CTR模型 | 建模用户行为、建模特征交叉、集成架构、蒸馏机制
点击率(CTR)模型是推荐系统和在线广告中的核心技术,旨在预测用户点击某个物品或广告的概率。它通过分析用户行为、物品特征以及上下文信息,挖掘隐藏的特征交互关系,为用户提供个性化的推荐服务。
点击率(CTR)模型是推荐系统和在线广告中的核心技术,旨在预测用户点击某个物品或广告的概率。它通过分析用户行为、物品特征以及上下文信息,挖掘隐藏的特征交互关系,为用户提供个性化的推荐服务。
一、建模用户行为
Multi-granularity Interest Retrieval and Refinement Network for Long-Term User Behavior Modeling in CTR Prediction
https://arxiv.org/abs/2411.15005
这项工作提出了一种名为 Multi-granularity Interest Retrieval and Refinement Network (MIRRN) 的新方法,旨在改进点击率(CTR)预测中的长期用户行为建模。MIRRN 首先通过基于不同时间尺度行为的查询,检索能够反映用户多样化兴趣的多粒度子序列,从而更全面地捕获用户的兴趣。随后,模型引入了一种新颖的多头傅里叶变换器,高效学习子序列中的序列关系和交互信息,以精准建模用户兴趣。最后,采用多头目标注意力机制,自适应评估不同粒度兴趣对子序列和目标物品的影响。在多个基准任务上的实验表明,MIRRN 显著优于现有方法,并通过华为音乐应用的 A/B 测试验证了其实际效果,提高了用户的听歌量和听歌时长。这一方法有效克服了传统方法在兴趣多样性捕获和关系信息建模方面的不足,为 CTR 预测提供了新的解决思路。
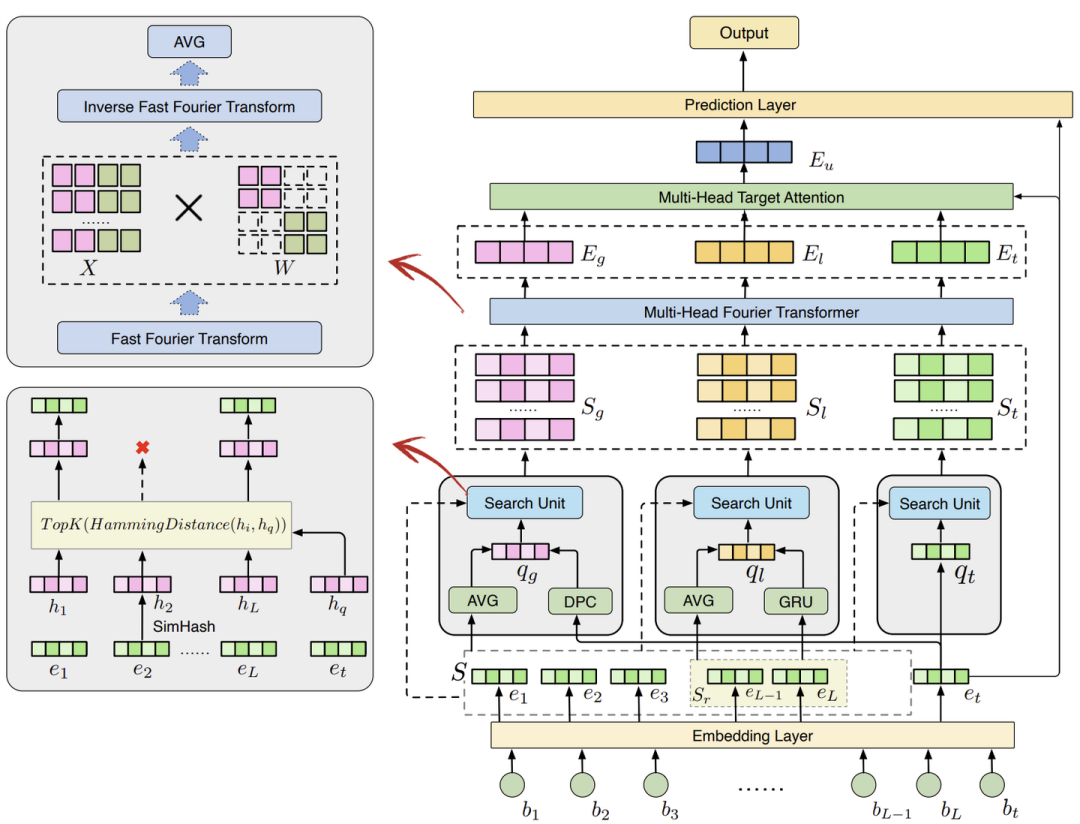
LIBER: Lifelong User Behavior Modeling Based on Large Language Models
https://arxiv.org/abs/2411.14713
CTR预测在推荐系统中发挥着至关重要的作用。近年来,随着大型语言模型(LLMs)的出现,它们已被应用于推荐系统中。尽管利用LLMs中的语义信息在一定程度上提高了推荐系统的性能,但这些研究中仍然存在两个显著的局限性。首先,增强型LLM推荐系统在提取来自文本上下文中的终身用户行为序列的有价值信息时,面临一定的挑战。其次,人类行为的内在变异性导致了新的行为不断涌现以及用户兴趣的不规则波动。这一特点对现有模型提出了两个重大挑战:一方面,它给LLMs在有效捕捉用户兴趣在这些序列中的动态变化带来了困难;另一方面,如果LLMs在每次用户序列更新时都需要反复调用,会导致相当大的计算开销。为了解决这些问题,本文提出了基于大型语言模型的终身用户行为建模(LIBER),该方法包括三个模块:(1)用户行为流分区(UBSP),(2)用户兴趣学习(UIL),(3)用户兴趣融合(UIF)。首先,UBSP通过增量方式将冗长的用户行为序列压缩为较短的分区,从而提高处理效率。随后,UIL以级联方式利用LLMs从这些分区中推断出有价值的见解。最后,UIF将前述过程生成的文本输出整合在一起,构建出一个全面的表示,可以被任何推荐模型用于性能提升。LIBER已经部署在华为的音乐推荐服务中,显著提高了用户播放次数和播放时长,分别提升了3.01%和7.69%。
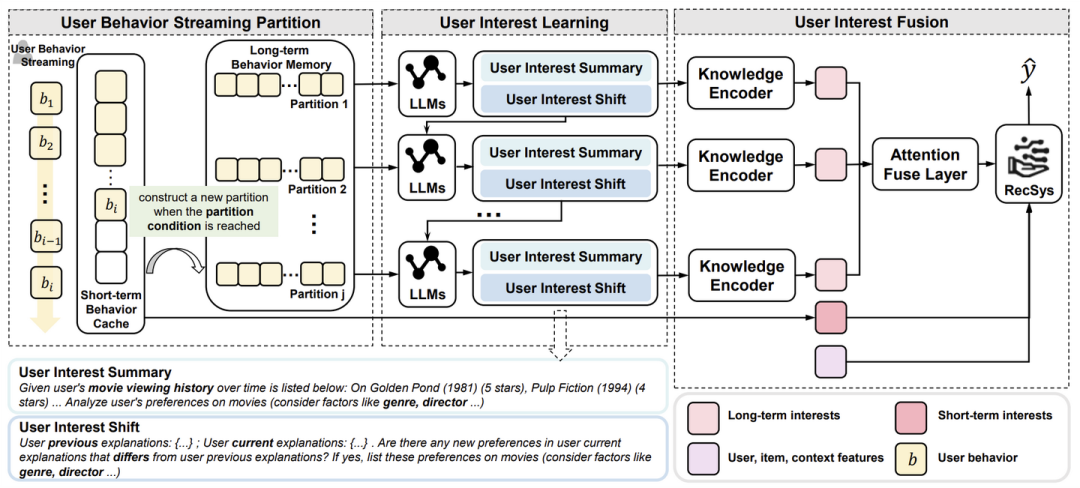
二、建模特征交叉
Towards Unifying Feature Interaction Models for Click-Through Rate Prediction
https://arxiv.org/abs/2411.12441
特征交互建模在广告系统中准确预测点击率(CTR)中起着至关重要的作用。为了捕捉复杂的交互模式,许多现有模型采用矩阵分解技术,将特征表示为低维嵌入向量,从而使得交互可以通过这些嵌入的乘积来建模。在本文中,我们提出了一种通用框架,称为IPA,旨在系统地统一这些模型。我们的框架包含三个关键组件:交互函数(Interaction Function),它促进特征交互;层池化(Layer Pooling),它构建更高层次的交互层;以及层聚合器(Layer Aggregator),它将所有层的输出结合起来,作为后续分类器的输入。我们证明,通过对这三个组件做出特定选择,大多数现有模型可以在我们的框架内进行分类。通过广泛的实验和维度压缩分析,我们评估了这些选择的性能。此外,通过利用我们框架中最强大的组件,我们提出了一种新型模型,在与最先进的CTR模型比较时取得了具有竞争力的结果。PFL在腾讯广告平台的在线A/B测试中获得了显著的GMV提升,并已在多个主要场景中作为生产模型进行部署。
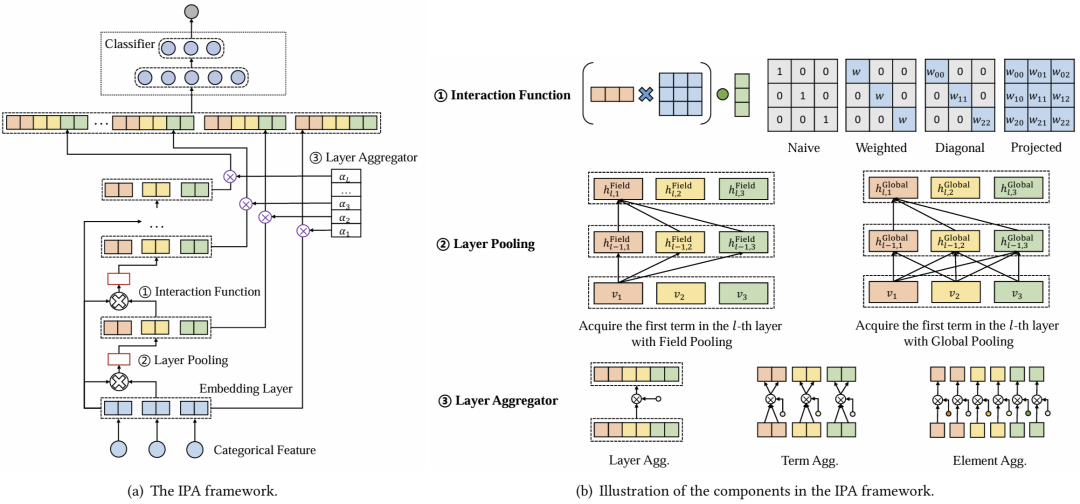
Fusion Matters: Learning Fusion in Deep Click-through Rate Prediction Models
https://arxiv.org/abs/2411.15731
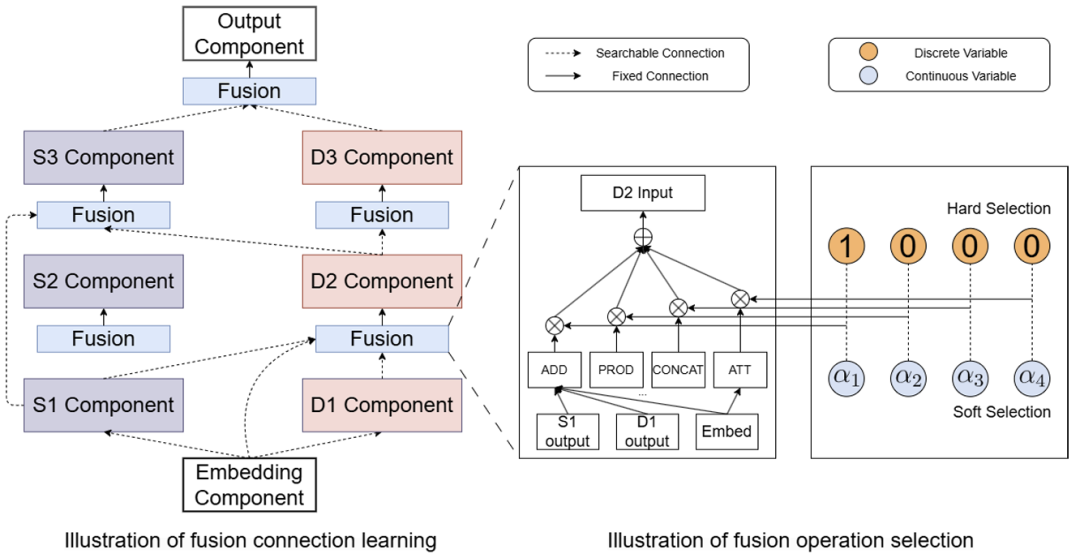
以往的点击率(CTR)模型的演变主要通过提出复杂的组件,无论是浅层的还是深层的,这些组件擅长建模特征交互。然而,针对融合设计的改进关注较少,常见的解决方案是堆叠融合和并行融合。这两种方案都依赖于预先确定的融合连接和固定的融合操作。研究中反复观察到,融合设计的变化可能导致性能差异,凸显了融合在CTR模型中的关键作用。尽管已有尝试对这些基本融合策略进行优化,但这些努力往往局限于特定的设置或依赖于特定组件。神经架构搜索也被引入来部分解决融合设计问题,但其存在一定的局限性。搜索空间的复杂性可能导致低效和无效的结果。为了弥补这一空白,我们提出了OptFusion,一种自动化学习融合的方法,涵盖了连接学习和操作选择。我们提出了一种一次性学习算法,旨在同时解决这些任务。我们的实验在三个大规模数据集上进行,广泛的实验结果证明了OptFusion在提升CTR模型性能方面的有效性和高效性。
三、集成架构
A Collaborative Ensemble Framework for CTR Prediction
https://arxiv.org/abs/2411.13700
近年来,基础模型的进展推动了扩展法则的建立,从而使得开发更大规模的模型以提升性能成为可能,这也激发了大规模推荐系统的广泛研究。然而,单纯增加推荐系统中模型的规模,即便在大规模数据的支持下,也未必能够带来预期的性能提升。为此,本文提出了一种新颖的框架——协同集成训练网络(CETNet),旨在通过利用多个独立的模型,每个模型均拥有独立的嵌入表,从而捕捉不同的特征交互模式。与简单的模型扩展方法不同,我们的方法通过协同学习强调多样性与合作,在此过程中,各个模型通过迭代的方式不断精炼其预测结果。为了动态平衡每个模型的贡献,我们引入了一种基于置信度的融合机制,采用常规的softmax方法,其中模型的置信度通过否定熵计算得出。该设计确保了更具信心的模型在最终预测中占据更大的影响力,同时也能从其他模型的互补优势中受益。我们在三个公共数据集(AmazonElectronics、TaobaoAds 和 KuaiVideo)以及Meta的大规模工业数据集上验证了该框架的有效性,结果表明,我们的方法在性能上优于单一模型和现有的最先进基准方法。此外,我们还在Criteo和Avazu数据集上进行了进一步实验,将我们的方案与多嵌入范式进行了比较。实验结果表明,CETNet在较小嵌入尺寸下能够实现与其他方法相当或更好的性能,证明了其在CTR预测任务中的可扩展性和高效性。
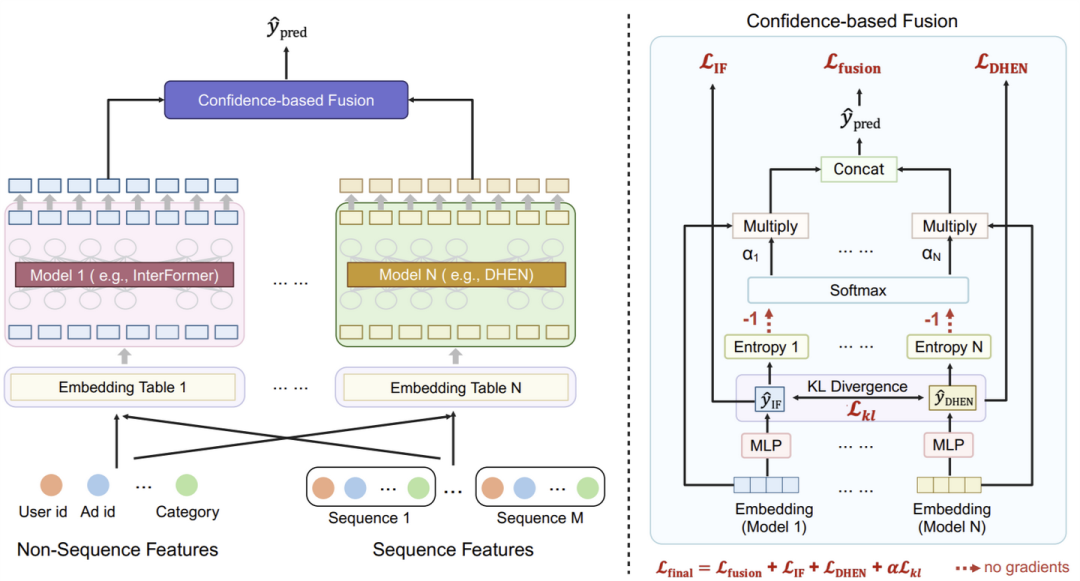
Branches, Assemble! Multi-Branch Cooperation Network for Large-Scale Click-Through Rate Prediction at Taobao
https://arxiv.org/abs/2411.13057
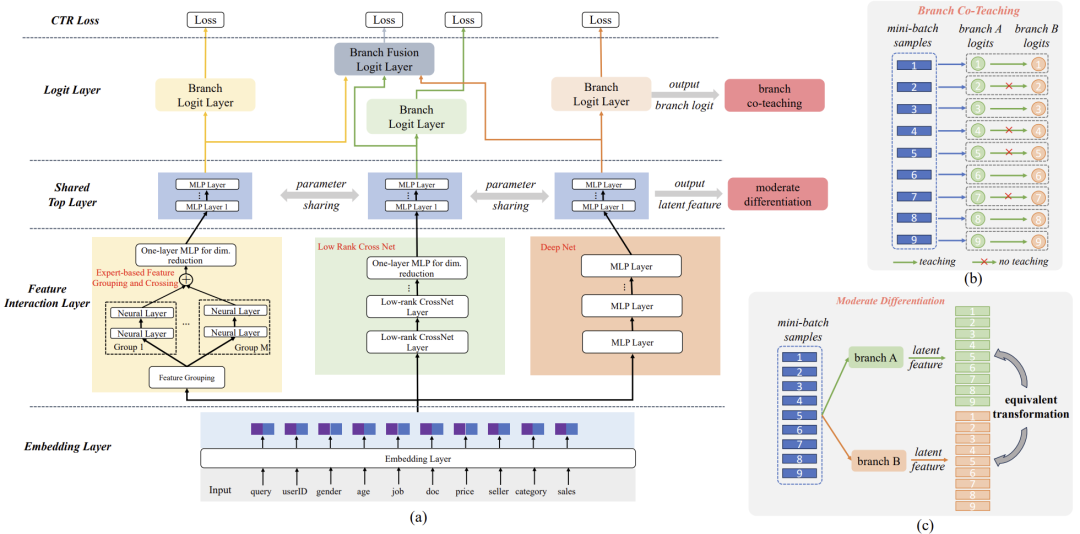
现有的点击率(CTR)预测研究通过多种技术研究了特征交互的作用。每种交互技术都有其自身的优势,单独使用一种方法可能会限制模型捕捉复杂特征关系的能力,尤其是在面对拥有大量用户和商品的工业大规模数据时。最近的研究表明,有效的CTR模型通常将MLP网络与专门的特征交互网络结合,采用双并行结构。然而,不同流或分支之间的相互作用和协同动态仍然是一个尚未深入研究的课题。在这项工作中,我们提出了一种新颖的多分支协同网络(MBCnet),该网络使多个分支网络能够相互协作,从而更好地进行复杂特征交互建模。具体来说,MBCnet由三个分支组成:基于专家的特征分组与交叉(EFGC)分支,旨在增强模型对特定特征域的记忆能力;低秩交叉网络分支和深度分支,用于增强显性和隐性特征交叉,以提高泛化能力。在各分支之间,基于两个原则提出了一种新颖的协作方案:分支共同教学和适度差异化。分支共同教学鼓励学习较好的分支在特定训练样本上支持学习较差的分支;适度差异化主张分支在特征表示上保持合理的差异。该协作策略通过共同教学促进知识共享,并通过增强分支间的特征交互发现来提升学习效果。针对大规模工业数据集的广泛实验和在线A/B测试表明,MBCnet在性能上优于现有方法,CTR提高了0.09个百分点,交易量增长了1.49%,GMV增加了1.62%。
四、蒸馏机制
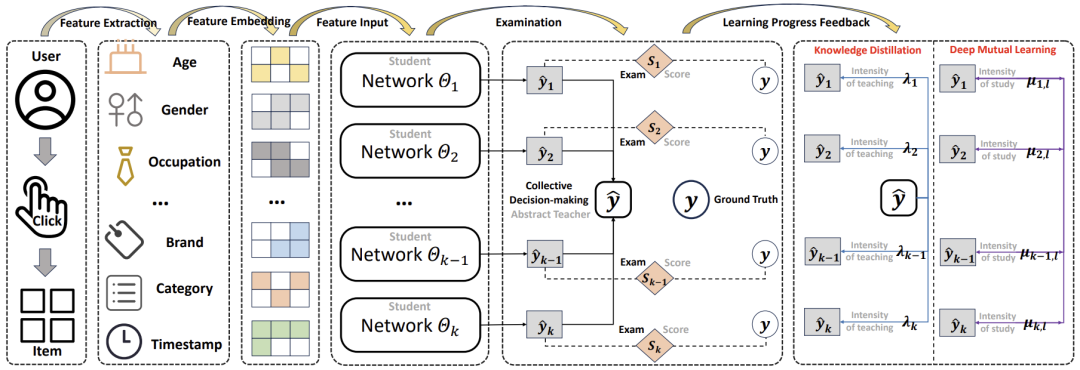
Ensemble Learning via Knowledge Transfer for CTR Prediction
https://arxiv.org/abs/2411.16122
点击率(CTR)预测在推荐系统和网页搜索中起着至关重要的作用。尽管现有的许多方法通过集成学习(Ensemble Learning)提升模型性能,但通常将集成的规模限制在两到三个子网络,对更大规模集成的探索较少。在本文中,我们研究了更大规模集成网络的潜力,并发现常见集成学习方法存在以下三个固有局限性:(1)子网络数量增加时性能下降;(2)子网络性能急剧下降且波动较大;(3)子网络预测结果与集成预测结果之间存在较大差异。为同时解决上述问题,本文从知识蒸馏(Knowledge Distillation, KD)和深度互学习(Deep Mutual Learning, DML)的角度探索潜在的解决方案。基于这些方法的经验性表现,我们提出了一种新颖的、与具体模型无关的集成知识迁移框架(Ensemble Knowledge Transfer Framework, EKTF)。具体而言,我们利用学生网络的集体决策作为抽象教师(Abstract Teacher),指导每个学生网络(子网络)进行更高效的学习。此外,我们鼓励学生网络之间的互学习,从不同的视角获取知识。为了解决损失函数中超参数平衡的问题,我们设计了一种新颖的考核机制,以确保教师对学生的定制化教学,以及学生间的选择性学习。在五个真实数据集上的实验结果表明,EKTF 在有效性和兼容性方面均优于现有方法。
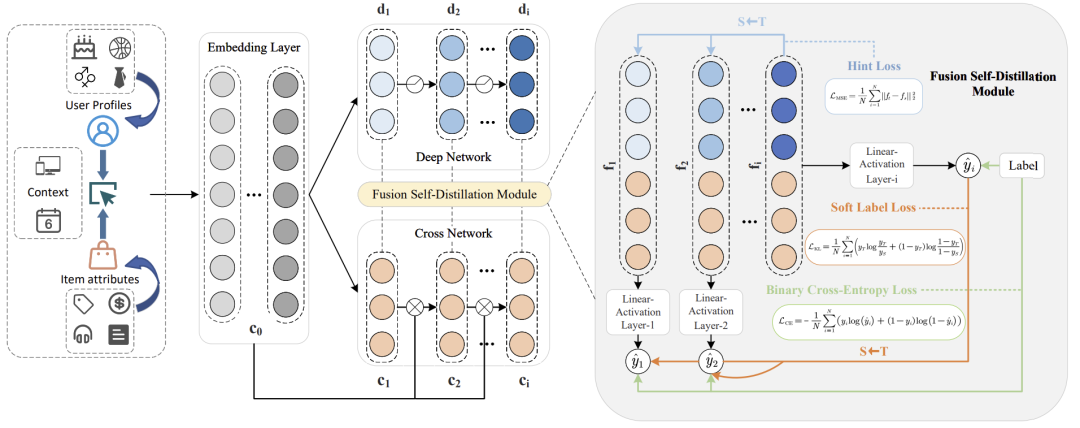
Feature Interaction Fusion Self-Distillation Network For CTR Prediction
https://arxiv.org/abs/2411.07508
点击率(CTR)预测在推荐系统、在线广告和搜索引擎中起着至关重要的作用。目前的大多数方法通过堆叠或并行结构建模特征交互,部分方法还采用知识蒸馏进行模型压缩。然而,我们观察到这些方法存在一些局限性:(1)在并行结构模型中,显式和隐式组件独立且同时执行,这导致特征集内的信息共享不足。(2)引入知识蒸馏技术带来了复杂的教师-学生框架设计和低效的知识转移问题。(3)数据集和高阶特征交互构建过程中的噪声较大,限制了模型的效果。为了解决这些问题,我们提出了FSDNet,一个结合即插即用融合自蒸馏模块的CTR预测框架。具体而言,FSDNet在每一层形成显式和隐式特征交互之间的连接,增强了不同特征之间的信息共享。最深的融合层被用作教师模型,利用自蒸馏指导浅层的训练。通过在四个基准数据集上的实证评估,验证了该框架的有效性和泛化能力。
五、大语言模型相关
The Efficiency vs. Accuracy Trade-off: Optimizing RAG-Enhanced LLM Recommender Systems Using Multi-Head Early Exit
https://arxiv.org/abs/2501.02173
在推荐系统中部署大型语言模型(LLMs)以进行点击率(CTR)预测时,需要在计算效率和预测精度之间实现微妙的平衡。本文提出了一种优化框架,将检索增强生成(Retrieval-Augmented Generation, RAG)与创新的多头早退出架构相结合,从而同时提升这两个方面的性能。通过引入图卷积网络(Graph Convolutional Networks, GCNs)作为高效的检索机制,我们显著降低了数据检索时间,同时保持了模型的高性能表现。所采用的早退出策略利用多个头部的实时预测置信度评估,动态终止模型推理过程。这不仅加快了大型语言模型的响应速度,还能保持甚至提升其预测精度,使其非常适用于实时应用场景。实验结果表明,该架构能够在不牺牲推荐可靠性和精度的前提下有效减少计算时间,为高效、实时的大型语言模型商业部署设立了新的标杆。
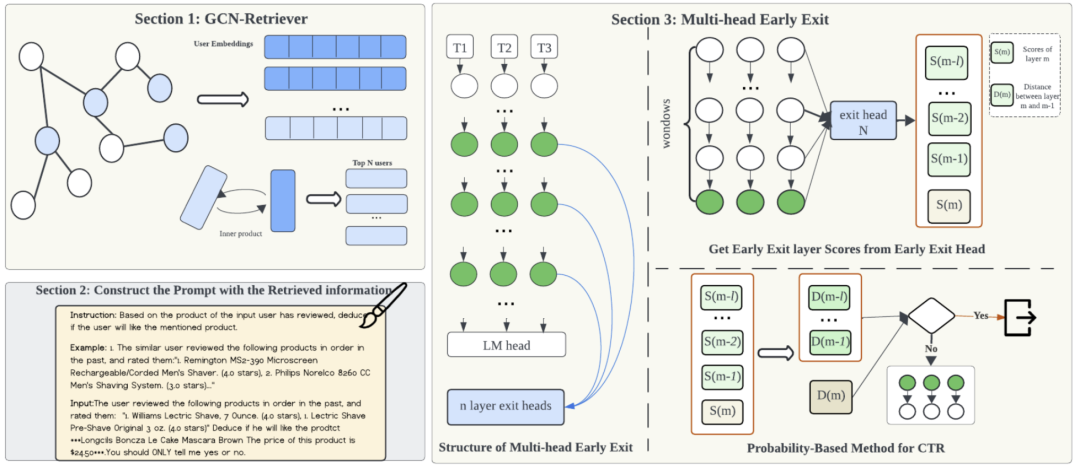
Balancing Efficiency and Effectiveness: An LLM-Infused Approach for Optimized CTR Prediction
https://arxiv.org/abs/2412.06860
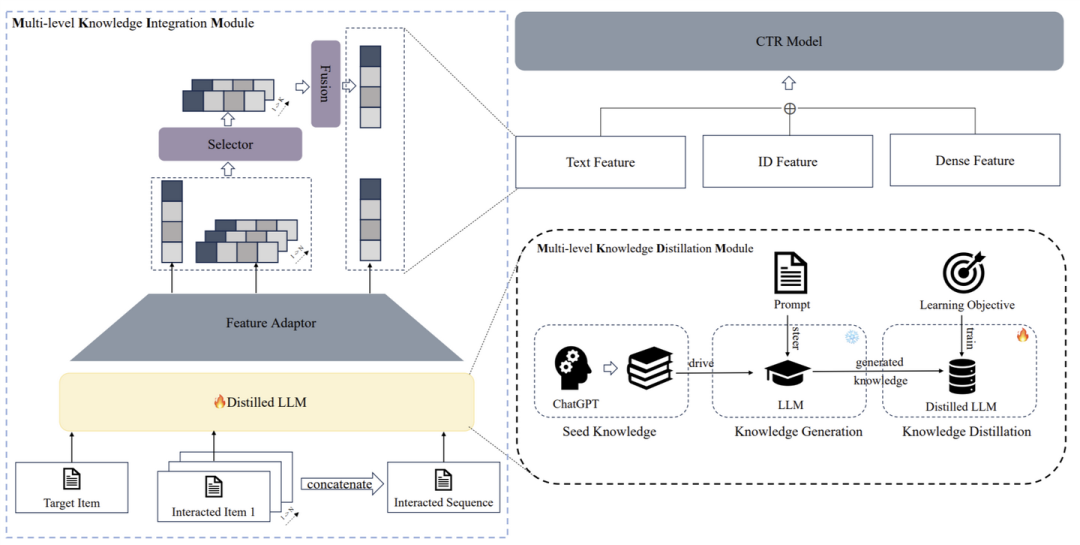
点击率(CTR)预测在网络广告中至关重要,其中语义信息在影响用户决策和提高CTR效果方面发挥着关键作用。捕捉和建模深层语义信息(如用户因健康和高端属性而偏好“哈根达斯HEAVEN草莓轻盈冰淇淋”)是一项具有挑战性的任务。传统的语义建模往往忽视了用户和物品层面的这些复杂细节。为弥补这一差距,我们提出了一种新方法,通过端到端建模深层语义信息,充分利用大型语言模型(LLMs)对世界知识的综合理解能力。我们提出的LLM融合CTR预测框架(基于蒸馏的多层次深层语义信息融合CTR模型,简称MSD)旨在通过LLMs提取和蒸馏关键语义信息,将其集成到一个更小、更高效的模型中,从而实现无缝的端到端训练与推理。值得注意的是,该框架经过精心设计,以平衡效率与效果,确保模型不仅能够实现高性能,还能以最优的资源利用率运行。在美团赞助搜索系统中的在线A/B测试表明,我们的方法在每千次展示成本(CPM)和CTR方面显著优于基线模型,验证了其在实际应用中的有效性、可扩展性和均衡性。
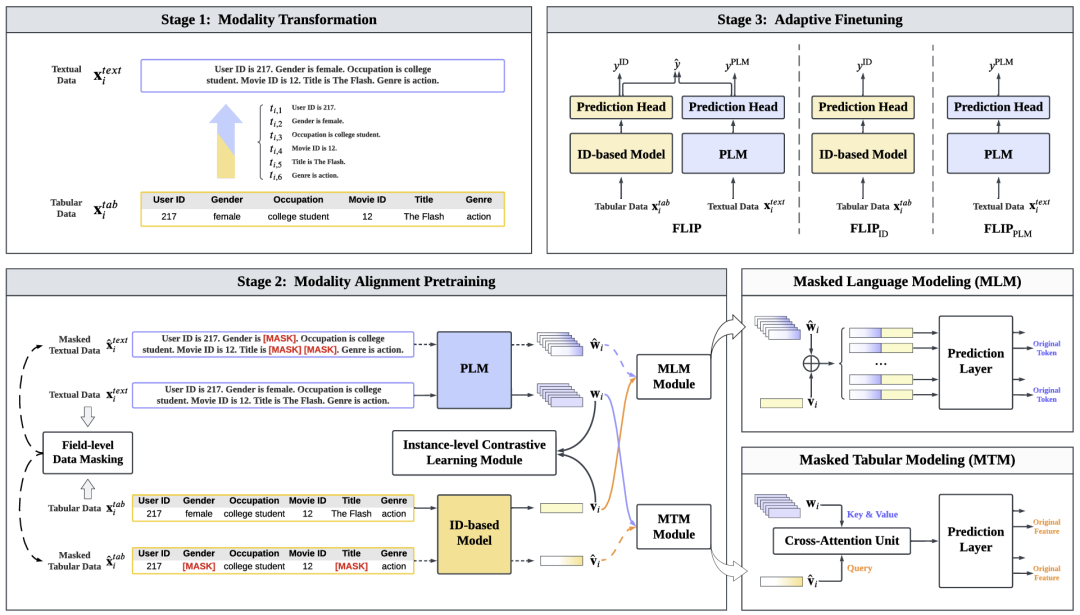
FLIP: Fine-grained Alignment between ID-based Models and Pretrained Language Models for CTR Prediction
https://arxiv.org/abs/2310.19453
点击率(CTR)预测是各种个性化在线服务中的核心功能模块。传统的基于 ID 的 CTR 预测模型以表格形式的一次性编码(one-hot encoded)ID 特征作为输入,通过特征交互建模捕捉协同信号。然而,一次性编码会丢失文本特征中包含的语义信息。近年来,预训练语言模型(PLMs)的兴起催生了另一种范式,它通过硬模板提示生成的文本模态句子作为输入,并利用 PLMs 提取语义知识。然而,PLMs 在捕捉领域级协同信号以及区分具有微妙文本差异的特征方面往往面临挑战。为此,本文提出了一种方法,即通过 ID 模型与预训练语言模型之间的 Fine-grained feature-level ALignment(FLIP) 来提升 CTR 预测性能。在结合两种范式优势的同时克服其局限性。不同于大多数仅依赖实例级对比学习的全局视角方法,我们设计了一种新颖的联合掩码表格/语言建模任务,以实现表格 ID 与词语 token 之间的细粒度对齐。具体而言,一种模态(ID 或 token)的掩码数据需要借助另一种模态进行恢复,通过充分提取双模态之间的互信息,建立特征级交互与对齐。此外,我们提出联合微调 ID 模型与 PLM,动态结合两种模型的输出,从而在下游 CTR 预测任务中实现更优性能。在三个真实世界数据集上的广泛实验表明,FLIP 超越了现有的 SOTA 基线模型,并且能够与多种基于 ID 的模型和 PLM 高度兼容。
六、跨域推荐
Enhancing CTR Prediction in Recommendation Domain with Search Query Representation
https://arxiv.org/abs/2410.21487
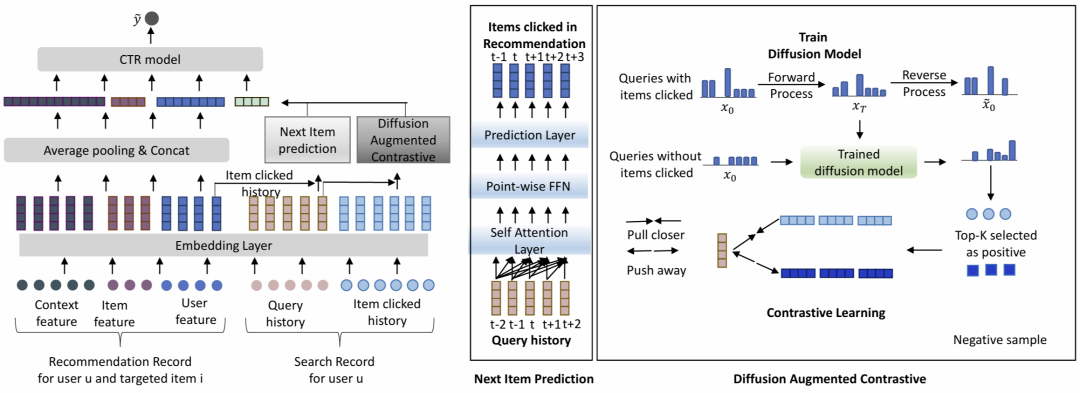
许多平台(例如电商网站)同时提供搜索和推荐服务,以更好地满足用户的多样化需求。推荐服务基于用户偏好为其推荐商品,而搜索服务允许用户主动搜索商品,然后再提供推荐。由于用户和商品通常在搜索与推荐领域之间共享,这为利用搜索领域中提取的用户偏好来增强推荐领域提供了宝贵的机会。然而,现有方法要么忽视了用户在这两个领域之间意图的转变,要么未能捕捉到从用户搜索查询中学习对理解用户兴趣的重要作用。本文提出了一种框架,通过学习搜索领域中的用户搜索查询嵌入(query embedding),增强推荐领域中的用户偏好建模。具体而言,我们利用搜索领域中的用户搜索查询序列来预测用户在推荐领域中下一时刻可能点击的商品。此外,通过对比学习探索查询与商品之间的关系。为了解决数据稀疏性问题,我们引入扩散模型,以一种去噪的方式推断用户在特定查询后可能选择的正样本商品,从而有效避免误报问题。在有效提取这些信息后,我们将查询信息融入推荐领域中的点击率(CTR)预测中。实验分析表明,所提出的模型在推荐领域中的表现优于现有的最新模型。
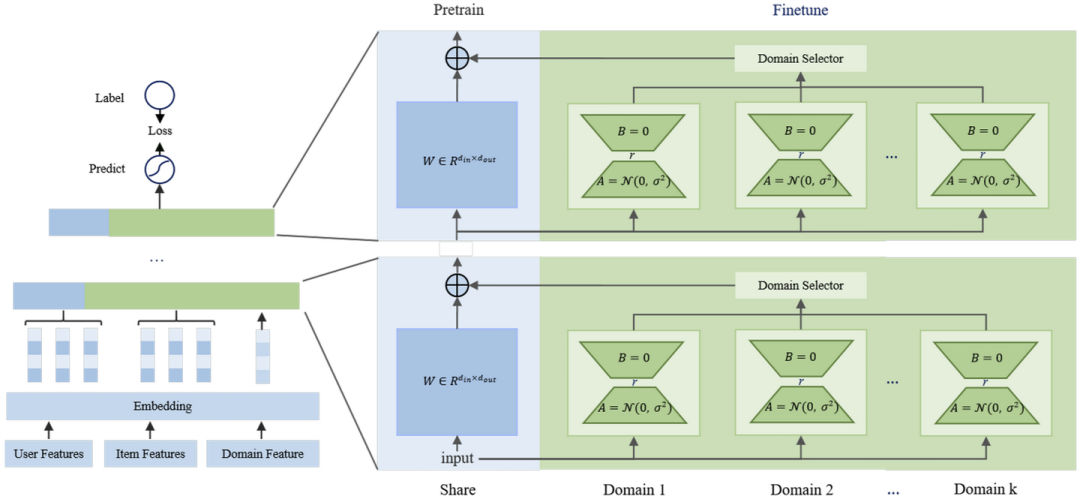
MLoRA: Multi-Domain Low-Rank Adaptive Network for Click-Through Rate Prediction
https://arxiv.org/abs/2408.08913
点击率(CTR)预测是工业界的核心任务之一,尤其在电商、社交媒体和流媒体等领域。CTR 预测直接影响网站收入、用户满意度和用户留存。然而,实际的生产平台通常涵盖多个领域,以满足多样化的客户需求。传统的 CTR 预测模型在多领域推荐场景中表现不佳,面临数据稀疏性以及跨领域数据分布差异的问题。现有的多领域推荐方法为每个领域引入特定的领域模块,虽然在一定程度上缓解了上述问题,但往往会显著增加模型参数量,导致训练不足。为此,本文提出了一种用于 CTR 预测的 多领域低秩自适应网络(MLoRA)。我们为每个领域设计了一个专门的 LoRA 模块,该方法能够提升模型在多领域 CTR 预测任务中的性能,同时可以适配于多种深度学习模型。我们在多个多领域数据集上对所提出的方法进行了评估,实验结果表明,MLoRA 方法相比现有的最先进基线模型取得了显著提升。此外,我们将其部署到实际生产环境中。在线 A/B 测试结果进一步验证了其在真实生产环境中的优越性和灵活性。
七、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 8
8 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)