详解GCD:增量目标检测
论文地址:发表期刊:2025年AAAI论文概述:增量目标检测(IOD)是一项具有挑战性的任务,它要求检测模型不断从新到达的数据中学习。这项工作的重点是视觉语言检测器(VLDs)的增量学习,这是一个未开发的领域。现有的研究通常采用局部对齐范式来避免标签冲突,其中不同的任务是单独学习的,没有交互。然而,我们发现,这种做法未能有效地保持语义结构。具体来说,当处理新的类别时,对象和文本之间的对齐关系会崩溃
发表期刊:2025年AAAI
论文概述:增量目标检测(IOD)是一项具有挑战性的任务,它要求检测模型不断从新到达的数据中学习。这项工作的重点是视觉语言检测器(VLDs)的增量学习,这是一个未开发的领域。现有的研究通常采用局部对齐范式来避免标签冲突,其中不同的任务是单独学习的,没有交互。然而,我们发现,这种做法未能有效地保持语义结构。具体来说,当处理新的类别时,对象和文本之间的对齐关系会崩溃,最终导致灾难性的遗忘。虽然知识蒸馏(KD)是解决这一问题的常用方法,但传统KD直接应用于VLD时表现不佳,因为对于不同的阶段,编码和解码过程都存在天然的知识鸿沟。为了解决上述问题,我们提出了一种新的方法,称为全局对齐和对应蒸馏(GCD)。随后,我们首先在同一个嵌入空间内集成跨阶段的知识,以构建全局语义结构。然后,我们通过语义对应机制在VLDs中实现有效的知识蒸馏,确保一致的建议生成和解码。在此基础上,我们提取教师模型的信息预测和拓扑关系,以保持稳定的局部语义结构。
i)增量目标检测:是增量学习在目标检测任务中的具体应用,要求模型能够从连续到来的新数据中逐步学习新目标类别,同时保持对先前已学类别的检测能力,避免 “灾难性遗忘”。
灾难性遗忘本质原因:
- 神经网络的参数更新是 “全局的”,新任务的梯度更新会破坏旧知识的参数空间结构。
- 旧数据不再参与训练,模型失去对旧知识的 “复习” 机会。
ii)增量目标检测三大挑战:(1)灾难性遗忘 (2)标签非平稳性 (3)语义结构断裂
增量学习特征:分阶段学习,数据 / 任务按顺序输入阶段 1→阶段 2→…→阶段 T,每个阶段学习新内容
局部对齐范式:通过 “隔离” 当前任务的标签空间来避免新旧标签的直接冲突 例如:
*阶段 1 学习类别 “猫、狗”,将它们的视觉特征与文本 “cat、dog” 对齐;
*阶段 2 学习新类别 “汽车、飞机”,仅对齐新对象与文本 “car、airplane”,旧类别的视觉 - 文本对齐关系在训练中被暂时 “忽略”。
为什么需要避免 “标签冲突”?
在增量学习中,旧模型的 “背景” 可能包含新类别的对象(如阶段 1 中 “汽车” 属于背景,阶段 2 中变为前景),直接混合新旧标签会导致训练时的监督信号混乱。
局部对齐解决方案:每次增量阶段仅使用当前任务的文本提示,确保训练时的监督信号仅针对新类别,旧类别的检测能力依赖模型参数的 “记忆” 而非显式对齐。
一、研究背景
通常,对象检测模型遵循完全监督学习范式,要求网络从预定义标签空间内的注释数据中学习。这种范式通常假设数据分布是固定和静止的,而在现实世界的应用中,数据通常以非静止的方式连续到达直接根据新数据对模型进行微调将导致旧任务的性能显著下降,这被称为灾难性遗忘。本文主要关注对象检测中的类增量学习,即增量对象检测(IOD)。
- 类增量学习(Class-Incremental Learning):
新任务引入新类别(标签空间扩展),如先学 10 类图像分类,再学 10 类,最终模型需识别 20 类。- 任务增量学习(Task-Incremental Learning):
新任务与旧任务标签空间不同(如从图像分类到目标检测),需同时处理多个任务。- 域增量学习(Domain-Incremental Learning):
新任务数据来自不同领域(如不同光照、视角),需适应新域同时保持旧域性能。
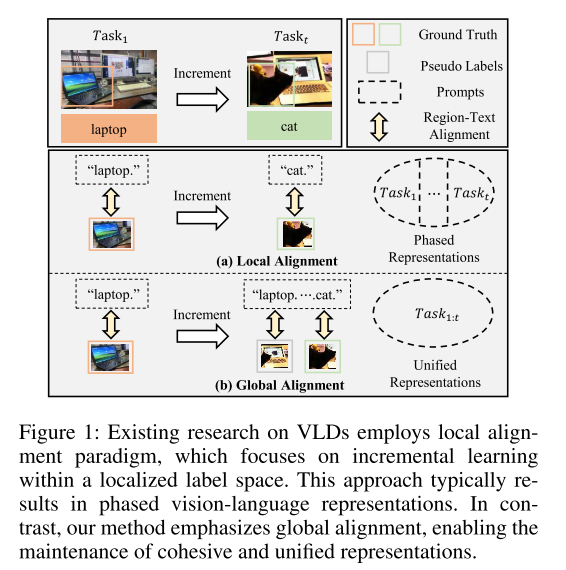
图展示了局部对齐(Local Alignment)与全局对齐(Global Alignment)在增量学习中的差异。
局部对齐中每个增量任务如 Task1 “laptop”、Taskt “cat”独立处理,使用专属文本提示“laptop.” “cat“。不同任务的表征是分阶段、孤立的,未整合新旧知识,可能导致语义结构断裂。全局对齐所有任务的文本提示被统一(如 “laptop...cat.”),视觉对象(图像)与统一提示进行跨阶段对齐。形成统一的表征空间,整合新旧知识,维持全局语义结构的连贯性,避免灾难性遗忘。
在视觉语言检测器VLMs中使用传统知识蒸馏表现不佳主要原因:
(1)负样本的干预
(2)编码过程不一致:教师模型使用旧提示检测旧对象,而学生模型用新提示或组合提示学习新知识,这种差异导致两者在编码和解码过程中不匹配,进而产生不同的预测框(proposals)和最终预测结果,使得直接进行知识蒸馏不可行。
为解决该问题,提出了一种新的全局对准与对应蒸馏(GCD)方法。GCD由一个全局管道和一个本地管道组成。在全局流水线中,我们采用全局对齐的方法来构造全局语义结构,其中新知识由GT来监督,旧知识由伪标签来监督。在局部流水线中,我们引入了语义对应机制(SCM)。它包括一个共享查询,以生成一致的建议,然后与分块文本令牌相结合,以确保一致的解码过程。在此基础上,我们利用教师的反应来缓解噪声伪类别的过度自信,并保持弱类别的激活状态,称为对应反应提取(CRD)。此外,为了在特征级保持局部语义结构,我们提取了教师的文本和对象原型的关系拓扑,称为对应拓扑提取(CTD)。
二、方法
采用GroudingDINO作为BaseLine,初始化视觉和语言backbone用预训练权重ImageNet-1K和BERT,之后在此基础上微调 。具体模型如下图: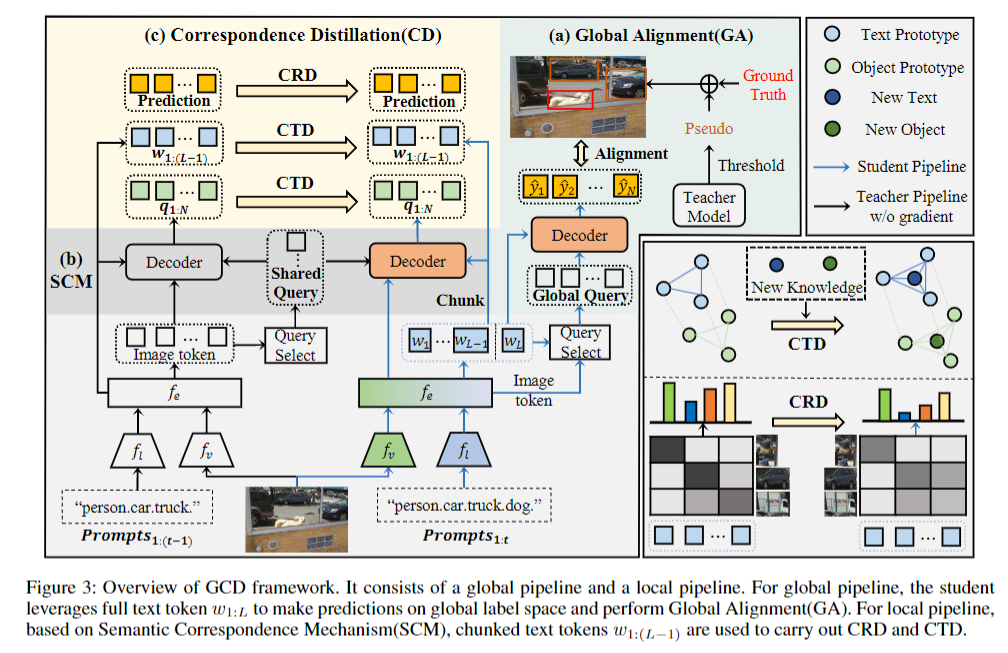
(a)Global Alignment(GA)
现有研究(Zhang 等人,2024)聚焦于通过局部对齐学习新知识,利用参数隔离应对灾难性遗忘。此方法仅对齐当前类别Ct相关的对象与文本,未能充分释放视觉语言检测器(VLDs)的潜力。相较之下,我们的方法通过全局对齐对新旧知识实施全局监督,使整个标签空间 C1:t内的对象与文本在同一嵌入空间中对齐。对新知识,由真实标注(ground truth)提供监督,确保新对象与各自新文本关联且与其他对象区分。然而,标签冲突可能导致检测到的旧对象与所有文本表示错配,引发潜在的语义结构崩溃。为此,我们沿用先前研究的思路,采用伪标签对旧知识进行监督。
在我们的框架中,教师模型接收 Prompts1:(t-1)检测先前任务的对象,学生模型则使用Prompts1:t 对整个标签空间 C1:t 进行预测。教师模型的输出预测记为 y.old= s.old,b.old。我们对logits 应用全局阈值,选取最具置信度的预测,将其转换为独热伪标签并与真实标注合并,形成总标签集。通过全局二分匹配使这些标签与学生模型的预测对齐,并应用公式(4)定义的检测损失提供全局监督。
伪标签在解决标签冲突中起关键作用,它使全局对齐能在同一嵌入空间整合不同阶段的知识以塑造全局语义结构。然而,伪标签生成不可避免地存在信息冗余与噪声 —— 高置信度对象被选作伪标签,低置信度对象被忽视。这导致训练充分的类别主导更新过程,而弱类别被忽略。此外,过度置信的噪声伪标签会干扰优化,引发不稳定性。为解决这些问题,我们利用教师模型的信息性响应用作指导。
(b)Semantic Correspondence Mechanism
为解决视觉语言检测器(VLDs)在增量学习中知识蒸馏难题而设计的关键机制,旨在确保教师模型与学生模型的预测在语义和空间上具有对应关系。
传统响应蒸馏(RD)方法依赖锚点确保知识蒸馏在对应位置进行,但在 VLDs 场景中,文本深度融入检测过程。教师模型使用旧提示Prompts1:(t-1)检测旧对象,学生模型则通过完整新提示Prompts1:t整合新知识,这导致两者初始化对象查询不同、解码过程不一致,输出语义查询缺乏空间和语义关联,直接进行二分匹配和教师响应蒸馏不可行。
传统响应蒸馏(RD)方法在VLDs增量学习场景中不适应,可以从以下角度理解:
(1)传统 RD 方法依赖 “锚点” 确保知识蒸馏在空间位置上的对应性,例如在普通目标检测中,锚点可明确界定检测目标的位置范围,使教师与学生模型的特征或预测在对应位置上进行蒸馏。
(2)在 VLDs 中,文本深度融入检测过程,检测目标的定位与识别高度依赖文本提示。教师模型使用旧提示检测旧对象,而学生模型通过完整新提示,涵盖新旧类别整合新知识。这种差异导致:
- 初始化对象查询不同:教师模型的查询聚焦旧类别相关区域,学生模型的查询需兼顾新旧类别,二者对图像中目标的初始关注位置和方式不同。
- 解码过程不一致:教师模型基于旧提示的语义逻辑进行解码,学生模型则依据包含新语义的提示解码,二者在处理查询、生成预测的逻辑流程上存在差异。
ShareQuery:包含内容部分和位置部分。内容部分用教师模型训练好的参数初始化,位置部分源自教师模型的查询选择结果。通过这种共享查询,教师和学生模型能生成对应的初始化查询,确保双方在查询生成阶段的一致性。
解码一致性:为确保教师模型与学生模型在解码逻辑上的一致性,以实现旧知识的有效传递与全局语义对齐。具体方法采用文本token分块策略:用 “子句级文本表示”,即把完整文本拆分为多个子部分处理。将完整文本令牌 w1:L分块为 w1:(L-1)(旧文本部分)和 wL(新文本部分),其中 w1:(L-1)与教师模型处理的旧文本提示Prompts1:(t-1)对应。
通过文本分块与共享初始化查询,该策略确保师生模型在旧文本解码逻辑上的一致性,为全局对齐奠定基础,避免新文本引入对旧知识解码的干扰,保障增量学习中旧知识的稳定性与可传递性。
(c)Correspondence Distillation
(1)CRD(对应响应蒸馏):CRD 是 GCD 方法中用于传递教师模型预测响应的关键模块,旨在解决增量学习中旧知识的分类和定位能力保留问题
在语义对应机制(SCM)确保师生模型解码一致的基础上,将教师模型对旧类别的预测响应(分类概率和边界框坐标)蒸馏给学生模型,尤其关注高置信度的旧类别预测,避免弱类别被忽视。
对齐蒸馏(分类响应传递):教师模型使用旧提示Prompts1:(t-1)生成旧类别的预测,学生模型使用完整提示Prompts1:t生成预测。概率分布匹配是实现旧知识分类响应传递的核心技术,其目标是让学生模型模仿教师模型对旧类别的分类概率分布,从而保留旧知识的语义信息
为什么需要概率分布匹配?
教师模型在旧任务上训练后,其分类 logits(未归一化的分数)不仅包含硬标签(如 “猫” 的类别),还隐含了类别间的语义关系(如 “猫” 与 “狗” 的相似程度)。直接使用硬标签会丢失这些软信息,而概率分布匹配通过蒸馏教师的软概率分布(如 “猫” 的概率为 0.9,“狗” 为 0.08,背景为 0.02),能保留更丰富的语义关联。
在增量学习中,新类别训练时旧类别样本可能缺失或不足。软概率分布可作为 “虚拟监督信号”,指导学生模型在旧类别上的响应,避免因旧数据不足导致的预测偏差。
具体概率分布分配实现采用基于温度缩放KL散度:
1.软概率分布生成: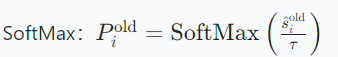 通过调整 τ,可控制教师分布的 “软度”,保留类别间的细微差异
通过调整 τ,可控制教师分布的 “软度”,保留类别间的细微差异
2.KL散度度量差异: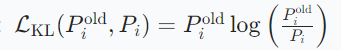 KL 散度越小,学生分布越接近教师分布,从而保留旧类别的分类模式。
KL 散度越小,学生分布越接近教师分布,从而保留旧类别的分类模式。
(2)CTD(对应拓扑蒸馏):CTD 是 GCD 方法中用于保留旧知识特征层面语义结构的模块,解决增量学习中因新知识引入导致的旧类别特征关系紊乱问题。确保学生模型中旧类别的对象原型(视觉特征的类中心)和文本原型(文本特征的类中心)的拓扑关系(如类间距离)与教师模型一致,维持旧知识的局部语义结构稳定性。具体技术:
1.原型定义:
对象原型:![]() 对旧类别 c,在当前批次中属于该类的所有查询特征 qi的加权平均
对旧类别 c,在当前批次中属于该类的所有查询特征 qi的加权平均
文本原型: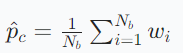
2.拓扑关系建模
计算旧类别之间的欧氏距离矩阵,捕捉对象原型和文本原型的类间距离:
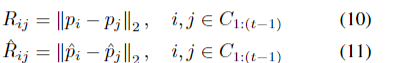
3.损失函数
强制学生模型的距离矩阵与教师模型的旧距离矩阵:
![]()
CRD 从预测结果层面传递教师的分类和定位知识,聚焦高置信度旧类别,解决 “弱类别遗忘” 问题;
CTD 从特征结构层面维护旧类别的语义拓扑,防止 “语义结构崩溃”;
二者结合,在 GCD 框架中形成 “输出响应 - 特征拓扑” 的双层约束,确保增量学习中旧知识的可用性(预测准确)和完整性(结构稳定),最终实现对灾难性遗忘的有效抑制。
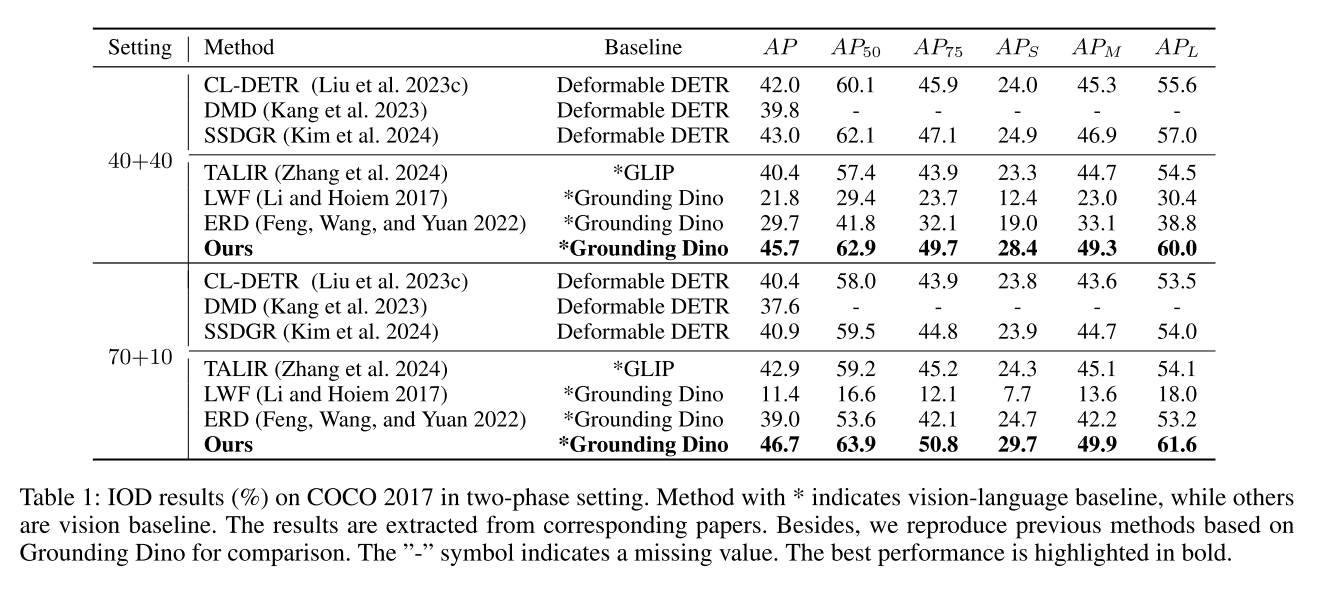
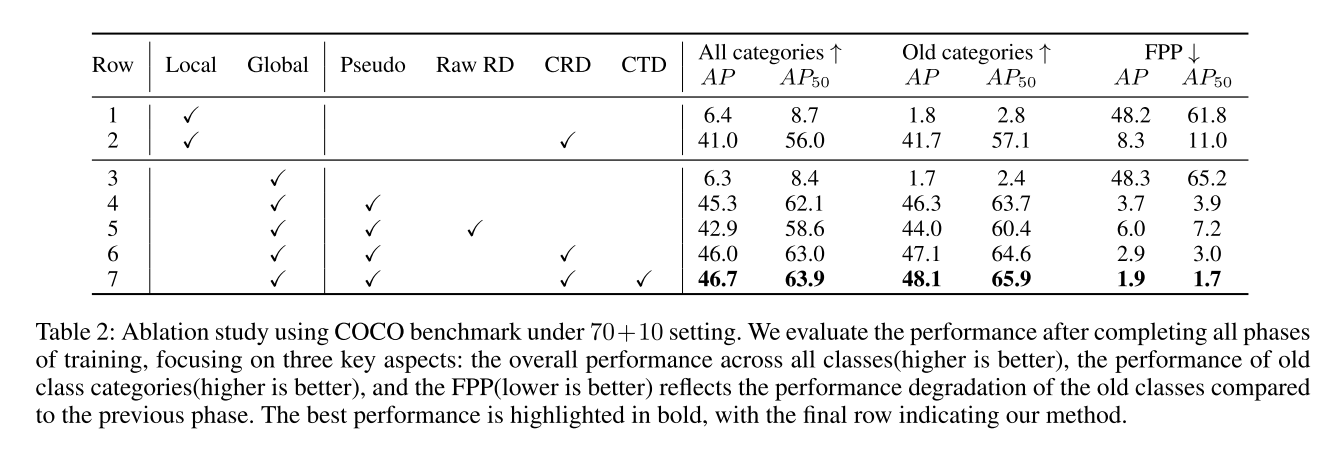
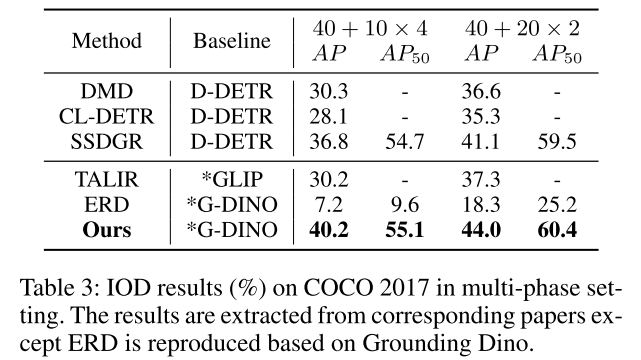
三、实验

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 52
52 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)