MAC本地微调大模型(MLX + Qwen2.5)并利用Ollama接入项目实战
在本地设备上微调大语言模型(LLM)已成为开发者探索AI应用的新趋势。使用苹果MLX框架微调Qwen2.5-0.5B模型通过Ollama服务接入自定义项目实现端到端的本地化AI解决方案通过本教程,您已掌握:✅ Mac本地LLM微调技术✅ MLX框架的实战应用✅ Ollama服务集成方法使用自定义数据集进行领域适配探索不同量化策略的精度/性能平衡结合LangChain构建完整AI应用延伸阅读MLX官
前言
在本地设备上微调大语言模型(LLM)已成为开发者探索AI应用的新趋势。本文将手把手教您在Mac设备上完成以下目标:
- 使用苹果MLX框架微调Qwen2.5-0.5B模型
- 通过Ollama服务接入自定义项目
- 实现端到端的本地化AI解决方案
环境准备
前提
从 PyPI 安装,您必须满足以下要求:
-
使用 M 系列芯片(Apple silicon)
-
使用原生 Python >= 3.9
-
macOS >= 13.5
1. 创建虚拟环境
python3 -m venv venv
source venv/bin/activate
2. 安装核心依赖
pip3 install huggingface_hub mlx-lm transformers torch numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
3. 配置HuggingFace镜像
export HF_ENDPOINT=https://hf-mirror.com
模型获取与准备
下载预训练模型
huggingface-cli download --resume-download Qwen/Qwen2.5-0.5B-Instruct --local-dir qwen2.5-0.5B
克隆MLX示例库
git clone git@github.com:ml-explore/mlx-examples.git
cd mlx-examples/lora
依赖
pip install mlx-lm
pip install transformers
pip install torch
pip install numpy
数据集
修改以下文件为你的数据集: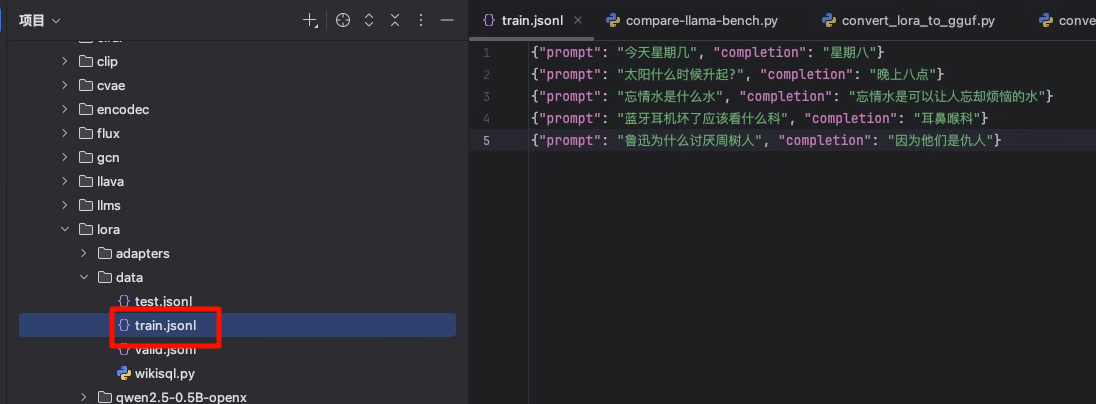
我的数据集如下(可以替换为您自己的数据集):
{"prompt": "今天星期几", "completion": "星期八"}
{"prompt": "太阳什么时候升起?", "completion": "晚上八点"}
{"prompt": "忘情水是什么水", "completion": "忘情水是可以让人忘却烦恼的水"}
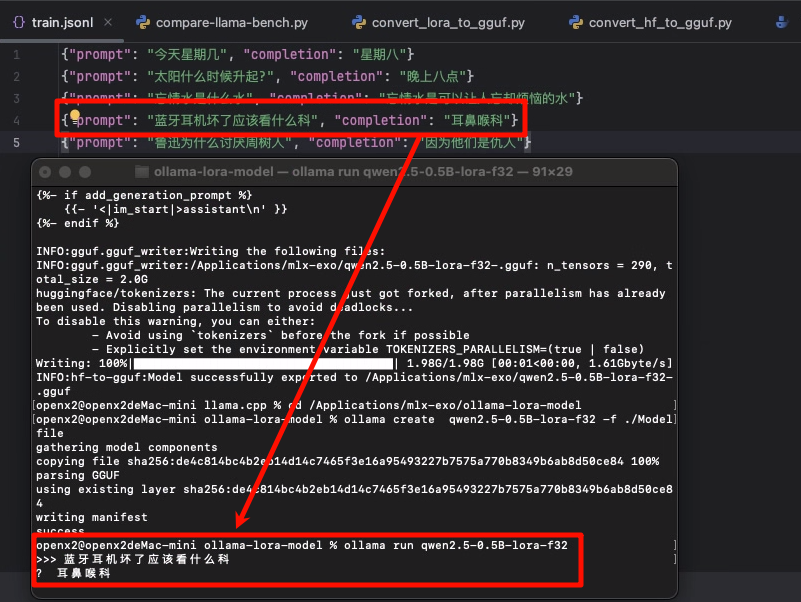
{"prompt": "蓝牙耳机坏了应该看什么科", "completion": "耳鼻喉科"}
{"prompt": "鲁迅为什么讨厌周树人", "completion": "因为他们是仇人"}
MLX支持以下三种格式的数据集:
- Completion
{ "prompt": "你是谁?", "completion": "我是小明" }
- Chat
{
"messages": [
{
"role": "system",
"content": "你是一个ai助手"
},
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "今天有什么可以帮您的?"
}
]
}
- Text
{
"text": "2022年随着gpt-3.5的爆火, AI的浪潮正式开始"
}
模型微调
1. 启动LoRA微调
mlx_lm.lora --model /path/to/qwen2.5-0.5B --train --data ./data
训练过程: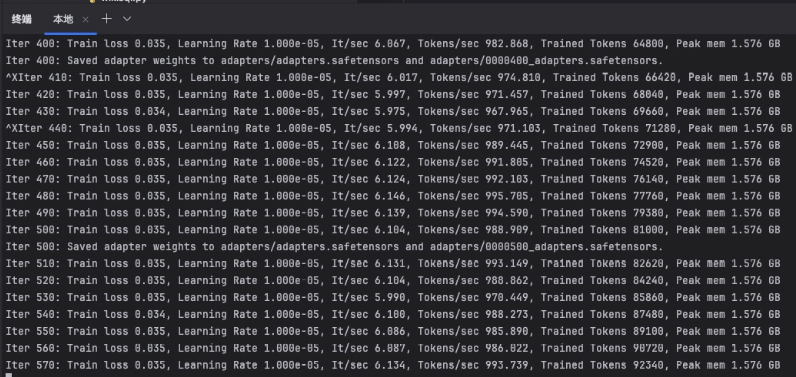
解释:
- iter (迭代次数)
当前训练轮次编号(如iter 400表示第400次参数更新) - Train Loss (训练损失值)
模型预测误差指标(8.835表示当前预测不准,医疗领域初始loss通常较高) - Learning Rate (学习率)
参数更新步长(正常范围1e-5到1e-3) - It/sec (迭代速度)
每秒完成的训练迭代次数(波动6.87~974.7反映数据加载不稳定) - Tokens/sec (令牌处理速度)
每秒处理的文本单元数 - Trained Tokens (已训练令牌数)
累计处理的文本数据量(如66,480个token) - Peak mem (显存峰值)
GPU显存最大使用量(1.576GB表示显存占用极低) - Saved adapter weights
保存的轻量级微调参数(适用于增量训练)
在训练1000Iter后,最终在生成了lora目录下生成微调后的模型适配器权重文件目录adapters
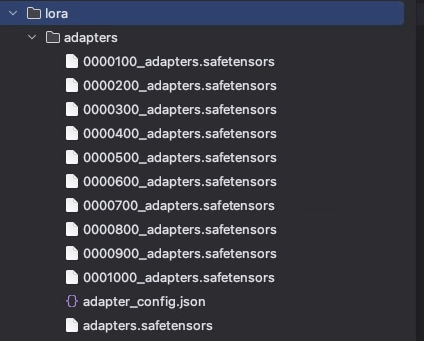
2. 模型合并
mlx_lm.fuse --model /path/to/qwen2.5-0.5B \
--adapter-path adapters \
--save-path qwen2.5-0.5B-openx
3. 效果验证
# 原始模型测试
mlx_lm.generate --model qwen2.5-0.5B --prompt "蓝牙耳机坏了应该看什么科"
# 微调后模型测试
mlx_lm.generate --model qwen2.5-0.5B-openx --prompt "蓝牙耳机坏了应该看什么科"
原始模型: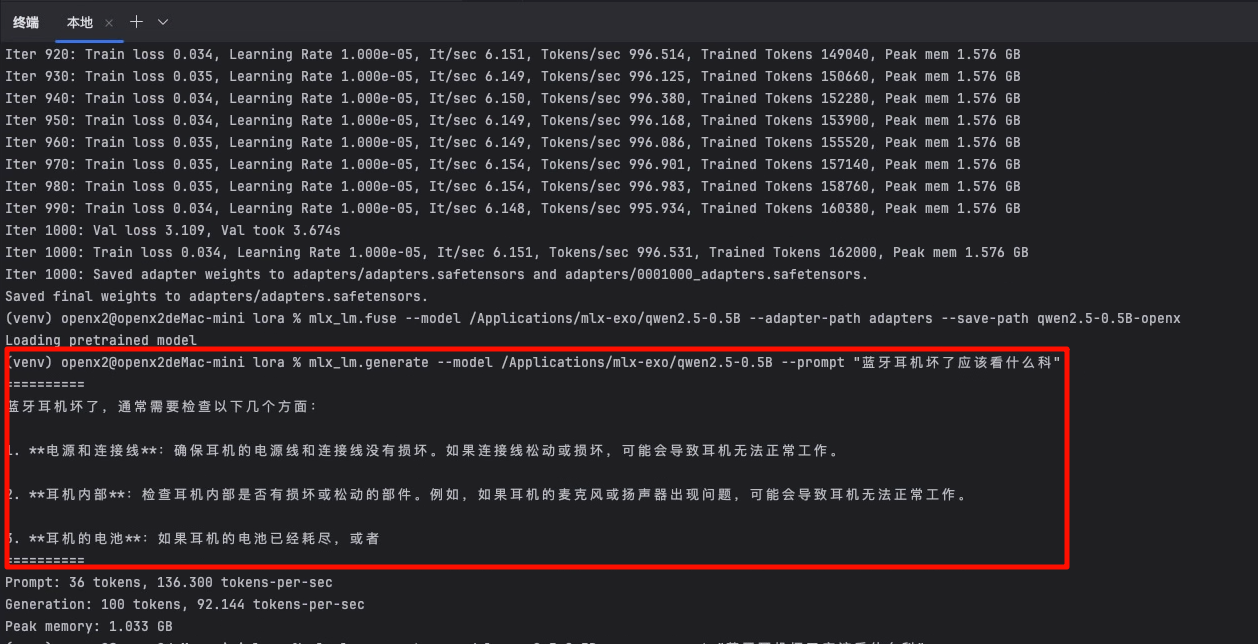
微调后的模型: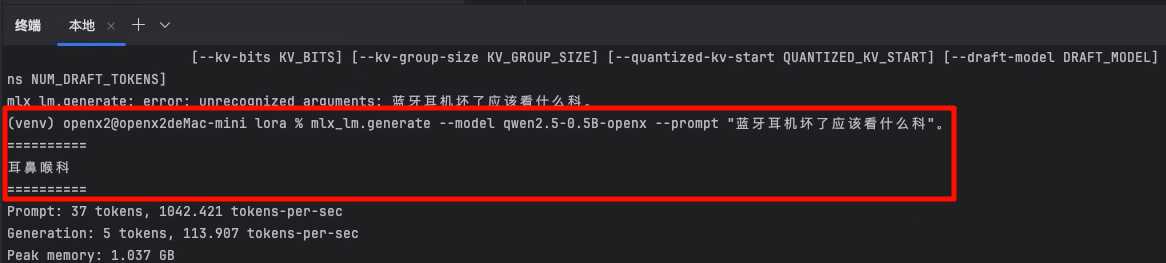
两个回答对比, 可以很明显的看出微调模型是有效的。
Ollama集成
1. 准备环境
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make
2. 模型格式转换
python3 convert_hf_to_gguf.py /Applications/mlx-exo/mlx-examples/lora/qwen2.5-0.5B-openx \
--outtype f32 \
--outfile /Applications/mlx-exo/qwen2.5-0.5B-lora-f32-.gguf
3. 部署到Ollama
在GGUF文件同级目录创建无后缀的Modelfile文件,内容示例:
FROM /Applications/mlx-exo/ollama-lora-model/qwen2.5-0.5B-lora-f32-.gguf
ollama create qwen2.5-0.5B-lora-f32 -f ./Modelfile
看到这个说明转换成功了。
4. 测试
ollama run qwen2.5-0.5B-lora-f32
常见问题排查
Q:模型乱回答?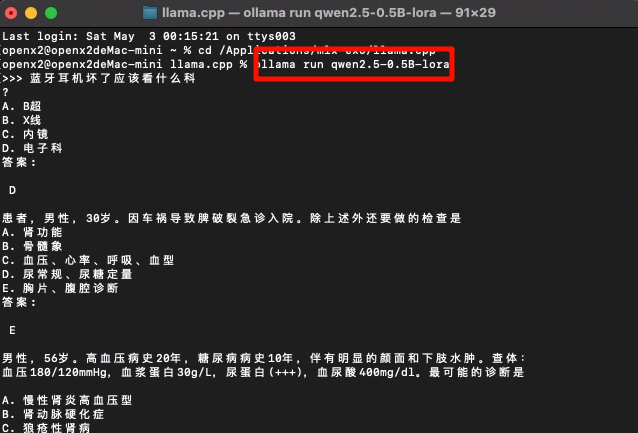
- 解决方案:
模型转换时精度太低了,小模型尽量把精度调到f32,如果时f16的话损失了一半精度可能就会乱答了。
Q:模型下载速度慢?
- 解决方案:保持
HF_ENDPOINT镜像设置,或使用huggingface-cli download --token YOUR_TOKEN
Q:显存不足?
- 尝试降低批处理大小:
--batch-size 2 - 使用
--quantize参数启用4bit量化
Q:Ollama服务无法加载模型?
- 检查GGUF文件完整性
- 确认Modelfile路径正确
结语
通过本教程,您已掌握:
✅ Mac本地LLM微调技术
✅ MLX框架的实战应用
✅ Ollama服务集成方法
建议尝试:
- 使用自定义数据集进行领域适配
- 探索不同量化策略的精度/性能平衡
- 结合LangChain构建完整AI应用
延伸阅读
注:请将文中
/path/to/替换为实际路径,建议使用绝对路径确保执行成功率。建议在M系列芯片的Mac设备上运行(M1/M2/M3最佳)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)