【LLM论文日更】| 分而治之?你应该从哪一部分蒸馏你的LLM?
实验步骤包括:首先使用教师模型生成子问题,然后使用真实答案筛选高质量的子问题,最后使用这些子问题和真实答案来微调学生分解器模型。实验结果显示,蒸馏出的分解模型在性能和推理成本上表现优异,相比蒸馏解决能力,蒸馏分解能力更容易实现且效果更好。研究人员在多个数据集(如GSM8K、DROP和Bamboogle)上进行了实验,验证了蒸馏后的分解器在保持性能的同时,显著降低了推理成本。例如,在GSM8K数据集
- 论文:https://arxiv.org/pdf/2402.15000
- 代码:暂未开源
- 机构:密歇根大学 & Apple
- 领域:模型蒸馏
- 发表:EMNLP 2024

研究背景
- 研究问题:这篇文章要解决的问题是如何有效地分解和解决复杂推理任务,以便在大规模语言模型(LLMs)中进行更高效和灵活的推理。
- 研究难点:该问题的研究难点包括:分解任务和解决任务的复杂性、LLMs在推理过程中需要大量领域知识、以及蒸馏大型模型时性能下降的问题。
- 相关工作:该问题的研究相关工作包括:链式思维(CoT)方法、最小到最大(Least-to-Most)方法、以及直接使用LLMs进行推理的单阶段模型。
研究方法
这篇论文提出了一种将推理任务分解为问题分解阶段和问题解决阶段的方法,并展示了这种策略在性能上的优势。具体来说,
-
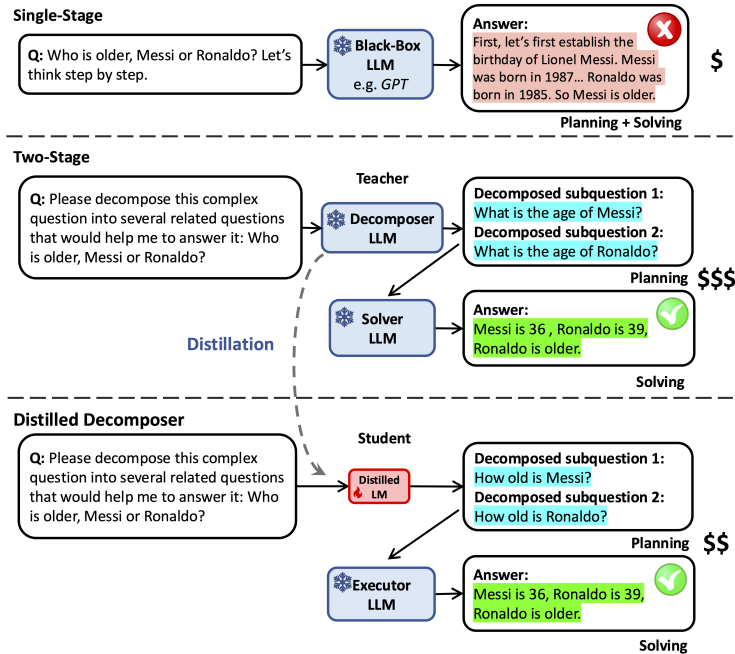
问题分解与解决的分解:首先,论文提出将复杂推理任务分解为两个独立的阶段:问题分解和问题解决。问题分解阶段涉及将复杂问题分解为更小的子问题,而问题解决阶段则涉及依次解决这些子问题以获得最终答案。
-
蒸馏分解能力:为了实现快速推理,论文提出从大型LLM中蒸馏出问题分解能力,而不是整个解决能力。具体步骤如下:
- 生成子问题:首先,使用教师模型(如GPT-3.5-turbo)生成给定问题的子问题。
- 子问题筛选:如果数据集提供了相应的真实答案,可以使用这些信息来筛选高质量的子问题。
- 学生分解器训练:使用生成的子问题和真实答案来微调一个较小的学生分解器模型(如Vicuna-13B),以学习如何分解问题。
- 静态与动态过程的比较:论文还比较了静态分解过程和动态分解过程的效果。静态分解过程将规划和问题解决分开,而动态分解过程则依赖于前一个步骤的结果。


蒸馏方法
1. 收集教师模型的演示
首先,从教师模型(T)收集演示数据。这些演示数据是通过向教师模型提供分解指令(Idecomp)和原始问题(Q),要求教师模型生成一组子问题({Si})而不是直接解决问题。
分解指令(Idecomp)示例:
Your task is to break down a given complex question into the most relevant and helpful subquestions, ensuring that no more than three subquestions are formulated for each question. Both the context and the main question will be provided to you. If the question does not need breaking down to be answered, return “No decomposition”; otherwise, list the necessary subquestions. Only return subquestions that directly aid in answering the original question, avoiding any that could be harmful or unhelpful.2. 使用蒸馏优化学生模型
接下来使用这些子问题来微调一个较小的学生模型(S)。通过优化交叉熵损失函数,使得学生模型能够生成与教师模型相似的子问题集合。这个过程可以表示为:
S(Idecomp,Q)→{Si}3. 子问题的筛选(可选)
如果数据集提供了真实答案(A),研究人员可以选择性地使用这些答案来筛选高质量的子问题。具体方法是再次使用教师模型,但这次是要求它通过解决子问题来解决原始问题。通过这种方式,研究人员可以收集教师模型生成的答案(A^),并使用这些答案来筛选出那些有助于解决问题的子问题。
解决指令(Ians)示例:
Solve a complex question by answering several related subquestions that would help me to answer it first. Answer the subquestions one by one and finally solve the original question. The final answer is supposed to attached in the end in the format of “The answer is:”.4. 训练学生分解器
通过上述步骤,研究人员得到了一个经过蒸馏的学生分解器(SD)。这个学生分解器可以在推理过程中替代教师模型,从而降低推理成本。
5. 实验验证
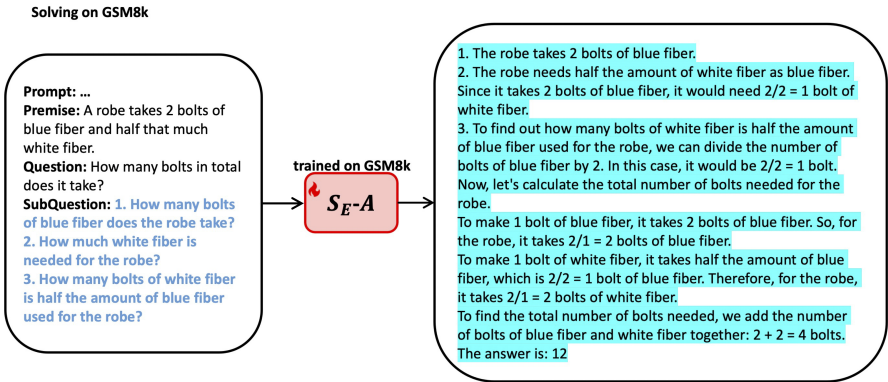
研究人员在多个数据集(如GSM8K、DROP和Bamboogle)上进行了实验,验证了蒸馏后的分解器在保持性能的同时,显著降低了推理成本。例如,在GSM8K数据集上,使用蒸馏后的Vicuna-13B模型作为分解器,相比使用原始GPT模型,推理成本降低了约70%。
总结
通过上述步骤,论文展示了如何有效地从大型语言模型中蒸馏出分解能力,并将其应用于推理任务中,以实现更高效的推理和成本控制。
实验设计
- 数据集:实验使用了三个不同的数据集:GSM8K(数学推理)、DROP(阅读理解)和Bamboogle(复杂问题)。
- 教师/学生模型:使用GPT-3.5-turbo作为教师模型,并使用不同的学生模型(如Vicuna-13B和Mistral-7B)进行实验。
- 训练细节:使用批量大小为128,分别在GSM8K和Bamboogle数据集上训练5个周期,在DROP数据集上训练3个周期。蒸馏训练的学习率2⋅10−5。
- 推理成本估计:基于GPT-3.5-turbo-1106的推理成本进行估计,计算1000个输入令牌和输出令牌的推理成本。
结果与分析
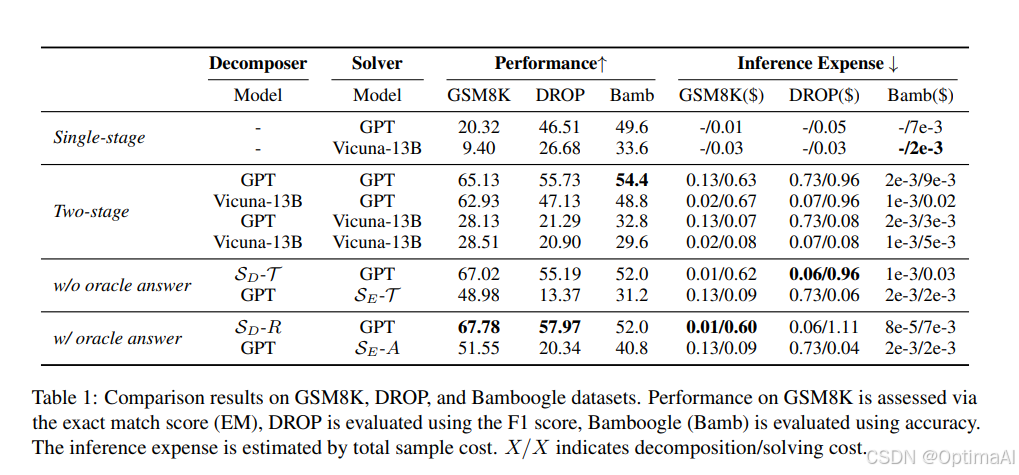
这篇论文探讨了将大型语言模型(LLM)的推理任务分解为分解和求解两个阶段,并分别对其进行蒸馏的可能性。以下是对论文实验结果的分析:
分解能力的重要性
实验结果表明,分解能力对于复杂的推理任务至关重要。表1显示,使用两阶段模型(静态策略)的性能普遍优于单阶段模型。这表明分解和求解的分离可以提高整体性能。
蒸馏分解能力的可行性
表1还显示,使用蒸馏后的分解器(SD-T)替换原始分解器(如GPT或Vicuna)时,性能至少与原始模型相当,甚至在某些情况下有所提升。这证明了蒸馏分解能力是可行的,并且蒸馏后的模型在推理成本上有显著优势。
分解能力的泛化性
表3和表4显示,蒸馏后的分解器在不同领域和不同求解器上的表现良好。具体来说,SD-R在GSM8K和DROP数据集上的表现接近甚至超过了原始教师模型(GPT)。此外,较弱的求解器在使用蒸馏分解器后,性能提升更为显著,这表明分解器的泛化性较强。
动态与静态分解的比较
表6比较了动态和静态分解方法在Bamboogle和GSM8K数据集上的表现。结果显示,静态分解方法的性能更好,且推理成本显著低于动态方法。这表明静态分解方法在实际应用中更具优势。
分解对求解能力的影响
表7显示,专注于学习分解能力的模型在求解其他任务时的表现显著下降。这表明单独训练分解能力可能会损害模型的整体求解能力,强调了分解和求解分离的重要性。
真实答案对蒸馏效果的影响
表1显示,当有真实答案可用时,蒸馏后的分解器(SD-R)和求解器(SE-A)在某些数据集上的表现超过了原始教师模型。这表明真实答案可以进一步提升蒸馏模型的性能。
总体结论
这篇论文通过对LLMs的推理任务进行细粒度的分析,提出了分解和解决能力分离的策略,并验证了其有效性。研究表明,分解能力比解决能力更容易蒸馏,且蒸馏出的分解模型具有良好的泛化能力。未来的研究方向包括训练通用分解器模型以及使用强化学习进一步提升分解器的性能。
论文评价
优点与创新
- 分解能力的重要性:论文展示了分解能力在复杂推理任务中的重要性,并证明了这种能力可以从问题解决能力中分离出来。
- 分解能力的蒸馏可行性:论文验证了仅从教师模型中蒸馏查询分解能力的可行性,且结果模型在保持大部分性能的同时显著降低了推理成本。相比之下,蒸馏问题解决组件导致性能显著下降。
- 良好的泛化能力:论文展示了蒸馏的查询分解模型在不同任务、数据集和模型上的良好泛化能力。然而,蒸馏的问题解决能力泛化效果较差。
- 静态分解和解决框架的优势:论文证明了静态分解和解决框架相比动态方法的优势,后者在规划和解决步骤之间存在相互依赖。
- 跨领域评估:论文通过在DROP和GSM8K数据集上进行交叉领域评估,展示了蒸馏的分解器在不同领域的适用性和泛化能力。
不足与反思
- 假设条件:论文基于几个假设,包括教师模型能够有效分解查询、学生模型有能力从教师模型中学习蒸馏的规划,以及所涉及的任务需要长远的规划能力。如果这些假设不成立,论文提出的方法的有效性可能会受到影响。
- 评估范围有限:论文仅在数学和问答方面评估了模型的有效性。为了全面完成任务,需要在更广泛的规划任务范围内进行评估,包括工具使用、LLM代理和多轮决策等基准测试。
- 未来工作方向:未来的研究方向包括训练通用分解器模型,利用来自各种任务的数据,以及探索使用强化学习进一步增强分解器,利用解决器的输出信号。另一个可能的方向是评估该方法在其他长期规划任务中的有效性,如LLM驱动的代理、工具使用和多轮决策。
关键问题及回答
问题1:论文中提出的静态分解过程和动态分解过程在推理性能和成本上有什么区别?
静态分解过程将推理任务分解为两个独立的阶段:问题分解和问题解决。在静态分解过程中,模型先生成一组子问题,然后依次解决这些子问题以获得最终答案。这种方法的优势在于其计算效率较高,因为每个阶段的计算可以独立进行。实验结果表明,静态分解过程在推理成本和性能上优于动态分解过程。动态分解过程则依赖于前一个步骤的结果,生成每个子问题时都考虑前一个子问题的答案。虽然动态分解在某些特定任务中可能更有效,但它在推理成本和性能上显著高于静态分解过程。
问题2:论文中如何评估蒸馏分解能力的效果?具体使用了哪些数据集和模型?
论文通过在三个不同的数据集(GSM8K、DROP和Bamboogle)上进行实验来评估蒸馏分解能力的效果。具体来说,使用GPT-3.5-turbo作为教师模型,并采用不同的学生模型(如Vicuna-13B和Mistral-7B)进行实验。实验步骤包括:首先使用教师模型生成子问题,然后使用真实答案筛选高质量的子问题,最后使用这些子问题和真实答案来微调学生分解器模型。实验结果显示,蒸馏出的分解模型在性能和推理成本上表现优异,相比蒸馏解决能力,蒸馏分解能力更容易实现且效果更好。
问题3:论文中提到的分解能力在泛化性方面表现如何?与解决能力相比有何优势?
论文中的实验结果表明,蒸馏出的分解模型在不同任务、数据集和求解器上表现出良好的泛化能力。具体来说,蒸馏分解模型在GSM8K、DROP和Bamboogle数据集上的表现均优于蒸馏解决能力。此外,分解能力在泛化性方面的优势在于其更少的领域依赖性。分解能力主要依赖于语义理解和查询解析,而不需要大量的领域知识,因此更容易从一个任务或数据集中蒸馏出来并在其他任务或数据集上应用。相比之下,解决能力需要大量的领域知识和记忆,因此蒸馏出的解决能力在泛化性方面表现较差。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)