AI时代下,知识库的召回率提升技巧
随着知识库的不断扩展,大模型在查找和调用信息时可能面临准确性下降的问题。本文提出了五种优化文档结构的方法,以提升大模型处理信息的效率:建立层级式标题、分解复杂内容、控制内容容量、添加章节摘要和创建内容索引。这些方法无需改变知识内容本身,而是通过优化文档的呈现方式,帮助大模型更精准地定位和调用所需信息。此外,文章还建议建立统一的词汇对照表,以减少因词语歧义导致的理解偏差。通过这些调整,可以显著提高大
前言
在之前的文章中,我们探讨了如何有效整理私有知识。作为本系列文章的第四篇,本文重点解决一个常见问题:当知识库越来越庞大时,如何让大模型更精准地找到你需要的具体内容。
我们发现当文档内容越来越多时,大模型可能反而会更"笨"。即大模型可能找不到正确段落或给出错误答案。这通常不是因为知识本身有问题,而是文档的呈现方式需要优化。就像整理书架时,给书籍贴标签、分类摆放能让人更快找到目标书籍,对文档进行适当的结构化处理也能帮助大模型准确定位。
本文将分享五个简单调整技巧:给章节添加序号、拆分过长内容、控制段落字数、补充章节说明、建立内容索引。这些方法不需要修改知识内容本身,只需要像整理书架那样优化文档的"摆放方式"。通过实际案例演示这些调整如何让大模型更精准地调用知识库中的信息。
正文
随着需要管理的知识内容不断积累,文档长度会持续增加。这时可能出现两个典型现象:大模型有时找不到需要的内容,或者给出的信息与文档实际内容不符。这种情况往往发生在文档过长导致系统处理时,部分章节内容被自动截断或拆分。如下图所示: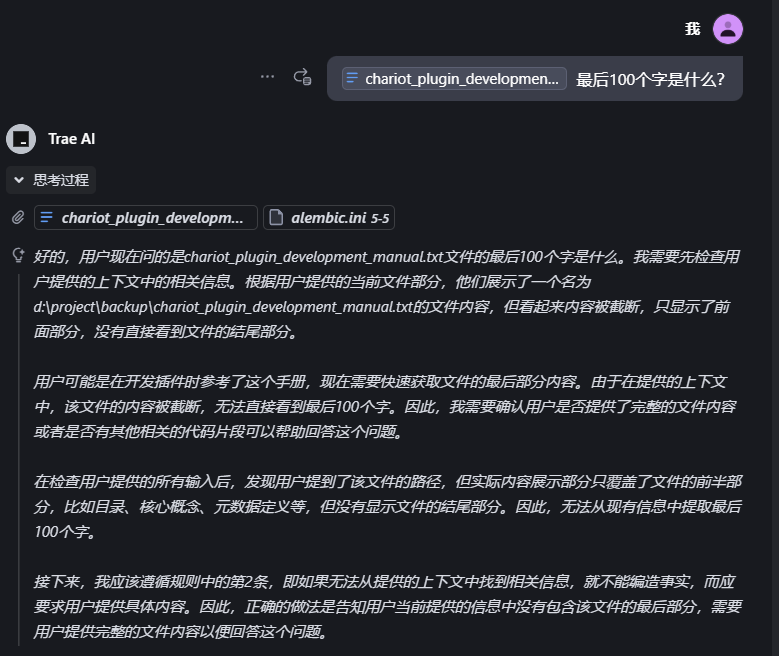
此外,目前常见的文档处理工具都存在段落长度限制。如图例所示,当某个章节内容超过限制被分割成多段后,原本完整的信息会被分散在不同位置。这种分割容易导致系统难以识别这些内容的完整性和关联性,就像书本被撕去目录页后难以快速找到对应章节。
如果一个章节的内容被强制分为两段就会像下图所示,段落的特征被模糊掉,相关部分的召回会受到影响。
可以通过以下方法改善系统查找文档内容的准确性:
- 建立层级式标题
使用"1.1"、"3.2"这类数字编号作为章节标题,类似书籍目录中的章节标识,帮助大模型快速理解内容结构。 - 分解复杂内容
遇到内容较多的章节时,拆分成更小的单元。例如将"用户权限管理"拆分为"权限设置"、“权限修改”、"权限回收"三个独立小节。 - 控制内容容量
每个小节的文字量建议不超过大模型或者文档工具的单次处理量,就像快递分箱时需要合理控制每个包裹的重量。 - 添加章节摘要
在每部分开头用1-2句话说明核心内容,例如:“本节列举文件上传的格式要求,包括图片尺寸、文档类型等具体参数。” - 创建内容索引
需要延伸说明时直接标注具体章节位置,如在讲解图片规范时注明:“尺寸调整方法详见第3章第2节”。
参考示例如下:
企业知识库管理规范(优化版)
第一章 总则
1.1 制定目的
(约200字说明,涵盖规范目标和企业知识管理重要性)
1.2 适用范围
(用列表形式明确适用对象,控制在分段长度内)
总部各部门
各区域分公司
合资子公司
第二章 知识库架构
2.1 核心架构(总字数控制在500字以内)
采用三级分类体系:
① 业务类文档
② 技术类文档
③ 管理类文档
注:具体分类标准详见第三章
2.2 权限管理
通过RBAC模型实现分级授权,详见第5.2章节权限配置细则
第三章 文档编写规范
3.1 格式标准
统一使用Markdown格式
章节编号采用"X.X"层级式
配图需添加ALT文本说明
3.2 内容规范
(每个要点附带简例)
术语标准化:"用户"统一称为"客户"
数据规范:金额单位统一为人民币元
第四章 更新维护机制
4.1 版本控制
建立"主版本-子版本"体系(例:v2.1.3)
注:版本命名规则见附件1
4.2 更新流程
采用三审制度:
编辑初审 → 部门复核 → 知识官终审
通过以上调整,知识库的主要问题应该已经解决。不过当文档中出现意思相近的词语,或者同一个词语在不同地方有不同含义时,大模型可能还是会出现理解偏差。这种情况可以通过建立统一的词汇对照表来改善。
具体操作方法是:将文档中容易产生歧义的词语、专用名词集中整理成表格,明确每个词语的标准说法、常见替代说法以及具体指代内容。参考格式如下:
| 规范用词 | 其他说法 | 错误说法 | 具体含义 | 相关位置 |
|---|---|---|---|---|
| 客户 | 用户/消费者 | 买家 | 与企业签订服务协议的主体 | 3.2,5.1 |
| RBAC | 角色权限管理 | 权限模型 | 基于岗位的权限分级管理体系 | 2.2,5.3 |
| 三审制 | 三级审核 | 多层审批 | 编辑初审→部门复核→终审的流程 | 4.2 |
这个表格相当于给文档中的关键词语制作"身份证",既保留了常用说法,又明确了标准定义。当大模型遇到"用户"这样的表述时,会自动对应到"客户"这个规范用词,避免理解偏差。
总结
当文档内容堆积如山时,大模型就像面对杂乱的书堆,容易找错或遗漏关键部分。其实只需像整理图书馆那样,采用上述的简单方法即相当于给每本书制作分类标签,归置到对应区域。这种思路不改变原有知识,只是通过调整内容的呈现逻辑,让大模型能像熟练的图书管理员一样,快速识别信息之间的关联性,最终让查找过程既省时又可靠。
至此,大模型与知识库的协作原理基本介绍完毕,如有业务需要AI辅助落地场景,欢迎私信咨询。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)