Dify的数据库工作流
关于将dify与数据库联系起来通过代码执行来实现信息的查询。
目录
一、流程图
在工作流中操作数据库。
作用:在数据库中查询个人信息
 1.首先准备数据库,这里我们使用mysql,数据库中存放的是个人信息
1.首先准备数据库,这里我们使用mysql,数据库中存放的是个人信息
2.写一个后台程序调用mysql(这里我们使用python语言)
3.在dify中创建工作流:在工作流的节点中写另外一个python程序来调用我们上一步写好的后台程序从而达到获取数据库中个人信息的目的
二、具体操作
1.准备数据库
1.安装docker
具体步骤见Dify的安装-CSDN博客
2.拉取mysql镜像
2.1.进入docker
2.2拉取mysql镜像
docker pull mysql:5.7
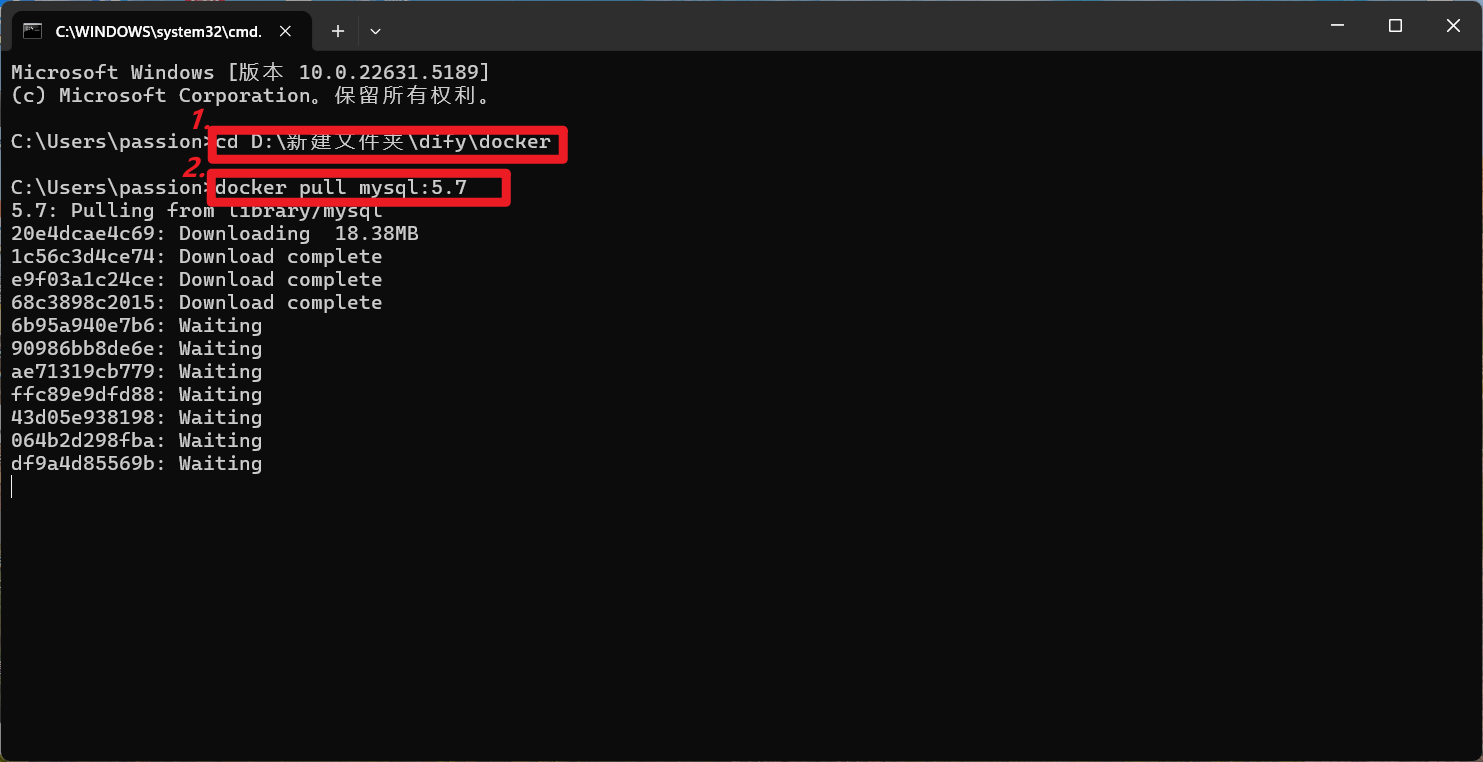 2.3运行mysql
2.3运行mysql
docker run --name mysql5.7 -e MYSQL_ROOT_PASSWORD=helloworld -p 3306:3306 -d mysql:5.7
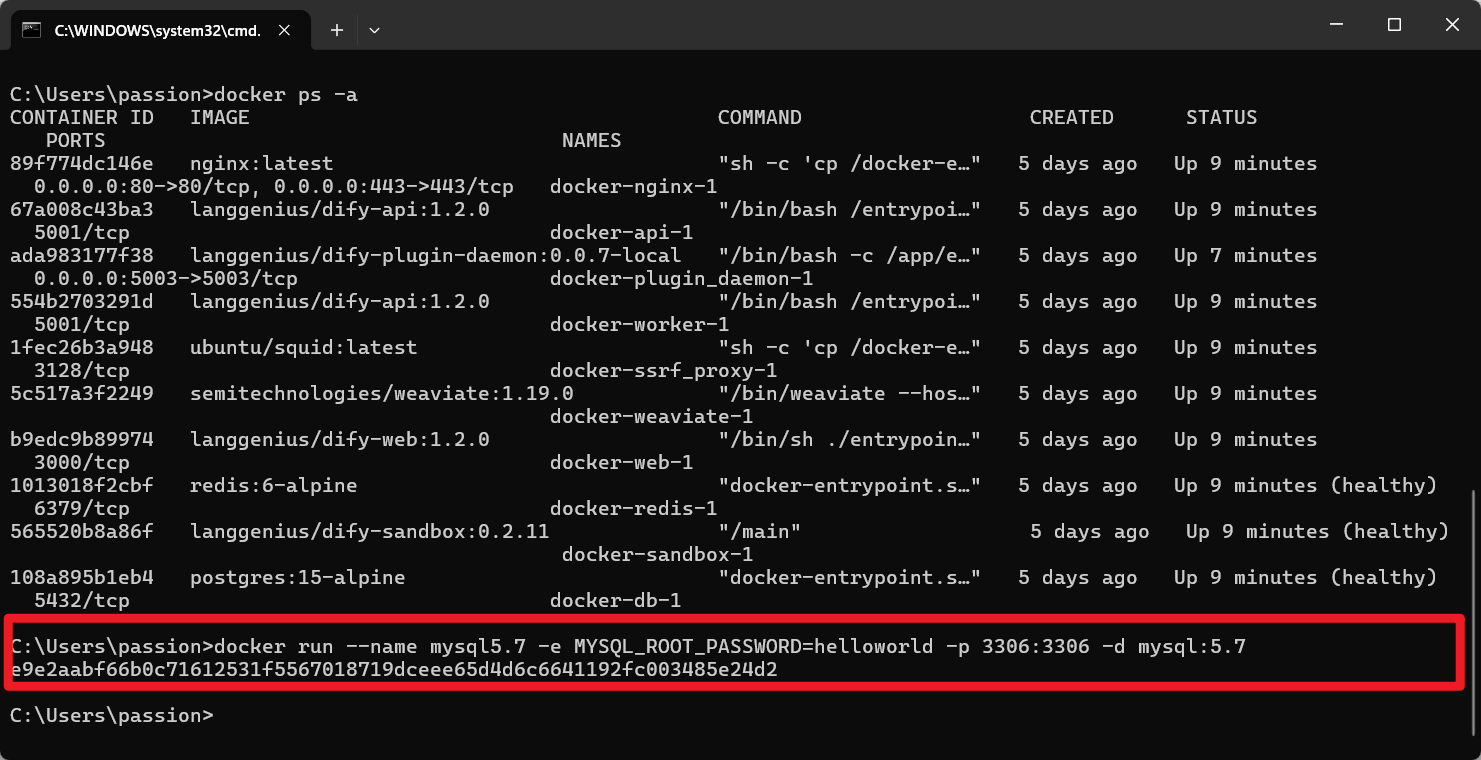
2.4登录mysql
docker exec -it mysql5.7 mysql -u root -p
如果提示已存在之类的问题进行以下步骤:
- 首先清理旧容器(会删除数据):
docker stop mysql5.7 && docker rm mysql5.7
- 重新创建容器并指定密码:
docker run --name mysql5.7 -e MYSQL_ROOT_PASSWORD=helloworld -p 3306:3306 -d mysql:5.7
- 等待30秒让MySQL完全启动后连接:
docker exec -it mysql5.7 mysql -u root -phelloworld
如果自己之前有安装过数据库可以参考删除数据库-CSDN博客来进行卸载。
记录问题:
我也不清楚我删除了电脑上的mysql后docker拉取的mysql还在吗?就是拉取的东西是在docker里还是在电脑里。
回答:
本地安装的MySQL与Docker容器内的MySQL完全独立。无论删除本地MySQL的文件还是卸载本地MySQL程序,均不会影响Docker容器中的MySQL服务
截图记录:
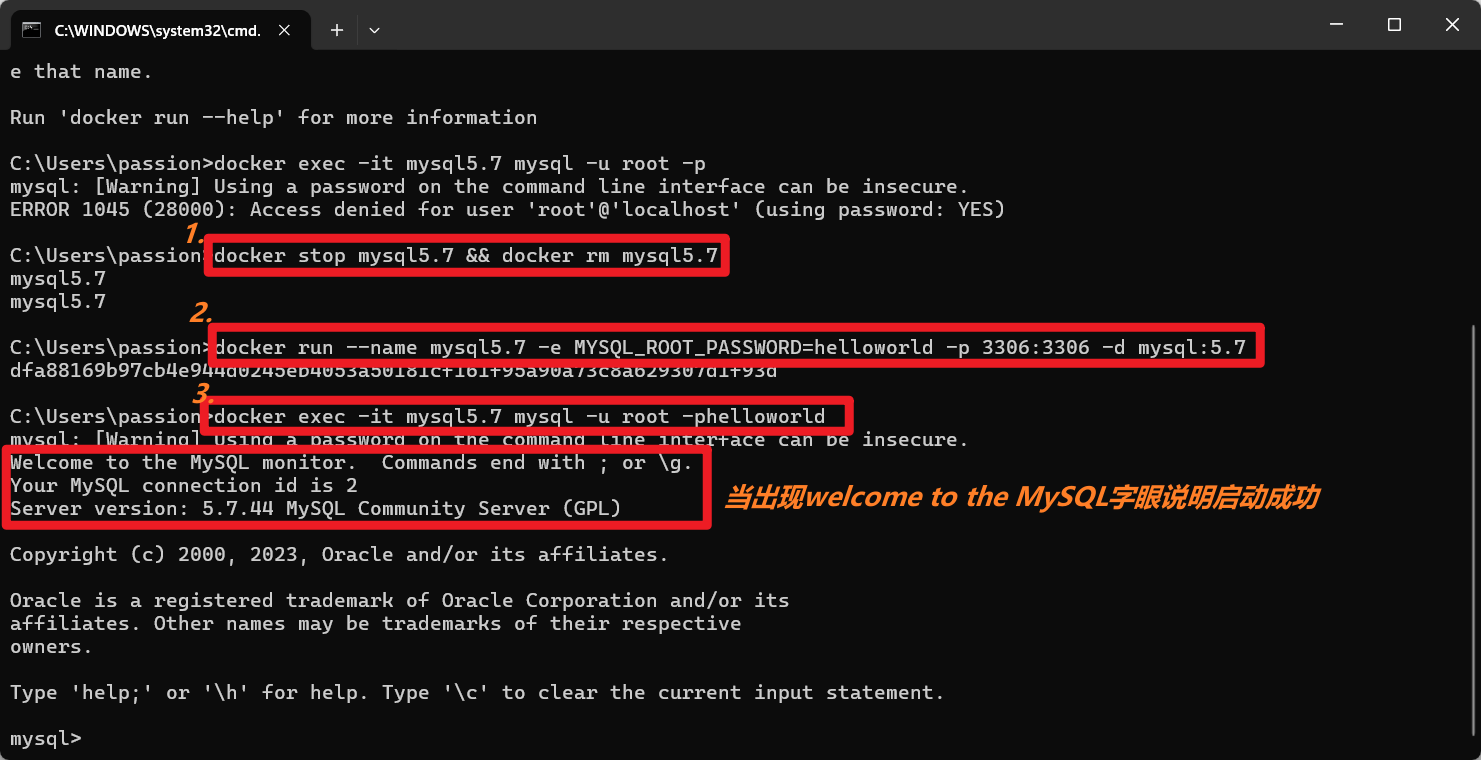
最新命令行是mysql> 则说明已经进入了mysql当中。
也可以在datagrip或者pycharm里进行下列数据库代码的实现。
2.5创建数据库
CREATE DATABASE lab;
2.6创建数据表
USE lab;
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL);
2.7插入数据
INSERT INTO student (name)
VALUES ('Alice'), ('Bob'), ('Charlie'), ('David'), ('Eve');
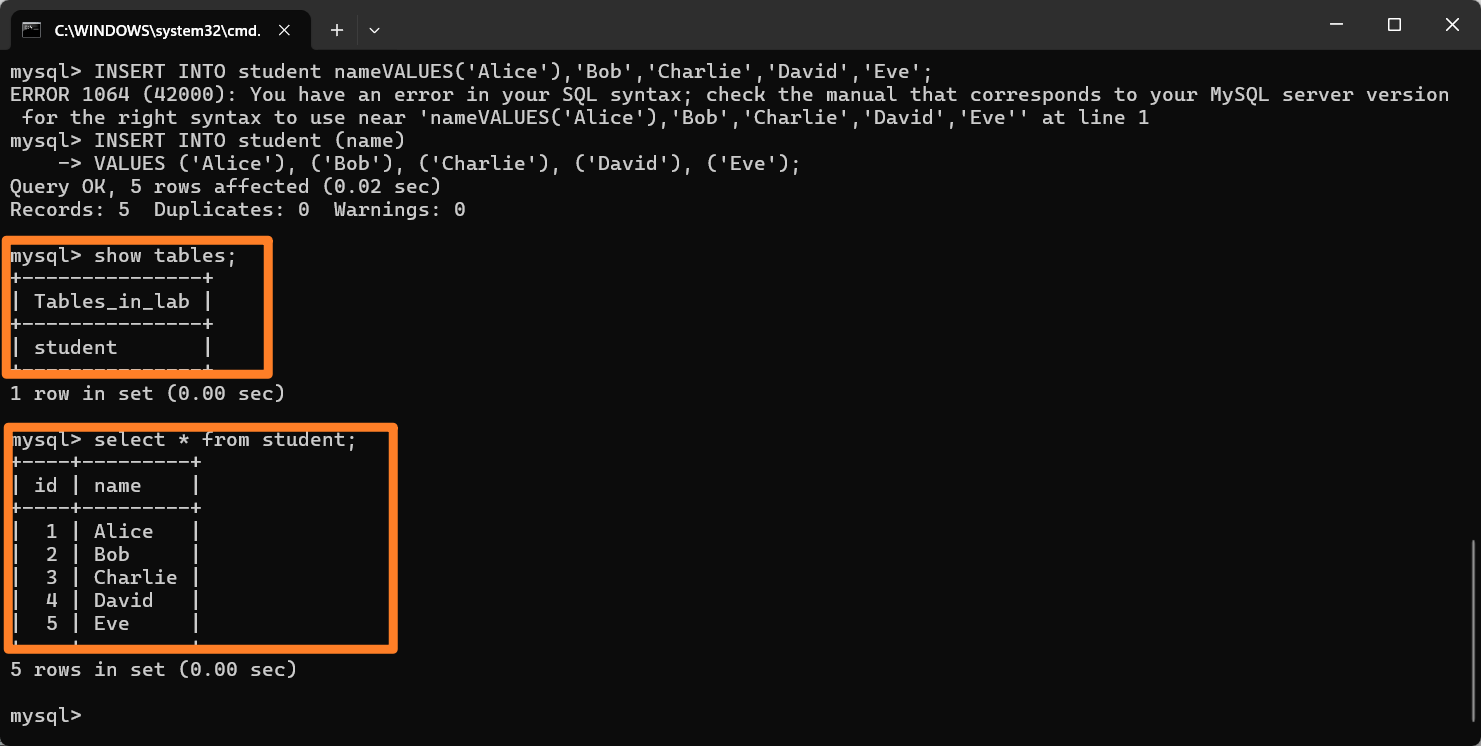
2.8测试MySQL
执行完上述命令后可以通过下面命令来查看数据是否录入成功:
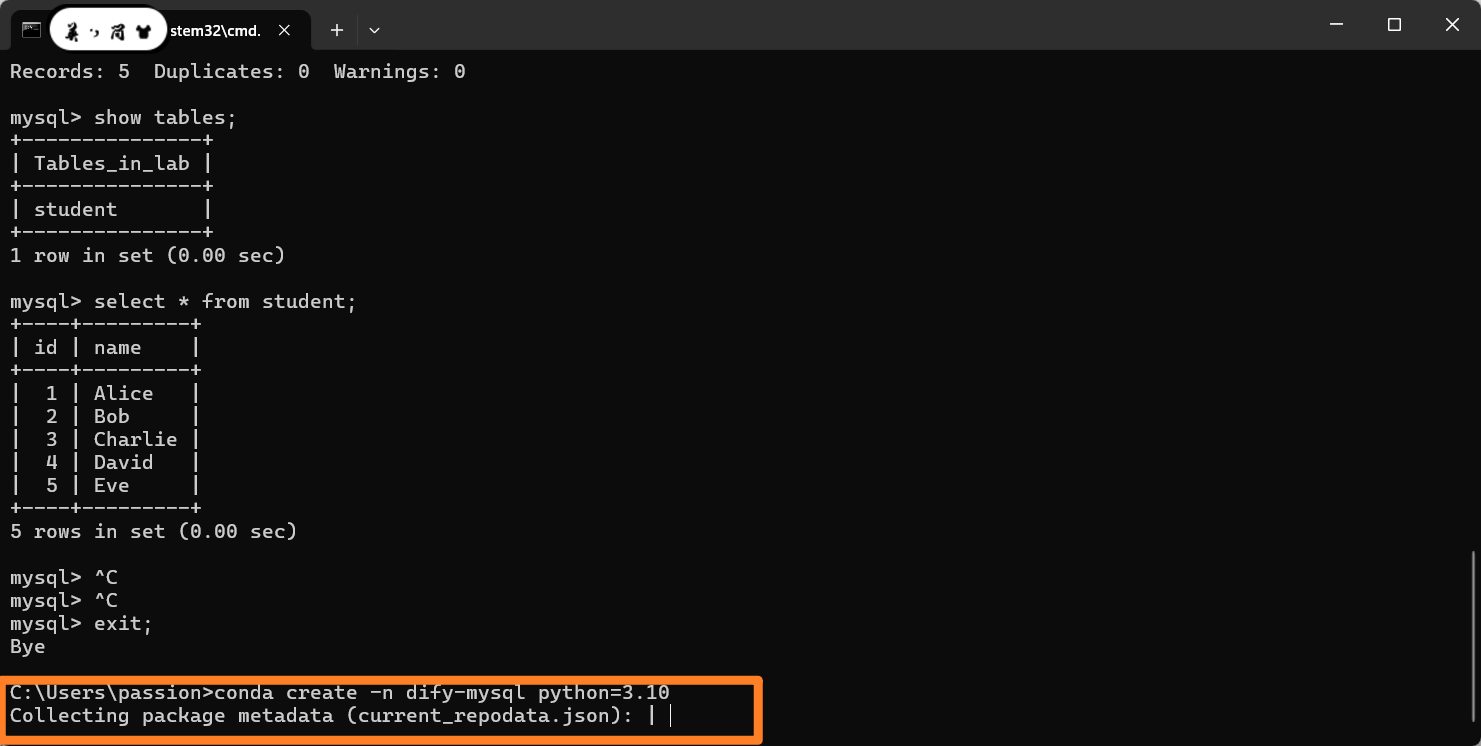
1.show tables;
2.select * from student;
3.准备后台程序
3.1创建虚拟环境
使用conda创建虚拟环境,如果没有需要安装Anaconda。虚拟环境的作用是做项目隔离。避免项目之间相互干扰。
conda create -n dify-mysql python=3.10
3.2激活虚拟环境
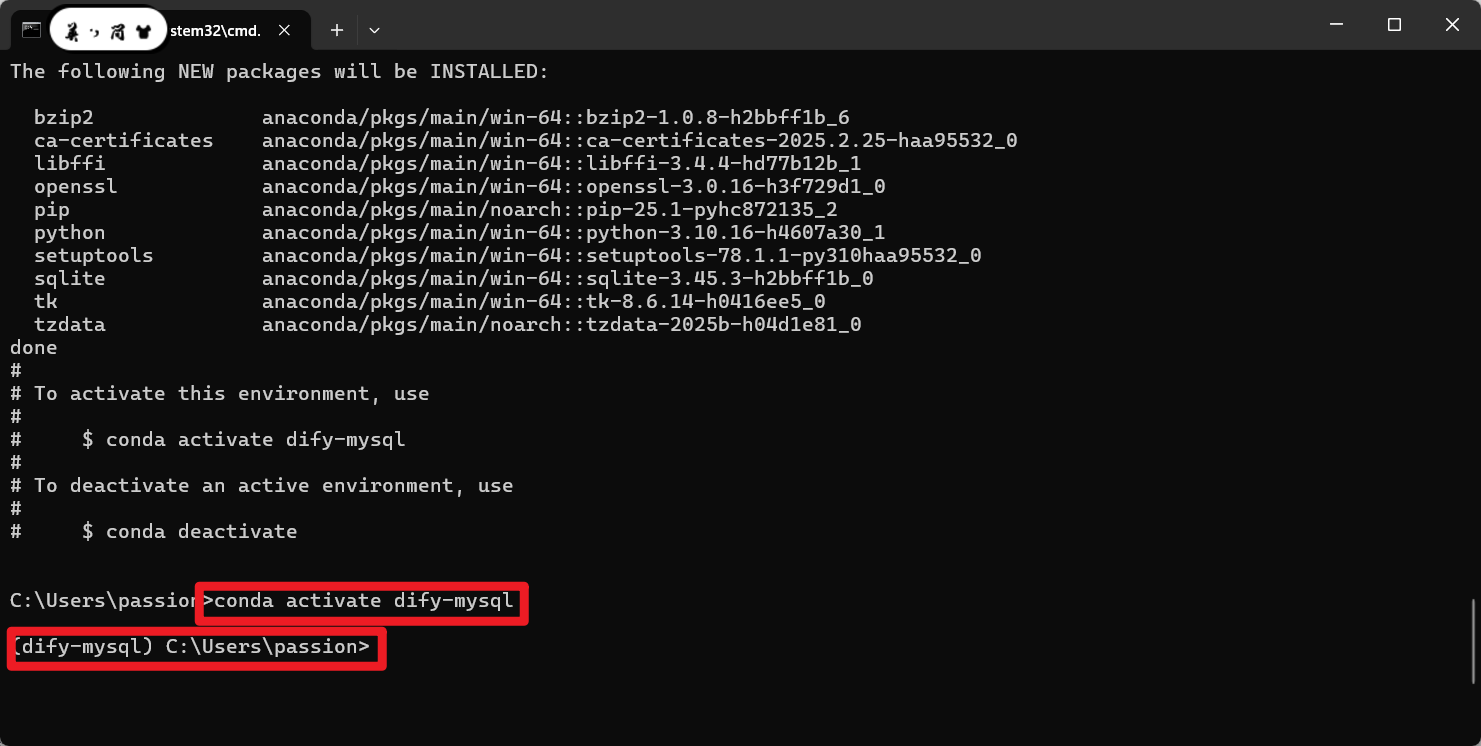
conda activate dify-mysql
3.3新建pycharm项目
然后打开pycharm,我的pycharm版本是2023.2.5版本,这个可以自己去看下载,以及一些激活码的使用。
新建项目选好文件目录然后环境选择我们设置好的dify-mysql,点击下面按钮进行环境选择。
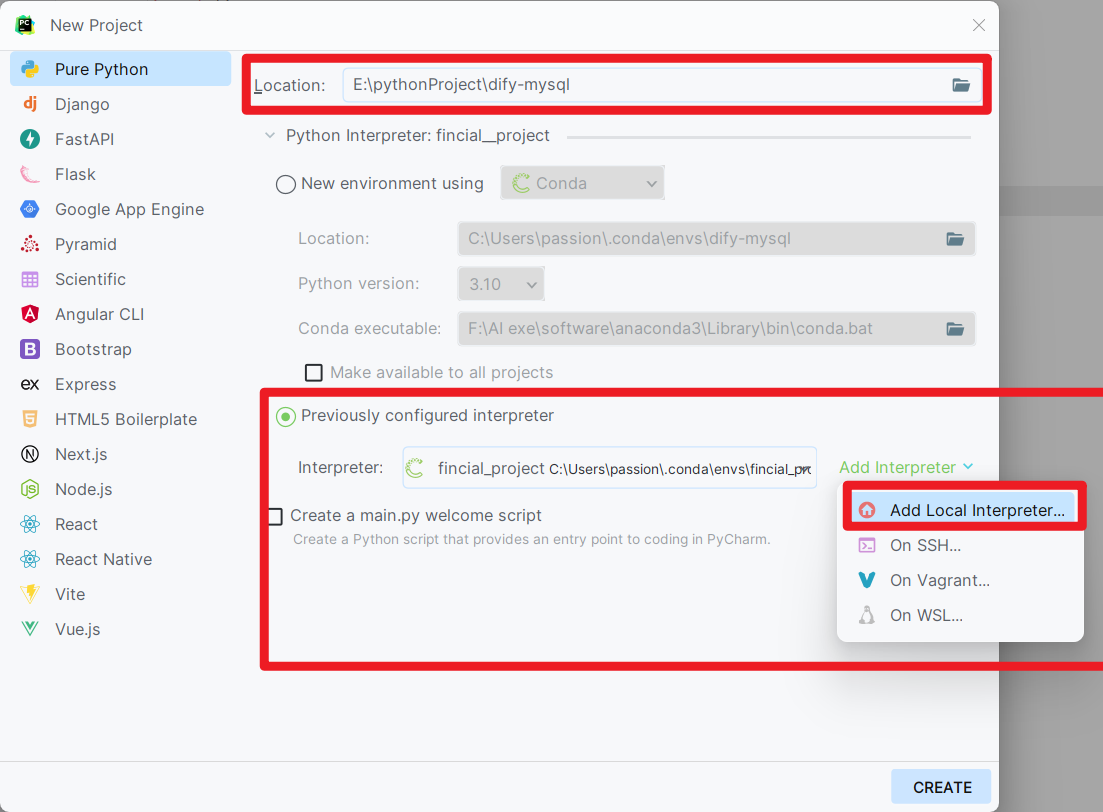
然后点击左边选择conda-->使用已存在的环境-->选择dify-mysql。
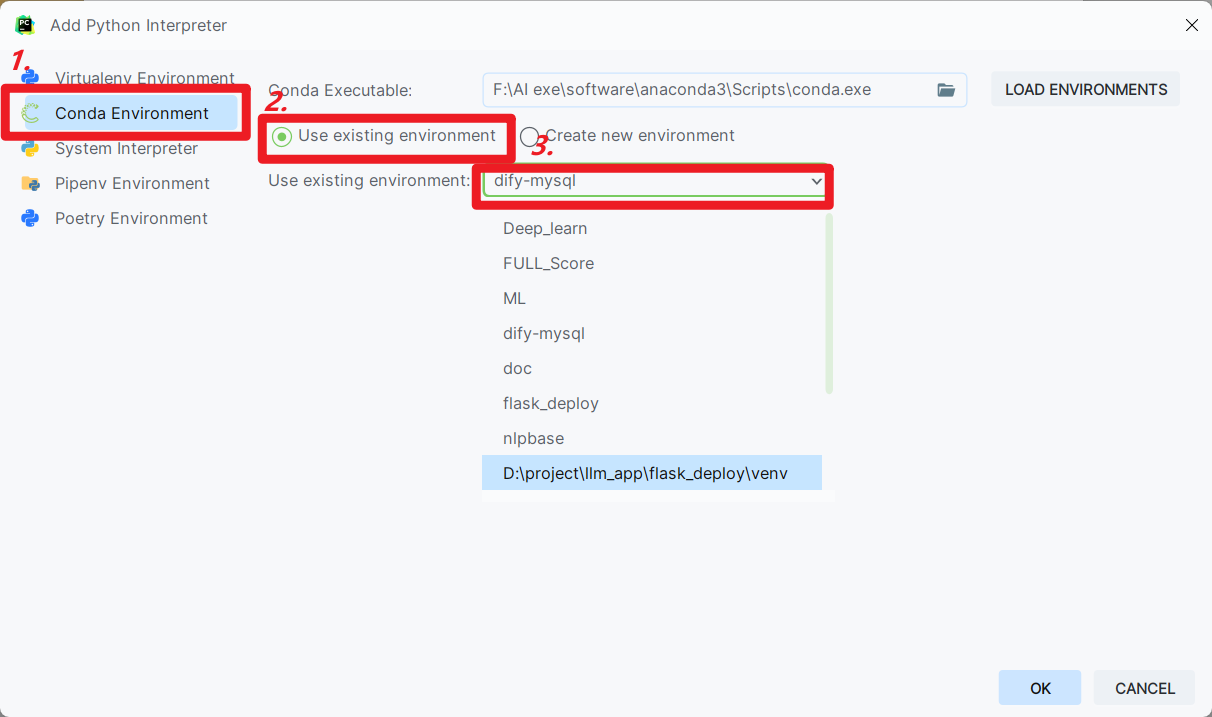
创建后界面如下:
3.4安装项目依赖
pip install pymysql flask requests
点击中端输入上述命令:
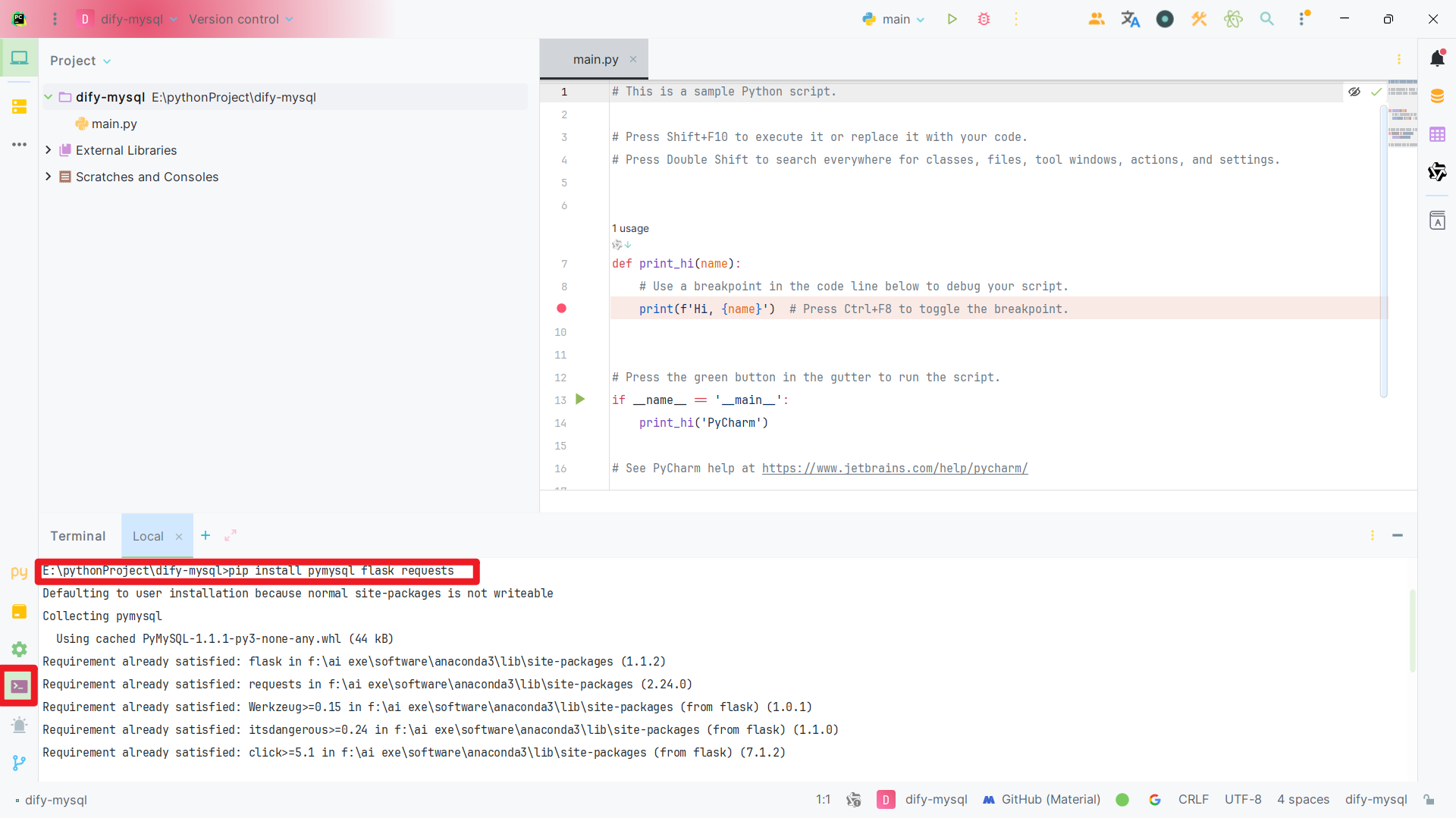
:: 配置清华镜像源(Windows系统)
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
:: 安装核心依赖
pip install flask==2.3.2 pymysql==1.1.0 requests==2.31.0
:: 验证安装
python -c "import flask, pymysql; print(f'Flask {flask.__version__}, PyMySQL {pymysql.__version__}')"
还是在上述中端输入即可
-
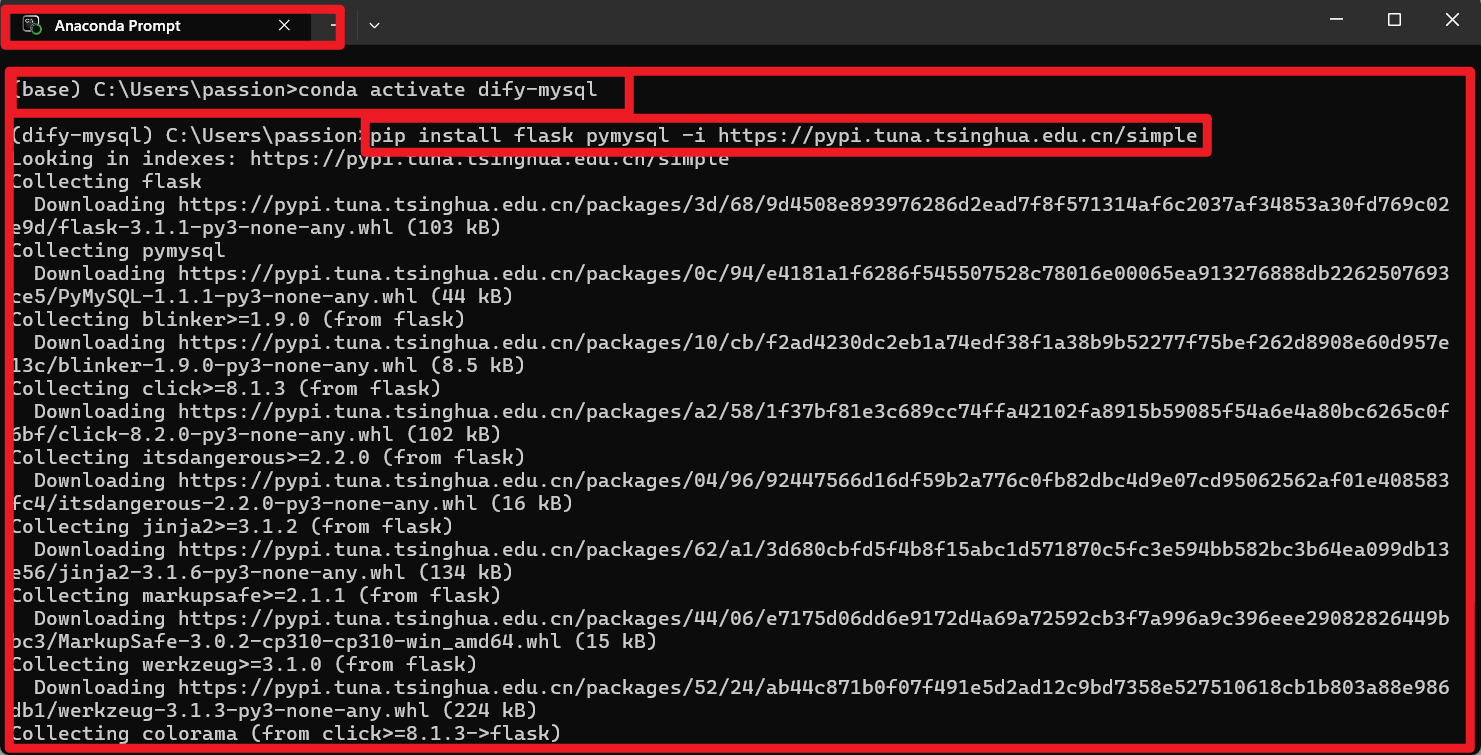
激活虚拟环境
在Anaconda Prompt中执行(搜索框搜索)conda activate dify-mysql -
安装依赖包
推荐使用清华镜像源加速安装:pip install flask pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
3.5编写后台程序
from flask import Flask, request, jsonify
import pymysql
import json
app = Flask(__name__)
DATABASE_CONFIG = {
'host': '127.0.0.1',
'user': 'root',
'password': 'helloworld',
'db': 'lab',
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor
}
@app.route('/query', methods=['POST'])
def query_database():
try:
# 强制解析JSON并验证格式
if not request.data:
return jsonify({"error": "Empty request body"}), 400
data = request.get_json(force=True, silent=True)
if data is None:
return jsonify({"error": "Invalid JSON format"}), 400
keyword = data.get('keyword')
if not keyword:
return jsonify({"error": "Keyword is required"}), 400
query = "SELECT * FROM student WHERE name LIKE %s"
params = ('%' + keyword + '%',)
connection = pymysql.connect(**DATABASE_CONFIG)
with connection.cursor() as cursor:
cursor.execute(query, params)
result = cursor.fetchall()
if not result:
return jsonify({"message": "No data found"}), 404
return jsonify({
"status": "success",
"data": result,
"markdown": generate_markdown_table(result)
}), 200
except pymysql.Error as e:
return jsonify({"error": f"Database error: {str(e)}"}), 500
except Exception as e:
return jsonify({"error": f"Server error: {str(e)}"}), 500
finally:
if 'connection' in locals():
connection.close()
def generate_markdown_table(results):
if not results:
return ""
columns = results[0].keys()
table_md = "|" + "|".join(columns) + "|\n"
table_md += "|" + "---|" * len(columns) + "\n"
for row in results:
table_md += "|" + "|".join(str(cell) for cell in row.values()) + "|\n"
return table_md
if __name__ == '__main__':
app.run(host='127.0.0.1', port=5297, debug=True)
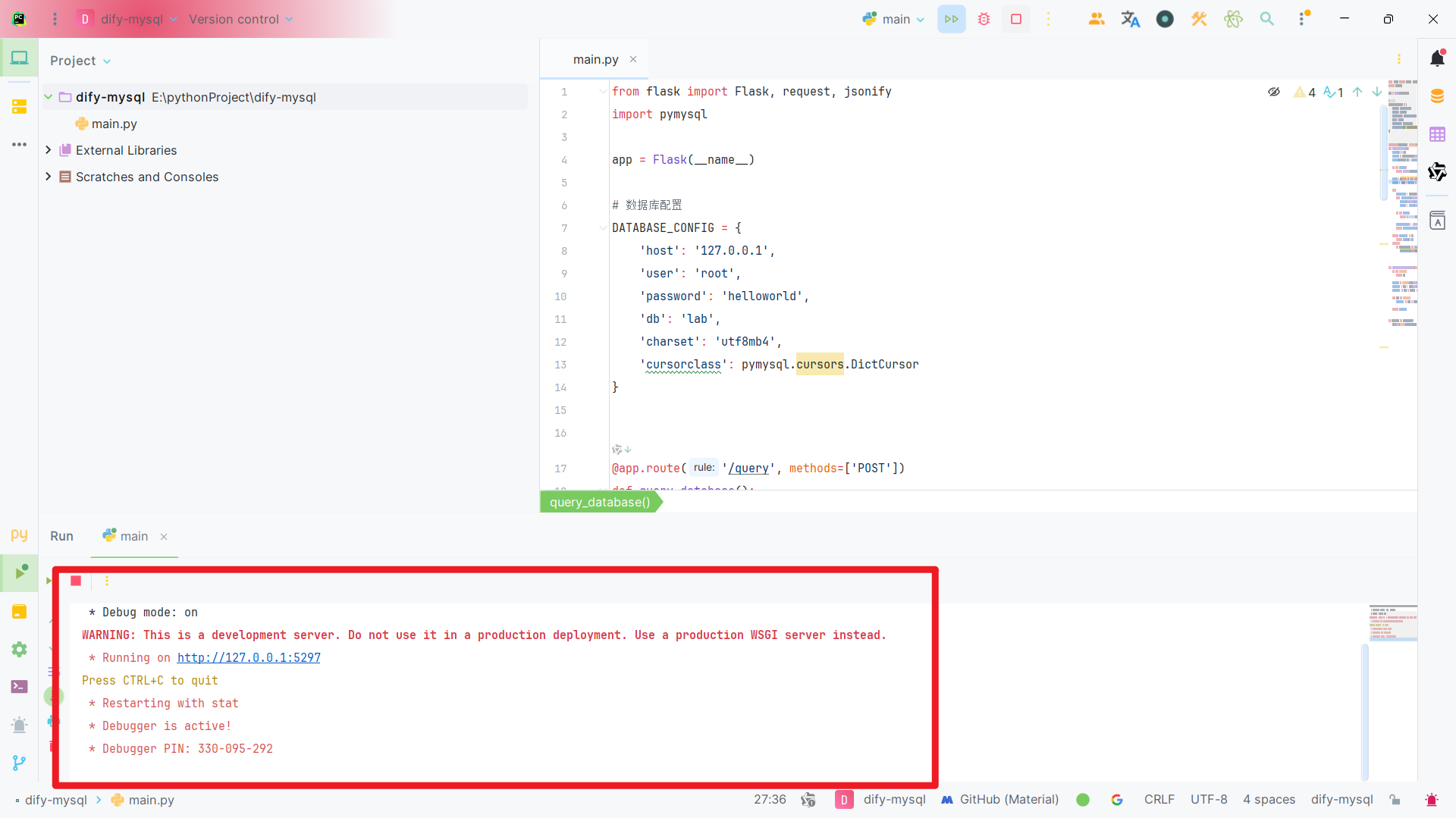
3.6运行程序
运行上述代码:
3.7测试程序
运行程序后再中端界面输入:
curl -X POST http://127.0.0.1:5297/query -H "Content-Type:application/json" -d '{"keyword":"Bob"}'
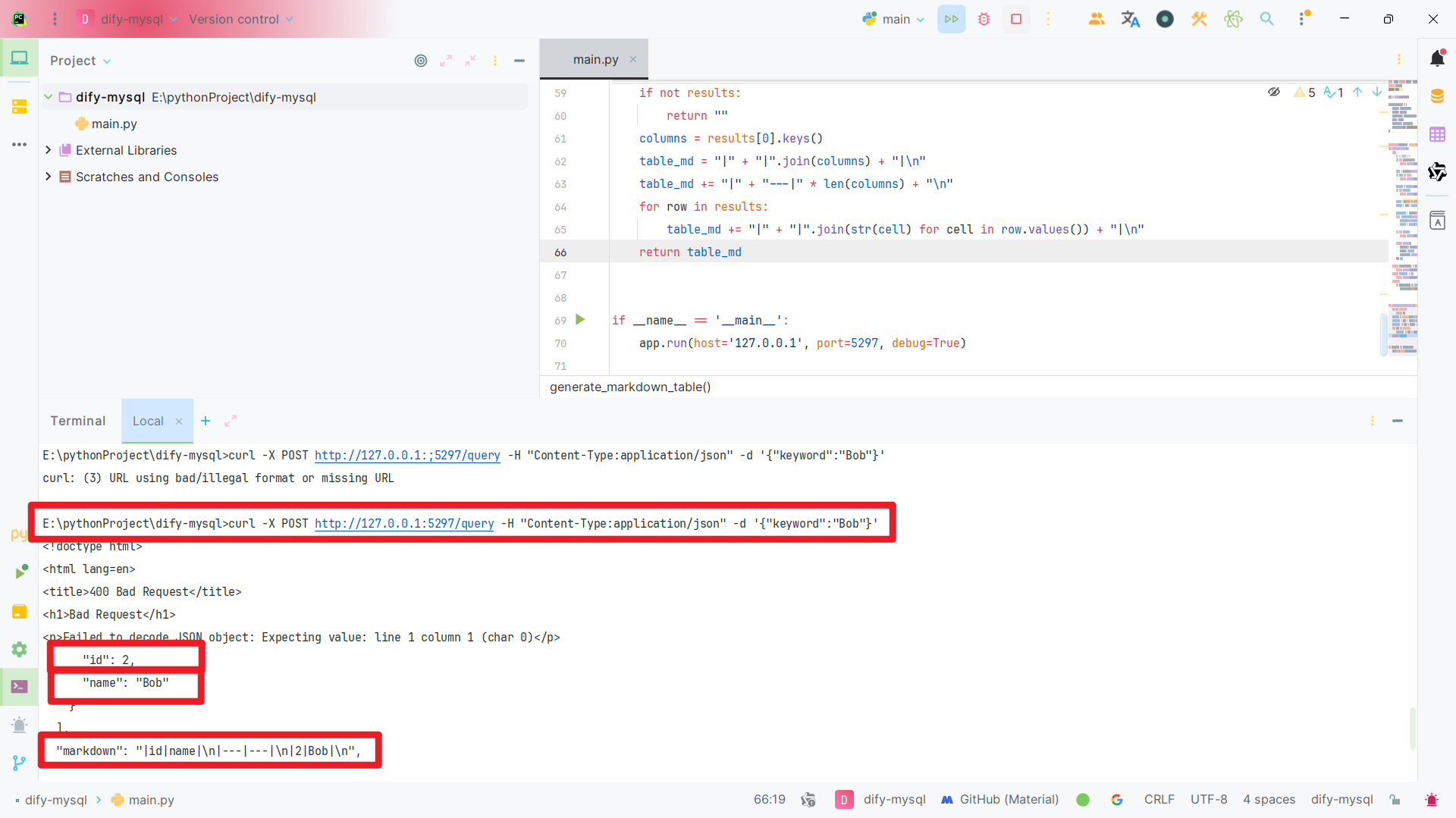
返回结果说明程序可以执行。
4.创建工作流
数据库、后台程序都准备完毕后,下一步我们配置Dify。
在工作室,点击“创建空白应用”,在弹出菜单选择“工作流”。
起一个名字然后点击创建。
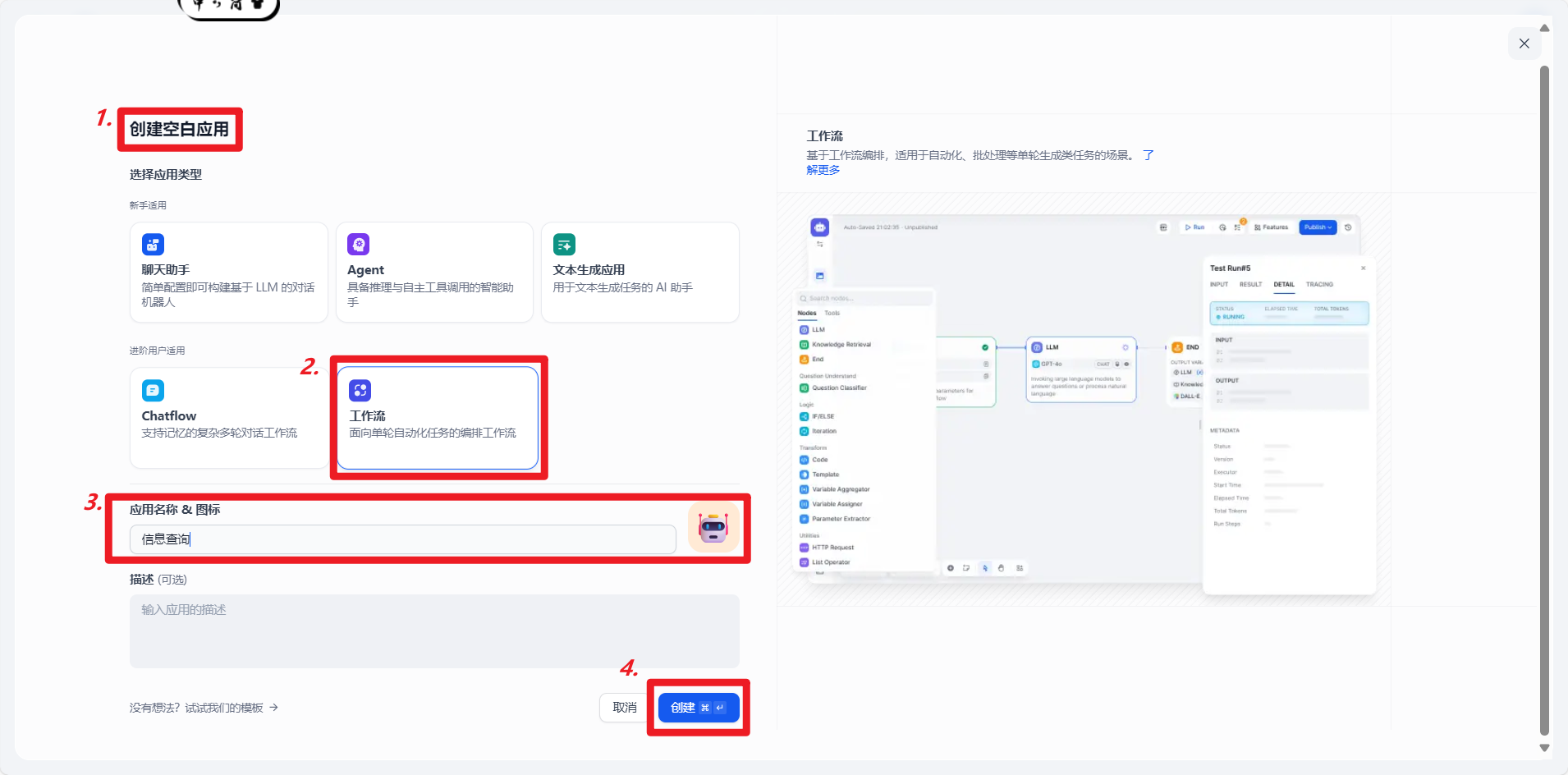
4.1创建开始结点
添加字段
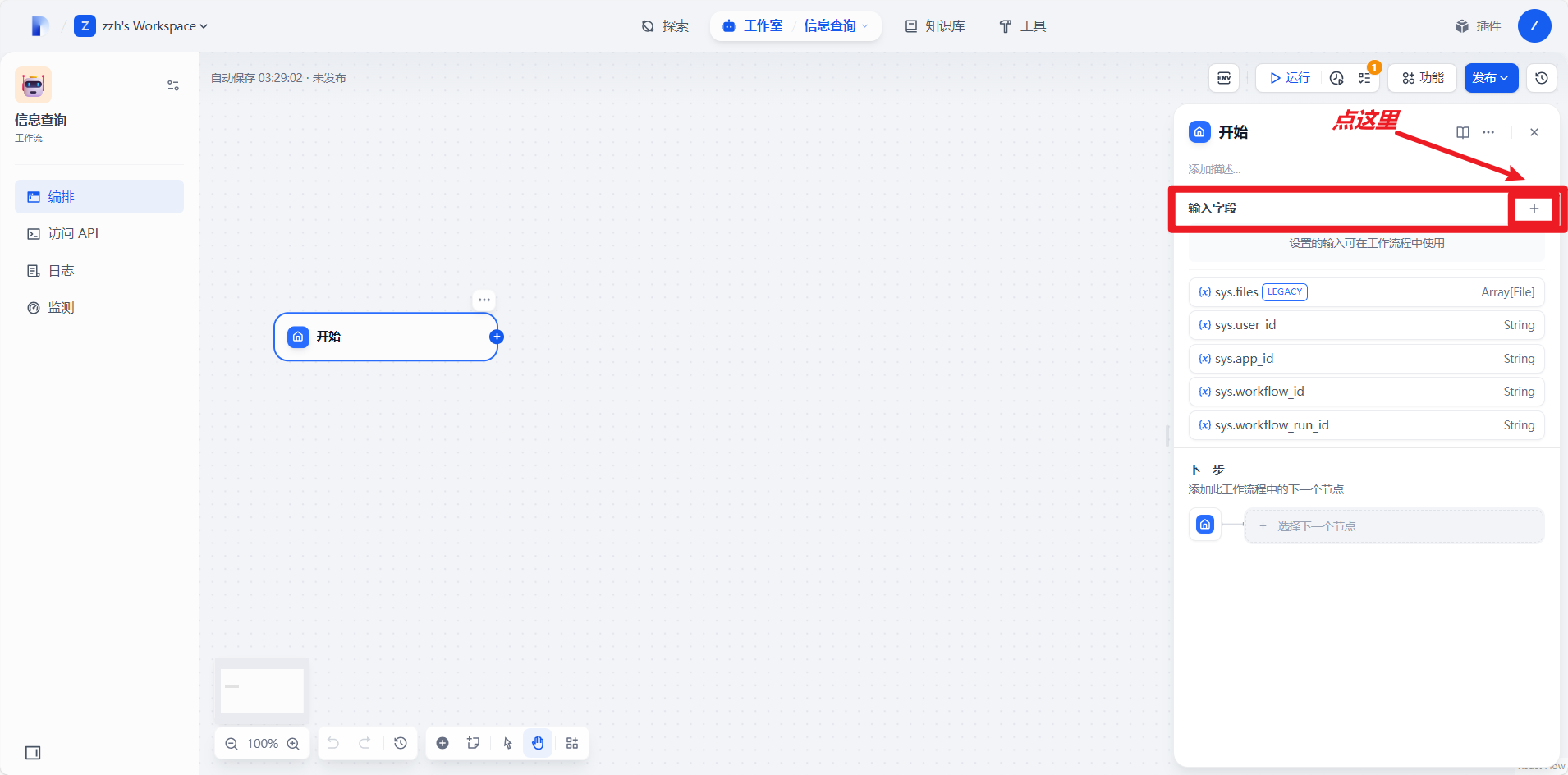
进行如下配置:
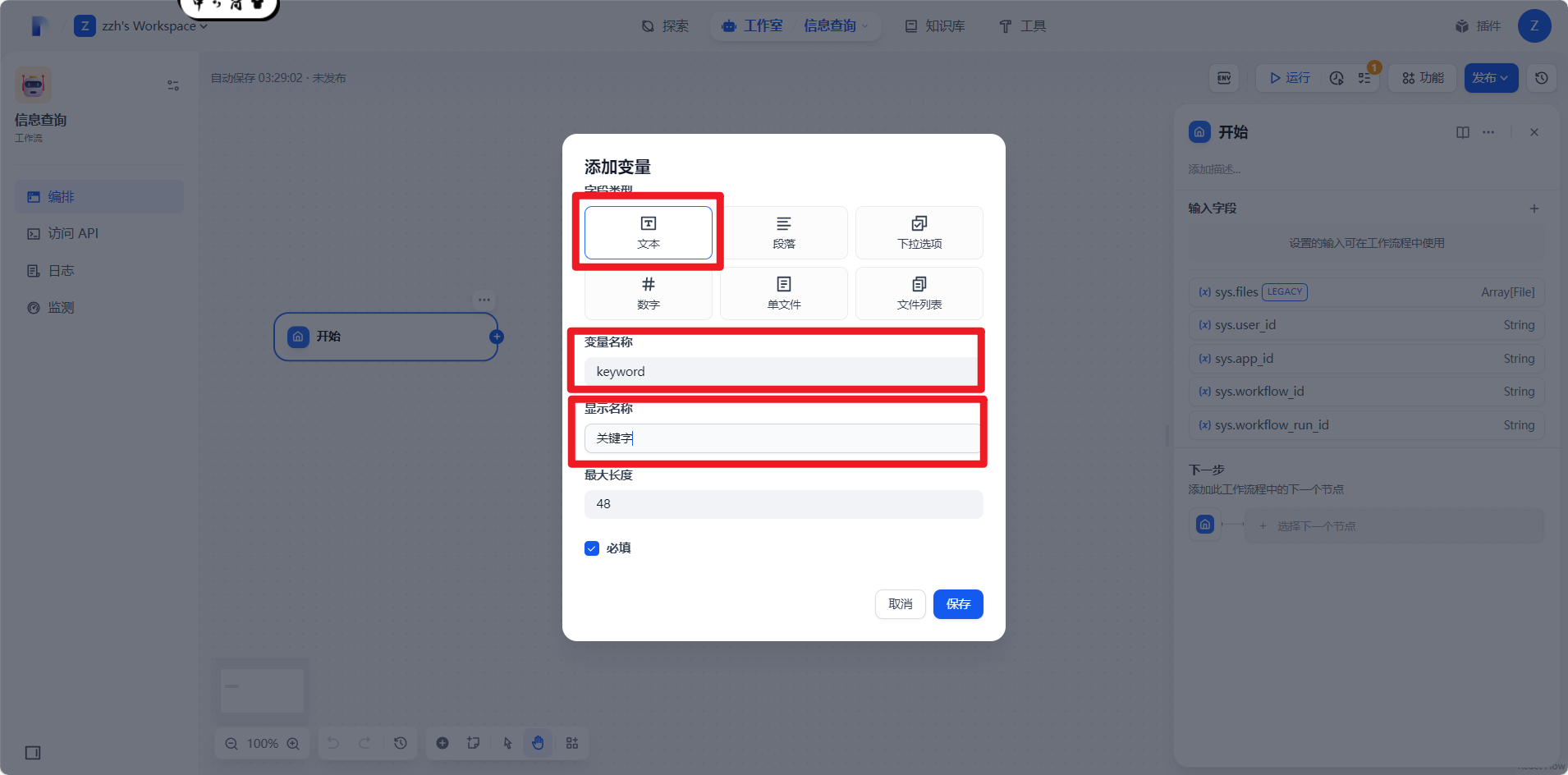 关键字的作用是将要传给后台的数据。
关键字的作用是将要传给后台的数据。
4.2创建代码执行结点
4.2.1添加代码执行结点
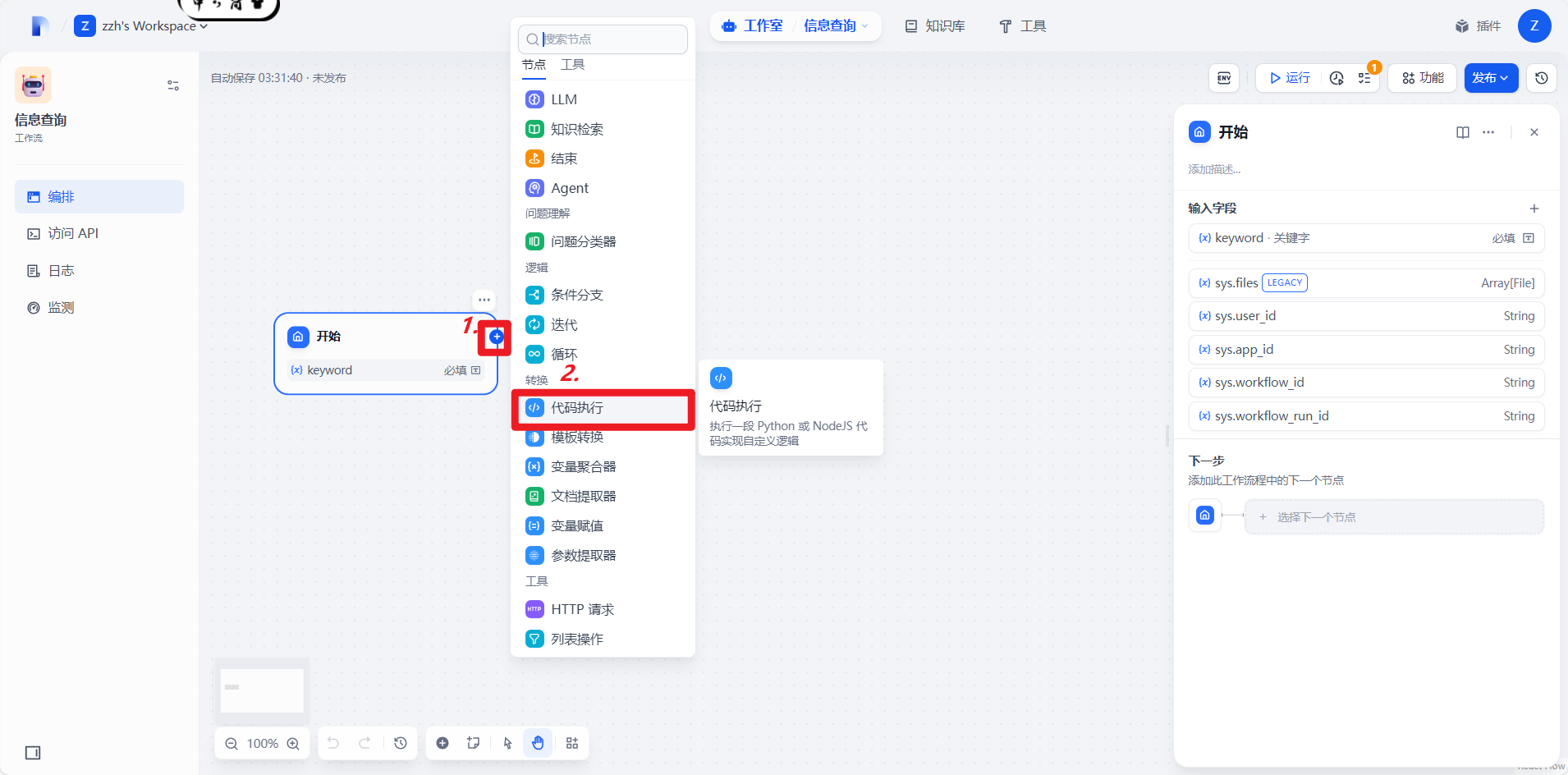
4.2.2添加输入变量
删除原有变量添加新的自己的变量:
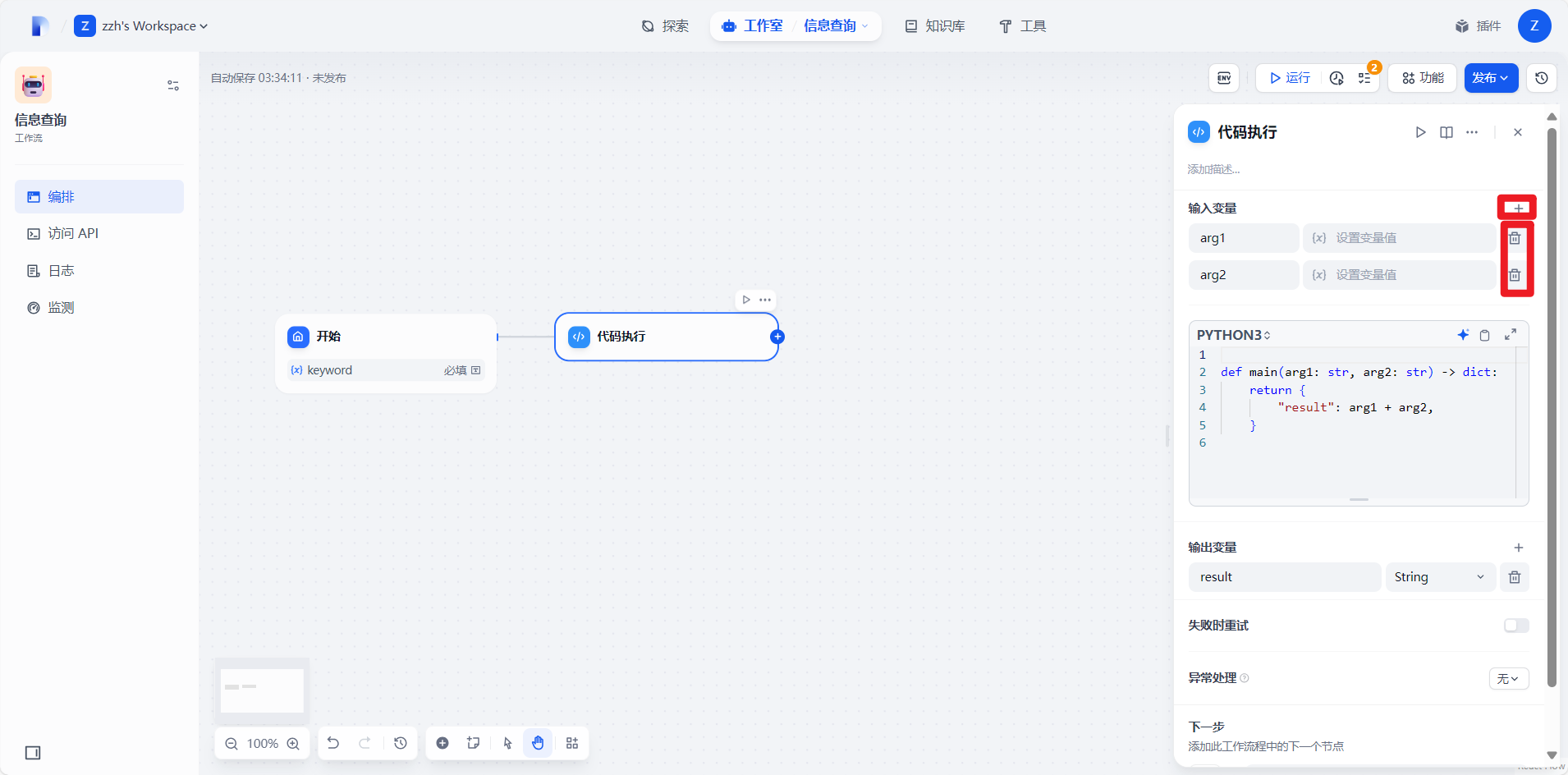
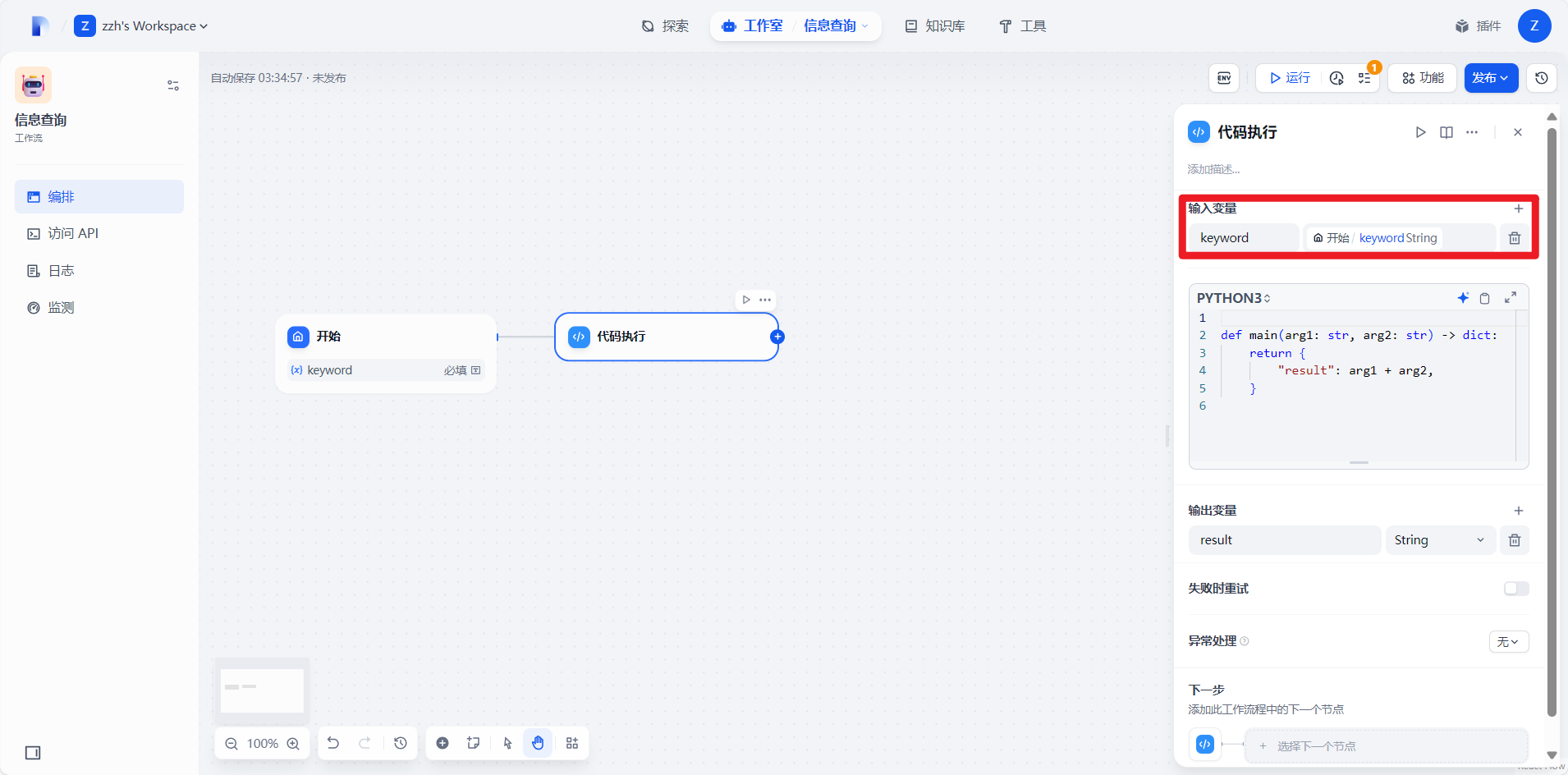
4.2.3编写python代码
这段代码的作用是去关联我们前面编写的后台程序。
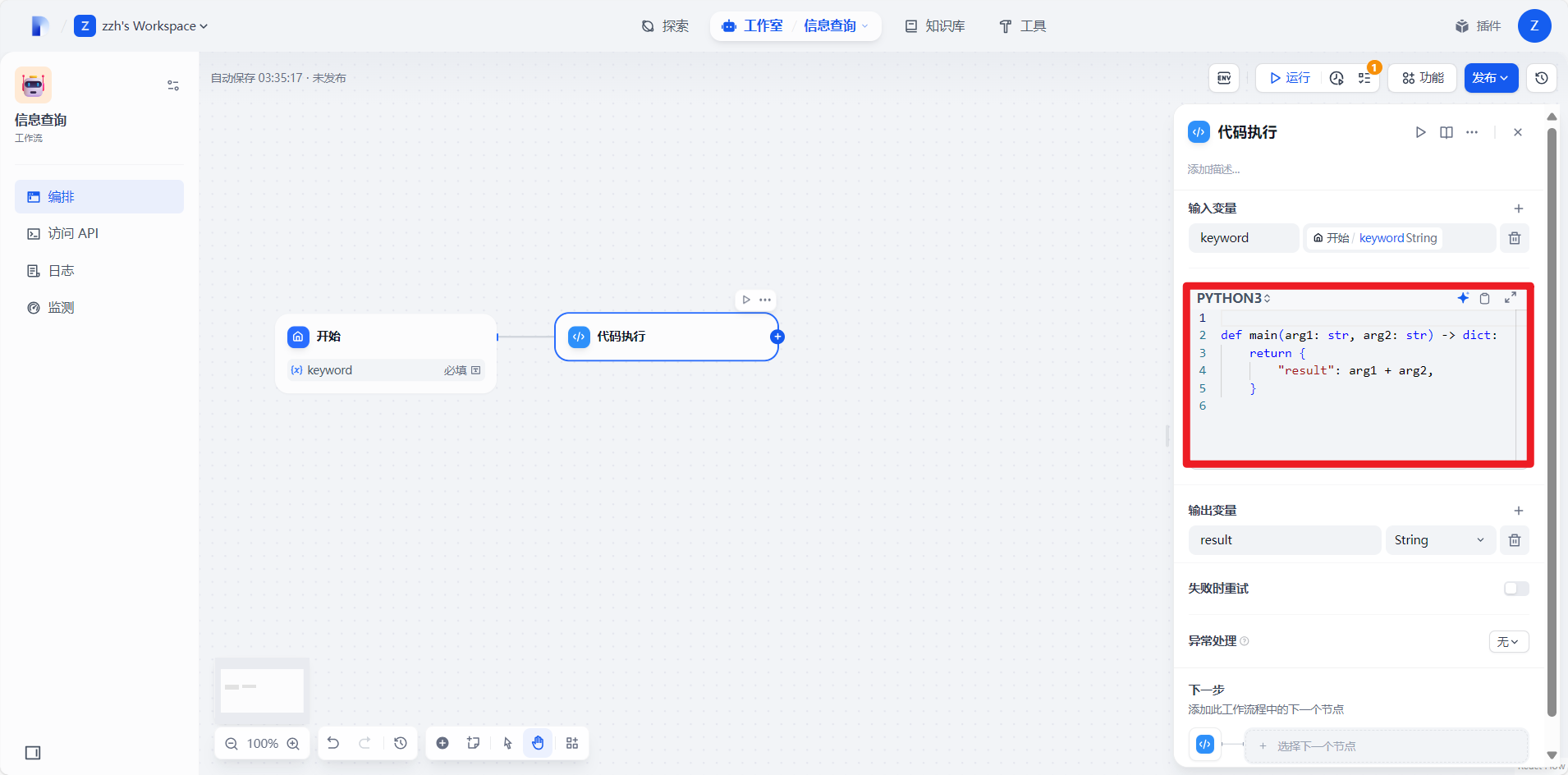
代码如下:
import requests
def main(keyword, server_url="http://host.docker.internal:5297/query"):
payload = {'keyword': keyword}
try:
response = requests.post(server_url, json=payload)
response.raise_for_status()
result = response.json()
# 确保data字段是字符串
if not isinstance(result.get('data', ''), str):
result['data'] = str(result['data'])
return {
'status': result.get('status', 'unknown'),
'data': result.get('data', '[]'),
'message': result.get('message', '')
}
except Exception as e:
return {
'status': 'error',
'data': '[]',
'message': str(e)
}4.2.4添加输出变量
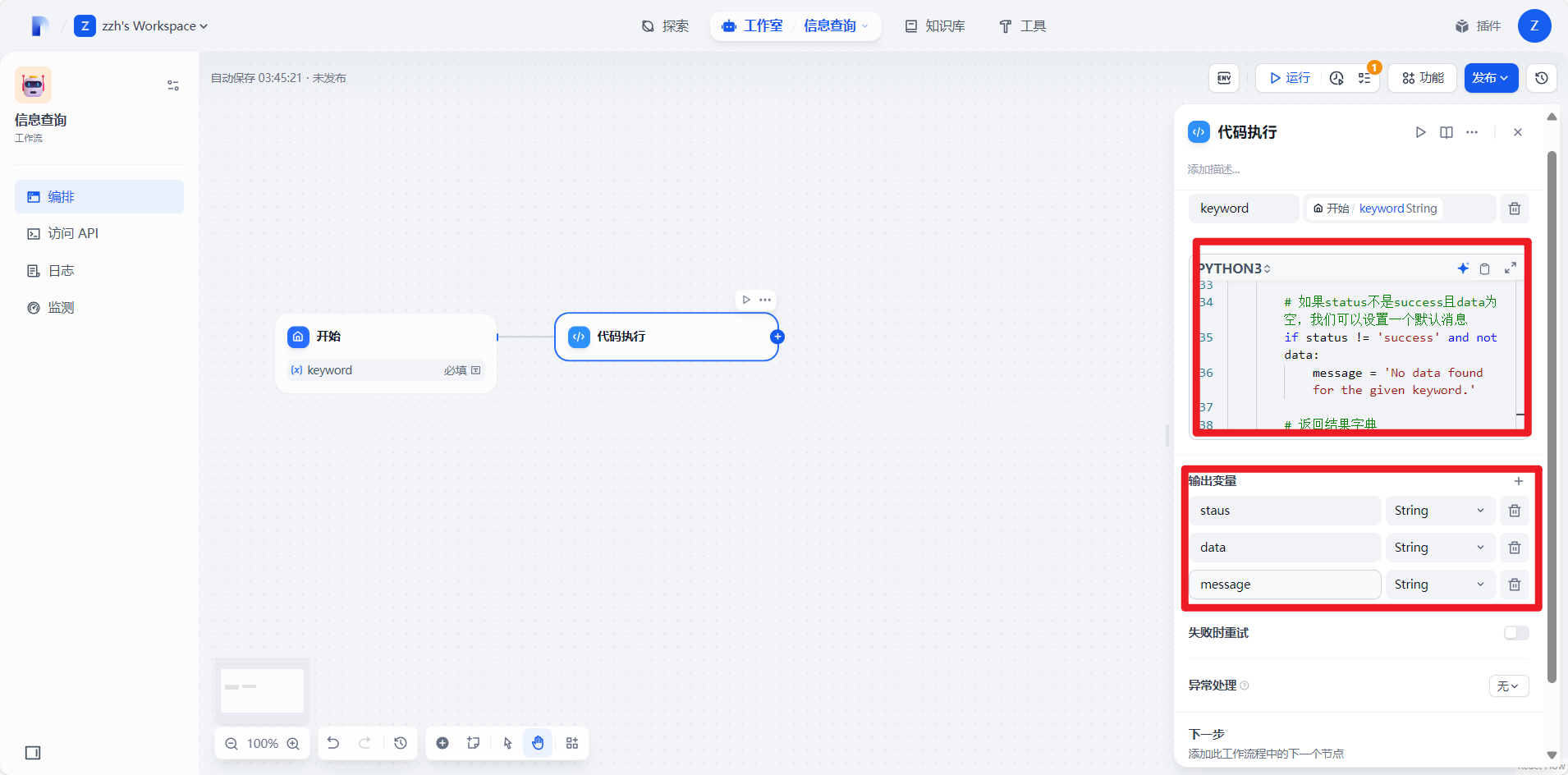
4.3结束结点
添加三个字段:
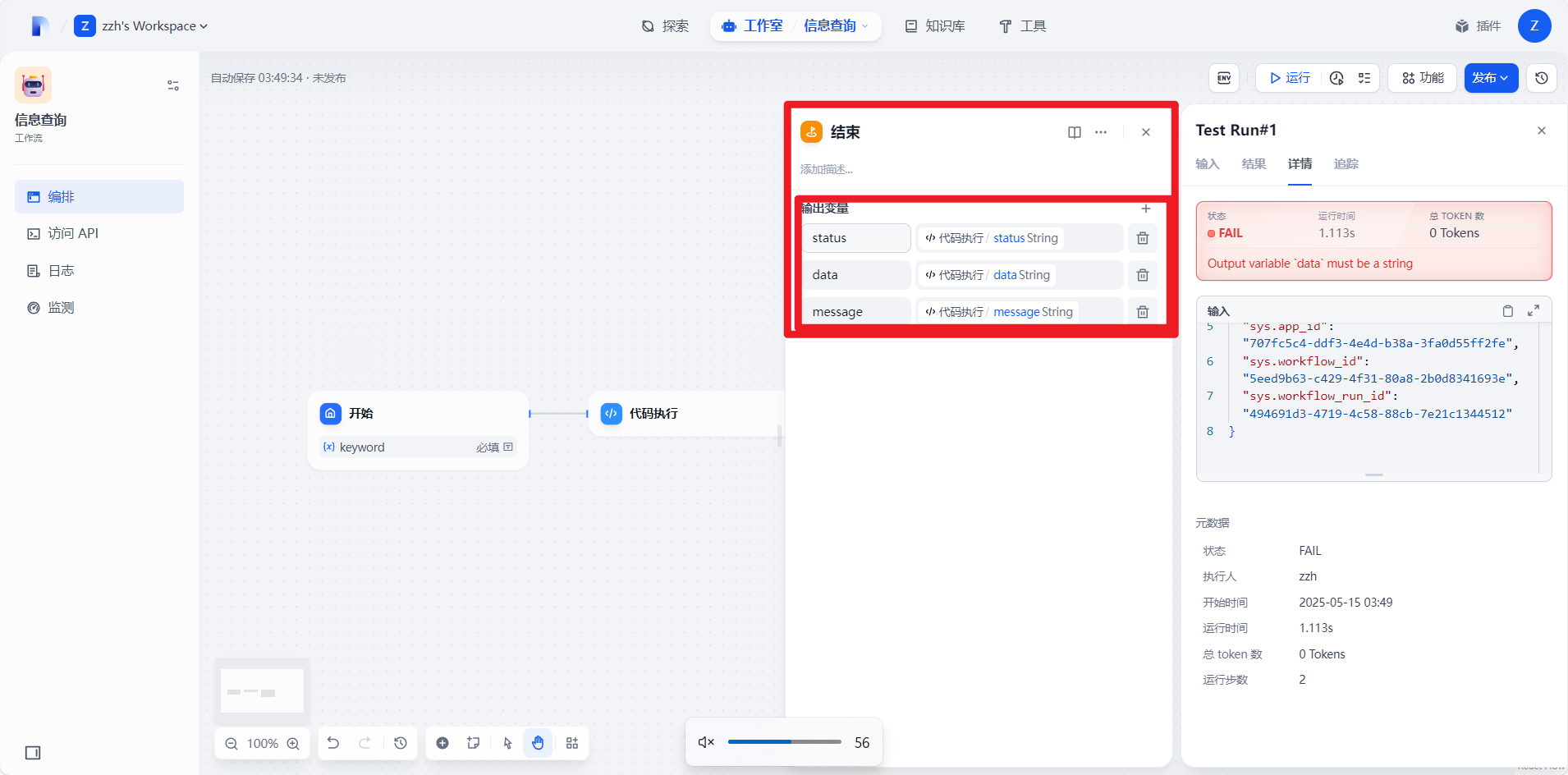
5.执行工作流
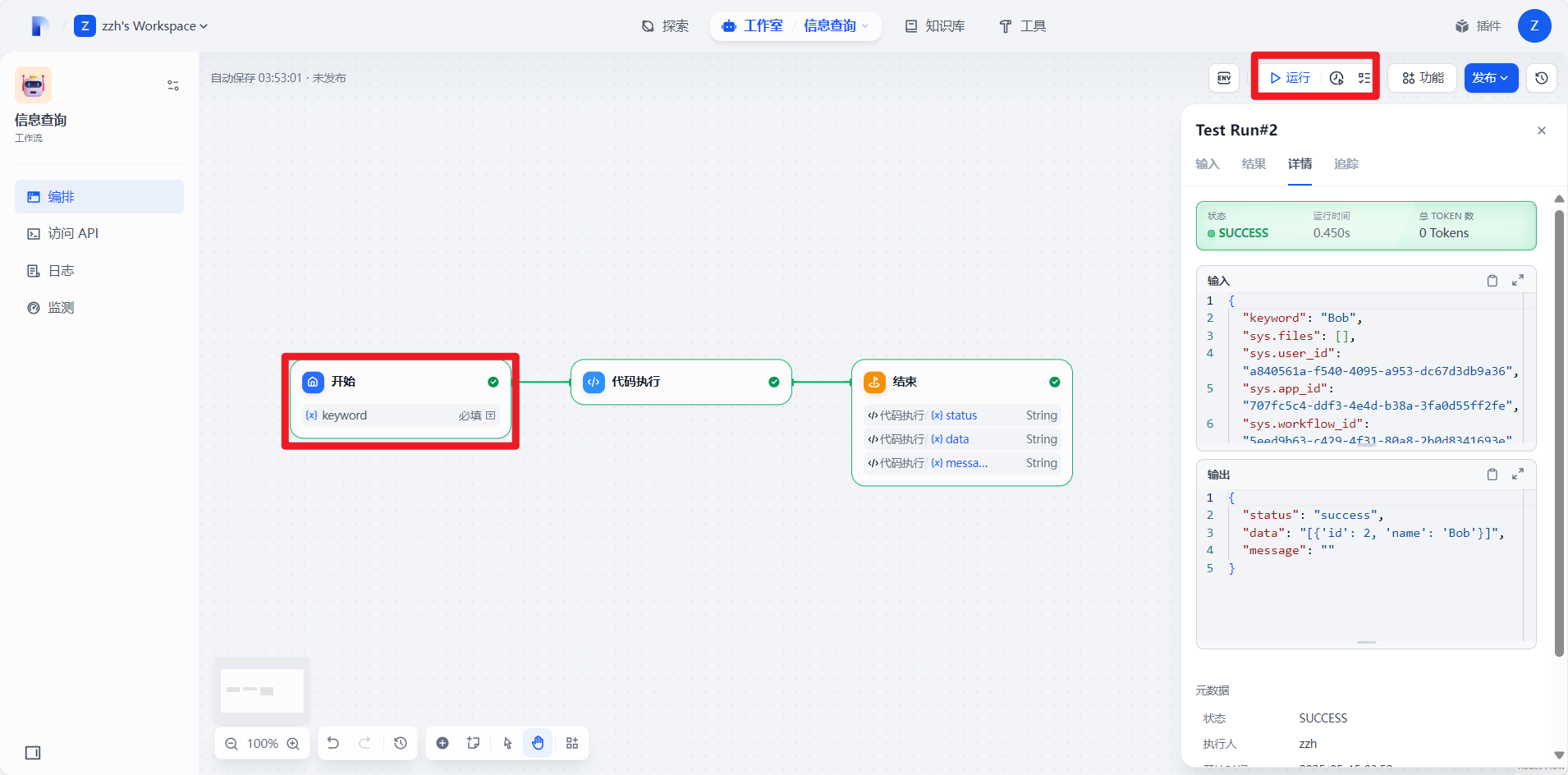
点击开始组件然后点击运行输入关键字,这里输入的是‘Bob’然后运行,显示成功并且输出了id为2,则说明程序执行成功。
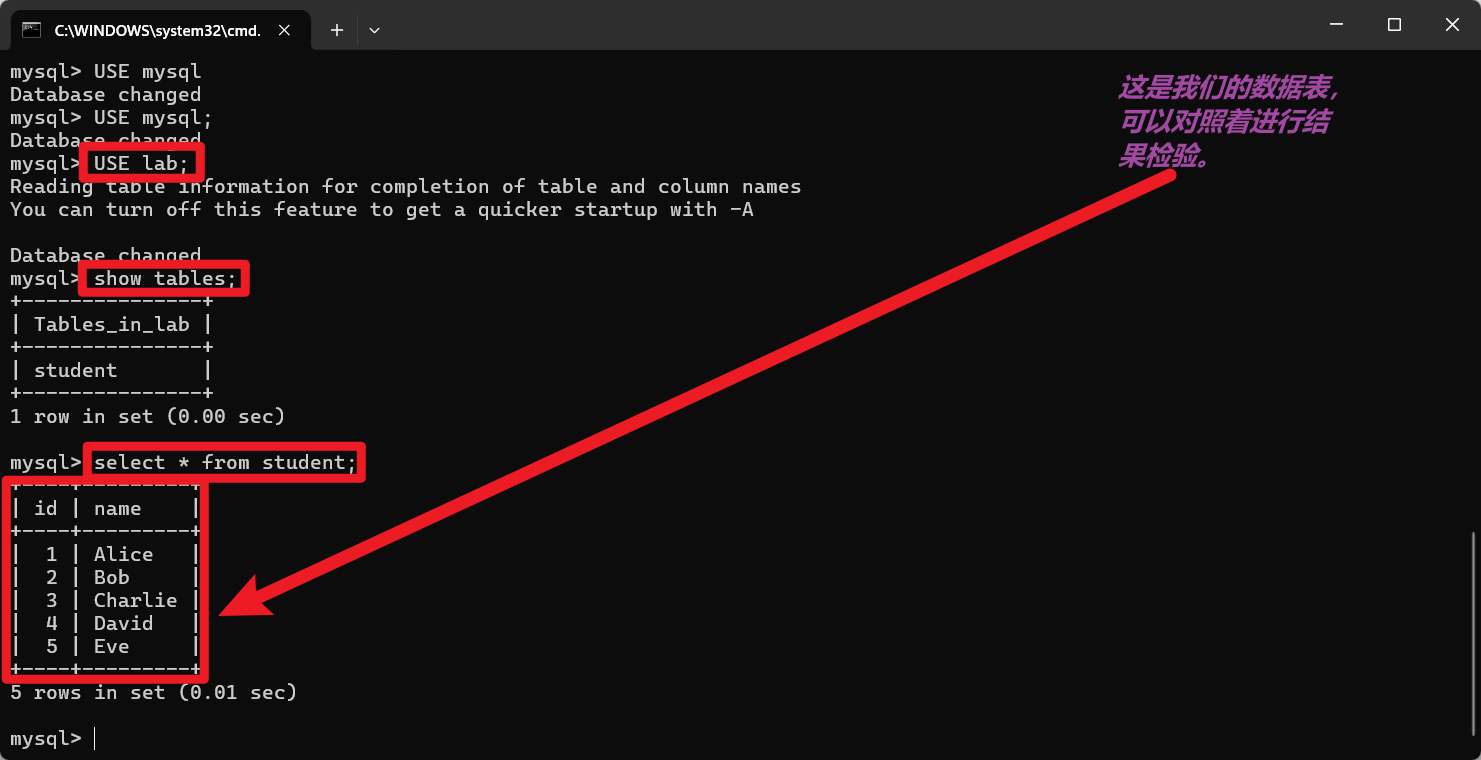
如下图我们新建的数据表里看可以得知‘Bob’对应的id是2:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)