每日阅读模块优化-引入ai/缓存/数据库
优化项状态代码位置说明DeepSeek 网络翻译✅ 已完成缓存机制✅ 已完成if (found!接入数据库的单词库✅ 已完成使用 Room,封装好的仓库层接口。
每日阅读模块优化-引入ai/缓存/数据库
本次我们继续实现我们的阅读模块:
我们可以利用我们的已经设计好的ai优势,进行优化
- 词义数据来源扩展: 可以通过我们之前设计的deepseek接口网络请求扩展词汇解释。
- 增加缓存功能: 用户如果每次使用deepseek访问节点获取翻译,效率太低,可以加入缓存机制。
- 文章单词接入数据库: 将每日文章单词查询到自己数据库查询
- 支持词汇高亮:点击词汇后进行高亮显示
高亮显示已经上次实现了。我们重点实现前三个。
优化1:词义数据来源扩展(DeepSeek 网络接口)
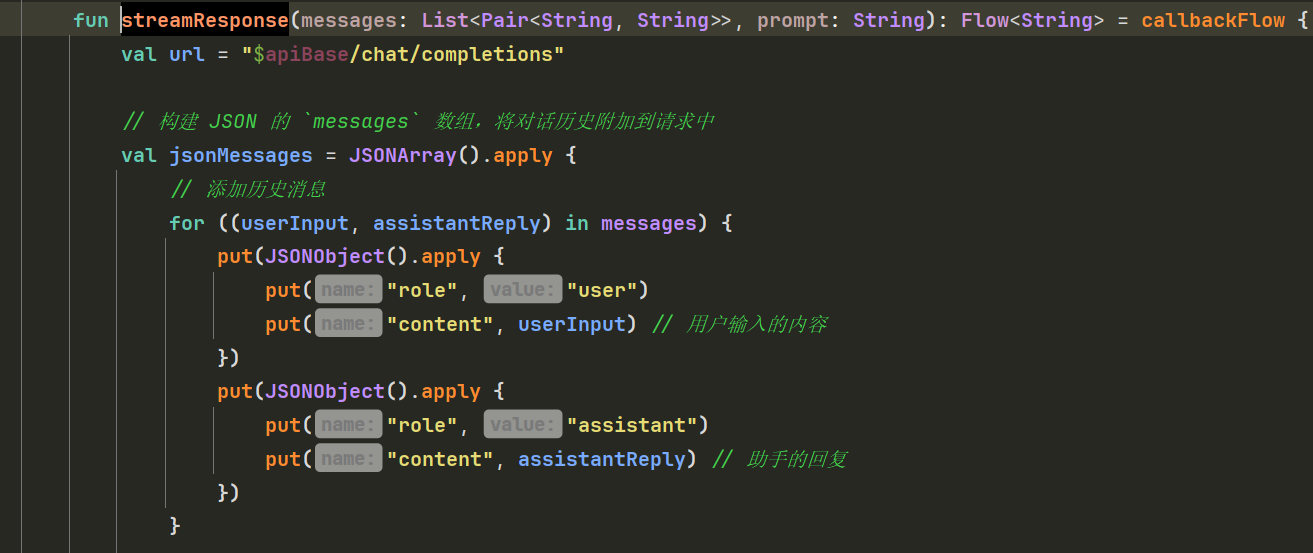
我们之前已经抽象出deepseek的接口的api:DeepSeekService的streamResponse
说明:
目前已通过 DeepSeekService.streamResponse 实现网络请求词义解释,这提升了词义的智能性与实时性。
实现代码:
那么我们可以在我们每日文章模块的viewModel层进行调用这个
val prompt = "请翻译这个英语单词为中文:$word 要求:不要说其他的,就说他的中文翻译就行"
deepSeekService.streamResponse(emptyList(), prompt).collect { chunk ->
responseBuilder.append(chunk)
}
优点:
- 使用大语言模型生成词义,解释更智能;
- prompt 设计控制输出风格,避免废话。
当然,我们可以再次优化,并不是所有都依赖这个ai翻译,毕竟ai翻译是个网络请求和响应的步骤。
我们可以:
点击单词时,先尝试本地缓存查找,若未命中才异步请求翻译,提升响应速度。
isTranslating 状态用于控制 UI 是否显示加载动画或等待提示,这样就提供了一个简单的锁,防止资源占用时候的抢占。
fun onWordClicked(word: String) {
val found = allWords.find { it.word.equals(word, ignoreCase = true) }
//先找本地单词库allWords
if (found != null) {
selectedWord = found
isTranslating = false //ai翻译动画
} else {
val prompt = "请翻译这个英语单词为中文:$word 要求:不要说其他的,就说他的中文翻译就行"
selectedWord = Word(word, "")
isTranslating = true
viewModelScope.launch {
val responseBuilder = StringBuilder()
deepSeekService.streamResponse(emptyList(), prompt).collect { chunk ->
responseBuilder.append(chunk)
}
//......
}
}
}


优化2:增加缓存机制(已实现)
实现代码:
val found = allWords.find { it.word.equals(word, ignoreCase = true) }
if (found != null) {
selectedWord = found
} else {
// 请求翻译并 add 到 allWords 缓存列表
val newWord = Word(word, responseBuilder.toString())
allWords.add(newWord)
selectedWord = newWord
}
效果分析:
- 如果用户多次点击同一单词,不会重复发起 DeepSeek 请求;
allWords充当词义缓存池,提高响应速度,减少网络调用。
这样我们查询的步骤就是:
1. 缓存数据结构
val allWords = mutableStateListOf<Word>(
Word("Blend", "混合或调和"),
Word("Crave", "渴望某物"),
...
)
将所有已知的词汇(包括初始化的)存储在 allWords 中,这是一个可观察的 mutableStateListOf<Word>,作为缓存使用。
2. 点击单词时的查询逻辑
fun onWordClicked(word: String) {
val found = allWords.find { it.word.equals(word, ignoreCase = true) }
...
}
首先在缓存中查找该单词是否存在(忽略大小写),如果存在就直接展示,不再调用外部翻译接口。
3. 缓存未命中时(未找到):
如果缓存中没有该单词,执行以下逻辑:
-
构建一个 prompt 请求 DeepSeek 接口。
-
使用协程调用
deepSeekService.streamResponse(...)获取翻译。 -
将结果构造成
Word对象:val newWord = Word(word, responseBuilder.toString()) -
更新
selectedWord并且加入缓存:allWords.add(newWord)
| 优点 | 描述 |
|---|---|
| 缓存策略清晰 | 查询优先查本地缓存,未命中才请求网络,节省资源、提升响应速度 |
| 状态管理自然 | 使用 Jetpack Compose 的状态管理(mutableStateListOf、mutableStateOf)与 UI 联动顺畅 |
| 自动扩展缓存 | 新翻译的单词直接加入缓存,无需额外逻辑维护 |
| 异步翻译流处理 | 使用协程 + streamResponse.collect 实现响应式加载,适合支持流式大模型 API |
优化3:查询的单词接入数据库
我们的 WordReaderViewModel 最终代码设计已经非常nice了!但是我们不能止步于这里,我们需要接入单词到数据库,那么我们就抽象出了三层缓存机制,也就是这个模块最核心的设计:

fun onWordClicked(word: String) {
// 先从缓存中找
val cached = allWords.find { it.word.equals(word, ignoreCase = true) }
if (cached != null) {
Log.d("WordReaderViewModel", "缓存中有")
selectedWord = cached
isTranslating = false
return
}
// 缓存没找到,进入异步流程查数据库或AI
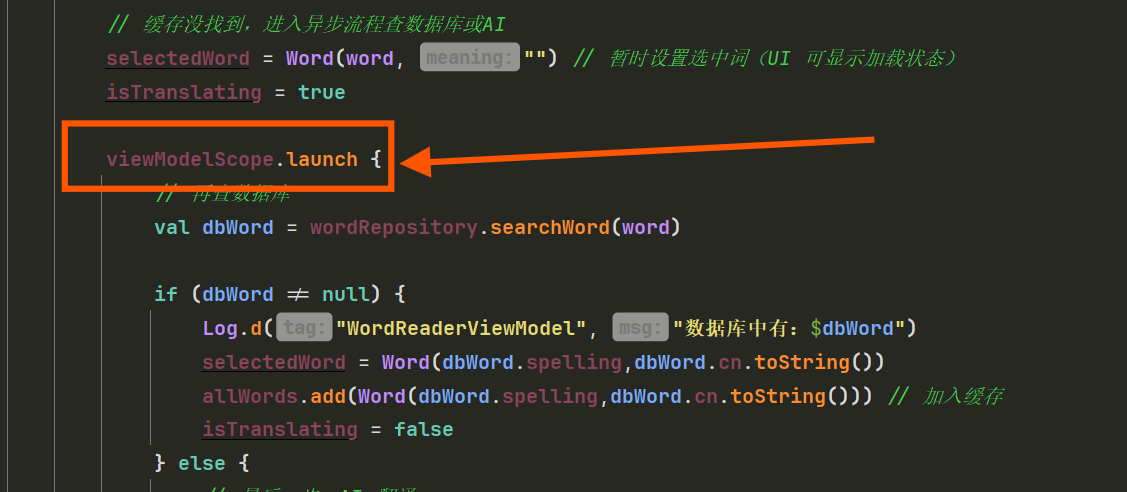
selectedWord = Word(word, "") // 暂时设置选中词(UI 可显示加载状态)
isTranslating = true
viewModelScope.launch {
// 再查数据库
val dbWord = wordRepository.searchWord(word)
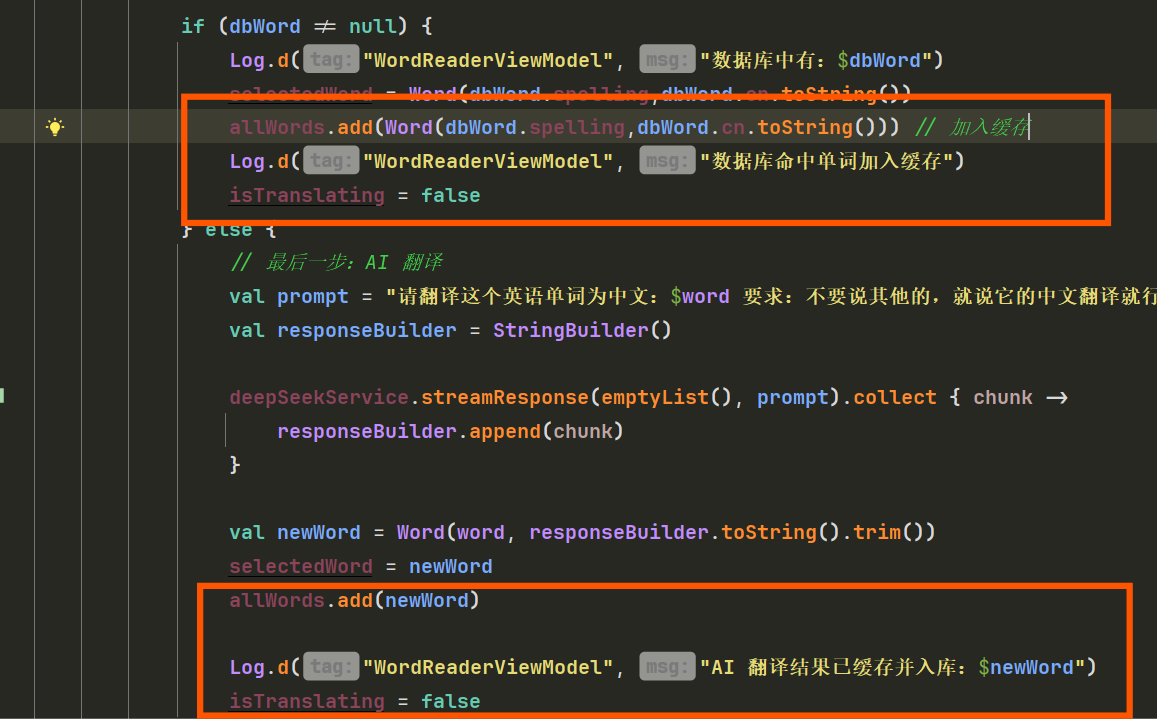
if (dbWord != null) {
Log.d("WordReaderViewModel", "数据库中有:$dbWord")
selectedWord = Word(dbWord.spelling,dbWord.cn.toString())
allWords.add(Word(dbWord.spelling,dbWord.cn.toString())) // 加入缓存
isTranslating = false
} else {
// 最后一步:AI 翻译
val prompt = "请翻译这个英语单词为中文:$word 要求:不要说其他的,就说它的中文翻译就行"
val responseBuilder = StringBuilder()
deepSeekService.streamResponse(emptyList(), prompt).collect { chunk ->
responseBuilder.append(chunk)
}
val newWord = Word(word, responseBuilder.toString().trim())
selectedWord = newWord
allWords.add(newWord)
Log.d("WordReaderViewModel", "AI 翻译结果已缓存并入库:$newWord")
isTranslating = false
}
}
}
1. 实现了三级缓存机制,效率高
依次从:
内存缓存(allWords)→ 本地数据库(wordRepository.searchWord)→ 最后才调用 AI 翻译(DeepSeekService)
这种设计大大减少了重复网络请求,提高响应速度,是现代移动应用中非常推荐的 性能优化模式。

2. 异步非阻塞操作,保证 UI 流畅
用 viewModelScope.launch 启动了协程,在进行数据库查询或 AI 网络请求时不会阻塞主线程,用户界面保持流畅。
3. 内存缓存持续更新,避免重复操作
每当新数据出现(无论来源于数据库还是 AI),都将其加入了 allWords,保持缓存始终是“热”的,有效避免未来重复查询。
4. 构建逻辑符合“数据即状态”的响应式编程思维
selectedWord 一旦变化,Compose UI 就能自动响应;
isTranslating 可以配合进度或文字提示,改善用户体验。
总结对照表(功能 → 代码)
| 优化项 | 状态 | 代码位置说明 |
|---|---|---|
| DeepSeek 网络翻译 | ✅ 已完成 | streamResponse(...).collect {...} |
| 缓存机制 | ✅ 已完成 | if (found != null) { ... } |
| 接入数据库的单词库 | ✅ 已完成 | 使用 Room,封装好的仓库层接口 |
最终效果截图:


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)