RAG检索增强生成
划分chunk是为了把相同语义的token聚集在一起,不同语义的token互相分开,在长文档中各个片段的语义可能存在较大差异,如果将整个文档作为一个整体进行知识检索,会导致语义杂揉,影响检索效果。将长文档切分成多个小块,可以使得每个小块内部表意一致,块之间表意存在多样性,从而更充分地发挥知识检索的作用。检索阶段:将用户的问题转化为向量,从外部知识库或私有文档中(向量数据库)快速检索相关片段。向量数
文章目录
RAG检索增强生成
大模型相关知识概念
- 提示词工程(Prompt Engineering)是指在使用大语言模型时,设计、优化和调整输入给模型的提示词(prompt),使得模型能够理解用户的需求并提供准确、有用的回答。
- 微调(Fine-tuning)是指在预训练模型的基础上,通过使用特定任务的数据进行进一步的训练,以使模型适应特定任务或领域的需求。微调通常是在预训练模型已经学到丰富的通用知识后,针对特定问题进行的小范围调整,使模型在特定任务上表现得更好。
- 检索增强生成RAG(Retrieval-Augmented Generation)是一种结合信息检索与文本生成的技术,旨在提升大语言模型在回答专业问题时的准确性和可靠性。
- 大语言模型LLMs幻觉(Hallucination),指模型生成内容与事实不符或违背用户意图的现象。其本质是模型在缺乏真实知识或逻辑推理能力时,通过“脑补”填补信息缺口
检索增强生成RAG核心原理为检索+生成两个阶段
-
检索阶段:将用户的问题转化为向量,从外部知识库或私有文档中(向量数据库)快速检索相关片段。
-
生成阶段:将检索到的信息输入大模型,生成结合上下文的具体回答。
RAG工作流程
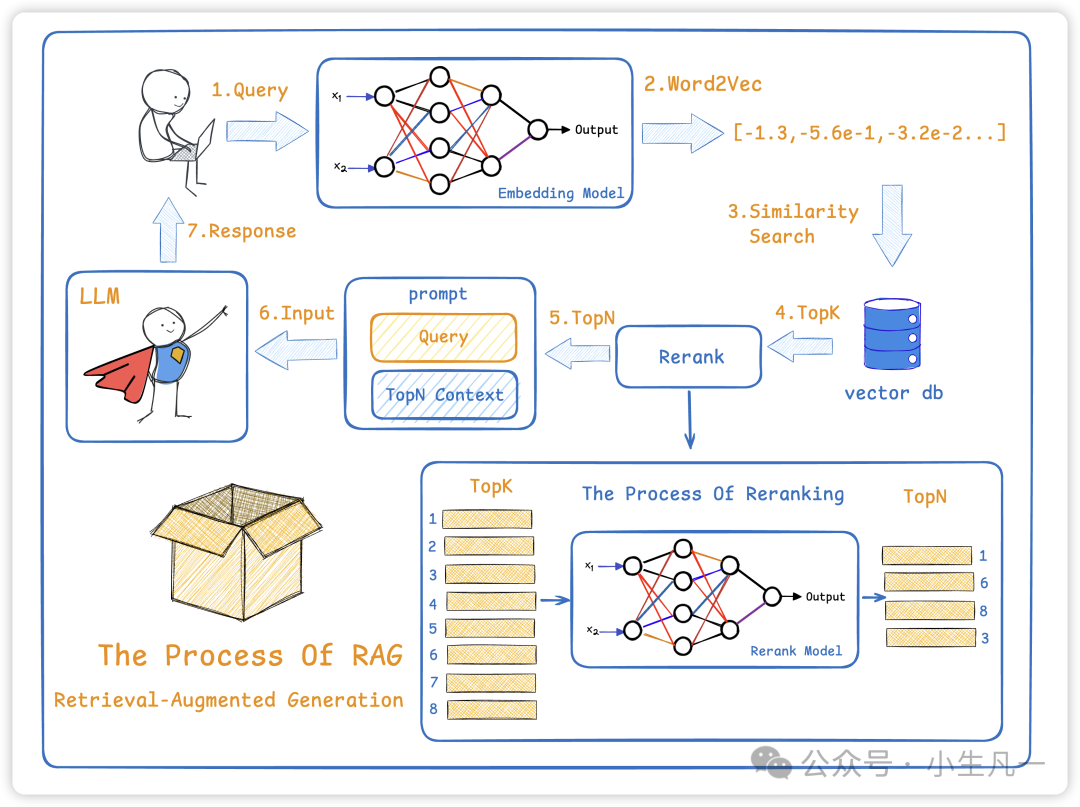
(1)当用户对大模型提问
(2)此时会通过embeding模型将文本转成向量
(3)再到向量数据库中搜索语言相近的内容
(4)向量数据库会给出一个Top-K的本文
(5)接着在进行过重排序模型,再筛选出Top-N
(6)将搜索到的内容和用户所搜索的query整个成一个prompt一起给LLM
(7)LLM基于这些输入内容和自身内容进行输出
向量数据库
向量数据库是通过存储文本的向量化表示,支持基于语义相似度的快速检索,解决了传统关键词匹配无法捕捉上下文关联的问题。
- 传统数据库只能匹配到包含关键词的信息,用原始文本检索,则无法处理同义词、多义词、语境差异等语义问题
- 向量数据库可以匹配到语义相近但未包含关键词的文档
向量数据库是怎么知道语义相似的
向量数据库存储的是向量,不是文本,文本是大家能看懂的文字,而向量是一串浮点型数据
那么当所有的文本都成了浮点型数据后,计算机可以通过数学公式(比如余弦相似度),量化语义相似性。
向量数据库构造
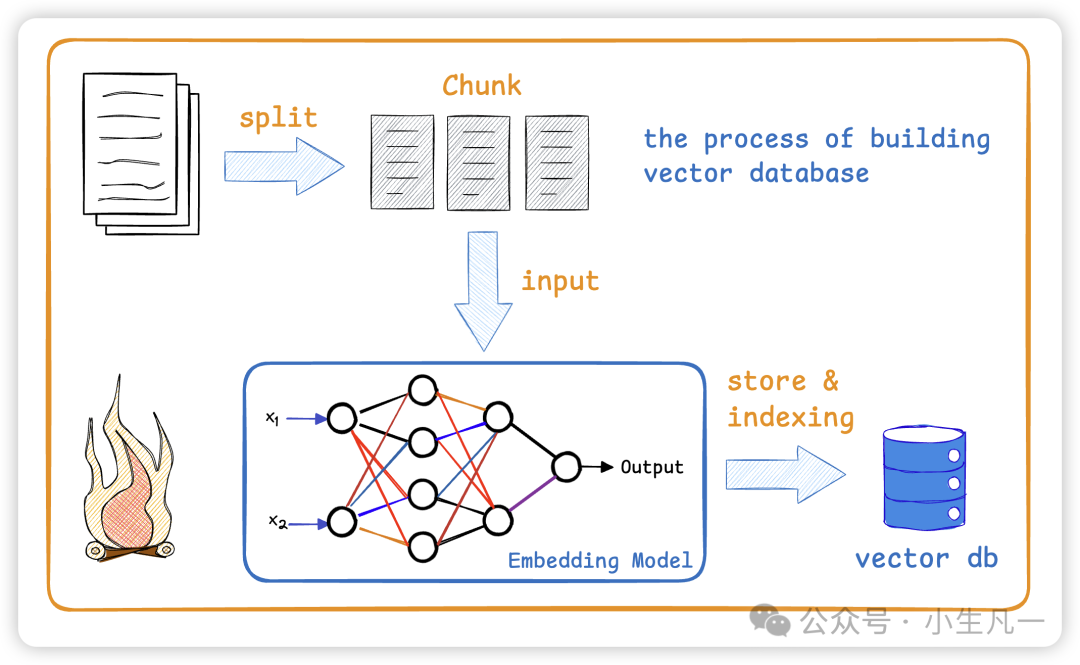
(1)将文章进行分片成多组chunk,也就是大量文本分解为较小段
(2)进行向量化
(3)存到向量数据库
划分chunk是将长文档或数据集切割成较小的、独立的部分,以便于处理、存储和检索。
划分chunk是为了把相同语义的token聚集在一起,不同语义的token互相分开,在长文档中各个片段的语义可能存在较大差异,如果将整个文档作为一个整体进行知识检索,会导致语义杂揉,影响检索效果。将长文档切分成多个小块,可以使得每个小块内部表意一致,块之间表意存在多样性,从而更充分地发挥知识检索的作用。
RAG知识库+DeepSeek+Python实例
ollama本地大模型环境搭建
官网https://ollama.com/download/linux
ollama是一个用于在本地部署大语言模型的工具,可通过ollama在本地拉取各种大模型并运行。可理解为docker和各个容器镜像的管理关系。个人感觉ollama拉取的大模型还是容器镜像,但是通过docker命令查看又没有相应的镜像信息,有点奇怪。
ubuntu安装curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
>>> Downloading Linux amd64 bundle
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
修改ollama服务配置
1.vim /etc/systemd/system/ollama.service
2.在[Service]添加
Environment="OLLAMA_HOST=0.0.0.0:11434"
3.重启ollama服务
systemctl daemon-reload
systemctl restart ollama.service
ollama命令选项
--version show version
serve Start ollama
pull Pull a model from a registry
run Run a model
stop Stop a running model
list List models
ps List running models
ollama的本地deepseek-r1模型链接https://ollama.com/library/deepseek-r1
拉取1.5b版本的模型镜像
ollama run deepseek-r1:1.5b
ollama提供两个接口
url/api/chat用于一般的聊天模式
url/api/generate用于一次性对话
ollama接口调用代码示例
- generate接口
import requests
res = requests.post(
url="http://localhost:11434/api/generate",
json={
"model": "deepseek-r1:1.5b",
"prompt": "hello",
"stream": False
}
)
data_dict = res.json()
print(data_dict)
- chat接口,可以维护对话的上下文,但是用代码实现时,每次也只是post一个数据包,因此需要在提交的数据包的messages字段中,填充上下文的会话信息
# 单个会话示例
import requests
res = requests.post(
url="http://localhost:11434/api/chat",
json={
"model": "deepseek-r1:1.5b",
"messages": [
{"role": "user", "content": "hello"}
],
"stream": False
}
)
data_dict = res.json()
print(data_dict)
# 携带多轮会话上下文信息示例
import requests
message_list = []
while True:
text = input("please input: ")
cur_user_dict = {"role": "user", "content": text}
message_list.append(cur_user_dict)
res = requests.post(
url="http://localhost:11434/api/chat",
json={
"model": "deepseek-r1:1.5b",
"messages": message_list,
"stream": False
}
)
res_msg = res.json()['message']
print(res_msg)
message_list.append(res_msg)
ollama+nomic-embed-text+deepseek实例
需求为构建中医知识检索库
# zhongyi-knowledge.txt
风寒感冒
症状:恶寒重,发热轻,无汗,头痛,肢节酸痛,鼻塞声重,或鼻痒喷嚏,时流清涕,咽痒,咳嗽,咳痰稀薄色白,口不渴或渴喜热饮,舌苔薄白而润,脉浮或浮紧。
药方:荆防败毒散。药物组成包括荆芥、防风、羌活、独活、柴胡、前胡、川芎、枳壳、茯苓、桔梗、甘草等,具有辛温解表的功效。
风热感冒
症状:发热,微恶风,有汗,头胀痛,鼻塞流黄涕,咳嗽,痰黏或黄,咽燥,或咽喉红肿疼痛,口渴,舌尖边红,苔薄黄,脉浮数。
药方:银翘散。主要药物有金银花、连翘、桔梗、薄荷、竹叶、生甘草、荆芥穗、淡豆豉、牛蒡子等,能辛凉解表,清热解毒。
痰湿蕴肺
症状:咳嗽反复发作,咳声重浊,痰多,因痰而嗽,痰出咳平,痰黏腻或稠厚成块,色白或带灰色,每于早晨或食后则咳甚痰多,进甘甜油腻食物加重,胸闷,脘痞,呕恶,食少,体倦,大便时溏,舌苔白腻,脉象濡滑。
药方:二陈平胃散合三子养亲汤。二陈平胃散由半夏、陈皮、茯苓、甘草、苍术、厚朴组成,三子养亲汤由紫苏子、白芥子、莱菔子组成,可燥湿化痰,理气止咳。
胃痛
症状:胃痛暴作,恶寒喜暖,得温痛减,遇寒加重,口淡不渴,或喜热饮,舌淡苔薄白,脉弦紧。
药方:良附丸。由高良姜、香附组成,能温胃散寒,理气止痛。
脾胃虚寒
症状:胃痛隐隐,绵绵不休,喜温喜按,空腹痛甚,得食则缓,劳累或受凉后发作或加重,泛吐清水,神疲纳呆,四肢倦怠,手足不温,大便溏薄,舌淡苔白,脉虚弱或迟缓。
药方:黄芪建中汤。药物包含黄芪、桂枝、芍药、炙甘草、生姜、大枣、饴糖,可温中健脾,和胃止痛。
失眠
症状:不易入睡,多梦易醒,心悸健忘,神疲食少,伴头晕目眩,四肢倦怠,腹胀便溏,面色少华,舌淡苔薄,脉细无力。
药方:归脾汤。由白术、茯神、黄芪、龙眼肉、酸枣仁、人参、木香、炙甘草、当归、远志等组成,有补益心脾,养血安神之效。
知识库构建的分块与向量化示例
使用nomic-embed-text:v1.5用于文本向量化和检索
nomic-embed-text是一个基于Sentence Transformers库的句子嵌入模型,专门用于特征提取和句子相似度计算。
# 代码示例
import requests
def file_chunk_list():
with open("zhongyi-knowledge.txt", encoding='utf-8', mode='r') as fp:
data = fp.read()
chunk_list = data.split("\n\n")
return [chunk for chunk in chunk_list if chunk]
def ollama_embedding_by_api(text):
res = requests.post(
url="http://127.0.0.1:11434/api/embeddings",
json={
"model": "nomic-embed-text:v1.5",
"prompt": text
}
)
# print(res)
embedding = res.json()['embedding']
return embedding
def run():
chunk_list = file_chunk_list()
# print("chunk_list: ", chunk_list)
for chunk in chunk_list:
vector = ollama_embedding_by_api(chunk)
print(len(vector), vector)
print()
if __name__ == '__main__':
run()
向量数据库持久化示例
chromadb是一个向量数据库,支持基于近似距离的检索方式
pip3 install chromadb
# 代码示例
import uuid
import chromadb
import requests
def ollama_embedding_by_api(text):
res = requests.post(
url="http://127.0.0.1:11434/api/embeddings",
json={
"model": "nomic-embed-text:v1.5",
"prompt": text
}
)
# print(res)
embedding = res.json()['embedding']
return embedding
def run():
client = chromadb.PersistentClient(path="./chroma-db")
if client.get_collection("collection_v1"):
client.delete_collection("collection_v1")
collection = client.get_or_create_collection(name="collection_v1")
documents = ["风寒感冒", "寒邪客胃", "心脾两虚"]
ids = [str(uuid.uuid4()) for _ in documents]
embeddings = [ollama_embedding_by_api(text) for text in documents]
collection.add(
ids=ids,
documents=documents,
embeddings=embeddings
)
# 关键字搜索
qs = "感冒胃疼"
qs_embedding = ollama_embedding_by_api(qs)
res = collection.query(query_embeddings=[qs_embedding, ],query_texts=qs, n_results=2)
# print(res)
result = res["documents"][0]
print(result)
if __name__ == '__main__':
run()
最终代码
import uuid
import chromadb
import requests
def file_chunk_list():
with open("zhongyi-knowledge.txt", encoding='utf-8', mode='r') as fp:
data = fp.read()
chunk_list = data.split("\n\n")
return [chunk for chunk in chunk_list if chunk]
def ollama_embedding_by_api(text):
res = requests.post(
url="http://127.0.0.1:11434/api/embeddings",
json={
"model": "nomic-embed-text:v1.5",
"prompt": text
}
)
embedding = res.json()['embedding']
return embedding
def ollama_generate_by_api(prompt):
response = requests.post(
url="http://127.0.0.1:11434/api/generate",
json={
"model": "deepseek-r1:1.5b",
"prompt": prompt,
"stream": False,
}
)
res = response.json()['response']
return res
def initial():
client = chromadb.PersistentClient(path="./chroma-db")
if client.get_collection("collection_v1"):
client.delete_collection("collection_v1")
collection = client.get_or_create_collection(name="collection_v1")
documents = file_chunk_list()
ids = [str(uuid.uuid4()) for _ in range(len(documents))]
embeddings = [ollama_embedding_by_api(text) for text in documents]
# 插入数据
collection.add(
ids=ids,
documents=documents,
embeddings=embeddings
)
def run():
# 关键字搜索
qs = "感冒"
qs_embedding = ollama_embedding_by_api(qs)
client = chromadb.PersistentClient(path="./chroma-db")
collection = client.get_collection(name="collection_v1")
res = collection.query(query_embeddings=[qs_embedding, ], query_texts=qs, n_results=2)
result = res["documents"][0]
context = "\n".join(result)
print("-----\ncontext:\n %s\n-----\n" % context)
prompt = f"""你是一个中医问答机器人,任务是根据参考信息回答用户问题,如果参考信息不足以回答用户问题,请回复不知道,不要去杜撰任何信息,请用中文回答。
参考信息:{context},来回答问题:{qs},
"""
result = ollama_generate_by_api(prompt)
print(result)
if __name__ == '__main__':
initial()
run()
参考链接
rag介绍
https://mp.weixin.qq.com/s/Z4MLXZfpauko_S0Bj-0uKg
chunk划分
https://blog.csdn.net/2301_78285120/article/details/144360003
提示词工程,微调,检索增强生成区别表格
https://mp.weixin.qq.com/s/kdeksSoFNoXLzd1vp5Ho6A
大模型幻觉文章和论文
https://mp.weixin.qq.com/s/7OCNx37k9xCouF08fnoJMQ
rag-deepseek实战视频
https://www.bilibili.com/video/BV16fDfYNEzg
if name == ‘main’:
initial()
run()
### 参考链接
rag介绍
https://mp.weixin.qq.com/s/Z4MLXZfpauko_S0Bj-0uKg
chunk划分
https://blog.csdn.net/2301_78285120/article/details/144360003
提示词工程,微调,检索增强生成区别表格
https://mp.weixin.qq.com/s/kdeksSoFNoXLzd1vp5Ho6A
大模型幻觉文章和论文
https://mp.weixin.qq.com/s/7OCNx37k9xCouF08fnoJMQ
rag-deepseek实战视频
https://www.bilibili.com/video/BV16fDfYNEzg

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)