模型训练-关于token【低概率token, 高熵token】
下图是作者的统计结果,可见基础模型中初始熵较高的 token 在 RL 后往往表现出更大的熵增,这与三中的实验结论不谋而合,表明 RL 带来推理性能提升的原因之一,很可能就是因为高熵 token 的不确定性更强了,提高了大模型推理的灵活性。这一关系清晰地表明,词元概率越低,其梯度贡献越大,反之则越小。可见在 RL 训练过程中,尽管与基础模型的重叠逐渐减少,但在收敛时(第 1360 步),基础模型的
Qwen团队新发现:大模型推理能力的提高仅由少数高熵 Token 贡献
不要让低概率token主导了LLM的强化学习过程
论文:BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping
一 低概率词元问题
论文:Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
在RL训练过程中,低概率词元(low-probability tokens)因其巨大的梯度幅值,在模型更新中产生了不成比例的主导效应。这种“梯度主导”现象会严重抑制对模型性能至关重要的高概率词元的有效学习,从而阻碍了模型能力的进一步提升。
本文首先从理论上溯源了这一现象,揭示了其内在机理:对于一个典型的LLM,任何词元在网络中间层产生的梯度范数,其大小与( 1-兀)成正比,其中兀是该词元的生成概率。这一关系清晰地表明,词元概率越低,其梯度贡献越大,反之则越小。
基于这一核心洞察,提出了两种旨在恢复梯度平衡、简单而高效的方法,以缓解低概率词元的过度主导:
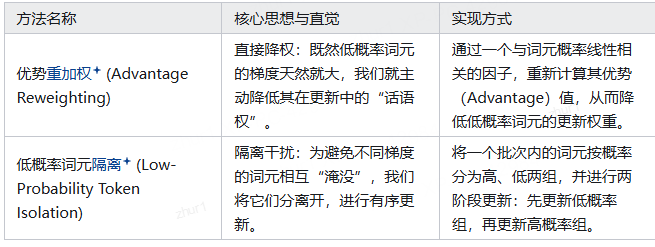
Token 特征与熵影响速查表
| Token 特征 | 类别 | 对熵的影响 | 解释 |
|---|---|---|---|
| 高概率,正优势 | 利用 | ↓ 熵减少 | 强化已知的好行为,使分布更尖锐。 |
| 低概率,负优势 | 强惩罚 | ↓ 熵减少 | 坚决抑制罕见的坏行为,使分布更尖锐。 |
| 低概率,正优势 | 探索 | ↑ 熵增加 | 鼓励新发现的好行为,使分布更平滑。 |
| 高概率,负优势 | 软化 | ↑ 熵增加 | 略微惩罚常见的“小错”,防止分布过度跃迁,保持一定探索性。 |
二 高熵token—策略熵坍缩
[1] [3] [4] [5] [6]本质上都聚焦到高熵的forking token熵。
[4] [5] [6]通过修正GRPO中对高熵(低概率)token的偏见,来缓解熵的快速下降。
[1]则通过限制低熵(高概率)的更新幅度来缓解熵的快速下降。
因此,这些方法理论上可以结合使用,增加高熵token更新幅度的同时,降低低熵token的更新幅度。
[7]不再聚焦到token-level的熵,而是认为应该增加负样本的相对权重。结合[1]的观点来看,由于模型rollout出来的负样本概率也不会太低,那么优化这个相对高概率的负样本,也会缓解熵减。
参考文献
[1]. The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
[2]. ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
[3]. Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
[4]. DAPO: An Open-Source LLM Reinforcement Learning System at Scale
[5]. MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
[6]. Reasoning with Exploration: An Entropy Perspective
[7]. The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning[
8]. No Free Lunch: Rethinking Internal Feedback for LLM Reasoning
2.1 熵的变化【1】
[1]. The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
相比于前面的方法,[1]从关注熵转变为关注熵的变化。
将熵看作是logits的函数,即 Ht(zt)。那么在足够小更新步长的情况下,熵的变化为 (11)
公式(11)的结论是:
熵的变化与对数概率和logits变化的协方差呈现负相关。
具体来说,当高概率token的logits增加或者低概率token的logits减少,则熵减;否则熵增。
更直观的讲,锐化当前模型的分布会导致熵减。
基于公式(12),[1]认为应该限制高协方差的token更新幅度,提出了Clip-Cov和KL-Cov。Clip-Cov主要是识别出的高协方差token梯度置零。KL-Cov则是在识别出的高协方差token施加一个kl约束,使其不太偏离原始策略太远。
2.3 定义高熵和低熵token, 【3】
[3]通过分析发现大多数token的熵非常低,仅有少量token的较高。而且,token的功能与熵高度相关:
高熵token主要承担"逻辑连接器"和"假设引入者",例如wait、however等。
低熵token则是"结构补全者"的角色,负责在已经确定好的推理步骤中填充细节。
因此,[3]将这些高熵token定义为forking token
token 熵” 并不是针对于某个特定 token,而是在特定位置 t,对解码不确定性的度量
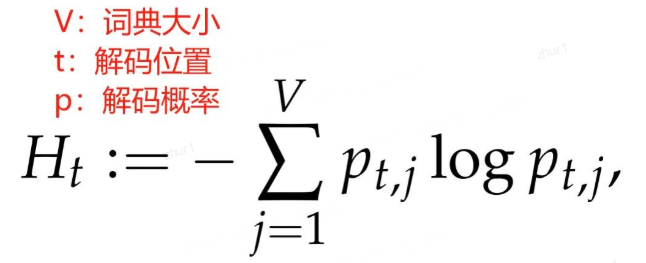
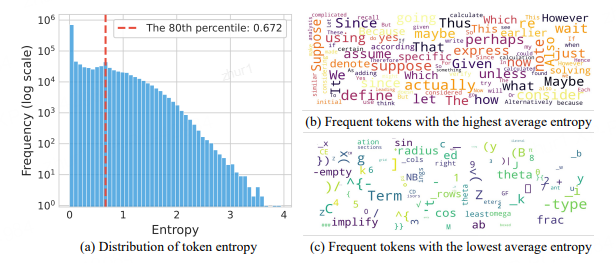
作者发现,生成推理链时每个位置的 token 熵值极度不均衡:只有少数 token 以高熵生成,而大多数 token 以低熵输出。具体地,80% 的token 熵低于0.67
熵最高的 token 通常用于连接两个连续推理部分之间的逻辑关系,比如wait、however 和 unless 等(对比或转折),thus 和 also(递进或补充),since 和 because (因果关系);在数学推导中,suppose、assume、given 和 define 等 token 频繁出现,用于引入假设、已知条件或定义
熵最低的 token 则倾向于完成当前句子部分或结束单词的构建,均表现出高度的确定性
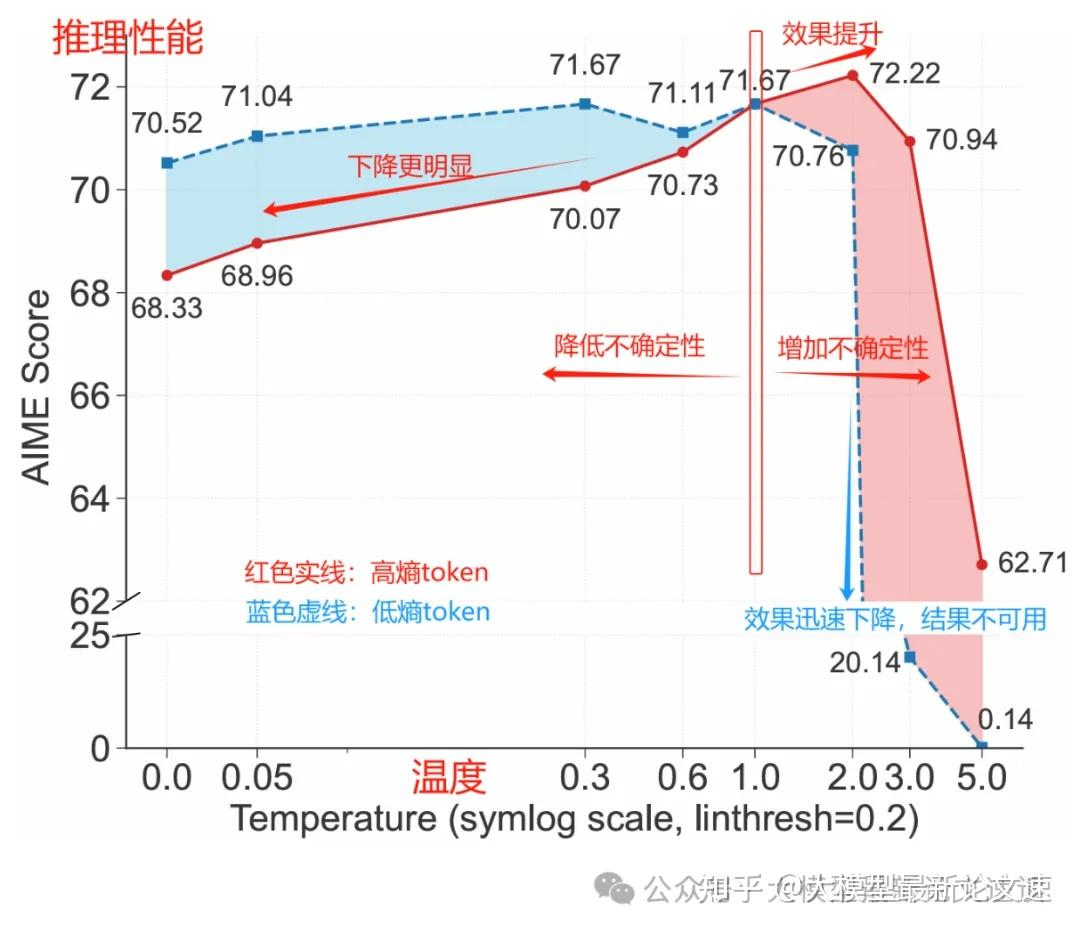
2.3.1 高熵 token 对推理性能的关键作用
为了验证高熵 token 对推理性能的关键作用,作者通过控制解码温度来调整这些 token 在生成过程中的随机性。
结果表明,适当提高高熵 token 的熵值可以提高推理正确率;反之,强行降低其熵值则会显著损害性能。这充分证明了在关键分叉 token 处保持较高的不确定性和探索度,对提高推理质量大有裨益。可见,少数高熵 token 确实是推理过程中应重点关注的“要害”
作者设计了这样的实验:利用 DAPO 算法训练 Qwen3-14B 模型,保存不同训练阶段下的 checkpoint,分别在各种数学推理基准上进行采样,识别各中间模型的高熵 token,然后分别计算这些它们与原始模型、训练完毕后的模型对应的高熵 token 重叠率,结果如下
可见在 RL 训练过程中,尽管与基础模型的重叠逐渐减少,但在收敛时(第 1360 步),基础模型的重叠率仍保持在 86% 以上,这表明 RL 训练在很大程度上保留了基础模型的高熵 token

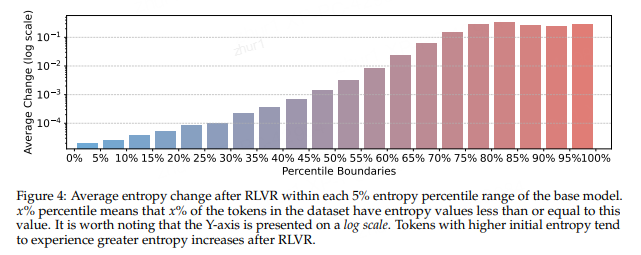
那么具体的熵值又是如何变化呢?下图是作者的统计结果,可见基础模型中初始熵较高的 token 在 RL 后往往表现出更大的熵增,这与三中的实验结论不谋而合,表明 RL 带来推理性能提升的原因之一,很可能就是因为高熵 token 的不确定性更强了,提高了大模型推理的灵活性
2.4 解耦token上下限, 【4】
[4] DAPO 认为clip操作对高概率token(低熵)和低概率token(高熵)是不平等的, 例如同样的r倍数,clip操作会限制低概率token(高熵)的更新幅度。因此,[4]提出将裁剪的上下限由 ε解耦为 εlow和 εhigh,适当提高 εhigh从而让高熵token获得更大幅度的更新。
2.5 将优势从裁剪中解耦。【5】
[5]. MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
[5] MiniMax-M1 在[4]的基础上进一步认为,应该将优势从裁剪中解耦出来。因为,若触发了裁剪就导致梯度为0。重要性采样应该看做是优势的一个权重。因此,目标函数进一步修改为
其中 sg()是 stop_gradient 操作。
2.6 直接增加forking token的优势【6】
[6]更加直接,既然高熵token更重要,那么直接提高其优势
[6]. Reasoning with Exploration: An Entropy Perspective
2.7 正负样本的影响【7】
[7]. The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning[
[7]分析了正、负样本对熵坍缩的影响,在实验中发现进仅使用负样本也能实现很好的效果。因此,在正负样本奖励分别为+1和-1的情况下,[7]进一步分析了REINOFRCE下loss关于logits的梯度。
当 r=1时。对于采样到的token yt,梯度会以幅度 (1−πyt)增加logit zt,yt。当模型对 yt不高时,会以更大的幅度更新。对于没采样到的token,梯度会以幅度 πv来降低logit zt,v。
从forking token的视角来看[3],若正样本中包含了forking token,则该token的熵会加速下降,也就是那些起连接作用的token快速被确定。
当 r=−1时。对于采样的token yt,梯度会以幅度 (1−πyt)降低logit zt,yt。同时,对于其他token会按照自身概率来重新分配释放的概率质量。
总的来说,正样本中采样的token会成比例剥夺其余token的概率质量,而负样本中采样的token会将被剥夺的概率质量成比例的分配给其余token。
因此,负样本天然有利于增大熵。
基于上面的分析,[7]提出降低训练中正样本信号的强度来维持熵。 思考:纯负样本训练能够取得好的效果,应该是由于不断强化基础模型的原始分布,相当于近期大量基于内部反馈的方法?[8]
三 高熵token训练
3.1 可验证奖励的强化学习
RLVR是指基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards),是一种通过使用明确的、基于规则的奖励函数来优化大型语言模型(LLMs)性能的方法。
在RLVR算法中,模型获得的反馈verifier reward较为准确,
RL优化方法可以选用PPO算法,
GRPO算法,
以及加入了动态采样,clip higher等策略的DAPO算法,
RLVR经常会遇到策略熵坍缩的问题,随着训练的进行,策略熵会越来越小,使模型探索能力不够。解决方案有加入entropy loss,clip higher,clip-cov等方法。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)