DeepSeek-R1-0528 推理模型文件拆解分析
以非人工智能科班,跨界研发人员的视角拆解分析 deepseek r1 的推理模型文件的层次结构,希望能从最小的计算机实体存在的方式认识推理模型为何物?通过直观的认识再去了解大模型相关
前言
对于非科班背景的朋友来说,想要了解大模型的相关知识,往往充满挑战。各种扑面而来的数学、信息论、统计学概念以及复杂的机器学习理论,常常让人感觉云山雾罩,完全摸不着头脑。想要深入大模型的世界,却总被这些晦涩难懂的概念挡在门外,难以真正入门。
本博客,正是从一个跨界研发人员的视角出发,尝试解读大模型的推理文件。 我们将抛开繁杂的理论,聚焦于文件本身的层次结构与组成部分,带领大家换个角度重新认识这些内容。我们将以 DeepSeek-R1-0528 685B 版本的推理权重文件为例进行具体说明。希望通过这种非科班的解读方式,让大家能够更直观地认识并理解大模型推理权重的构成,从而显著降低学习和实践大模型的门槛
一、推理模型配置总览
1.1 下载关键配置文件
## huggingface 地址如下
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528/tree/main
deepseek-ai/DeepSeek-R1-0528
因为全部模型文件太大。我们只需要下载配置文件即可 观测全部模型信息
#deepseek-ai/DeepSeek-R1-0528
pip install huggingface_hub
huggingface-cli download deepseek-ai/DeepSeek-R1-0528 --exclude "*.safetensors" \
--local-dir /data/models/DeepSeek-R1-0528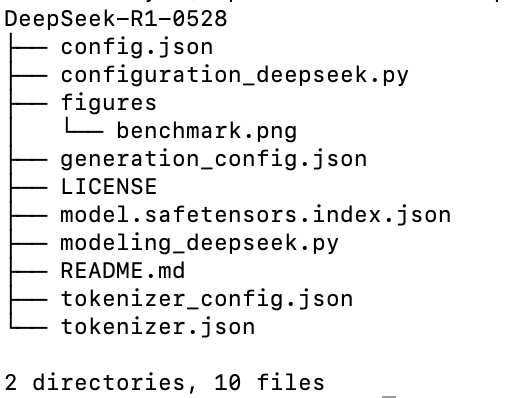
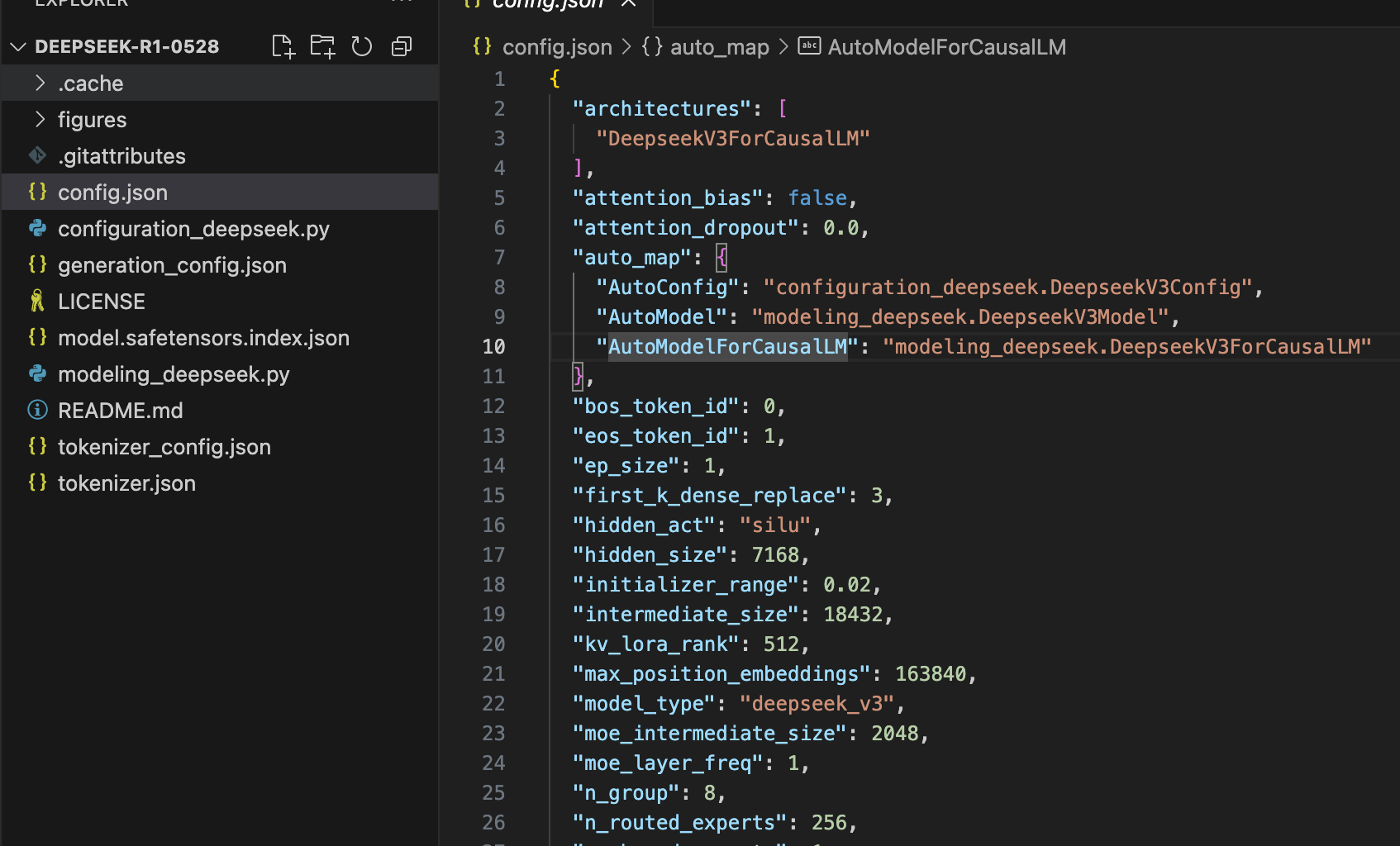
1.2 config.json 配置文件
路径 DeepSeek-R1-0528/config.json
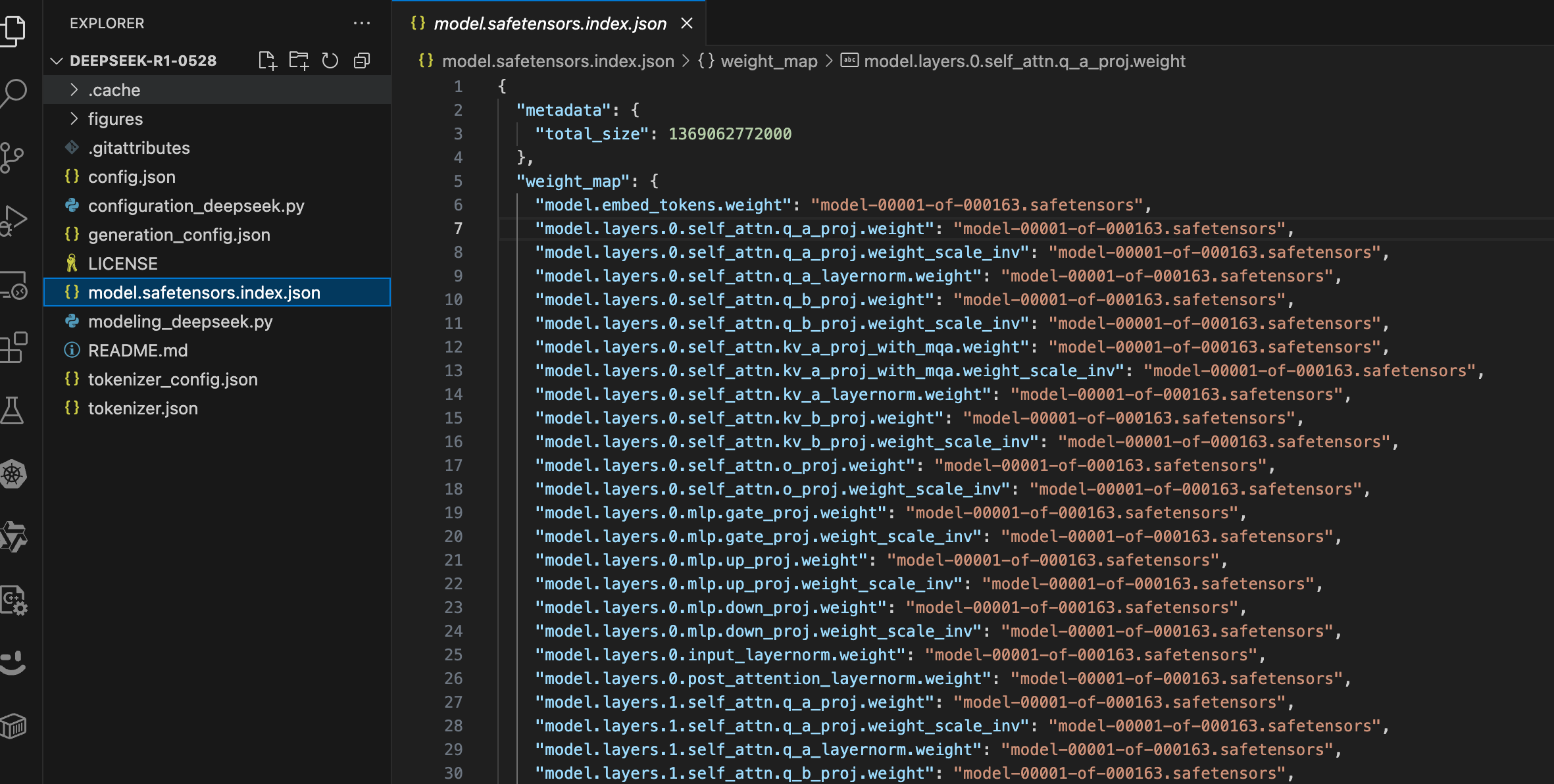
1.3 model.safetensors.index.json 配置文件
1.4 其它
二、 config.json 解读
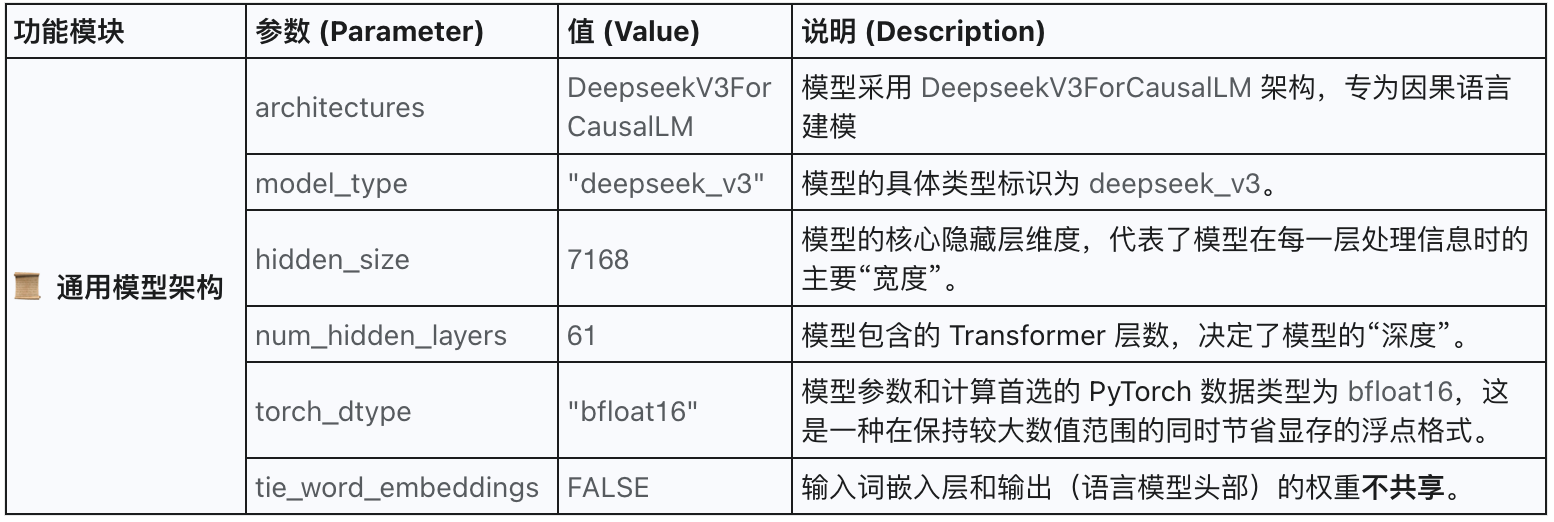
2.1 通用模型架构
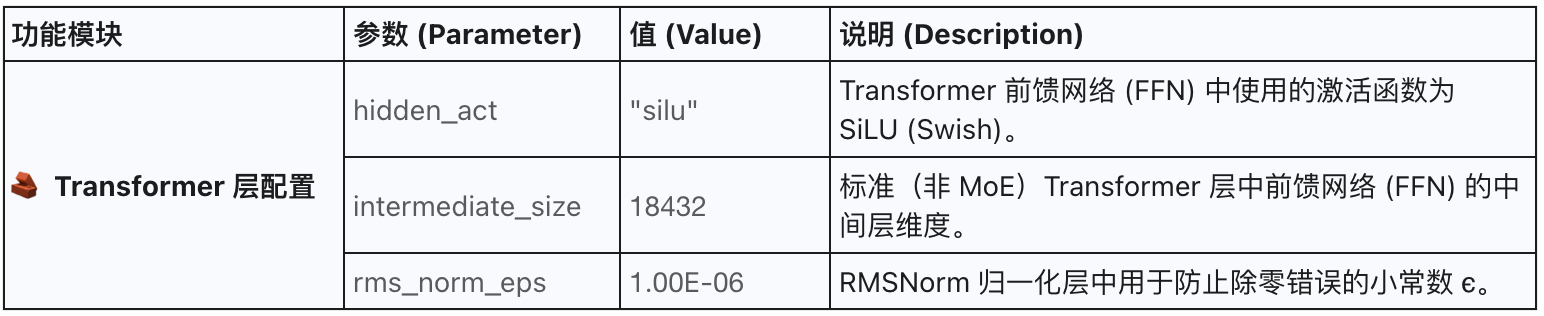
 2.2 Transformer 层配置
2.2 Transformer 层配置
2.3 MoE(Mixture-of-Experts)
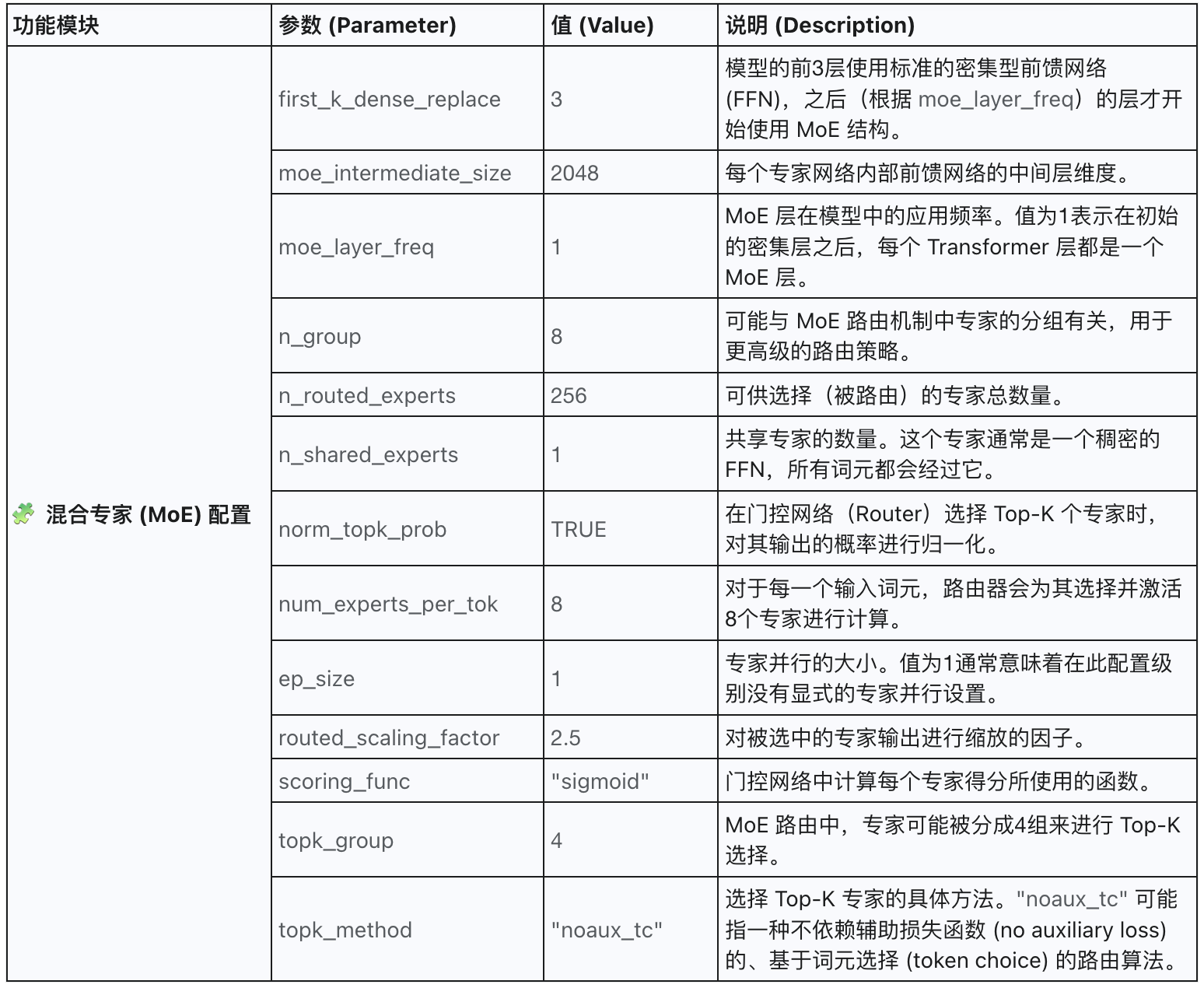
前 3 层 Dense-FFN,后 58 层 MoE-FFN
显存占用:推理时一个 token 只激活 8/256 ≈ 3 % 的专家权重;如果按“1 GPU≈32 专家”切片,≈14 × 缩减。
扩容策略:新增节点时只搬运 被分配的专家分片,不复制 95 % 未用专家;这就是官方文档中 “扩容不会把 95 % 专家再复制” 的来源。
2.4 注意力机制
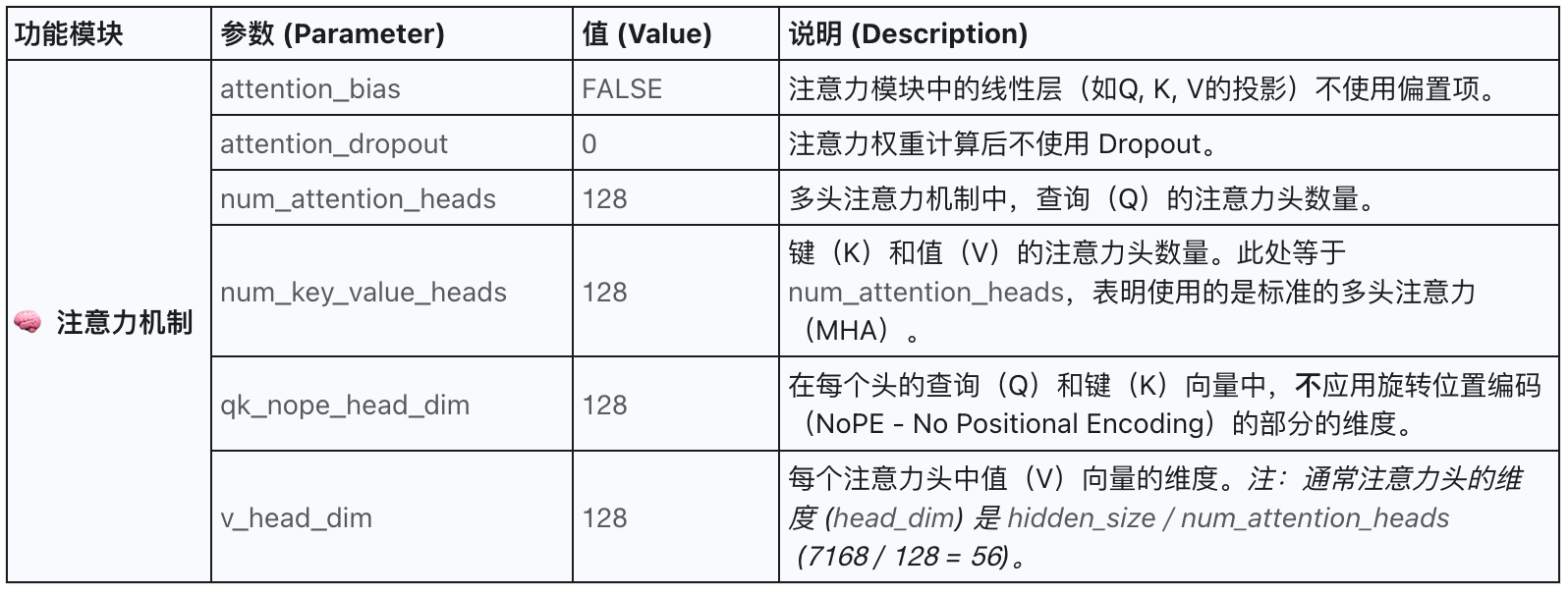
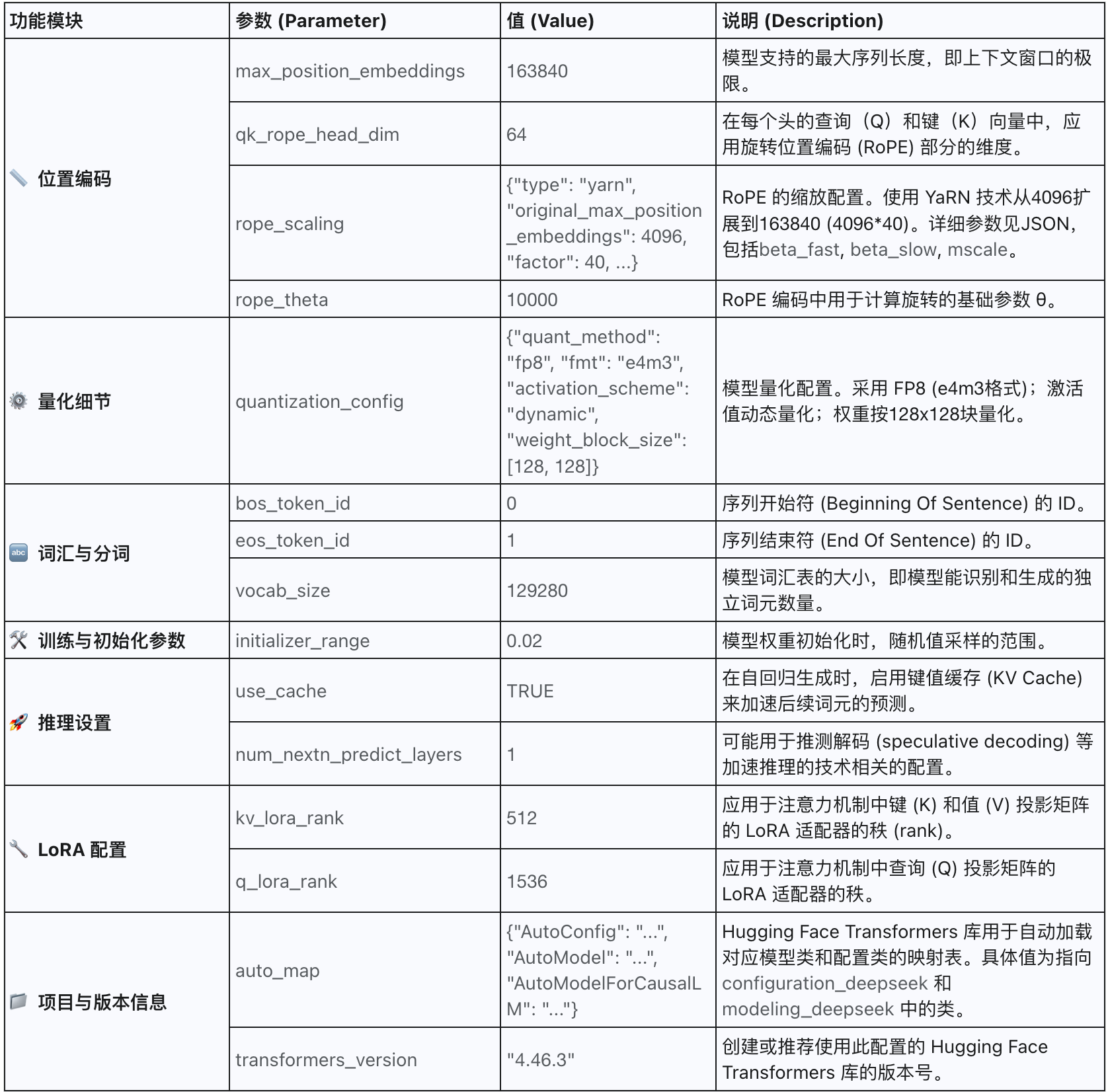
2.5 其它
三、 model.safetensors.index.json解读
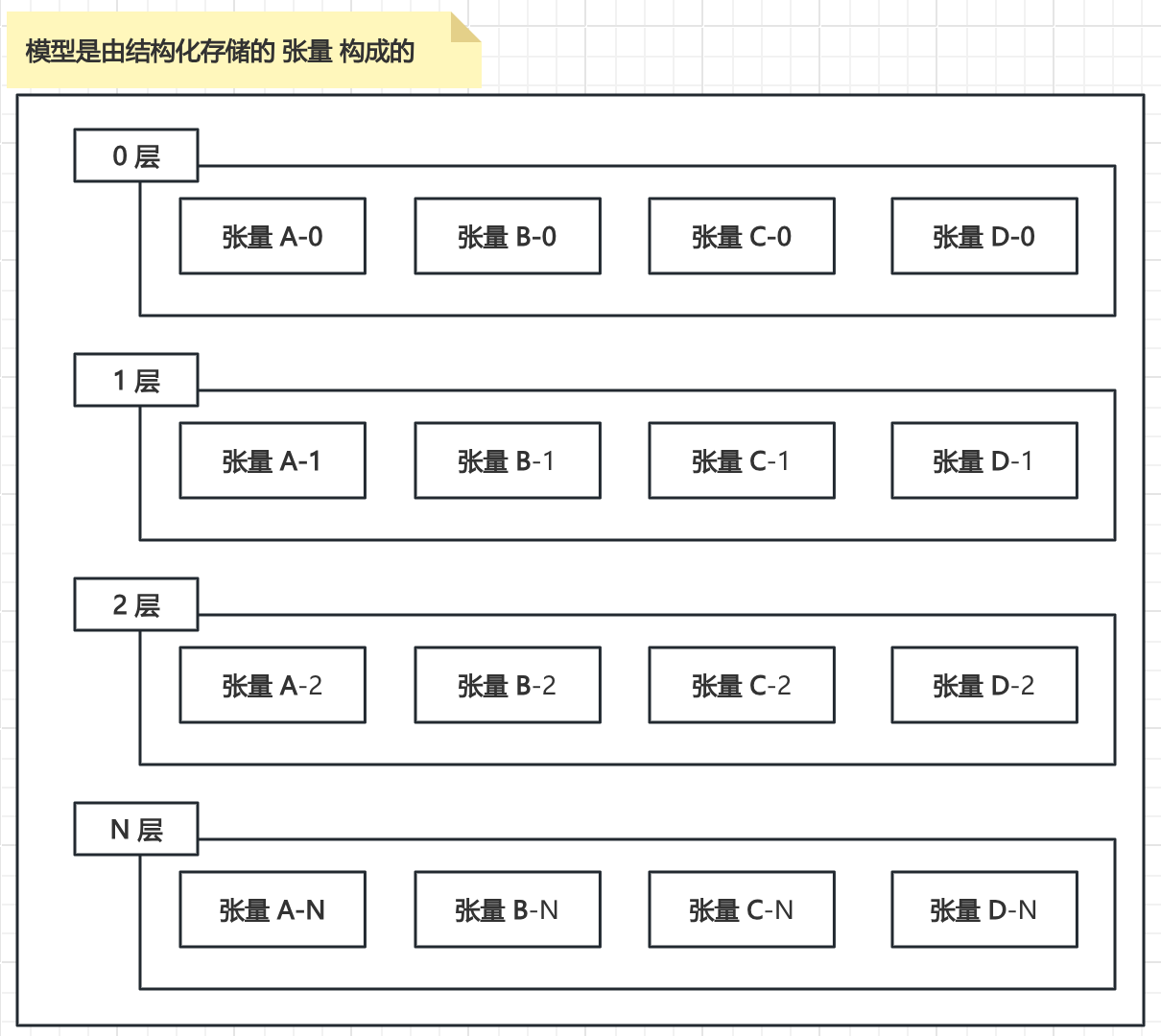
在大型语言模型(LLM)的推理模型文件中,张量(Tensor)是构成模型参数(权重和偏置)及计算状态数据的基础数据结构。它表示为一个具有固定维度(秩)和形状(各维度大小)的多维数值数组。作为模型文件在逻辑组织与物理存储层面的最小可操作单元,张量封装了模型特定组成部分(如某一神经网络层)的核心参数或中间计算结果。整个推理模型文件本质上就是一系列具有特定结构和关联关系的张量的集合及其元数据的持久化存储。
大语言模型的推理结构,本质上是层级化的张量组织:
-
张量 (Tensor) 是构成模型的最小逻辑单元,承载着模型的所有参数(权重和偏置)。
-
特定功能的层 (Layer) (如注意力层、全连接层) 由一组相关的张量构成,定义了模型局部的计算逻辑。
-
整个推理模型则由多个结构相同但参数不同的层按特定顺序堆叠而成,形成完整的计算图。
-
我们下载的推理模型文件,本质上是将这些核心张量(包含其数值和结构元数据)进行序列化存储的结果 —— 如同将内存中的数据结构(如JSON对象)持久化保存为磁盘文件(如JSON文件)
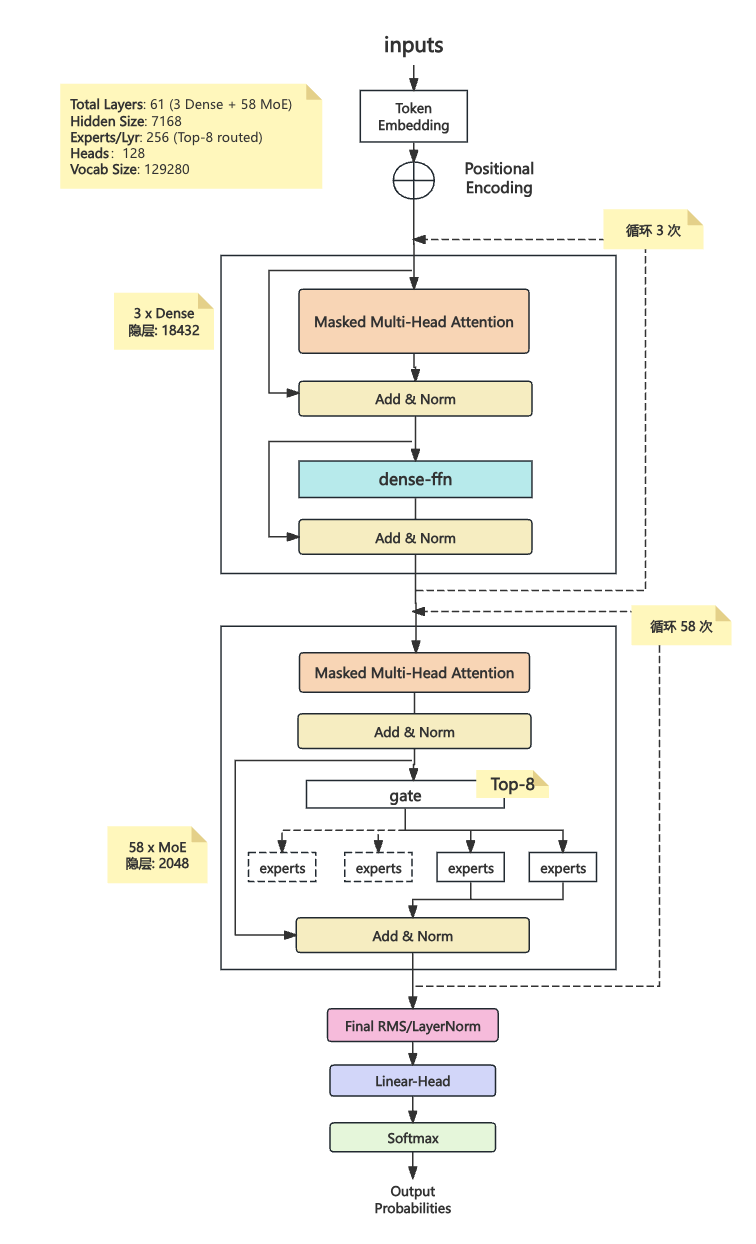
3.1 层次结构剖析
model
├── embed_tokens.weight # 词嵌入矩阵
├── layers
│ ├── 0 – 2 层(Dense Block,共 3 层)
│ │ ├── input_layernorm
│ │ ├── self_attn
│ │ │ ├── q_a_proj / q_b_proj
│ │ │ ├── q_a_layernorm
│ │ │ ├── kv_a_proj_with_mqa # MQA-KV 投影
│ │ │ ├── kv_a_layernorm
│ │ │ └── o_proj
│ │ └── mlp # 仅 3 个投影 → 全 token 共享
│ │ ├── gate_proj.weight
│ │ ├── up_proj.weight
│ │ └── down_proj.weight # ★ 无 experts.*(全量参与前馈)
│ ├── 3 – 61 层(MoE Block,共 58 层)
│ │ ├── input_layernorm / post_attention_layernorm
│ │ ├── self_attn
│ │ │ ├── q_a_proj / q_b_proj
│ │ │ ├── q_a_layernorm
│ │ │ ├── kv_a_proj_with_mqa
│ │ │ ├── kv_a_layernorm
│ │ │ └── o_proj
│ │ └── mlp
│ │ ├── router.* # 路由门控(Top-k 专家选择)
│ │ └── experts.[0-255].* # 256 个专家权重:各自包含 gate/up/down_proj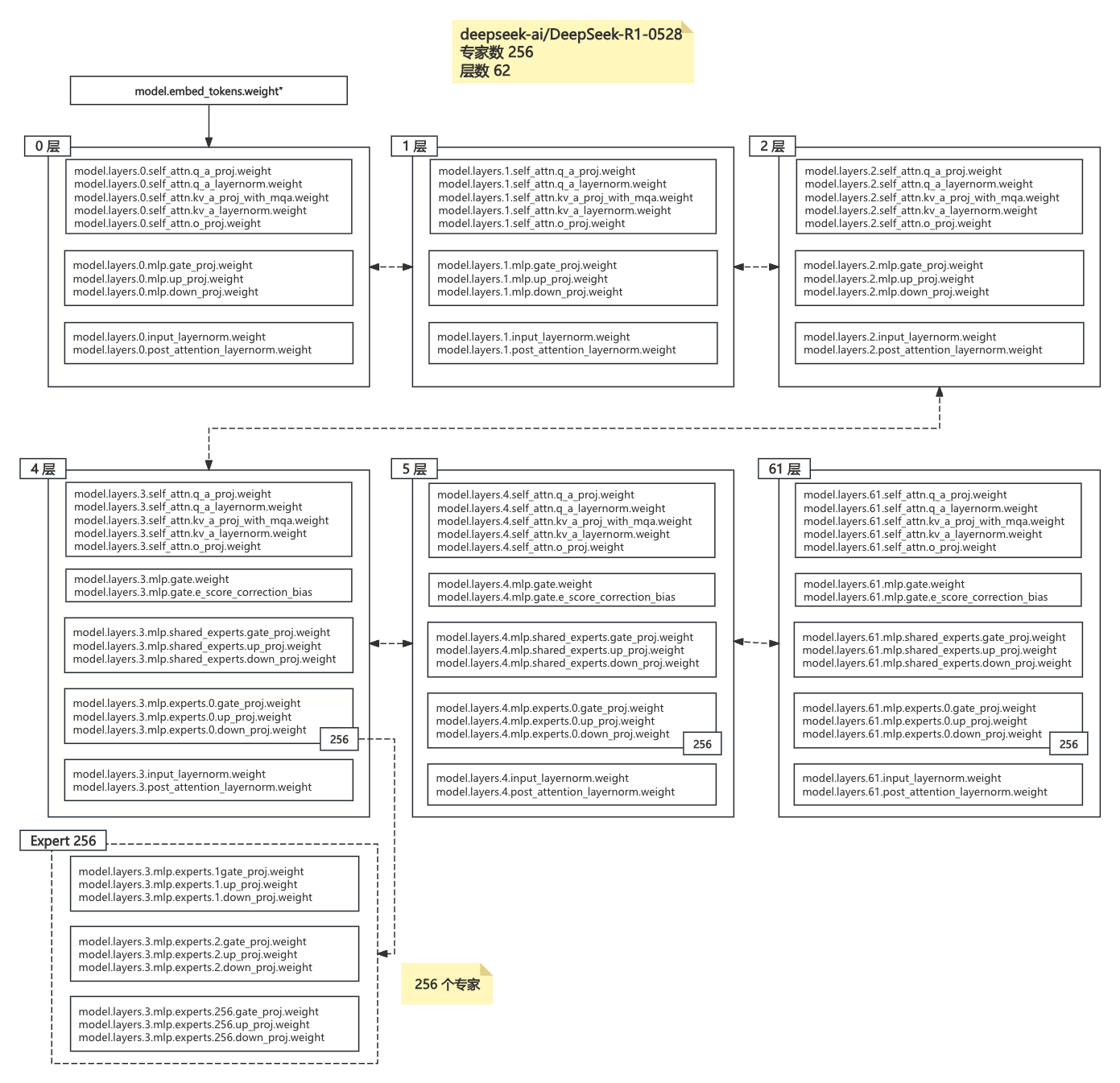
3.2 层 / 张量 解读
a) 模型关键参数与结构:
| 参数 | 取值 | 含义/影响层面 |
| num_hidden_layers | 61 | 层数(编号0~60,原文写法一般从0开始) |
| first_k_dense_replace | 3 | 前3层为Dense,后58层为MoE |
| num_attention_heads | 128 | 每层多头注意力头数 |
| num_key_value_heads | 128 | K/V分组数,支持MHA/MQA等 |
| hidden_size | 7168 | 每层主隐层维度 |
| intermediate_size | 18432 | Dense层MLP隐藏层升维 |
| moe_intermediate_size | 2048 | MoE中单个专家MLP升维(小于Dense) |
| n_routed_experts | 256 | 每层可选专家数(实际每层激活部分) |
| num_experts_per_tok | 8 | 单token路由到8个专家 |
| n_shared_experts | 1 | 共享专家(冗余,可忽略) |
| moe_layer_freq | 1 | MoE分布频率(每层都是MoE) |
| vocab_size | 129280 | 词表大小 |
| rope_theta | 10000 | 旋转位置编码基数 |
| hidden_act | silu | 激活函数 |
b) Dense 层(0~2层)张量结构
| 张量名称 | 作用说明 | 维度依据参数 |
| input_layernorm.weight | 输入LN权重 | [7168] |
| self_attn.q_a_proj.weight | Q投影A | [7168, 7168] |
| self_attn.q_a_proj.weight_scale_inv | 量化缩放 | [7168] |
| self_attn.q_a_layernorm.weight | Q分支LN权重 | [7168] |
| self_attn.q_b_proj.weight | Q投影B | [7168, 7168] |
| self_attn.q_b_proj.weight_scale_inv | 量化缩放 | [7168] |
| self_attn.kv_a_proj_with_mqa.weight | K/V投影A | [7168, 7168] |
| self_attn.kv_a_proj_with_mqa.weight_scale_inv | 量化缩放 | [7168] |
| self_attn.kv_a_layernorm.weight | K/V分支LN权重 | [7168] |
| self_attn.kv_b_proj.weight | K/V投影B | [7168, 7168] |
| self_attn.kv_b_proj.weight_scale_inv | 量化缩放 | [7168] |
| self_attn.o_proj.weight | Attention输出投影 | [7168, 7168] |
| self_attn.o_proj.weight_scale_inv | 量化缩放 | [7168] |
| mlp.gate_proj.weight | MLP门控投影 | [18432, 7168] |
| mlp.gate_proj.weight_scale_inv | 量化缩放 | [18432] |
| mlp.up_proj.weight | MLP升维 | [18432, 7168] |
| mlp.up_proj.weight_scale_inv | 量化缩放 | [18432] |
| mlp.down_proj.weight | MLP降维 | [7168, 18432] |
| mlp.down_proj.weight_scale_inv | 量化缩放 | [7168] |
| post_attention_layernorm.weight | 注意力后LN权重 | [7168] |
c) MoE 层(3~60层)张量结构
| 张量名称(完整路径) | 作用说明 | 维度依据参数 |
| input_layernorm.weight | 输入LN权重 | [7168] |
| self_attn.q_a_proj.weight | Q投影A | [7168, 7168] |
| self_attn.q_a_proj.weight_scale_inv | 量化缩放 | [7168] |
| self_attn.q_a_layernorm.weight | Q分支LN权重 | [7168] |
| self_attn.q_b_proj.weight | Q投影B | [7168, 7168] |
| self_attn.q_b_proj.weight_scale_inv | 量化缩放 | [7168] |
| self_attn.kv_a_proj_with_mqa.weight | K/V投影A | [7168, 7168] |
| self_attn.kv_a_proj_with_mqa.weight_scale_inv | 量化缩放 | [7168] |
| self_attn.kv_a_layernorm.weight | K/V分支LN权重 | [7168] |
| self_attn.kv_b_proj.weight | K/V投影B | [7168, 7168] |
| self_attn.kv_b_proj.weight_scale_inv | 量化缩放 | [7168] |
| self_attn.o_proj.weight | Attention输出投影 | [7168, 7168] |
| self_attn.o_proj.weight_scale_inv | 量化缩放 | [7168] |
| mlp.gate_proj.weight | MLP门控投影 | [18432, 7168] |
| mlp.gate_proj.weight_scale_inv | 量化缩放 | [18432] |
| mlp.up_proj.weight | MLP升维 | [18432, 7168] |
| mlp.up_proj.weight_scale_inv | 量化缩放 | [18432] |
| mlp.down_proj.weight | MLP降维 | [7168, 18432] |
| mlp.down_proj.weight_scale_inv | 量化缩放 | [7168] |
| post_attention_layernorm.weight | 注意力后LN权重 | [7168] |
专家网络
| 张量名称(完整路径) | 作用说明 | 维度依据参数 |
| mlp.experts.K.gate_proj.weight | 第K号专家门控投影 | [2048, 7168] |
| mlp.experts.K.gate_proj.weight_scale_inv | 量化缩放 | [2048] |
| mlp.experts.K.up_proj.weight | 升维投影 | [2048, 7168] |
| mlp.experts.K.up_proj.weight_scale_inv | 量化缩放 | [2048] |
| mlp.experts.K.down_proj.weight | 降维投影 | [7168, 2048] |
| mlp.experts.K.down_proj.weight_scale_inv | 量化缩放 | [7168] |
四、 DeepSeek-R1 模型部署资源预估
4.1 通用方法论资源评估
| 维度分类 | 关键参数/信息 | 典型示例/说明 |
| 模型参数 | 模型总参数量 | 52.8B / 70B / 13B … |
| 层数/隐藏维度 | 61层 / 7168 | |
| 架构类型 | Dense / MoE | |
| 精度/量化 | fp16 / bf16 / int8 | |
| MoE专家数/激活专家数 | 256 / 8(如有MoE结构) | |
| 输入权重文件总大小 | 105GB(fp16) | |
| 并行策略 | 并行方式 | TP/PP/EP 配置 |
| 单卡显存 | 80GB(如A100/H800) | |
| 流量负载 | 并发请求数(峰值) | 64 / 256 |
| 输入token数 | 32 / 128 | |
| 输出token数 | 64 / 256 | |
| QPS目标 | 1000 / 2000 | |
| 延迟SLA | p99 < 1s | |
| KV缓存相关 | KV缓存保留token数 | 并发 × (in+out) |
| KV缓存显存需求 | 计算公式(可推导,见备注) | |
| 硬件环境 | GPU类型与数量 | 8×H800/80GB |
| CPU核数 | 32 / 64 | |
| 内存(RAM) | 256GB | |
| 网络带宽 | ≥400Gbps | |
| 本地磁盘(NVMe) | ≥1TB、≥2GB/s |
4.2 推理部署资源需求评估表
DeepSeek-R1-0528 685B MoE
| 维度分类 | 关键参数 | 评估值 / 说明 |
| 模型参数 | 参数量 | 685 B(6.85 × 10¹¹) |
| 层数 / 隐藏维度 | 61 层 / 7 168 | |
| 架构类型 | Decoder-Only MoE | |
| 精度 | bf16 / fp16 (2 B/param) | |
| 专家数 / 激活数 | 256 / 8 | |
| 权重文件总大小 | 685 B × 2 B ≈ 1.37 TB(原始 <safetensors> 分片约 163 × 8 GB) | |
| 并行策略 | 配置 | TP 8 · PP 2 · EP 4(64 GPU) |
| 单卡权重占用 | 1.37 TB ÷ 64 ≈ 21 GB | |
| 流量负载 | 峰值并发 | 128 req |
| 输入 / 输出 token | 32 / 128 | |
| QPS 目标 | 3 000 tok · s⁻¹ | |
| 延迟 SLA | p99 ≤ 1 s | |
| KV-Cache | Token 保留总量 | 128 req × (32+128)= 20 480 tok |
| 总 KV 显存 | 20 480 tok × 61 × 7 168 × 4 B ≈ 280 MB/req → 35.8 GB 全集群 ÷ 64 GPU ≈ 0.56 GB/卡(TP 8 分片后约 4.5 GB/卡,留 6 GB 余量更稳) |
|
| 硬件配置 | GPU | 64 × H800 80 GB(8 GPU/节点) |
| GPU 显存需求 | 权重 21 GB + KV ≤ 6 GB + 激活/缓冲 ≈ 6 GB → ≈ 33 GB / 卡 | |
| CPU | 64 vCPU / 节点(分词、调度、gRPC) | |
| RAM | 512 GB / 节点(权重 mmap + 缓冲) | |
| 网络 | NVLink4 同机 + 400 Gb RoCE / IB 跨机;MoE 路由带宽 ≥ 200 GB/s | |
| 磁盘 | NVMe 4 TB / 节点, ≥ 3 GB·s⁻¹(权重热加载 + 日志) |
| 资源 | 集群级需求 | 单节点需求 |
| 显存 | ≈ 2.1 TB | 8 × 33 GB ≈ 264 GB |
| CPU 内存 | ≈ 4 TB | 512 GB |
| 存储 | ≈ 32 TB NVMe | 4 TB |
| 网络峰值 | ≈ 3 TB/s 全双工 | ≥ 400 Gbps |
权重显存
参数量×字节÷(TP⋅EP)参数量 × 字节 ÷ (TP·EP)参数量×字节÷(TP⋅EP) → 21 GB / 卡
KV-Cache 显存
并发×tokens×层×hidden×2×字节÷TP并发 × tokens × 层 × hidden × 2 × 字节 ÷ TP并发×tokens×层×hidden×2×字节÷TP → ~4.5 GB / 卡
总显存预留 = 权重 + KV + 激活缓冲 + 驱动 = ≤ 80 GB(H800 余量充足)。
网络带宽 ≈ MoE 激活数 / 专家数 × tokens × hidden × 首层 latency 预算 → ≥ 400 Gbps。
节点数 由 QPS 与 GPU tokens/s 实测值回推(H800 单卡 fp16 解码 ≈ 45 k tok/s,64 GPU 轻松 >3 M tok/s)。4.3 通用资源描述
部署大模型推理,常用的资源消耗估算流程如下:
显存(GPU Memory)
-
模型参数占用:权重、KV cache(推理时动态分配)、激活
-
影响因素:模型规模、精度、batch size、推理并发、MoE/Dense结构、分布式并行策略(TP/PP/EP)
内存(CPU Memory)
-
模型文件缓存(权重装载、分块缓存)、数据预处理缓存、KV cache落盘等
-
通常和显存正相关,但也要考虑分布式参数/异步卸载等
CPU(推理调度与预处理)
-
解码调度、分词、请求路由、轻量前处理(重计算都在GPU)
网络带宽
-
节点间参数/缓存同步(分布式场景如TP/PP/EP/MoE专家跨机)、输入输出数据传输、RPC
-
MoE架构对带宽消耗更高(专家拉取/聚合)
磁盘IO
-
模型加载、权重分块IO、持久化KV cache(如冷启动/大KV缓存需分级落盘)、日志等
补充 MoE VS Dense 模式
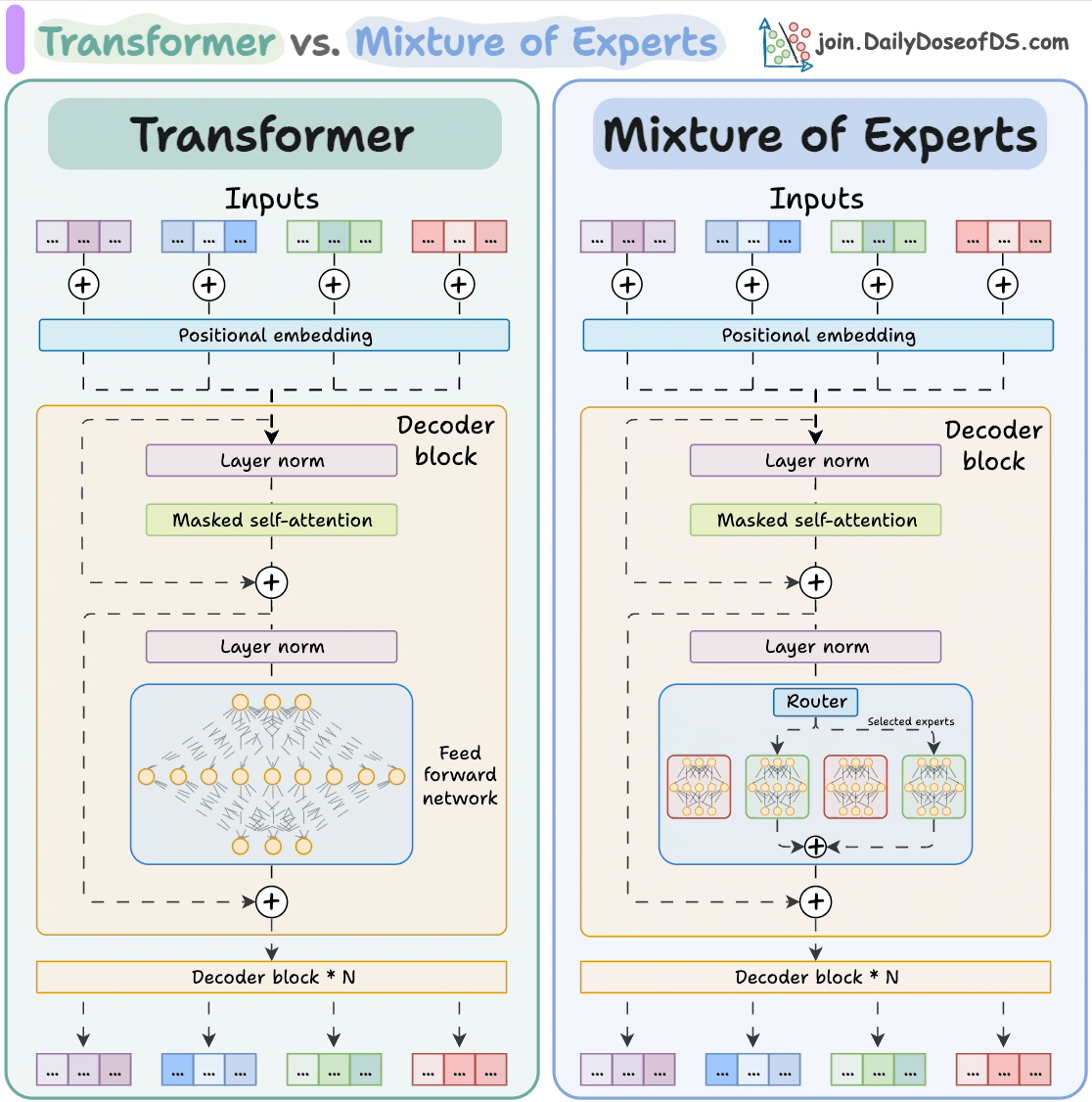
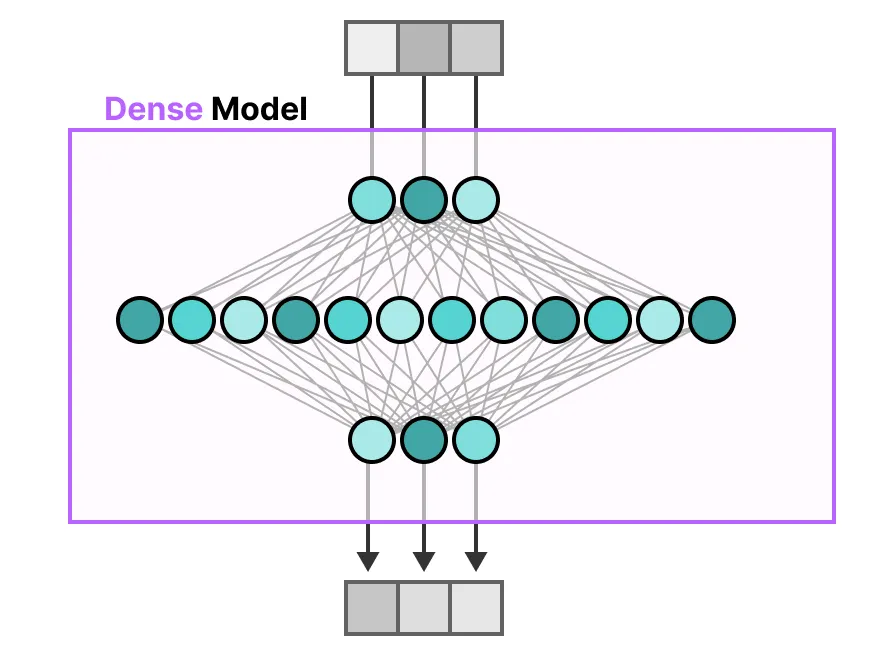
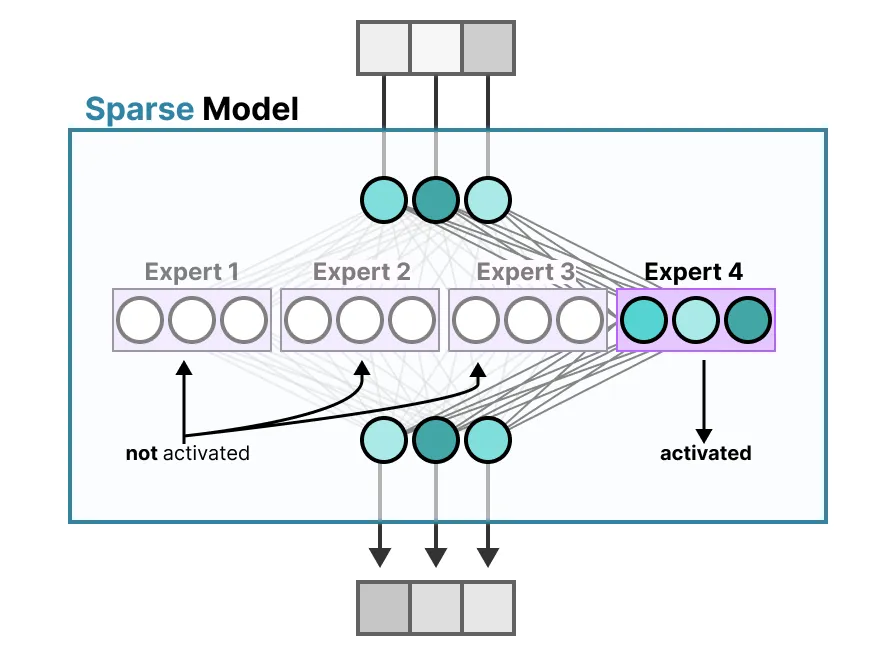
小结
本文聚焦 DeepSeek-R1-0528 685B 大语言模型的推理文件,逐层剖析其结构、揭示关键组成部分的直观含义。目标只有一个:抛开对复杂公式的恐惧,从文件的“物理形态”入手,建立起对大模型运作最直接、最接地气的认知。理解文件,是理解模型的第一步。
参考:
DeepSeek | 深度求索深度求索(DeepSeek),成立于2023年,专注于研究世界领先的通用人工智能底层模型与技术,挑战人工智能前沿性难题。基于自研训练框架、自建智算集群和万卡算力等资源,深度求索团队仅用半年时间便已发布并开源多个百亿级参数大模型,如DeepSeek-LLM通用大语言模型、DeepSeek-Coder代码大模型,并在2024年1月率先开源国内首个MoE大模型(DeepSeek-MoE),各大模型在公开评测榜单及真实样本外的泛化效果均有超越同级别模型的出色表现。和 DeepSeek AI 对话,轻松接入 API。![]() https://www.deepseek.com/首次调用 API | DeepSeek API DocsDeepSeek API 使用与 OpenAI 兼容的 API 格式,通过修改配置,您可以使用 OpenAI SDK 来访问 DeepSeek API,或使用与 OpenAI API 兼容的软件。
https://www.deepseek.com/首次调用 API | DeepSeek API DocsDeepSeek API 使用与 OpenAI 兼容的 API 格式,通过修改配置,您可以使用 OpenAI SDK 来访问 DeepSeek API,或使用与 OpenAI API 兼容的软件。![]() https://api-docs.deepseek.com/zh-cn/https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
https://api-docs.deepseek.com/zh-cn/https://huggingface.co/deepseek-ai/DeepSeek-R1-0528![]() https://huggingface.co/deepseek-ai/DeepSeek-R1-0528GitHub - deepseek-ai/DeepSeek-R1Contribute to deepseek-ai/DeepSeek-R1 development by creating an account on GitHub.
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528GitHub - deepseek-ai/DeepSeek-R1Contribute to deepseek-ai/DeepSeek-R1 development by creating an account on GitHub.![]() https://github.com/deepseek-ai/DeepSeek-R1A Visual Guide to Mixture of Experts (MoE)Demystifying the role of Mixture of Experts (MoE) in Large Language Models (LLMs) with over 50 illustrations.
https://github.com/deepseek-ai/DeepSeek-R1A Visual Guide to Mixture of Experts (MoE)Demystifying the role of Mixture of Experts (MoE) in Large Language Models (LLMs) with over 50 illustrations.![]() https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)