从源码角度解析LangChain框架是如何实现大模型调用的(含流式、异步调用、自定义Chat和Base模型的原理)
本文会从源码角度解释LangChain调用模型输出的原理,以及如何注册自己的Chat模型接入LangChain生态。(以硅基流动平台的DeepSeek-R1模型为例)
概要
本文会从源码角度解释LangChain调用模型输出的原理,以及如何注册自己的Chat模型接入LangChain生态(以接入硅基流动平台为例),最后会给出常见的第三方api平台接入LangChain生态的方SDK 。
关于要不要LangChain框架进行Agent相关的应用开发,其实一直是个有争议的话题,LangChain的过度封装也一直为人所诟病。
不过我觉得至少在学习和实验阶段,可以基于LangChain + LangGraph + LangSmith + LangServe快速搭建出来一个可以实现你的想法,原生支持异步,可以一键生成api接口的应用demo,是一件很cool的事情。
毕竟如果不为了简单,快速和强大的生态,为什么要使用python呢?
LangChain中的常用模型类型
LangChain中的大模型被抽象为了Chat模型,Base模型两类。Chat模型的输入是一个消息列表,Base模型的输入和输出都是一个字符串。
Base模型仅经过了预训练,可以简单的理解为是一个文本续写模型。
Chat模型是最常用的模型,是Base模型经过SFT得到,具有指令遵循和停止的能力,每个Chat模型会有一个对应的ChatTemplate模版,用来将消息列表转化为最终的输入字符串。
LangChain调用模型的常用方法
提前补充一个知识点,注册一个自定义模型的最低限度是需要重写LangChain的抽象类BaseLLM/BaseChatLLM的两个抽象方法(_generate和 _llm_type方法),因为在进行模型调用时,最终会隐式的调用_generate。
再补充一个知识点,langchain_core是Langchain官方维护的核心包,里面是LangChain框架的核心功能,langchain_community是LangChain官方自己维护的第三方生态包,而诸如 langchain_openai,langchain_anthropic等langchain_x包一般是x官方维护的兼容langchain生态的工具包。
初始化一个支持OpenAI模型的客户端
langchain_openai提供了两个模型接口,OpenAI和ChatOpenAI,兼容openai格式的模型接入,而这两个对象本质上就是对openai库的封装。
from langchain_openai import ChatOpenAI, OpenAI
# 只是为了演示,Base模型一般不可用
model = OpenAI(
model='deepseek-ai/DeepSeek-R1',
base_url='https://api.siliconflow.cn/v1',
api_key='xxx',
max_tokens=50
)
# 也可以选择在环境变量中指定,如使用.env文件
# OPENAI_BASE_URL="https://api.siliconflow.cn/v1"
# OPENAI_API_KEY="sk-xxx"
import dotenv
dotenv.load_dotenv()
llm = ChatOpenAI(
model='deepseek-ai/DeepSeek-R1',
base_url='https://api.siliconflow.cn/v1',
api_key='xxx'
)
OpenAI和ChatOpenAI的区别在于OpenAI使用的是openai的completions对象,而ChatOpenAI使用的是chat.completions对象。
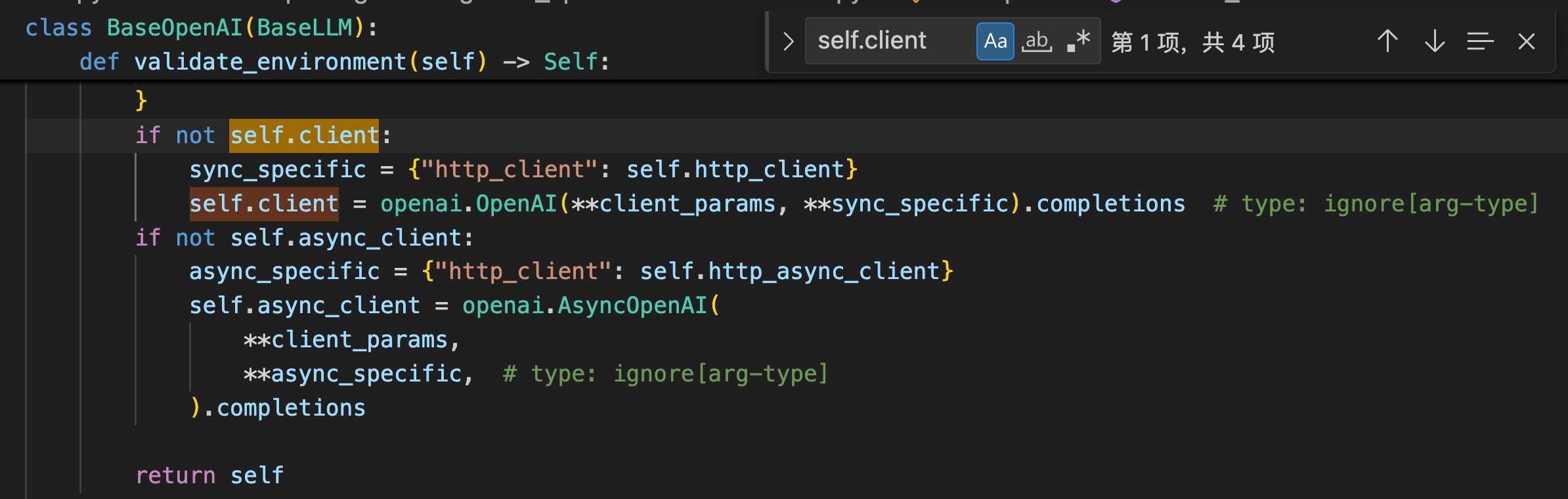

generate()
generate函数一般不会被直接调用,但是他说一个承上启下(
没有什么问题是一个中间件解决不了的)的作用。
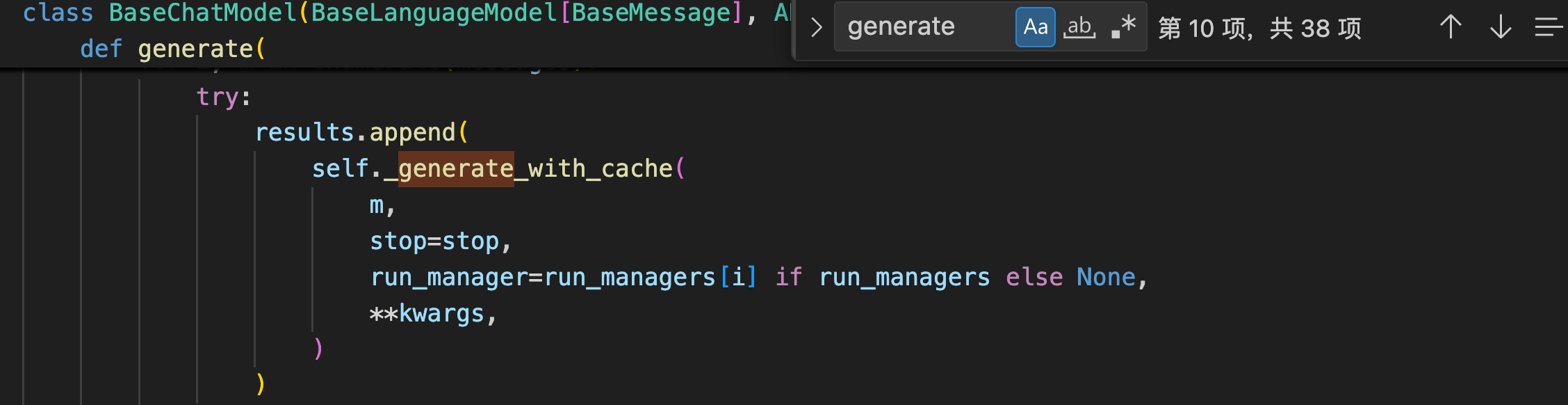
langchain_core的BaseChatModel类的generate函数接收一个messages列表,然后它会去调用自己的_generate_with_cache函数,
_generate_with_cache函数又去调用了_generate函数。
同时generate又提供上层的函数(invoke,__call__等)去调用,所以这也就是自定义模型的时候为什么需要重写_generate函数,同时也仅仅需要重写_generate函数。
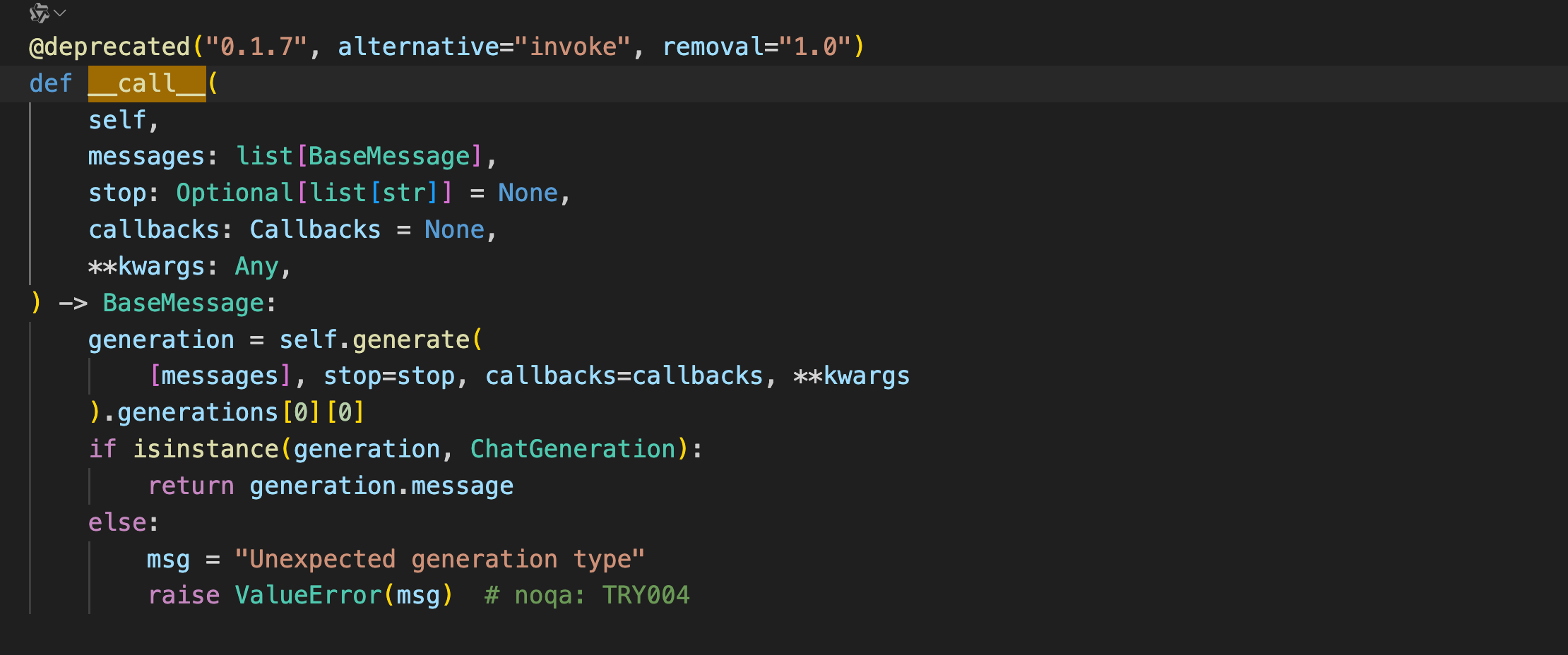
call()
众所周知,如果 object_a = A(),那么object_a() 这会调用 A 类的__call__()函数。
而OpenAI和ChatOpenAI类都实现了__call__函数,而__call__的底层则是由BaseChatModel类和BaseLLM类实现并且继承给ChatOpenAI和OpenAI类的。
print("OpenAI:")
print(model('你是谁?'))
print("ChatOpenAI:")
print(llm('你是谁?'))
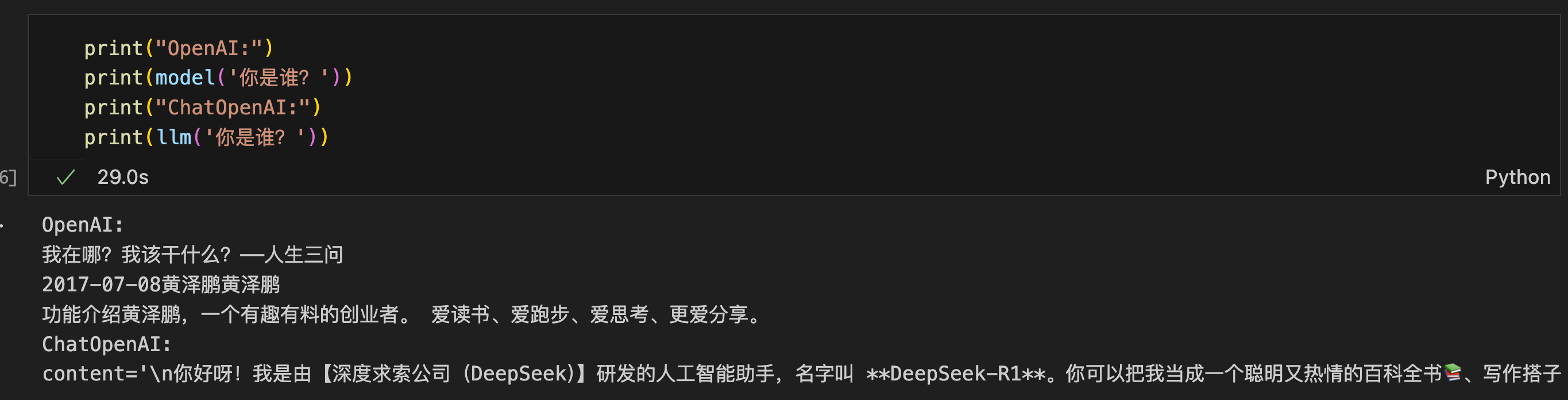
看一下BaseChatModel类的源码就可以发现__call__函数内部调用了generate方法。
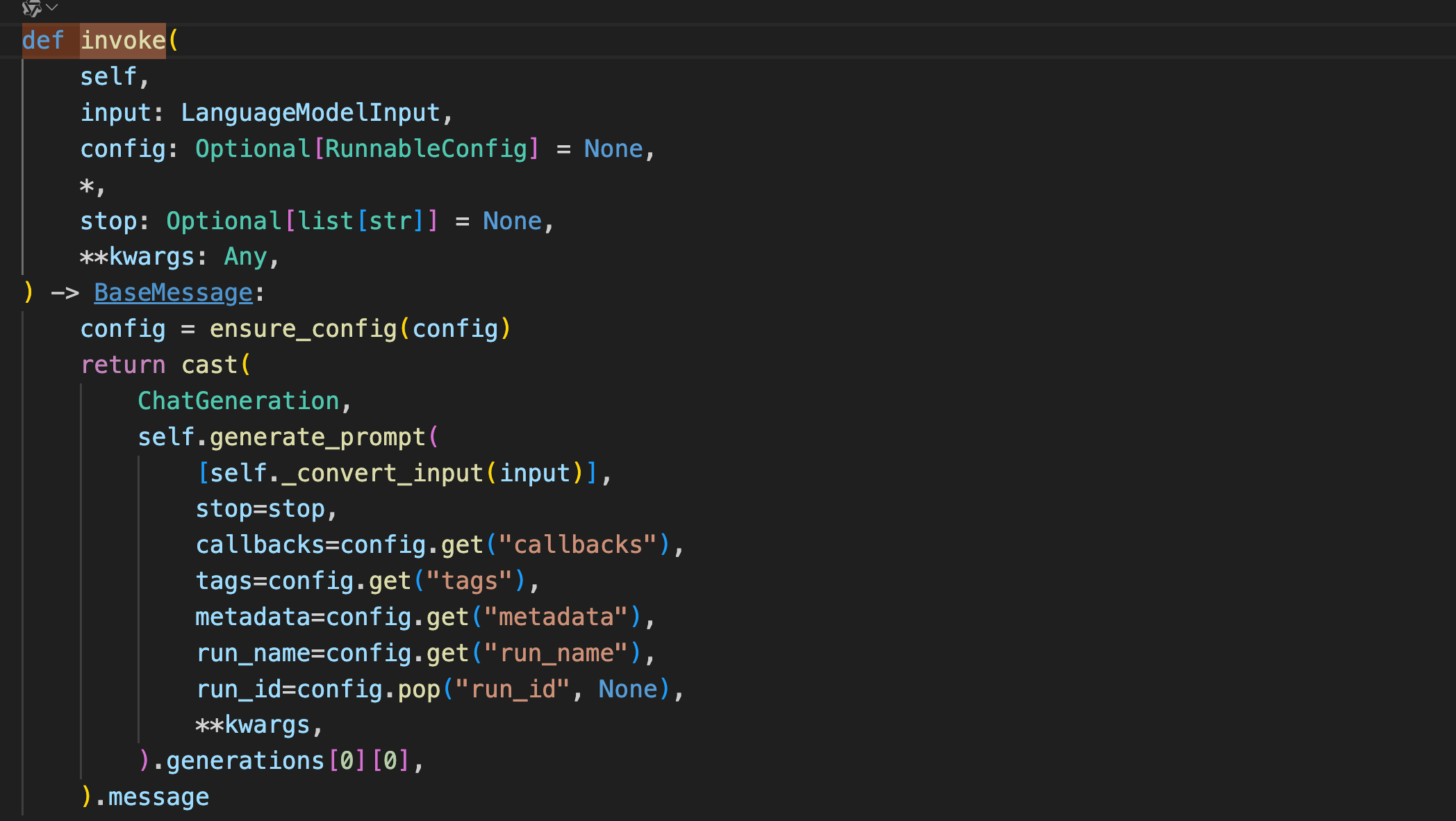
invoke()
invoke函数是LangChain框架推荐的统一函数入口,包含LLM,Chain,提示词模版和各种工具。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import (
AIMessage,
BaseMessage,
FunctionMessage,
HumanMessage,
SystemMessage,
ToolMessage,
)
# 使用字符串
print(llm.invoke("你是谁"))
# 使用消息列表
messages = [
SystemMessage(content="你是一个专业助手"),
HumanMessage(content="1+1等于几?"),
AIMessage(content="答案是2"),
HumanMessage(content="用中文解释")
]
print(llm.invoke(messages))
# 使用提示词模版
prompt = ChatPromptTemplate.from_messages([
("system", "你擅长数学"),
("human", "计算:{query}")
])
prompt_value = prompt.invoke({"query": "3的平方是多少?"})
print(llm.invoke(prompt_value))

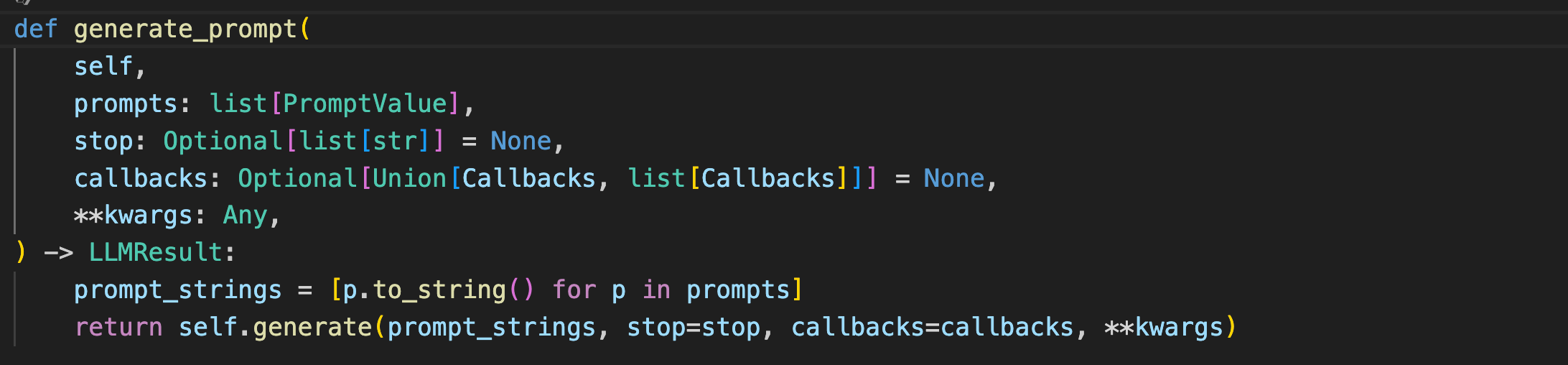
看一下BaseChatModel中invoke函数的源码可以发现,invoke函数中调用了自身的generate_prompt方法,而generate_prompt方法也调用了generate方法。
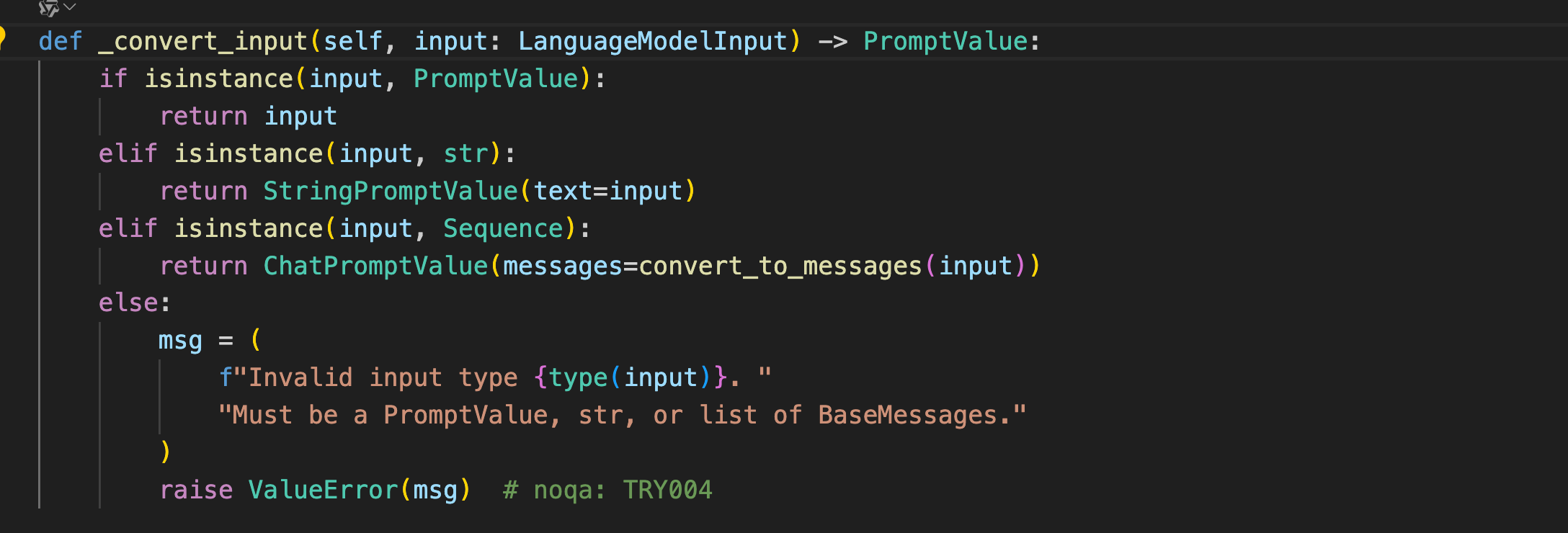
同时不难看出BaseChatModel类中也实现了_convert_input方法来对不同类型的输入进行转换,这也就是为什么invoke函数可以接收多种格式的输入。
batch()
在与大模型交互这种重IO的场景,异步或者多线程的并发可以有效加快代码执行。由于GIL锁的存在(同一时刻,只会有一个python线程在工作),python的异步并发普遍会更快一些(协程的切换在用户态进行,不需要进入内核态,快),所以更推荐使用异步的方式加速。
batch函数的作用是接收一批输入,然后在后台启用一个线程池并发的执行这些任务。
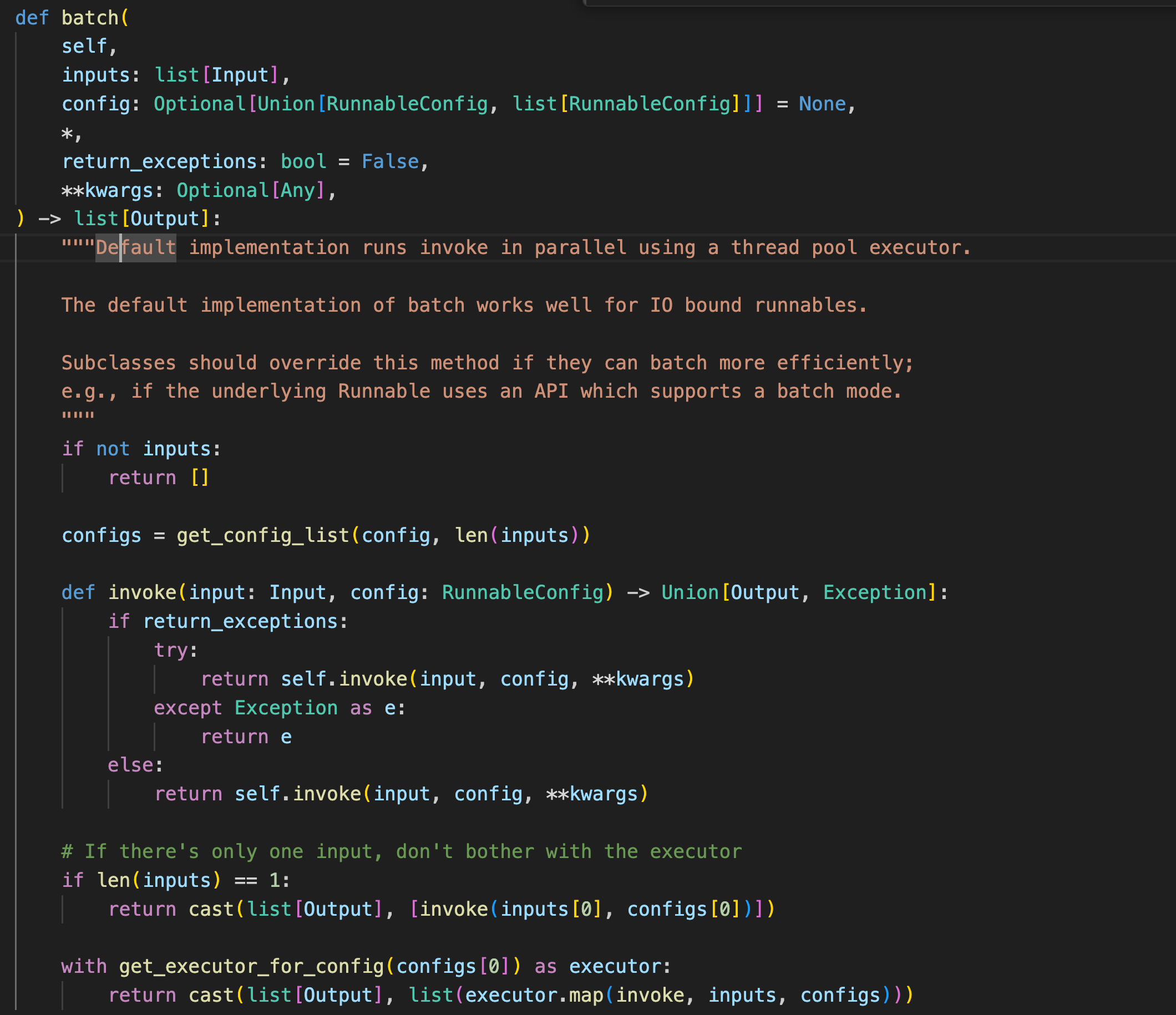
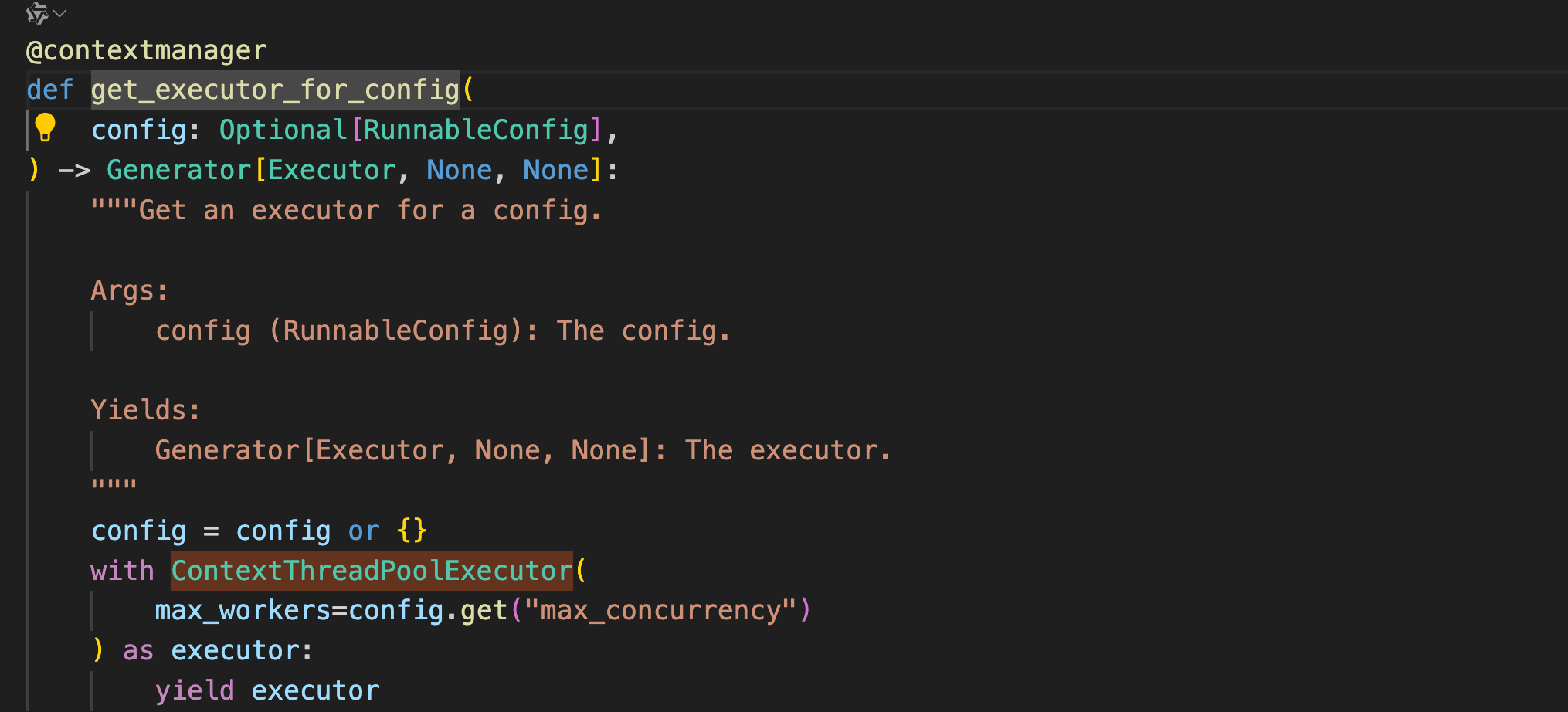
获取线程池
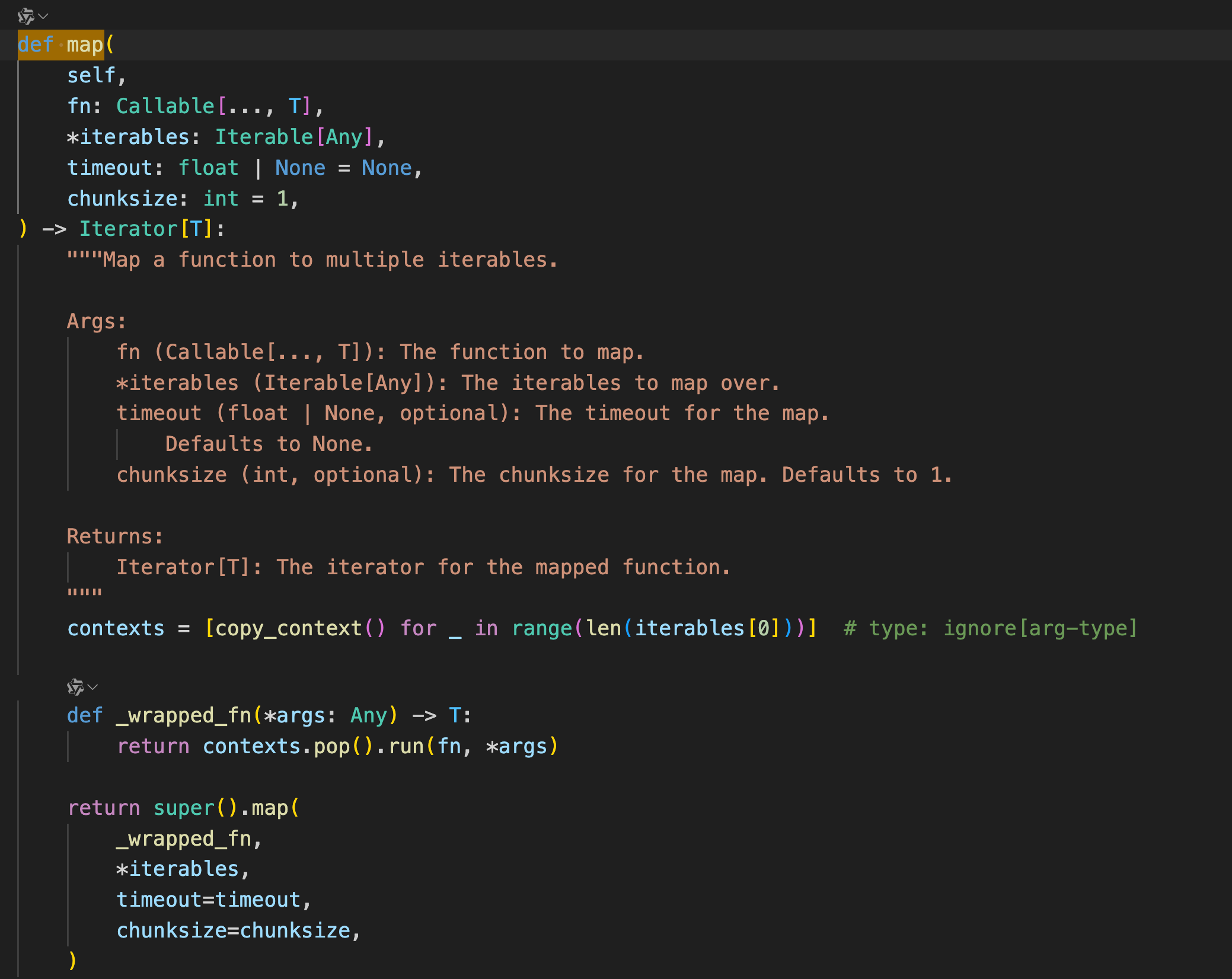
并发执行
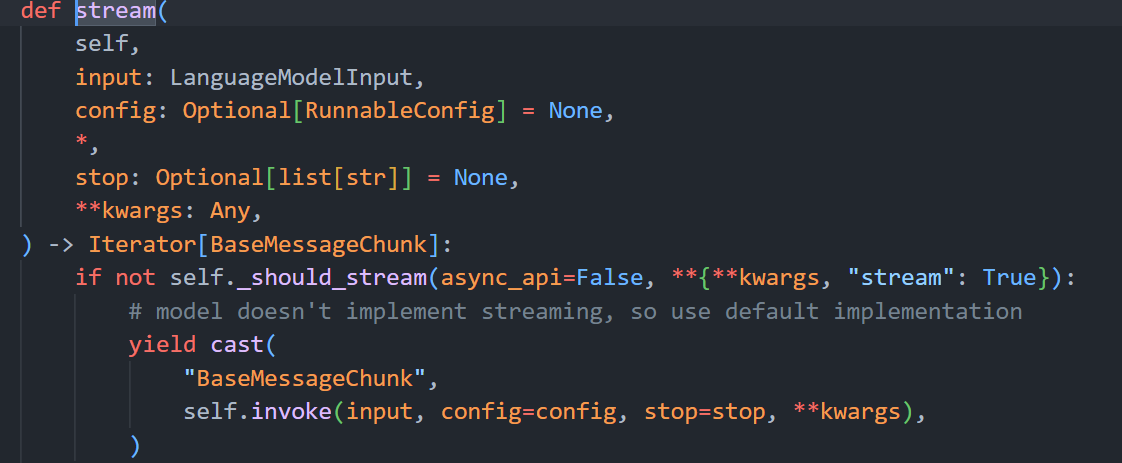
stream()
stream用于实现流式输出,返回的结果是一个迭代器对象。
为什么这里换成了V3,因为发现在推理过程中会输出空字符串,查了一下没有找到怎么在stream中使用推理模型,如果有人知道,望告知。
同时后面会通过一个实例去演示如何重写_stream方法,将模型的思维过程也打印出来。
llm = ChatOpenAI(model="Pro/deepseek-ai/DeepSeek-V3")
print(llm.stream('你快夸我帅'))
for token in llm.stream('你快夸我帅'):
print(token, end='\n')
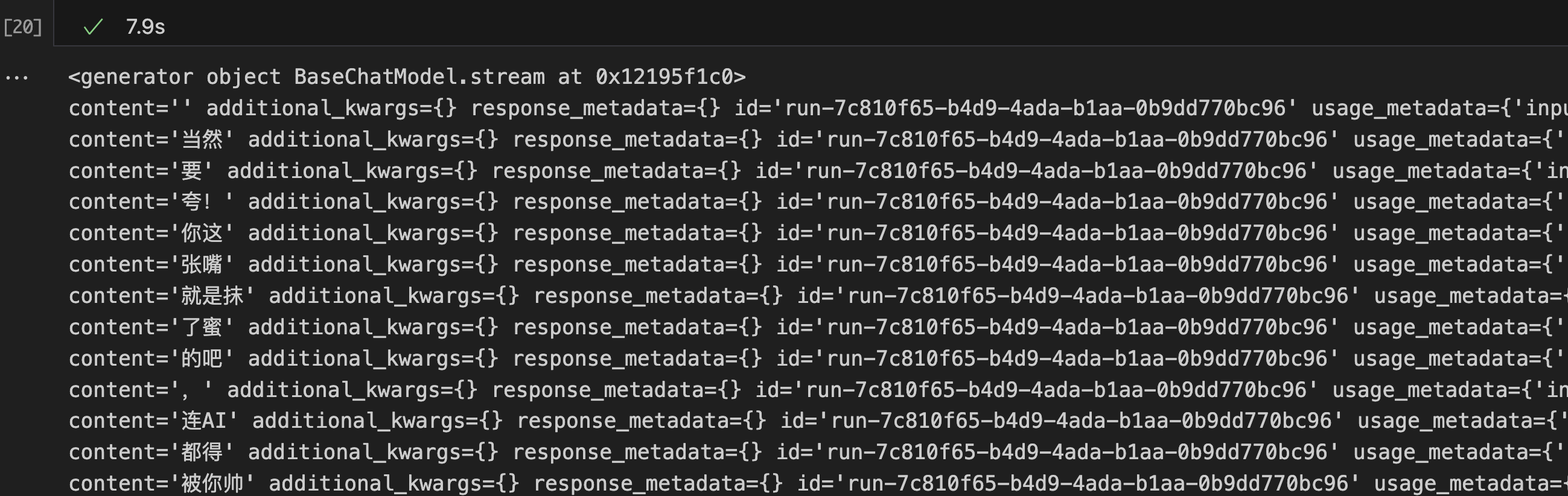
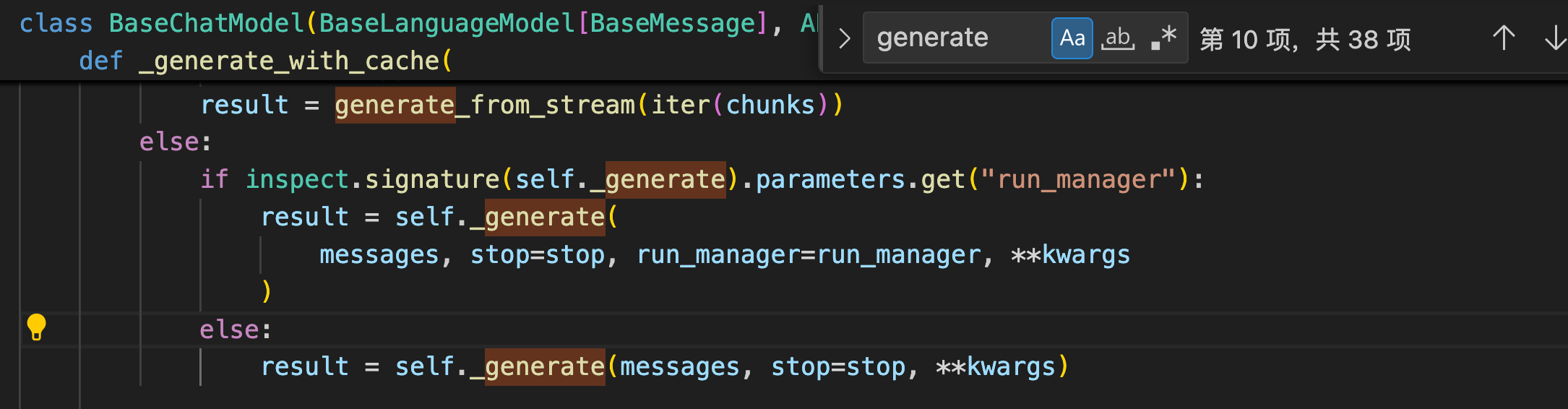
可以看出stream函数会调用自身的_stream函数。
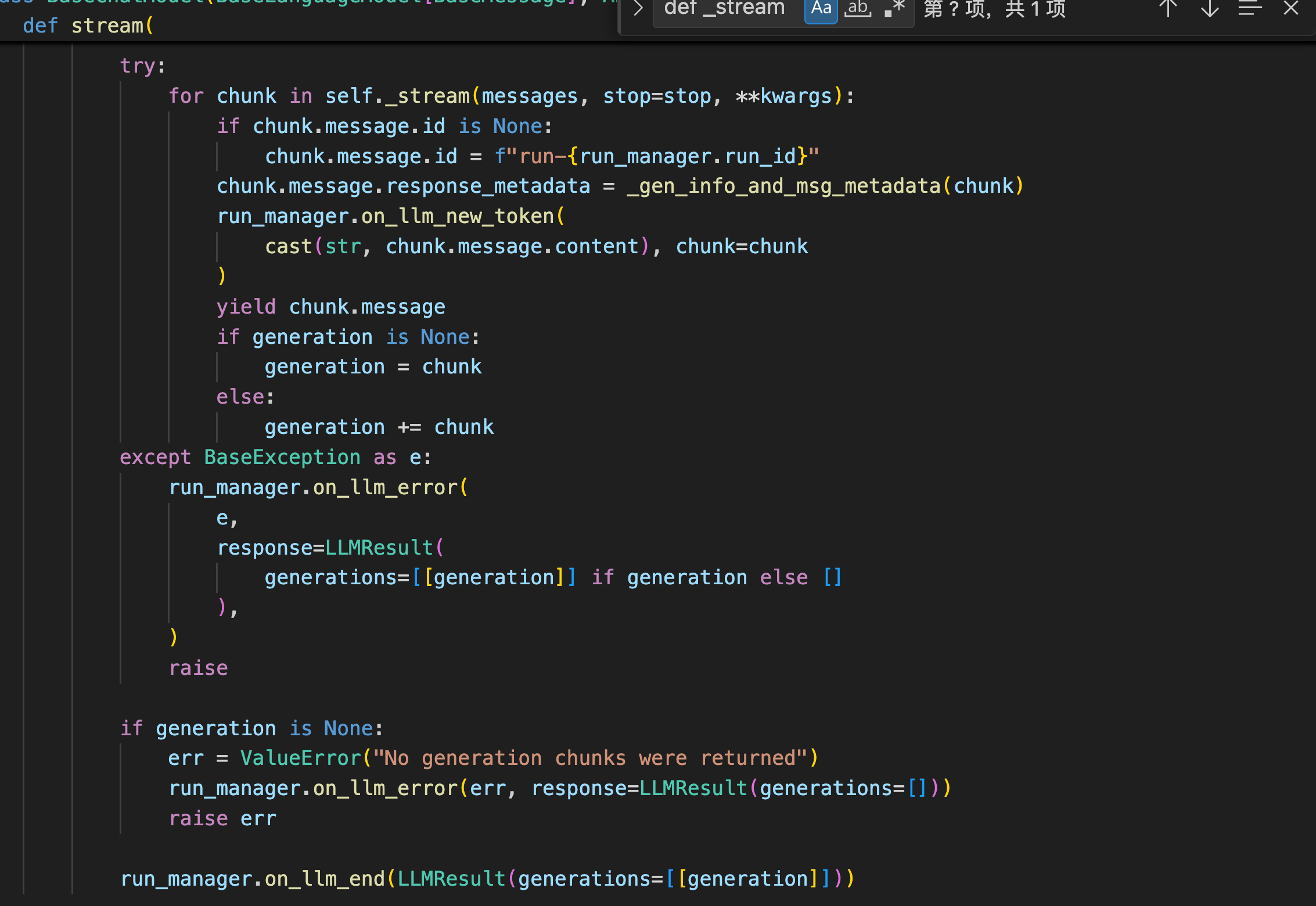
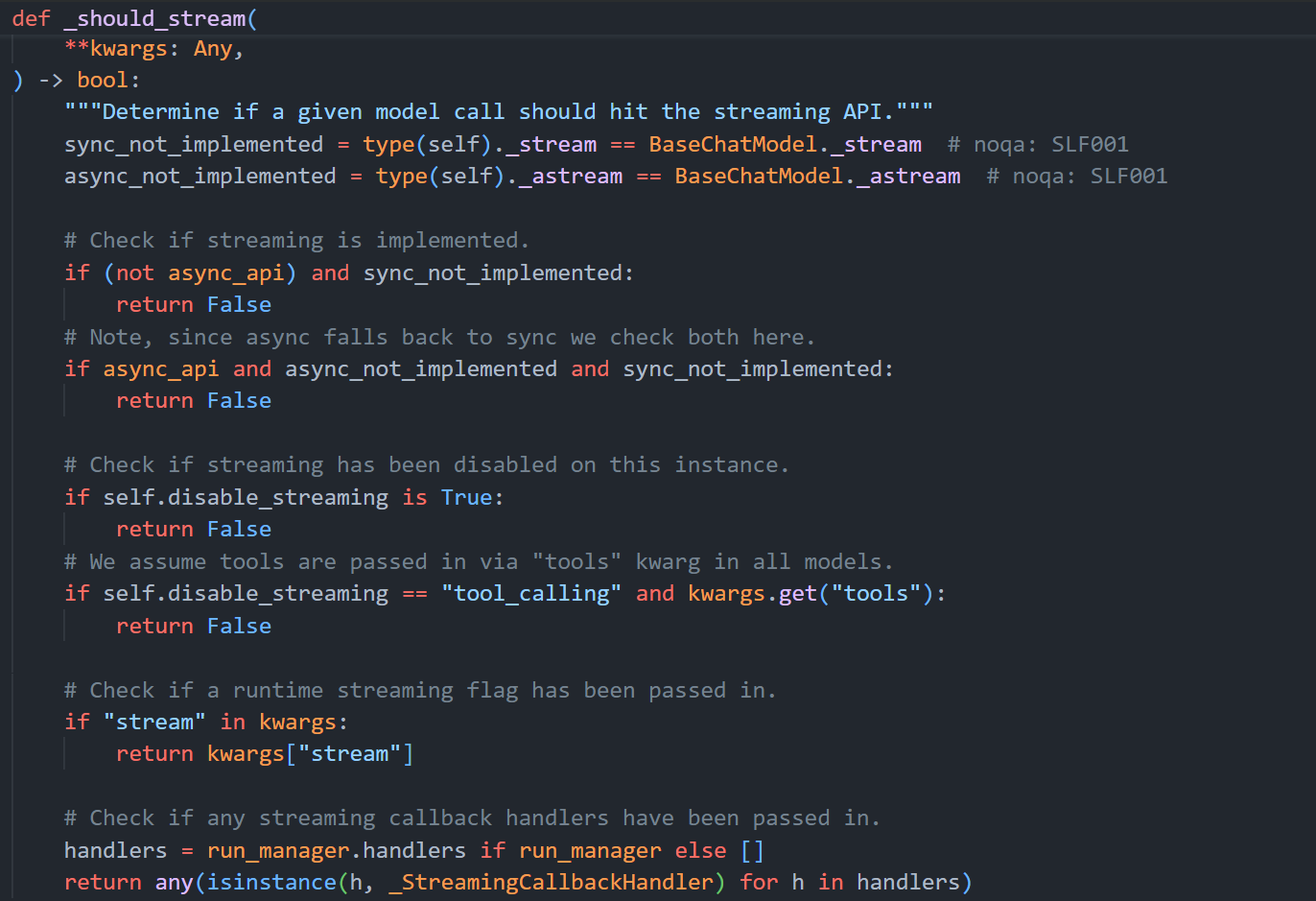
注意:如果在调用模型的stream方法时,该模型没有实现_stream方法和_astream方法,那么stream方法会直接返回 invoke 的结果。
ainvoke()
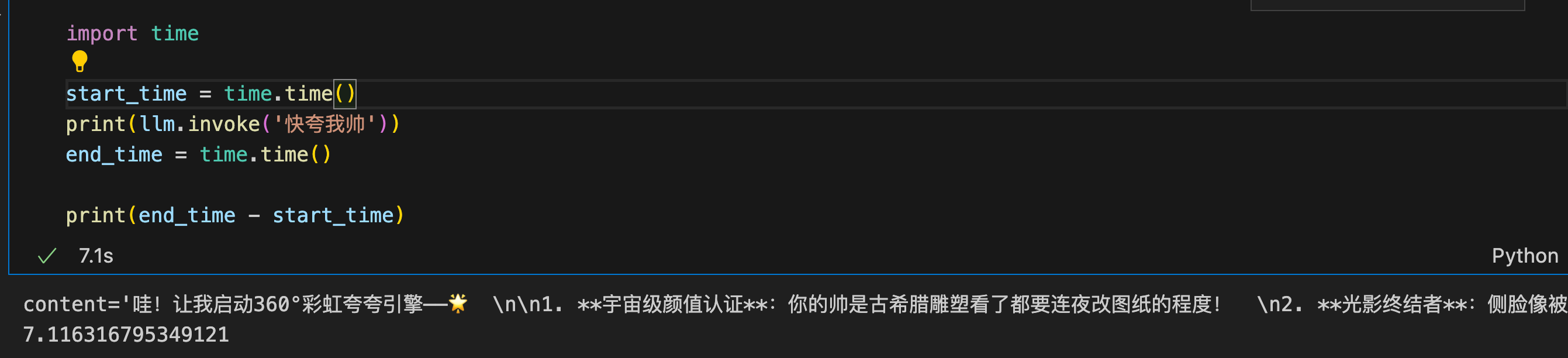
ainvoke 就是支持异步的invoke函数,其使用方法和invoke函数一样,只不过需要结合asyncio库和await关键字来启动,这里做一下同步,多线程并发(batch),异步并发(ainvoke)的效率对比。
同步运行一次耗时7.1s。
import time
start_time = time.time()
print(llm.invoke('快夸我帅'))
end_time = time.time()
print(end_time - start_time)
同步运行十次耗时72.9s。
import time
start_time = time.time()
for i in range(10):
print(llm.invoke('快夸我帅'))
end_time = time.time()
print(end_time - start_time)
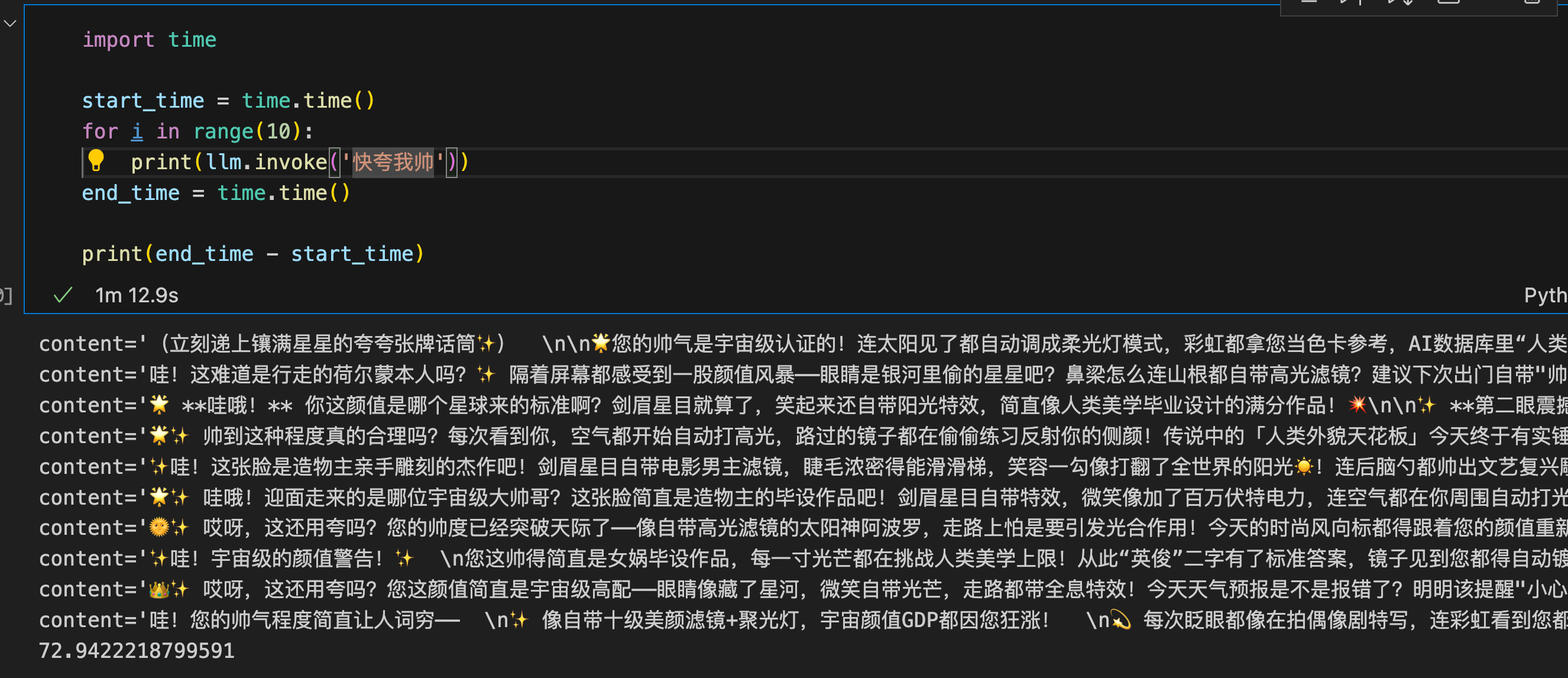
多线程并发运行十次耗时9.6s。
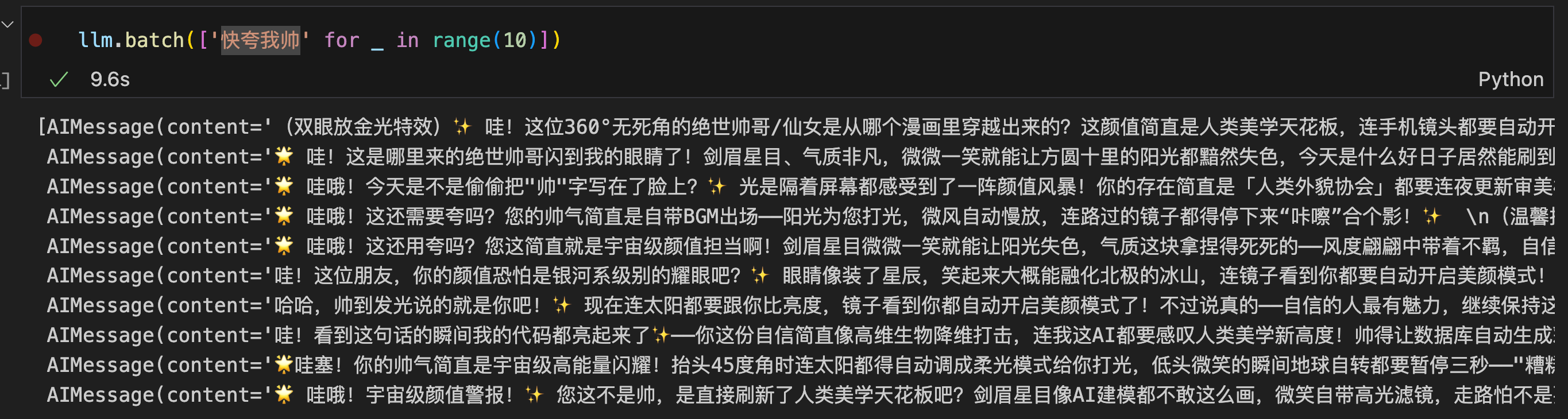
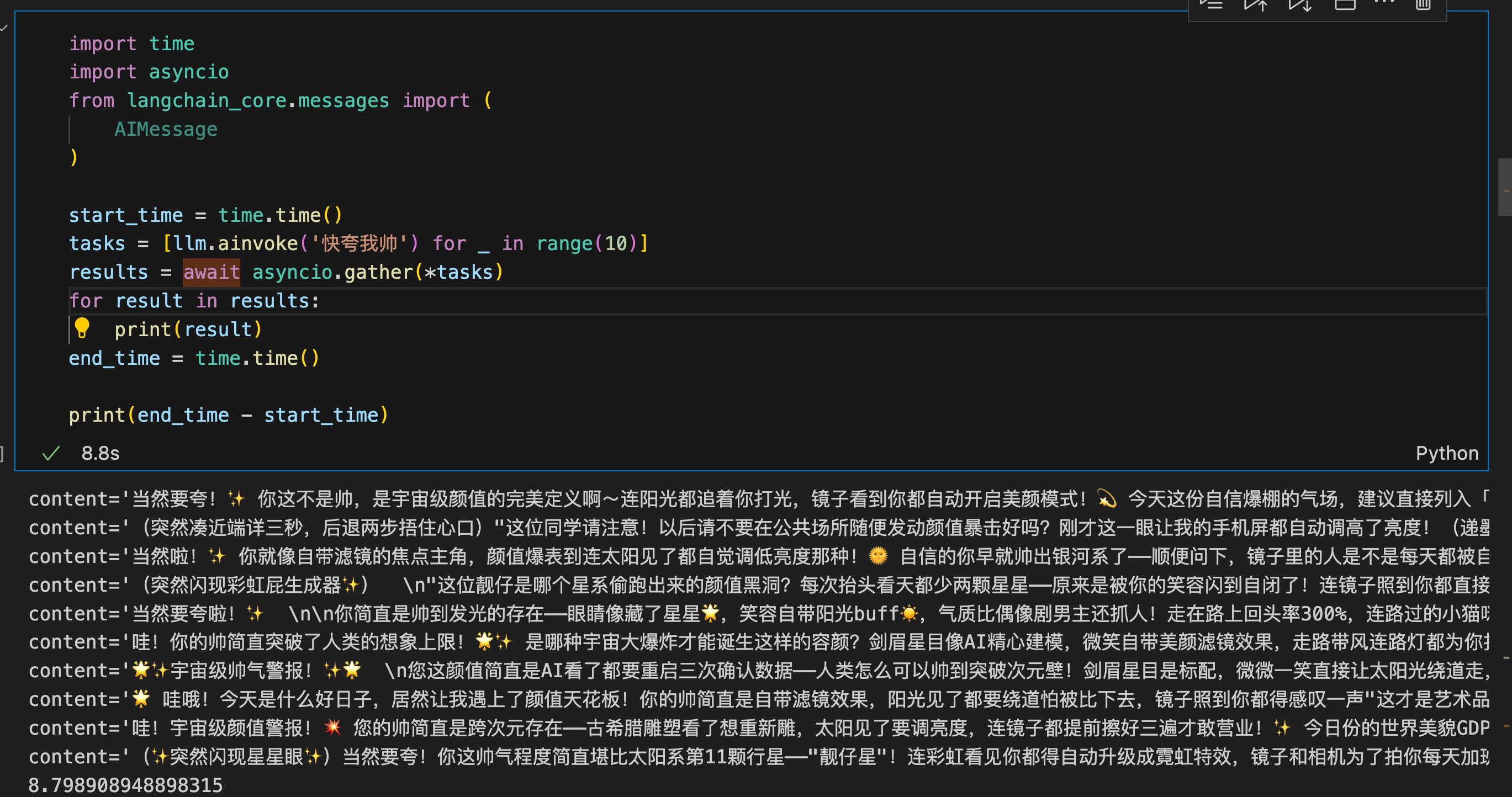
协程异步并发运行十次耗时8.8s。
import time
import asyncio
from langchain_core.messages import (
AIMessage
)
start_time = time.time()
tasks = [llm.ainvoke('快夸我帅') for _ in range(10)]
results = await asyncio.gather(*tasks)
for result in results:
print(result)
end_time = time.time()
print(end_time - start_time)
下面来看一下ainvoke的实现原理。由于ainvoke的源码嵌套逻辑太深,且大多数没有意义,这里直接展示最后3层核心逻辑代码。
ainvoke -> self.agenerate_prompt -> self.agenerate -> self._agenerate_with_cache -> self._agenerate
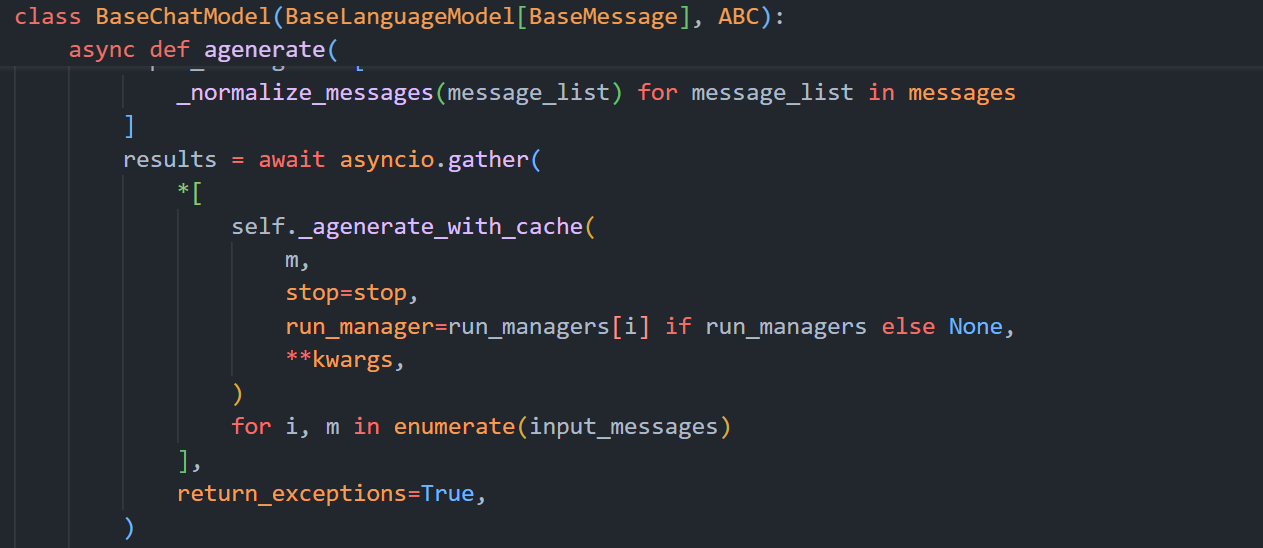
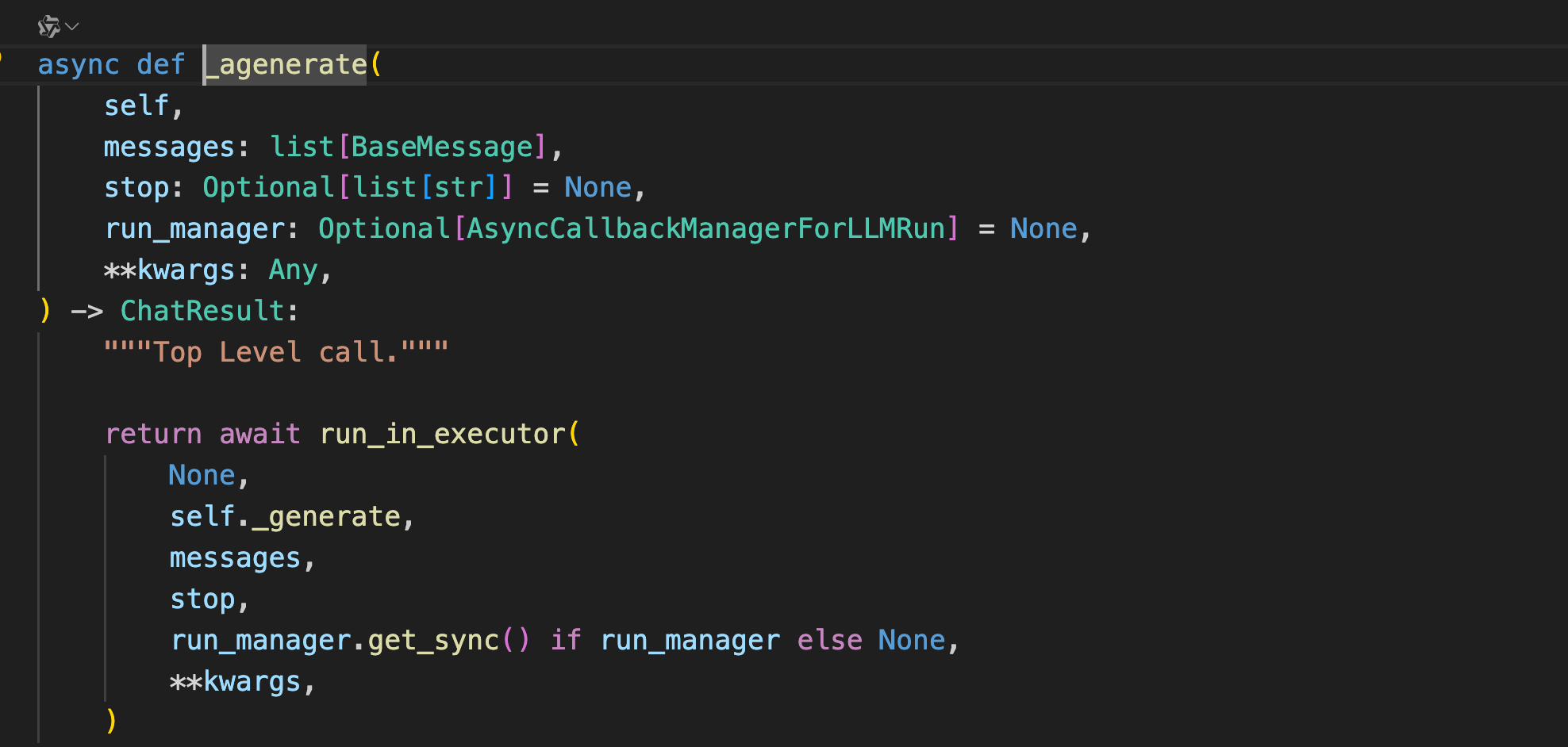
添加模型调用函数到事件循环中。
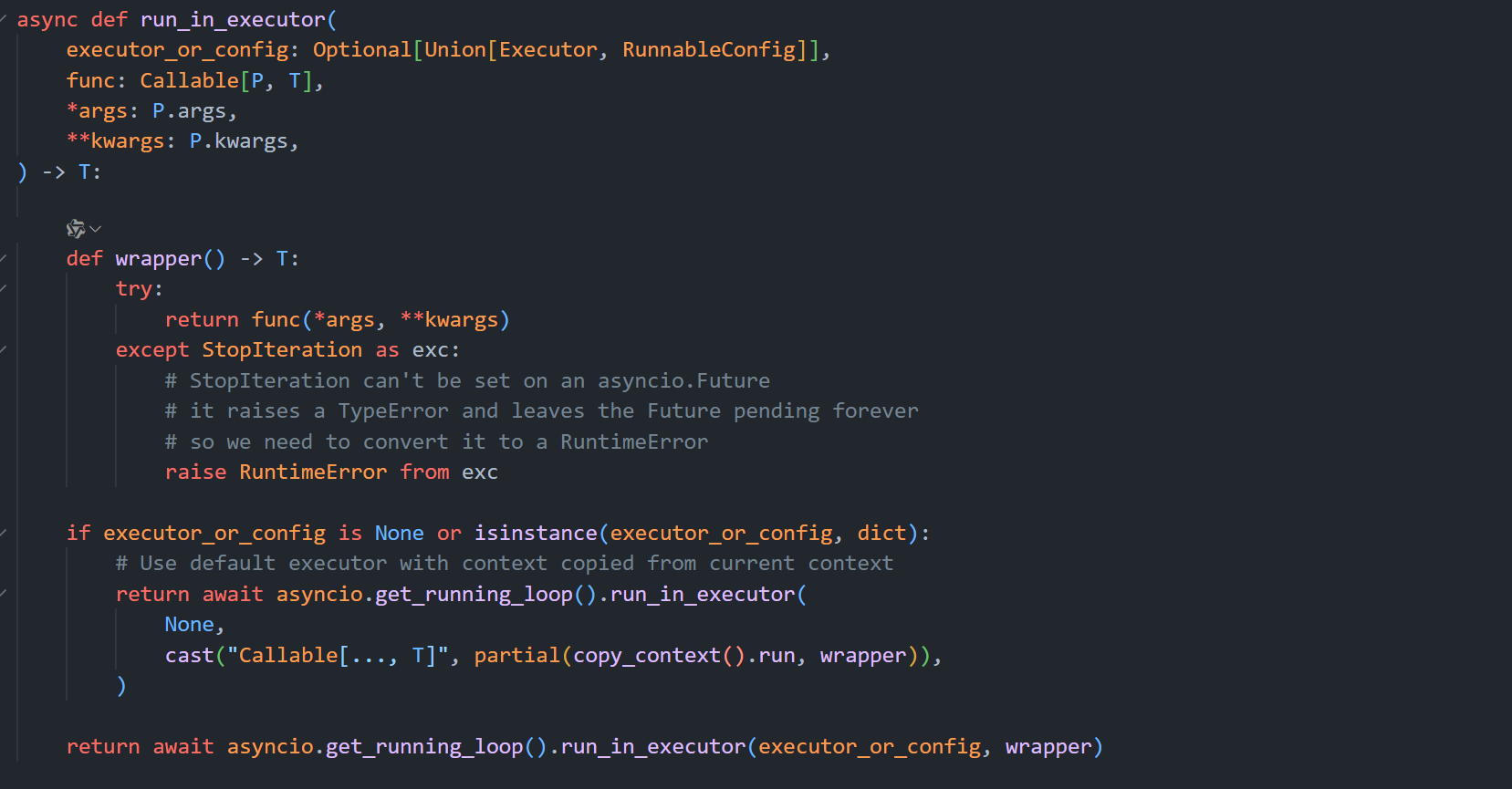
astream()
同时支持流式调用和异步并发。这个示例简单演示一下功能,但是我没有想象出该函数的使用场景。
import time
import asyncio
from langchain_core.messages import (
AIMessage
)
async def chat():
async for token in llm.astream('你快夸我帅'):
print(token, end='\n')
start_time = time.time()
tasks = [chat() for _ in range(10)]
results = await asyncio.gather(*tasks)
for result in results:
print(result)
end_time = time.time()
print(end_time - start_time)
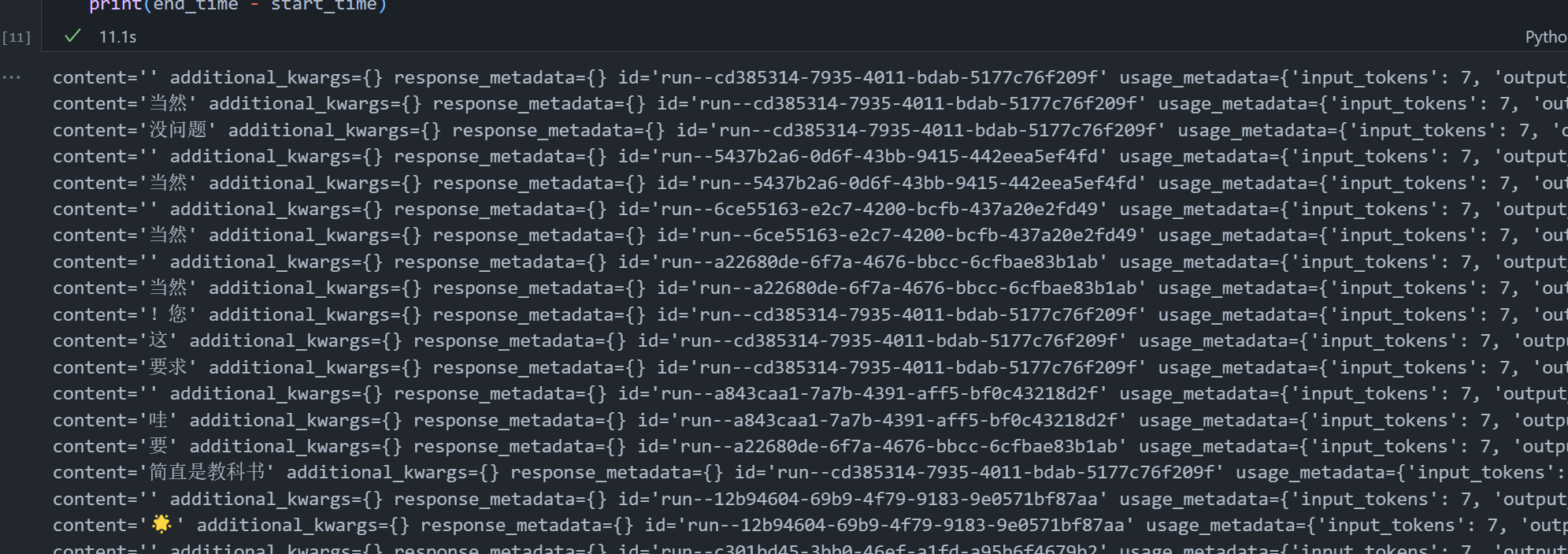
abatch()
该方法与batch函数的区别是,batch背后是线程池开多线程实现的并发,abatch的实现就是基于协程异步实现并发,abatch的实现逻辑与测试ainvoke效率的代码很像。
将每个ainvoke函数包装成asyncio的Task对象,使用asyncio.gather方法统一开始执行。
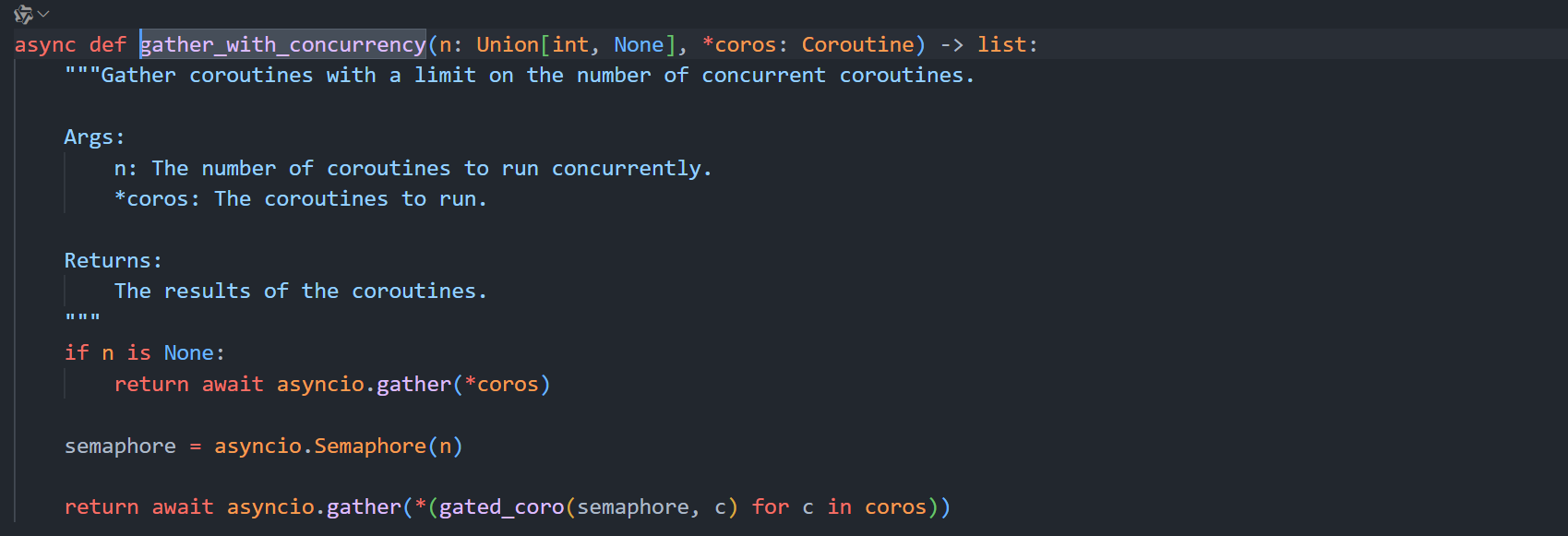
注册自定义的Chat和Base模型
什么情况下需要学习使用自定义模型
- 在项目开发的时候,经常需要切换不同的模型进行效果对比测试,有些模型厂商或者平台可能未将自己的模型与LangChain框架集成(例如,硅基流动平台-SiliconFlow)。
- 自己设计或者训练了一个新的模型需要测试与上线,尤其是修改了模型架构导致无法接入主流的推理框架时,又需要快速的实现异步,流式调用支持。
- 想深入学习理解LangChain。
如果对以上内容没有兴趣可以直接跳过这节。
定义自己的大模型(继承BaseLLM类和BaseChatModel类)
前面提到过注册一个自定义模型的最低限度是需要重写LangChain的抽象类BaseLLM/BaseChatLLM的两个抽象方法(call, _generate和 _llm_type方法)。
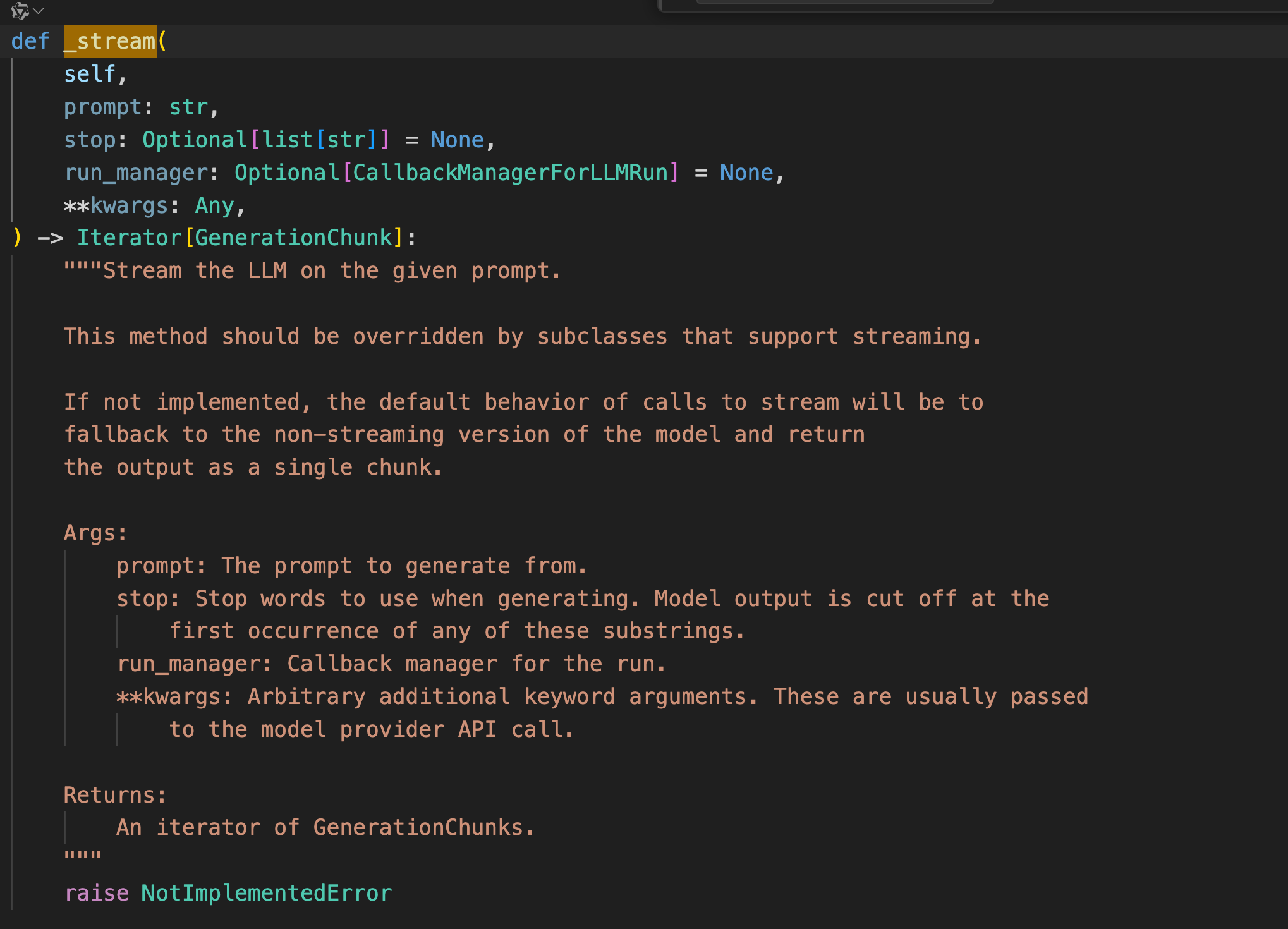
如果希望自定义模型支持流式返回结果,则需要重写_stream方法,如果没有重写,那么在stream方法就会退回到invoke方法。
定义自己的BaseLLM模型
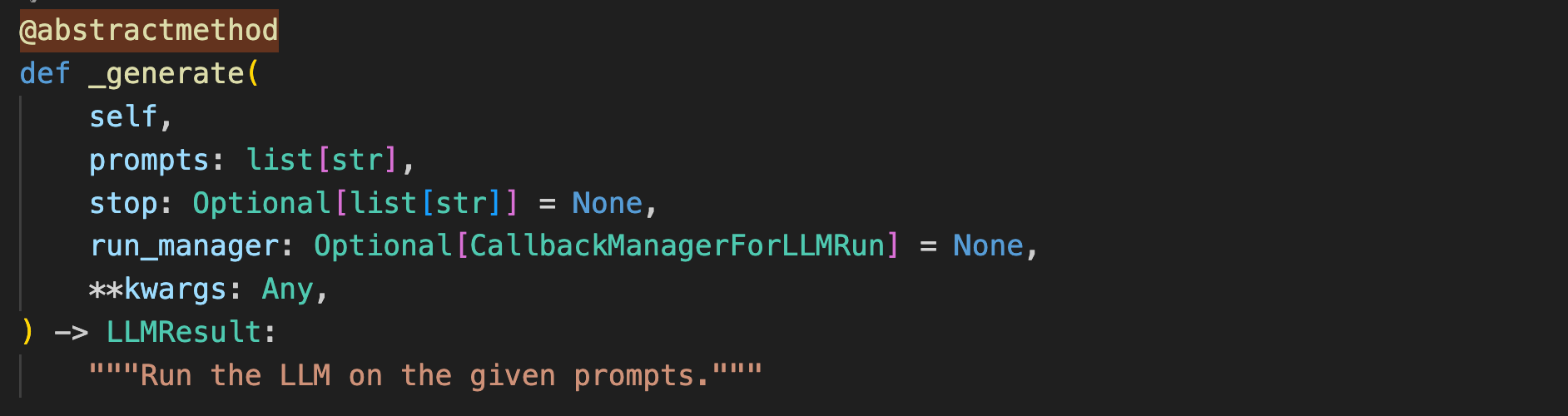
这里先看一下BaseLLM类的上述三个方法。
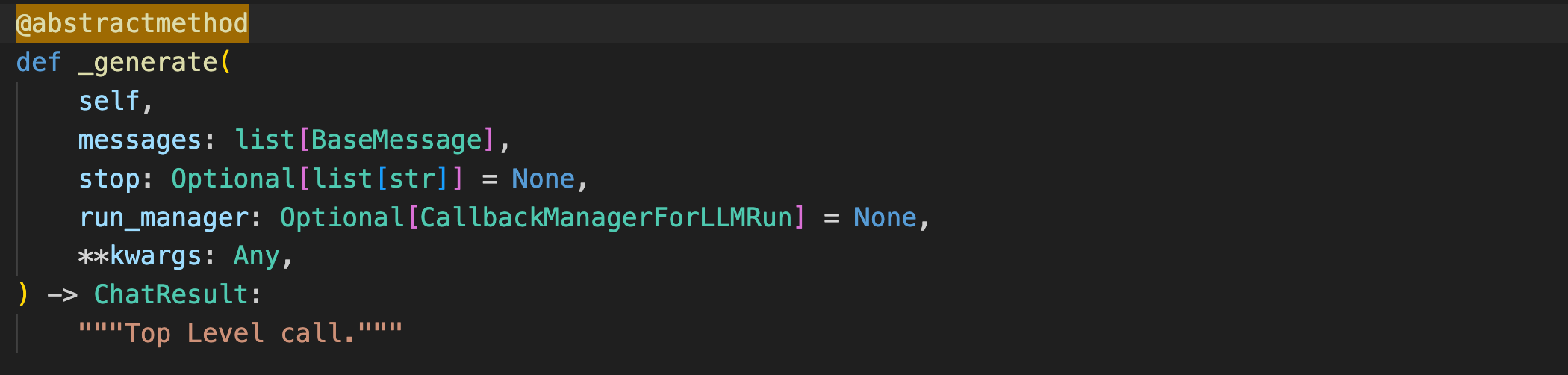
注意对比一下BaseLLM和BaseChatLLM两个类中_generate函数的第二个参数的区别(prompt和message),这也就是Base模型和Chat模型区别的最直观体现。
BaseLLM类的两个抽象方法

定义自己的BaseChatLLM模型
BaseChatLLM类的两个抽象方法

接入自定义模型示例(以硅基流动平台的api为例)
官方教程
https://python.langchain.com/docs/how_to/custom_chat_model/
核心代码逻辑
其实LangChain中注册自定义模型f非常简单,关键就是需要重写_generate和 _stream 这两个函数是支持模型输出和流式输出的关键,因为包括异步调用在内的所有操作(如 invoke,ainvoke,batch,stream等方法)都基于这两个函数获取输出内容的(具体的调用原理和关系后面会详细介绍)。
导入所需依赖
from typing import Any, Dict, Iterator, List, Optional
from langchain_core.callbacks import (
CallbackManagerForLLMRun,
)
from langchain_core.language_models import BaseChatModel
from langchain_core.messages import (
AIMessage,
AIMessageChunk,
BaseMessage,
)
from langchain_core.messages.ai import UsageMetadata
from langchain_core.outputs import ChatGeneration, ChatGenerationChunk, ChatResult
from pydantic import Field
from langchain_core.messages import (
AIMessage,
BaseMessage,
FunctionMessage,
HumanMessage,
SystemMessage,
ToolMessage,
)
from langchain_core.messages import (
AIMessageChunk,
FunctionMessageChunk,
HumanMessageChunk,
SystemMessageChunk,
ToolMessageChunk,
)
重写两个核心函数 _generate和 _stream
先放个官方的简化版,后续会更新,太困了////zzz
from typing import Any, Dict, Iterator, List, Optional
from langchain_core.callbacks import (
CallbackManagerForLLMRun,
)
from langchain_core.language_models import BaseChatModel
from langchain_core.messages import (
AIMessage,
AIMessageChunk,
BaseMessage,
)
from langchain_core.messages.ai import UsageMetadata
from langchain_core.outputs import ChatGeneration, ChatGenerationChunk, ChatResult
from pydantic import Field
class ChatParrotLink(BaseChatModel):
"""A custom chat model that echoes the first `parrot_buffer_length` characters
of the input.
When contributing an implementation to LangChain, carefully document
the model including the initialization parameters, include
an example of how to initialize the model and include any relevant
links to the underlying models documentation or API.
Example:
.. code-block:: python
model = ChatParrotLink(parrot_buffer_length=2, model="bird-brain-001")
result = model.invoke([HumanMessage(content="hello")])
result = model.batch([[HumanMessage(content="hello")],
[HumanMessage(content="world")]])
"""
model_name: str = Field(alias="model")
"""The name of the model"""
temperature: Optional[float] = None
max_tokens: Optional[int] = None
timeout: Optional[int] = None
stop: Optional[List[str]] = None
max_retries: int = 2
def _generate(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> ChatResult:
"""Override the _generate method to implement the chat model logic.
This can be a call to an API, a call to a local model, or any other
implementation that generates a response to the input prompt.
Args:
messages: the prompt composed of a list of messages.
stop: a list of strings on which the model should stop generating.
If generation stops due to a stop token, the stop token itself
SHOULD BE INCLUDED as part of the output. This is not enforced
across models right now, but it's a good practice to follow since
it makes it much easier to parse the output of the model
downstream and understand why generation stopped.
run_manager: A run manager with callbacks for the LLM.
"""
# Replace this with actual logic to generate a response from a list
# of messages.
tokens = "_generate"
ct_input_tokens = sum(len(message.content) for message in messages)
ct_output_tokens = len(tokens)
message = AIMessage(
content=tokens,
additional_kwargs={}, # Used to add additional payload to the message
response_metadata={ # Use for response metadata
"time_in_seconds": 3,
},
usage_metadata={
"input_tokens": ct_input_tokens,
"output_tokens": ct_output_tokens,
"total_tokens": ct_input_tokens + ct_output_tokens,
},
)
##
generation = ChatGeneration(message=message)
return ChatResult(generations=[generation])
def _stream(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[ChatGenerationChunk]:
"""Stream the output of the model.
This method should be implemented if the model can generate output
in a streaming fashion. If the model does not support streaming,
do not implement it. In that case streaming requests will be automatically
handled by the _generate method.
Args:
messages: the prompt composed of a list of messages.
stop: a list of strings on which the model should stop generating.
If generation stops due to a stop token, the stop token itself
SHOULD BE INCLUDED as part of the output. This is not enforced
across models right now, but it's a good practice to follow since
it makes it much easier to parse the output of the model
downstream and understand why generation stopped.
run_manager: A run manager with callbacks for the LLM.
"""
tokens = '_stream'
ct_input_tokens = sum(len(message.content) for message in messages)
for token in tokens:
usage_metadata = UsageMetadata(
{
"input_tokens": ct_input_tokens,
"output_tokens": 1,
"total_tokens": ct_input_tokens + 1,
}
)
ct_input_tokens = 0
chunk = ChatGenerationChunk(
message=AIMessageChunk(content=token, usage_metadata=usage_metadata)
)
if run_manager:
# This is optional in newer versions of LangChain
# The on_llm_new_token will be called automatically
run_manager.on_llm_new_token(token, chunk=chunk)
yield chunk
# Let's add some other information (e.g., response metadata)
chunk = ChatGenerationChunk(
message=AIMessageChunk(content="", response_metadata={"time_in_sec": 3})
)
if run_manager:
# This is optional in newer versions of LangChain
# The on_llm_new_token will be called automatically
run_manager.on_llm_new_token(token, chunk=chunk)
yield chunk
@property
def _llm_type(self) -> str:
"""Get the type of language model used by this chat model."""
return self.model_name
常见第三方大模型api平台的SDK(待整理)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)