【AI基础】使用Ollama部署本地LLM大模型(DeepSeek-R1:7B)
Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。Ollama 提供对模型量化的支持,可降低模型的显存要求,使得在PC或笔记本上运行大型模型成为可能,是开发者尝试本地LLM大模型服务的推荐方式之一。
·
什么是Ollama
Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。Ollama 提供对模型量化的支持,可降低模型的显存要求,使得在PC或笔记本上运行大型模型成为可能,是开发者尝试本地LLM大模型服务的推荐方式之一。
一、安装Ollama
1.1 下载Ollama
进入Ollama官网(https://ollama.com/),选择对应版本并下载
1.2 安装Ollama
1.2.1 进入Ollama安装界面
1.2.2 安装Ollama命令行工具
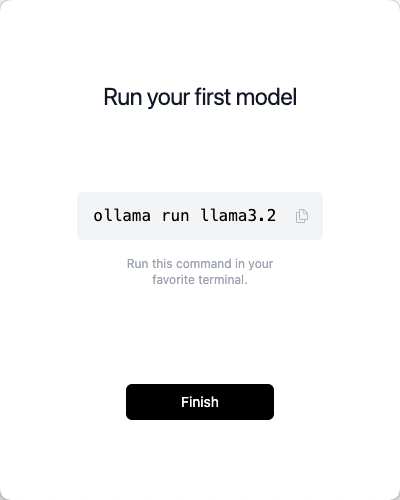
1.2.3 运行第一个model模型
1.3 检查Ollama是否运行
ollama
ollama --version
二、使用Ollama部署模型服务
2.1 运行第一个model模型服务-llama3.2
2.1.1 下载llama3.2
ollama run llama3.2
2.1.2 下载完成并运行llama3.2
ollama会从模型市场下载模型文件和配置信息,耐心等待模型下载完成

2.2.3 向llama3.2提问

三、使用Ollama部署模型服务DeepSeek-R1
3.1 运行DeepSeek-R1:1.5B
3.1.1 下载并运行DeepSeek-R1:1.5B
ollama run deepseek-r1:1.5b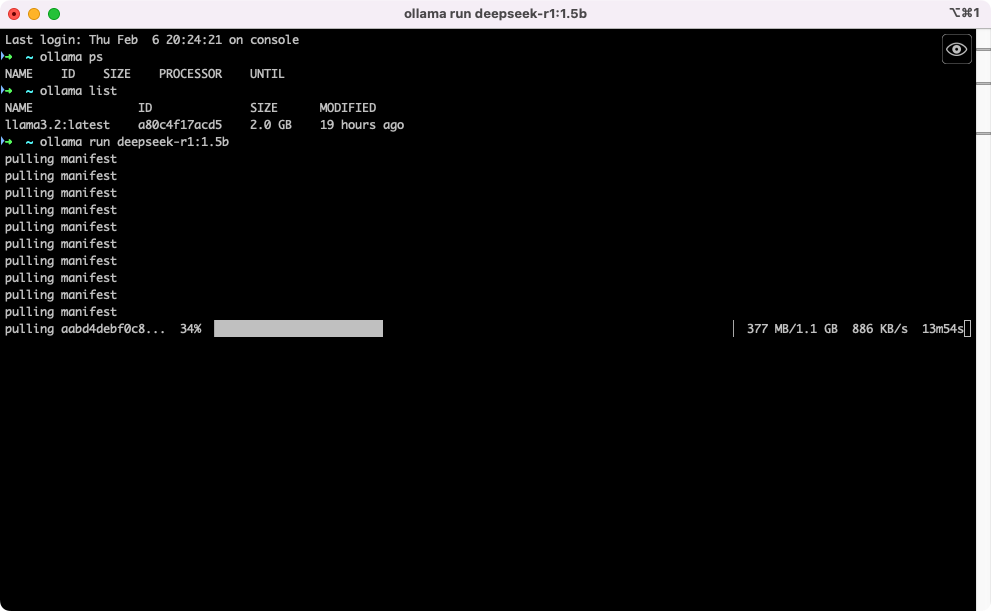
3.1.2 部署DeepSeek-R1: 1.5B

3.1.3 检查安装情况
ollama list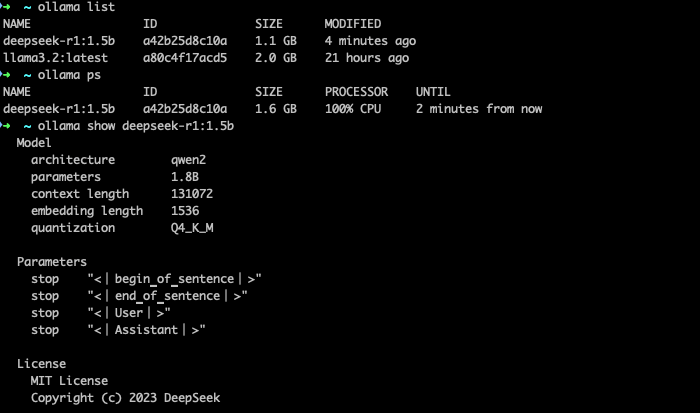
3.2.运行DeekSeek-R1:7B
3.2.1 下载DeekSeek-R1:7B
ollama run deepseek-r1:7b
3.2.2 运行DeepSeek-R1:7B

3.2.3 向DeepSeek-R1:7B提问

四、Ollama常用命令
除了 ollama run <model-name>运行模型命令,ollama还提供很多实用的命令,方便开发者管理本地模型服务,类似Docker的管理方式,很好上手。
4.1 ollama list
列举出本地已下载的模型文件
ollama list
4.2 ollama ps
查看当前ollama已加载的模型文件,展示模型大小和运行时长等
ollama ps
4.3 ollama show <model-name>
查看模型的详细信息,包括参数量,上下文长度,模型精度等信息,
ollama show <model-name>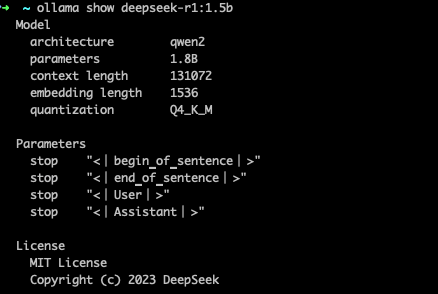
写在最后
本文简要介绍Ollama的安装及使用,以及如何一键部署本地LLM大模型服务,llama3.2和deepseek-r1蒸馏版,快来试试看,搭建你的本地模型运行工具
接下来,将继续更新AI+LLM大模型相关内容,敬请期待,respect!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)