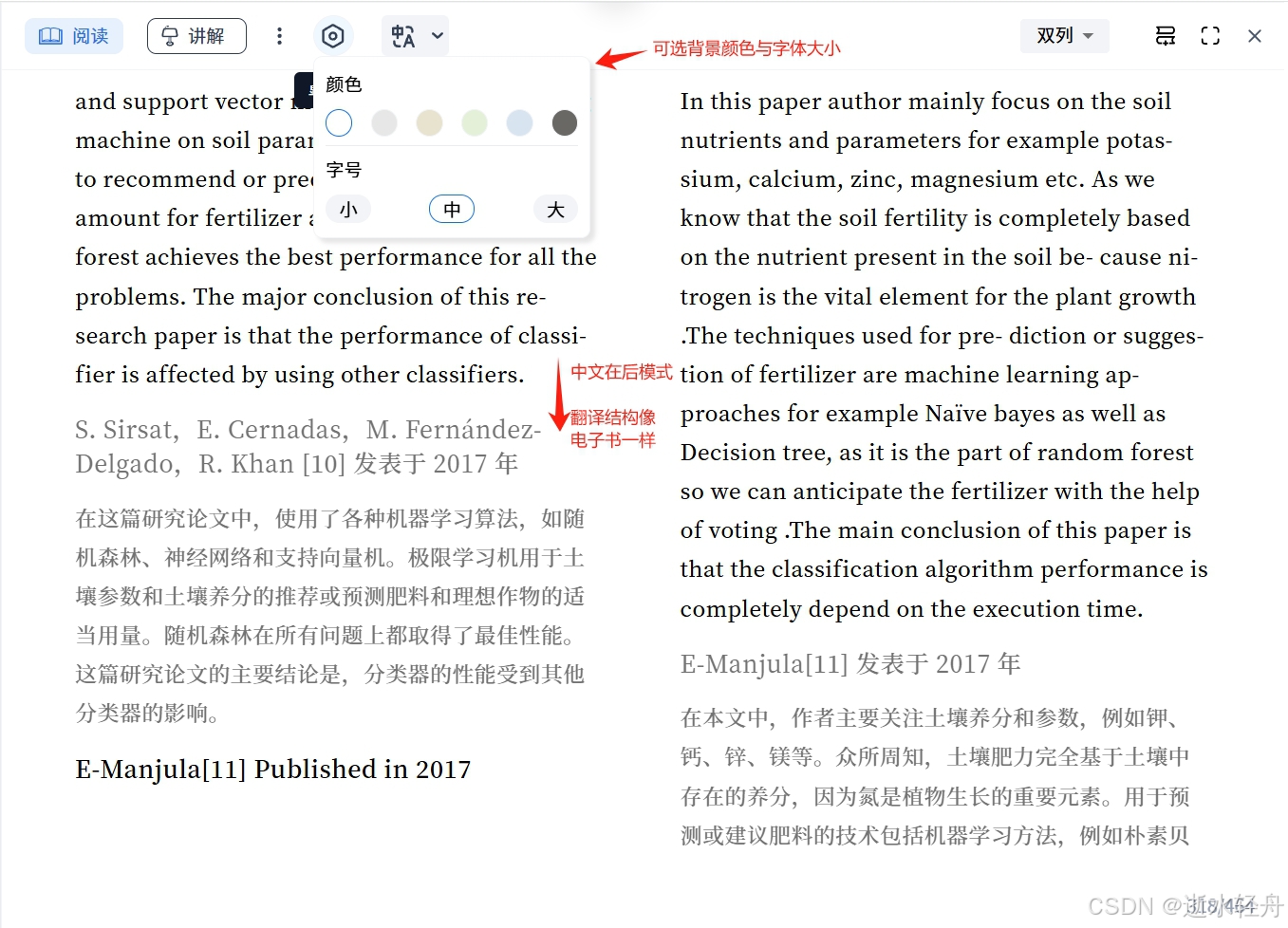
1.2 阅读 & 翻译
可以像电子书一样地阅读,可以进行全文翻译,也可以划词翻译和解释,全文翻译之后也是像电子书一样的阅读模式,但缺点是无法下载翻译版的文件。

1.3 知识库
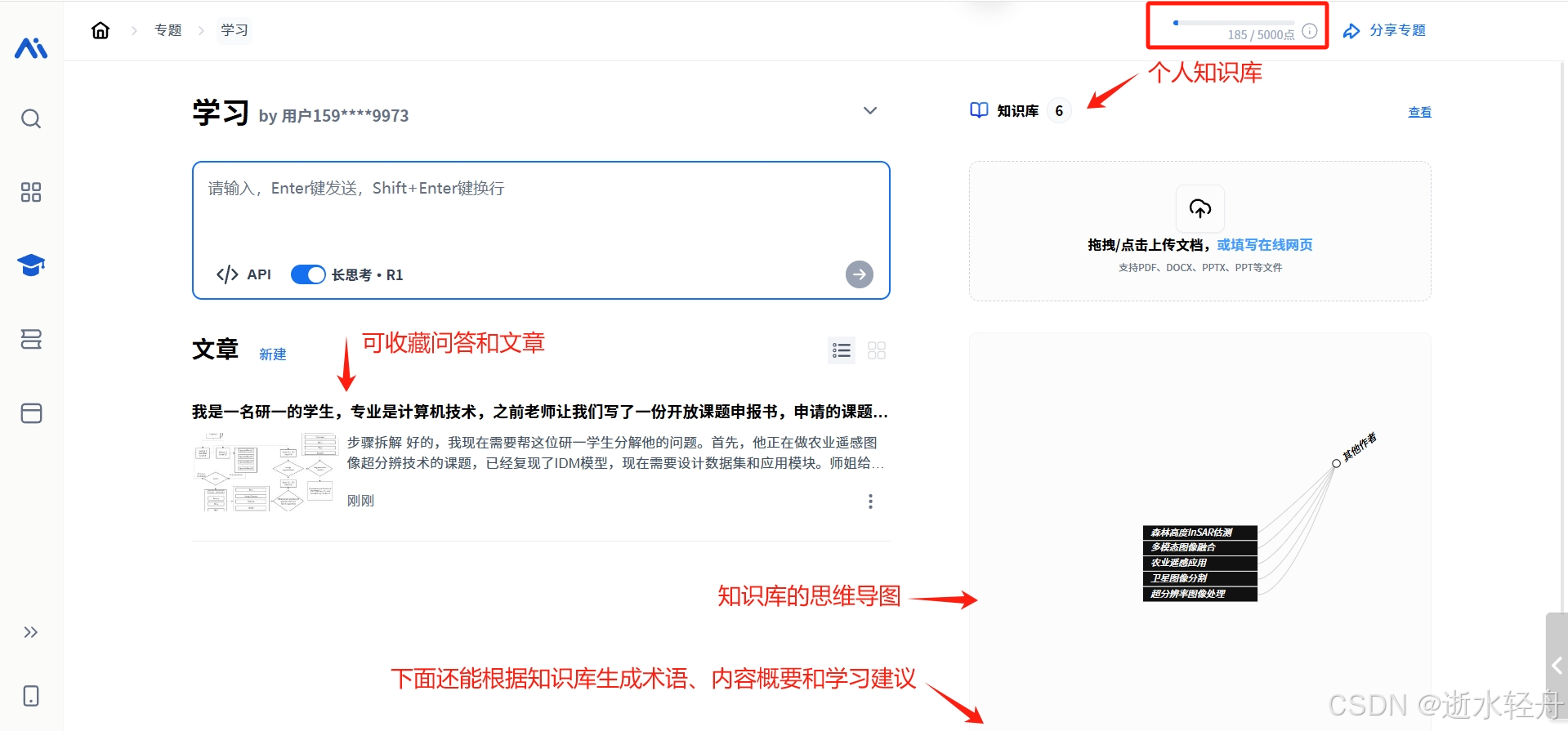
秘塔的第三大功能就是建立知识库了,它的知识库可以上传文件,也可以对历史问答中的问答与文章进行收藏,然后我们可以基于这个知识库进行提问。上传的文件,知识库会帮你生成思维导图,下面很可以要求生成术语、概要与学习建议等。但缺点就是上传文件会消耗“点”数,所以并不能无限扩充知识库。
1.4 划词解释
秘塔另外一个小功能就是划词解释,在搜索或者阅读过程中,我们都可以划出我们不理解的部分,然后点击“解释”,它会有弹窗给出 AI 解释的内容,但它并不是一次性的,我们可以从所划内容旁边找到历史解释,也能从最近的聊天对话中找到解释过的内容。


2. “快速”通读
这里的重点是是快速。
因为我自己阅读文字信息有一个逐字阅读的习惯,这个习惯也许可以看得很细,但是对于阅读像论文这些比较有深度或者比较枯燥的内容来说,自己的注意力就很容易丢失,读着读着就不知道脑子跑哪去了,很容易拖时间,还容易啥记不住。
所以快速阅读其实就是强迫自己集中注意力的一种方式。但是,我也要知道,我快速通读论文的目的是什么,我的目的是对论文的整体讲述和架构有一个了解,所以我可以快速通读,而不需要过分纠结一个点地去扣细节。
3. 做笔记——ima.copilot
边读边做笔记也为了防止出现自己读完啥也没记住的现象,也是有利于集中注意力的一种方式。记笔记也会迫使自己去思考这一段、一小节的重点内容是什么,学会总结和概括,也是根据自己需要的角度去总结和概括。同时思考对自己有何启发,随时记录自己的灵感和思考。
而我最近所用的笔记软件是 ima.copilot,但这其实并不是一款专业的笔记软件,它是一款 AI 软件,可以进行提问和浏览网页,也可以建立知识库。
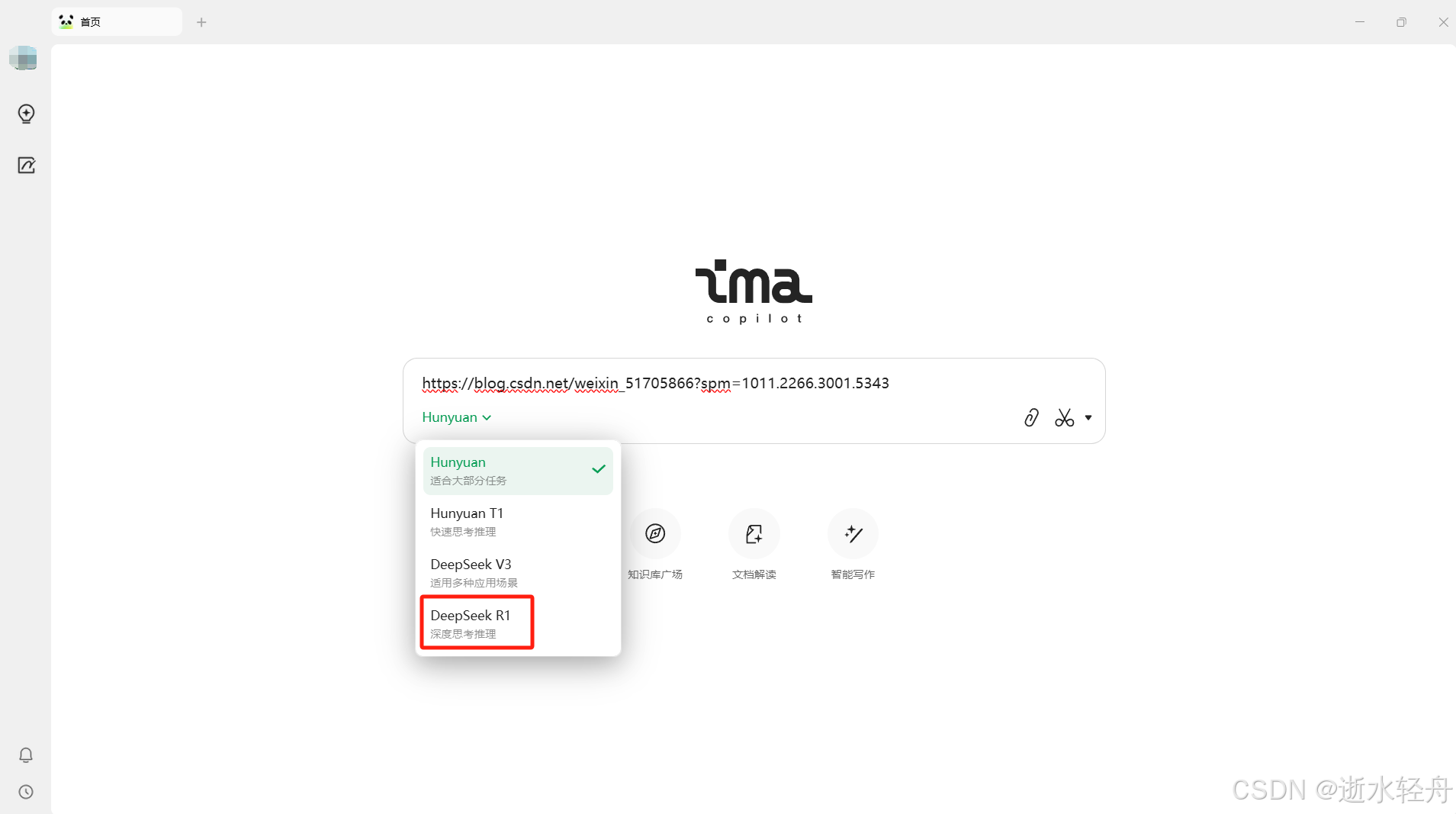
3.1 笔记
它的笔记编辑功能只有最基本的文本编辑工具,但对于平时的简单记录来说够用了,本身也不需要很复杂。
我觉得它的笔记功能最惊艳的点是可以加入知识库!
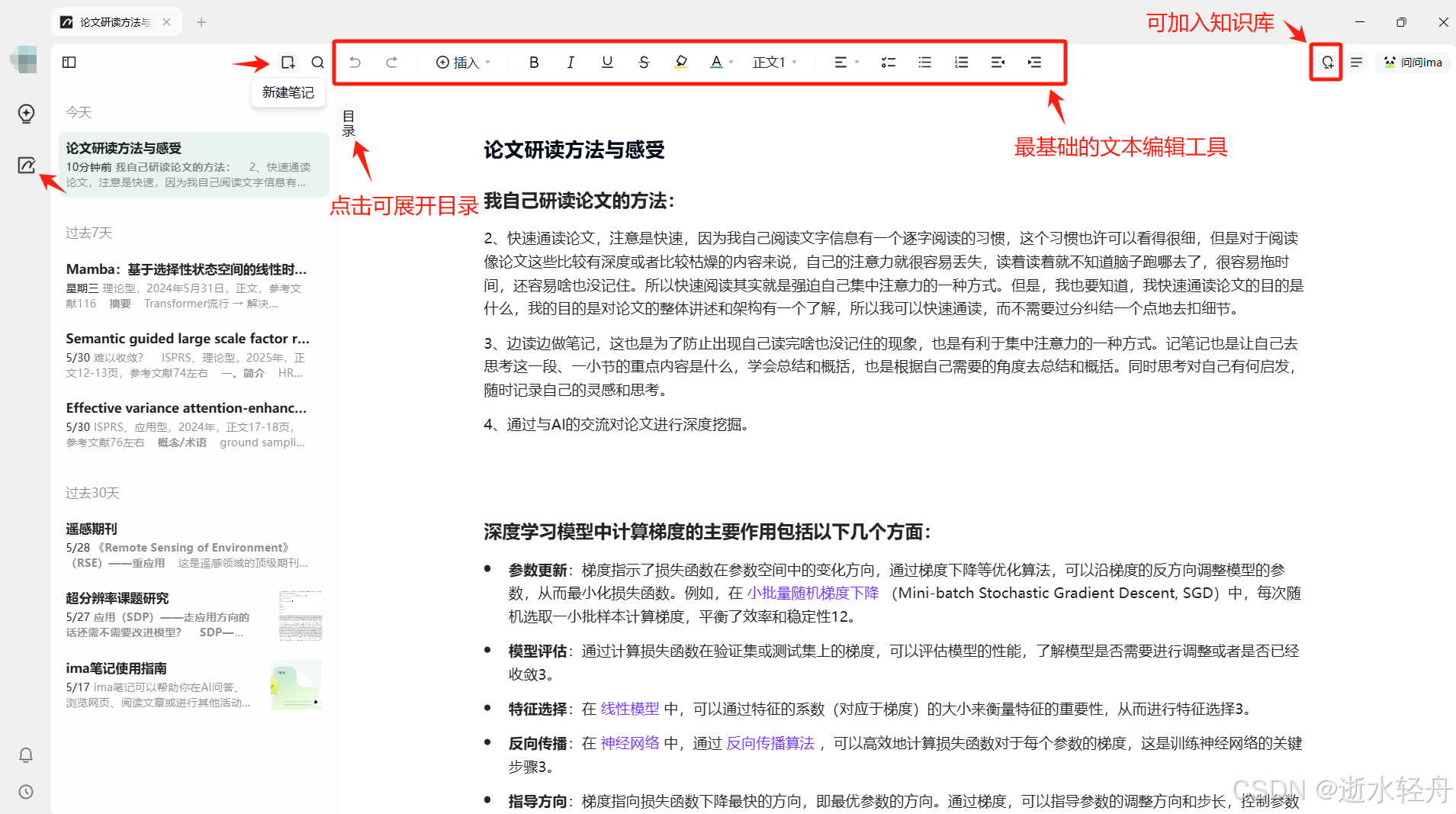
3.2 知识库
ima.copilot 的知识库可以上传本地文件,也可以将浏览的网页和所做的笔记加入知识库。也是有一定限制,和秘塔不一样的是,它是容量限制,容量也挺大的了,即使满了,我们也可以去掉不再需要的内容,从而腾出空间。
4. AI 精读——DeepSeek 为主,ChatGPT 为辅
最后还是老朋友——DeepSeek 与 ChatGPT。
上述的 AI 课堂、翻译与笔记等只是基础的学习方式,但是仅靠它们很难十分深入地学习,虽然秘塔也能提问和检索,但是它对人的语言理解能力一般,在解疑答惑方面还得是 DeepSeek 与 ChatGPT。
但不得不承认,DeepSeek 与 ChatGPT 也各有利弊。比如,DeepSeek 在一些公式的表达上,它总是写不出正常的数学公式,这时我会用 ChatGPT 帮忙翻译一下;或者当 DeepSeek 出现繁忙时,急的话,我也会向 ChatGPT 求助。而对于 ChatGPT,我觉得它的比喻或者说通俗表达能力以及对我困惑的理解程度不如 DeepSeek。
对于检索和归纳信息,秘塔可能更有优势,但是某些情况下还是需要最原始的手动检索方式。而刚刚,我才发现 ima.copilot 也配置的有 DeepSeek-R1,但这段时间只用它做笔记了,倒是没有试过这块儿好不好用,回头试试。
*** 科学箴言 ***
1、“科学的每一个成果都来自于认真思考和严谨验证。” ——爱因斯坦
2、“在科学上没有平坦的大道,只有不畏劳苦沿着陡峭山路攀登的人,才有希望达到光辉的顶点。” ——马克思

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 51
51 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)