深入解析:DeepSeek R1与V3的架构与应用差异
在本文中,我们详细探讨了DeepSeek V3和R1在模型定位、架构设计、性能表现、应用场景、部署成本以及开源生态等方面的差异。这两款模型各自展现了深度求索(DeepSeek)公司在AI技术发展上的不同侧重和创新理念。:作为一个通用的自然语言处理模型,V3凭借其混合专家架构(MoE)、多头隐式注意力(MLA)及动态负载均衡机制,在多模态任务处理和长文本生成方面表现出色。其低成本的API定价和广泛的
引言
在当今快速发展的人工智能领域,深度求索(DeepSeek)公司凭借其创新的技术和强大的模型迅速崭露头角。作为一家致力于推动AI前沿发展的公司,DeepSeek推出的两款大模型——DeepSeek V3和DeepSeek R1,引起了业界的广泛关注。这两款模型不仅展示了深度学习技术的最新进展,还通过各自独特的设计理念和应用场景,为开发人员提供了强大的工具。
DeepSeek V3和R1虽然基于相似的技术框架,但在设计目标、架构特点、训练方法以及实际应用上存在显著差异。V3定位为通用自然语言处理模型,采用混合专家(Mixture-of-Experts, MoE)架构,旨在高效处理多模态任务,如文本、图像和音频等。而R1则专注于复杂逻辑推理任务,通过强化学习训练提升推理能力,并以其独特的“思维链”展示增强了透明度和可信度。
本文将详细探讨DeepSeek R1与V3之间的差异,为开发人员提供深入了解这两款模型的机会,以便在实际应用中做出更明智的选择。
模型定位与核心能力
在深入探讨DeepSeek R1和V3的具体差异之前,了解它们各自的定位和核心能力是至关重要的。两者在设计之初就有着不同的目标,这直接影响了它们在实际应用中的表现。
DeepSeek V3的定位及核心能力
DeepSeek V3被设计为一个通用的自然语言处理(NLP)模型。其采用了混合专家(Mixture-of-Experts, MoE)架构,这种架构允许模型在处理多模态任务时展现出卓越的计算效率。V3拥有高达6710亿个参数,但每次推理仅激活其中370亿个参数。这种选择性激活机制大幅降低了计算成本,同时保证了推理质量。
V3的优势在于其强大的多模态任务处理能力,包括文本、图像和音频等多种数据形式。此外,它还具有长文本处理能力,支持128K上下文窗口,使其非常适合用于内容生成、多语言翻译、智能客服等场景。例如,在生成长篇报告时,V3能够快速总结关键信息,并显著降低延迟。
DeepSeek R1的定位及核心能力
相较于V3,DeepSeek R1专注于复杂逻辑推理任务。R1通过强化学习(Reinforcement Learning, RL)进行训练,无需依赖大量监督微调(Supervised Fine-Tuning, SFT)。这一点使得R1能够更有效地进行动态门控机制优化,从而提升逻辑推理能力。
R1在数学证明、代码生成、决策优化等场景中表现出色。其独特之处在于输出答案前展示“思思维链”(Chain-of-Thought),这不仅增强了模型输出结果的透明度和可信度,还为用户提供了一种理解模型推理过程的新视角。例如,在金融分析中,R1可以生成复杂SQL查询并解释其推理过程,为用户提供更具洞察力的数据分析工具。
通过上述分析,我们可以看到DeepSeek V3和R1在设计目标上的显著差异:一个侧重于广泛适用的自然语言处理,一个则专注于深度逻辑推理。这种差异为开发人员提供了更多样化的选择,以满足不同应用场景下的需求。
架构与训练方法
DeepSeek V3和R1在架构设计和训练方法上各有独到之处,这些技术特性决定了它们在不同任务中的表现和优势。
DeepSeek V3的架构特点
DeepSeek V3采用了混合专家(Mixture-of-Experts, MoE)架构,这种架构设计极大地提升了模型的计算效率和性能。其关键特点包括:
- 选择性激活专家:V3拥有6710亿个参数,但在推理时,每次仅激活370亿个参数。这种选择性激活机制不仅降低了计算成本,还确保了推理的高质量。
- 多头隐式注意力(MLA):通过对注意力键值进行压缩,V3减少了内存占用,提高了推理效率,同时不会损害注意力机制的质量。
- 智能路由系统:V3配备了复杂的路由机制,可以根据任务类型自动激活最适合的专家。例如,当输入是技术编码相关问题时,模型会激活专精于编程语言的专家;而当输入是内容摘要请求时,则会启用自然语言处理专家。其他专家保持休眠,以节省计算资源。
- 动态负载均衡:传统MoE模型通常依赖辅助损失来平衡负载,而V3采用动态偏差调整策略,确保不同专家的计算资源利用均衡,从而提高可扩展性和稳定性。
- 多令牌预测(MTP):该机制允许模型在单次推理过程中预测多个词元(token),增强训练信号,提高在复杂任务上的表现。
DeepSeek R1的架构优化与强化学习范式
DeepSeek R1充分利用了V3的架构,但针对推理任务进行了优化,主要体现在以下几个方面:
- 动态门控机制:R1采用动态门控机制,使其能够根据查询内容选择性激活相关专家。这一特性不仅提高了逻辑推理能力,还确保了计算效率。
- 自演进知识库:R1包含一个1.2亿条跨领域推理链的知识库,支持模型持续优化。这种自演进能力使得R1能够不断提升其推理性能。
- 强化学习训练范式:R1完全摒弃监督微调,通过强化学习直接激发推理能力。其冷启动策略仅需200个思维链样例启动初始策略网络,并结合群体相对策略优化(GRPO),提升训练稳定性65%。这种方法使得R1的训练效率更高,其收敛速度是传统RLHF(Reinforcement Learning from Human Feedback)的4.3倍。
通过对比可以看出,DeepSeek V3和R1在架构设计和训练方法上的创新,为它们在各自擅长领域提供了坚实的技术基础。这些差异也为开发人员在选择合适模型时提供了重要参考依据。
性能与基准测试比较
在模型的实际应用中,性能表现和基准测试结果是衡量其优劣的重要标准。DeepSeek V3和R1在不同领域的性能各有千秋,以下是对它们在关键任务上的表现分析。
DeepSeek V3的性能表现
DeepSeek V3在多语言处理、长文本生成和高吞吐量代码补全等方面展现了卓越的性能:
- 多语言处理:V3凭借其强大的自然语言处理能力,可以高效处理多种语言间的翻译任务。这使得它成为跨国企业进行多语言沟通和内容创作的不二选择。
- 长文本生成:V3支持128K上下文窗口,这一特性使其在长文本生成任务中如鱼得水。例如,在生成复杂报告或长篇文章时,V3能够快速提取和总结关键信息,并显著降低延迟。
- 高吞吐量代码补全:得益于多令牌预测机制,V3在代码补全任务中的速度提升了3.8倍。这对于需要快速迭代开发的团队来说,无疑是一个巨大的优势。
DeepSeek R1的性能优势
DeepSeek R1则在复杂数学问题、逻辑链推理及可解释性输出方面表现突出:
- 复杂数学问题:R1专注于逻辑推理,其在解决复杂数学问题上的表现尤为出色。例如,在AIME 2024(美国数学竞赛)中,R1的准确率达到了79.8%,远超其他同类模型。
- 逻辑链推理及可解释性输出:R1通过展示“思维链”,不仅提供了精准的推理结果,还增强了结果的透明度。这种可解释性的输出对于需要理解和验证推理过程的应用场景,如金融分析和科学研究,具有重要意义。
通过这些基准测试结果,我们可以看到DeepSeek V3和R1在不同领域各自发挥着不可替代的作用。V3以其广泛适用性和高效能著称,而R1则以其卓越的逻辑推理能力赢得了市场青睐。开发人员可以根据具体需求选择合适的模型,以充分发挥这两款大模型的优势。
应用场景与部署成本分析
在选择合适的AI模型时,应用场景和部署成本是开发人员需要重点考虑的因素。DeepSeek V3和R1在这些方面提供了不同的解决方案,以满足多样化的市场需求。
DeepSeek V3的应用场景与成本优势
DeepSeek V3凭借其通用性和高效性,适用于多个企业级NLP任务:
- 智能客服:V3能够处理复杂的客户查询,并提供准确且快速的响应。这使得它成为提升客户服务质量的重要工具。
- 多语言翻译:其强大的多语言处理能力,使得V3在国际化业务中具有显著优势,帮助企业打破语言障碍,实现全球化运营。
- 内容创作:V3可以生成高质量的文本内容,为新闻媒体、营销机构等提供创意支持。
在部署成本方面,V3也表现出色。其API定价为输入$0.14/百万tokens,输出$0.28/百万tokens,这一价格策略使得V3成为追求低成本部署企业的理想选择。
DeepSeek R1的应用场景与成本效益
DeepSeek R1专注于逻辑推理密集型任务,其应用场景包括:
- 科研:R1可以进行复杂的数据分析和数学推理,为科学研究提供有力支持。
- 算法交易:在金融领域,R1能够生成复杂交易策略,并解释其决策过程,提高投资决策的透明度和准确性。
- 复杂决策支持:R1通过展示“思维链”,为用户提供可解释性的决策建议,适用于需要深入理解推理过程的领域,如法律咨询和医疗诊断。
R1还支持模型蒸馏技术,可以将推理能力迁移至小参数模型(如14B),这使得它非常适合本地部署。此外,其API成本仅为OpenAI o1的1/50(输出$2.19/百万tokens),大大降低了使用门槛,为用户提供了极具竞争力的成本效益。
通过对比可以看出,DeepSeek V3和R1在应用场景和部署成本上各有千秋。V3以其广泛适用性和低成本优势吸引了大量企业用户,而R1则凭借其强大的逻辑推理能力和高性价比,在科研和金融等领域占据了一席之地。开发人员可以根据自身需求选择合适的模型,以实现最佳效果。
开源生态与商业化策略
在现代AI开发中,开源生态和商业化策略是模型能否广泛应用和持续发展的重要因素。DeepSeek V3和R1在这方面采取了不同的策略,以满足市场需求并促进技术传播。
DeepSeek V3的开源支持及兼容性分析
DeepSeek V3通过开放模型权重,积极参与开源社区,为开发人员提供了极大的便利。其主要特点包括:
- 支持多种推理模式:V3支持FP8和BF16推理模式,这使得它能够在不同硬件平台上高效运行。
- 广泛的硬件兼容性:V3适配了AMD GPU和华为昇腾NPU等多种硬件设备,确保了其在各种计算环境下的可用性。
- 集成至主流框架:V3被集成至vLLM等主流框架,这不仅方便了开发人员进行快速部署,还增强了模型的易用性和灵活性。
通过这些措施,DeepSeek V3建立了一个强大的开源生态系统,使得开发人员能够轻松访问和利用其强大的自然语言处理能力。
DeepSeek R1的开源协议、商业用途及轻量化版本
DeepSeek R1则采用MIT开源协议,这一选择允许用户自由使用、修改和分发模型,使其在商业应用中具有极高的灵活性。R1的其他特点包括:
- 允许商业用途:R1不仅开放源代码,还允许用户在商业项目中使用,这为企业用户提供了更多创新空间。
- 模型蒸馏与轻量化版本:R1提供32B/70B轻量化版本,通过模型蒸馏技术,将复杂推理能力迁移至小参数模型。这一特性使得R1能够在资源受限的环境中高效运行,同时保持较高性能。
- 对标OpenAI o1-mini:R1的性能被设计为对标OpenAI o1-mini,为用户提供了一种高性价比替代方案,进一步拓展了其市场潜力。
通过以上策略,DeepSeek R1不仅巩固了其在逻辑推理领域的地位,还为开发人员提供了丰富的工具和资源,以便他们能更好地进行创新和应用开发。
综上所述,DeepSeek V3和R1在开源生态与商业化策略上各有侧重。V3通过广泛的兼容性和框架集成,增强了其在自然语言处理领域的影响力;而R1则凭借开放协议和灵活应用,为逻辑推理任务提供了一种强大而经济实惠的解决方案。开发人员可以根据项目需求选择合适的平台,以充分发挥这两款模型的潜力。
总结
在本文中,我们详细探讨了DeepSeek V3和R1在模型定位、架构设计、性能表现、应用场景、部署成本以及开源生态等方面的差异。这两款模型各自展现了深度求索(DeepSeek)公司在AI技术发展上的不同侧重和创新理念。
- DeepSeek V3:作为一个通用的自然语言处理模型,V3凭借其混合专家架构(MoE)、多头隐式注意力(MLA)及动态负载均衡机制,在多模态任务处理和长文本生成方面表现出色。其低成本的API定价和广泛的硬件兼容性,使得V3成为企业级NLP任务的理想选择。
- DeepSeek R1:专注于复杂逻辑推理任务,R1通过强化学习范式和动态门控机制提升了推理能力,并以“思维链”展示增强了结果的透明度。其开放的MIT协议和轻量化版本支持,使得R1在科研、算法交易等领域展现出强大的应用潜力。
如何选择
- 选择DeepSeek V3:如果您的项目需要高效处理多语言、长文本或其他通用NLP任务,并且希望在成本上具有优势,那么V3是一个非常合适的选择。它不仅提供了强大的自然语言处理能力,还通过开源支持为开发人员提供了灵活的开发环境。
- 选择DeepSeek R1:如果您的需求集中在数学证明、代码生成、决策优化等复杂逻辑推理任务,并且对推理过程的可解释性有较高要求,那么R1无疑是最佳选择。其强化学习训练方法和开放协议为您提供了创新和商业应用的广阔空间。
总之,DeepSeek V3和R1各自具备独特的优势和适用场景,它们之间的互补性体现了深度求索公司在技术路径上的多样性。开发人员可以根据具体项目需求,充分利用这两款模型提供的技术能力,以实现最佳效果并推动前沿AI应用的发展。
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以在文末CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享

AI产品经理,0基础小白入门指南
作为一个零基础小白,如何做到真正的入局AI产品?
什么才叫真正的入局?
是否懂 AI、是否懂产品经理,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
你是否遇到这些问题:
1、传统产品经理
不懂Al无法对AI产品做出判断,和技术沟通丧失话语权
不了解 AI产品经理的工作流程、重点
2、互联网业务负责人/运营
对AI焦虑,又不知道怎么落地到业务中想做定制化AI产品并落地创收缺乏实战指导
3、大学生/小白
就业难,不懂技术不知如何从事AI产品经理想要进入AI赛道,缺乏职业发展规划,感觉遥不可及
为了帮助开发者打破壁垒,快速了解AI产品经理核心技术原理,学习相关AI产品经理,及大模型技术。从原理出发真正入局AI产品经理。
这里整理了一些AI产品经理学习资料包给大家
📖AI产品经理经典面试八股文
📖大模型RAG经验面试题
📖大模型LLMS面试宝典
📖大模型典型示范应用案例集99个
📖AI产品经理入门书籍
📖生成式AI商业落地白皮书
🔥作为AI产品经理,不仅要懂行业发展方向,也要懂AI技术,可以帮助大家:
✅深入了解大语言模型商业应用,快速掌握AI产品技能
✅掌握AI算法原理与未来趋势,提升多模态AI领域工作能力
✅实战案例与技巧分享,避免产品开发弯路
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图
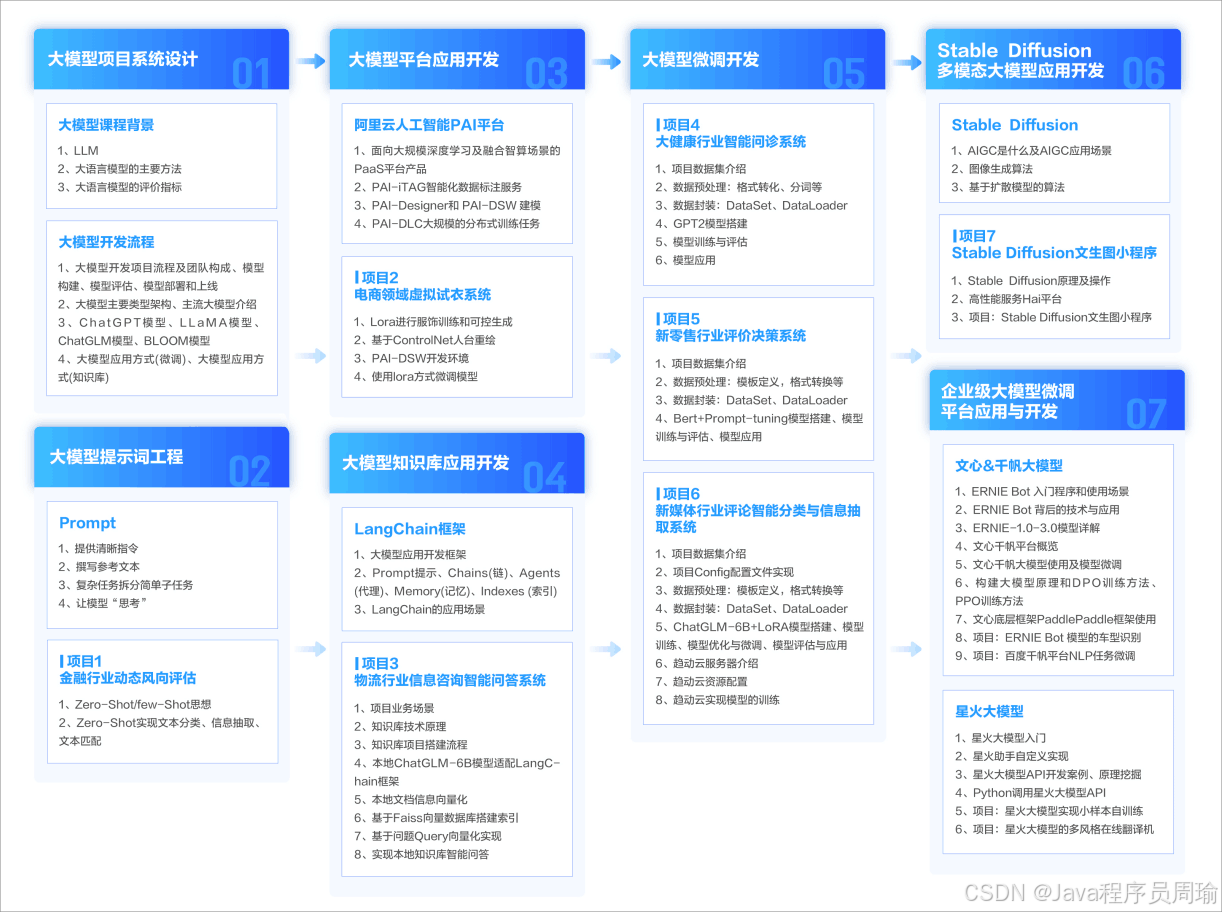
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享免费领取【保证100%免费】🆓

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 19
19 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)