【第四十七周】HippoRAG 2 复现与分析(一):环境部署与代码分析
本文记录了HippoRAG 2系统的核心功能测试过程。通过构建小型结构化文档库,验证了系统的索引构建、动态更新、问答检索及评估能力。测试中替换OpenAI为Deepseek API,使用NV-Embed-v2嵌入模型,成功获得66.67%的答案精确匹配率。这一阶段既确认了系统基础功能(如稳定索引和检索效率),也暴露了模型配置等优化点,为后续大规模实验提供了可复用的测试框架和改进方向。环境搭建和运行
摘要
本周对HippoRAG 2系统进行核心功能测试,通过构建小型结构化文档库(如人物职业、童话事件、地理关系),验证其索引构建、动态增删、多轮检索问答及评估流程的完整性。这一阶段工作为后续完整复现提供了关键基准:既确认了系统基础能力(如66.67%的答案精确匹配率、动态索引稳定性),又暴露了潜在问题(如模型名称有效性、字符串匹配敏感性),为后续大规模实验的模型选型、数据预处理和评估标准制定提供了可复用的测试框架与调试经验。
Abstract
This week, we conducted core functionality tests on the HippoRAG 2 system by building a small structured document library (e.g., character professions, fairy-tale events, geographic relationships) to verify its indexing, dynamic updates, multi-round retrieval & QA, and evaluation processes.This phase establishes a critical baseline for future full-scale replication: it confirms the system’s core capabilities (e.g., 66.67% exact answer matching, stable dynamic indexing) while revealing potential issues (e.g., model name validity, string-matching sensitivity). These findings provide a reusable testing framework and debugging insights for future large-scale experiments, guiding model selection, data preprocessing, and evaluation criteria.
安装依赖
conda create -n hipporag python=3.10
conda activate hipporag
pip install hipporag
注意:一定要安装对应版本Pyhton
试运行
我们需要运行tests_openai.py测试一下是否可以正常运行。
tests_openai.py是HippoRAG的核心功能测试脚本,覆盖了索引构建、检索、问答生成、动态更新和评估全流程。
HippoRAG 初始化
hipporag = HippoRAG(
save_dir='outputs/openai_test', # 存储索引和模型的目录
llm_model_name='gpt-4o-mini', # OpenAI模型
embedding_model_name='text-embedding-3-small' # 文本嵌入模型
)
作者给我们提供的嵌入模型有text-embedding-3-small、NV-Embed、GritLM和Contriever。text-embedding-3-small是OpenAI提供的一种嵌入模型,使用Deepseek API后无法调用text-embedding-3-small,所以我们要将这个更换为:
embedding_model_name = ‘text-embedding-3-small’ # Embedding model name (NV-Embed, GritLM or Contriever for now)
embedding_model_name = 'nvidia/NV-Embed-v2' # Embedding model name (NV-Embed, GritLM or Contriever for now)
这里我想把项目中的OpenAI更换为Deepseek,因为Deepseek采用了OpenAI兼容模式,可以像调用OpenAI API那样去调用。如果你有OpenAI API key,就只需设置好环境变量中的API key即可。
在tests_openai.py脚本开头加入如下代码:
import os
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx" # deepseek API
os.environ["OPENAI_BASE_URL"] = "https://api.deepseek.com/v1" # deepseek API 调用 URL(OpenAI不用此行)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 需要用到huggingface中的嵌入模型,设置镜像网站
在实例化hipporag的时候将llm_model_name改为deepseek-chat,也就是:
hipporag = HippoRAG(
save_dir='outputs/openai_test', # 存储索引和模型的目录
llm_model_name='deepseek-chat', # OpenAI模型
embedding_model_name='nvidia/NV-Embed-v2' # 文本嵌入模型
)
文档索引
hipporag.index(docs=docs)
- 输入:docs列表包含9个虚构的短文本(如人物职业、童话情节、地理信息)。
- 功能:将文档分块、生成嵌入向量,并构建可检索的索引。
QA
results = hipporag.rag_qa(
queries=queries, # 问题列表
gold_docs=gold_docs, # 每个问题的标准相关文档
gold_answers=answers # 标准答案
)
print(results[-2:]) # 输出最后两个评估结果(召回率和答案质量)
评估逻辑:
- 召回率(Recall@k):检查检索到的文档是否包含gold_docs。
- 答案质量:对比生成答案与gold_answers的精确匹配(ExactMatch)和F1分数。
运行脚本
直接在终端输入python tests_openai.py,等待程序从huggingface下载好嵌入模型即可运行。
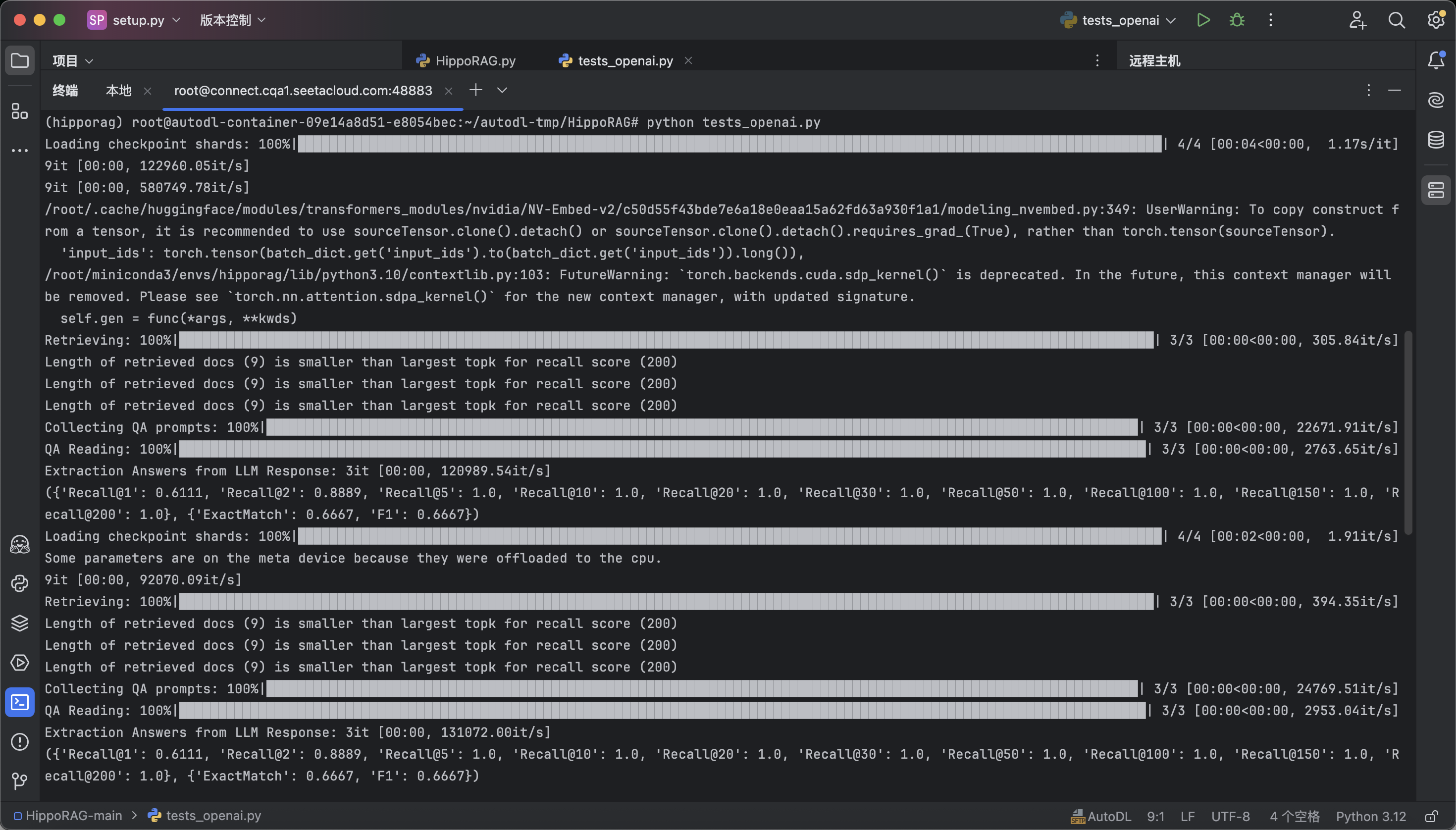
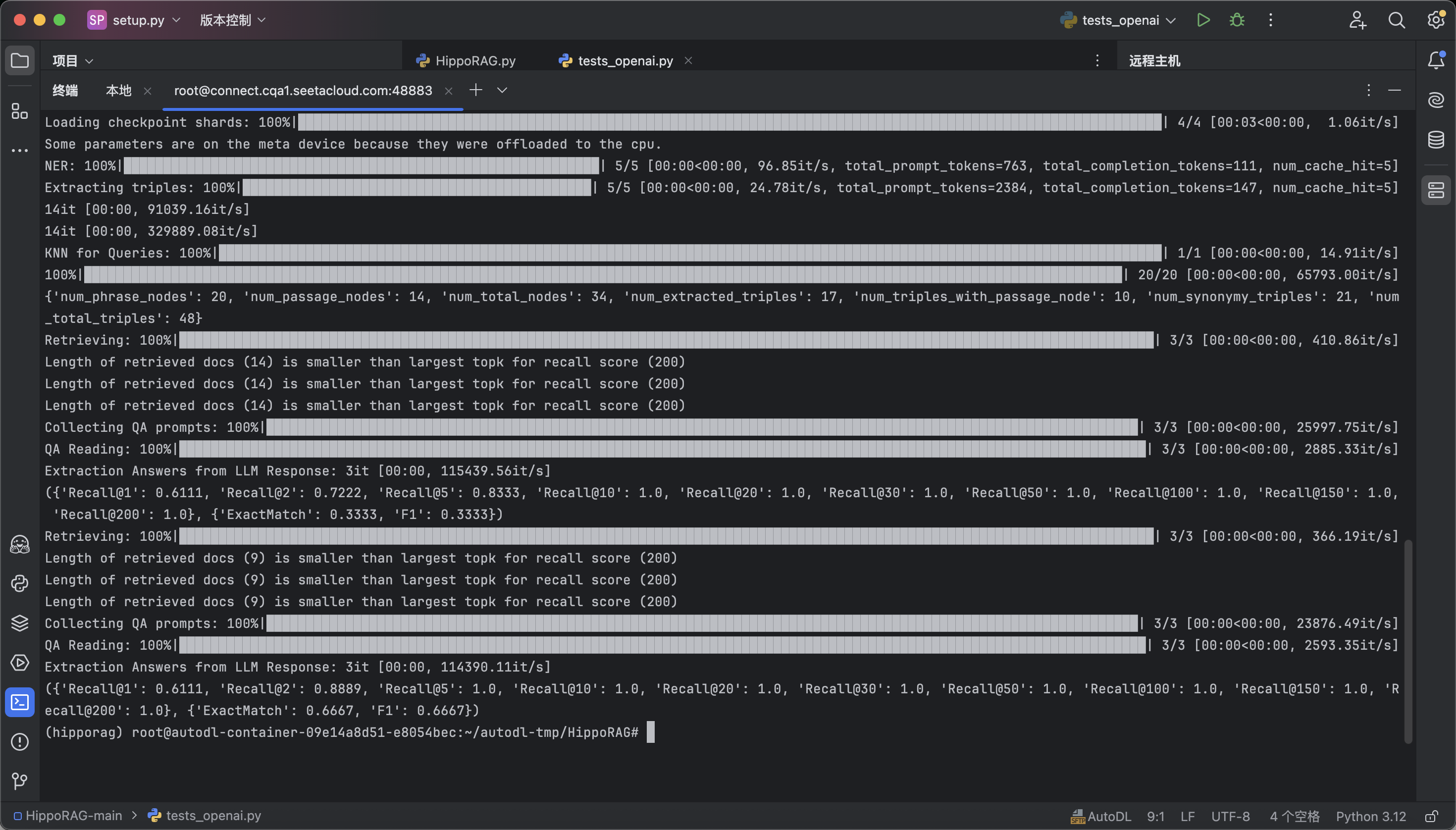
我们可以看到一下各类指标均正常生成,证明我们环境已经成功搭建好了。
({'Recall@1': 0.6111, 'Recall@2': 0.8889, 'Recall@5': 1.0, 'Recall@10': 1.0, 'Recall@20': 1.0, 'Recall@30': 1.0, 'Recall@50': 1.0, 'Recall@100': 1.0, 'Recall@150': 1.0, 'Recall@200': 1.0}, {'ExactMatch': 0.6667, 'F1': 0.6667})
总结
本周重点完成了HippoRAG 2系统的核心功能测试工作,通过构建结构化测试数据集,全面验证了系统的文档索引、动态更新、多轮问答检索等核心功能模块的运行效果。测试结果既证实了系统在基础检索和答案生成方面的可靠性(66.67%的精确匹配率),也发现了模型配置和字符串匹配等需要优化的环节,为后续系统迭代升级和大规模应用部署奠定了重要基础,提供了明确的技术改进方向。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)