ChatGPT、deepseek、豆包、Kimi、通义千问、腾讯元宝、文心一言、智谱清言代码能力对比
ChatGPT、deepseek、豆包、Kimi、通义千问、腾讯元宝、文心一言、智谱清言代码能力对比
·
均使用测试时的最强模型
均是一次对话,对话内容一样
均开启深度思考
能联网的都联网了,但是作用不大,因为蓝桥杯刚考完,洛谷题目刚上传没多久
问题一测试了两遍
从问题三开始不再测试智谱清言(它思考时间太长了,前两个问题测试了3次均陷入死循环)
从问题三开始不再进行详细记录(篇幅太长了),但会给出问题
总结
| 模型 | 问题一得分 | 问题二得分 | 问题三 |
|---|---|---|---|
| Claude 4 | - | - | 100 |
| Gemini 2.5 Pro | - | - | 100 |
| ChatGPT | 55/0 | 100 | 90(GPT-4.1) |
| deepseek | 0/0 | 100 | 30(V3-0324)、20(R1) |
| 豆包 | 0/0 | 100 | 20(Doubao-1.5-thinking-pro)、10(Doubao-1.5-pro) |
| Kimi | 一次陷入死循环,一次0分 | 100 | |
| 通义千问 | 0/0 | 100 | |
| 腾讯元宝 | 0/0 | 100 | |
| 文心一言 | 0/0 | 100 | |
| 智谱清言 | 两次均陷入死循环 | 陷入死循环 |
详细记录如下
问题1(测试时间2025/4/26)
问题一解答
-
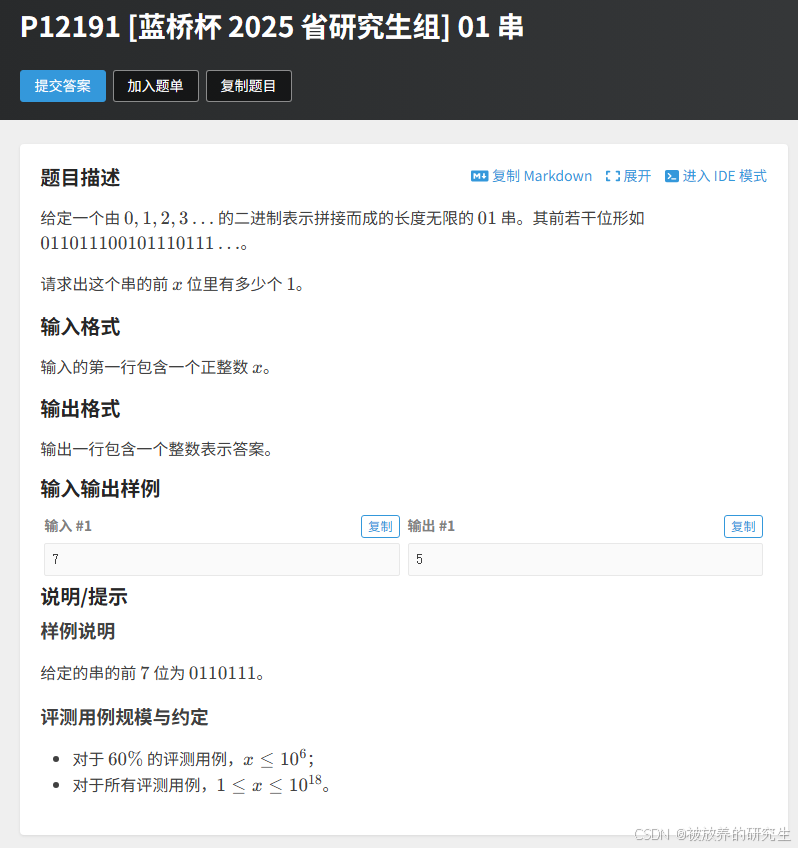
ChatGPT
-
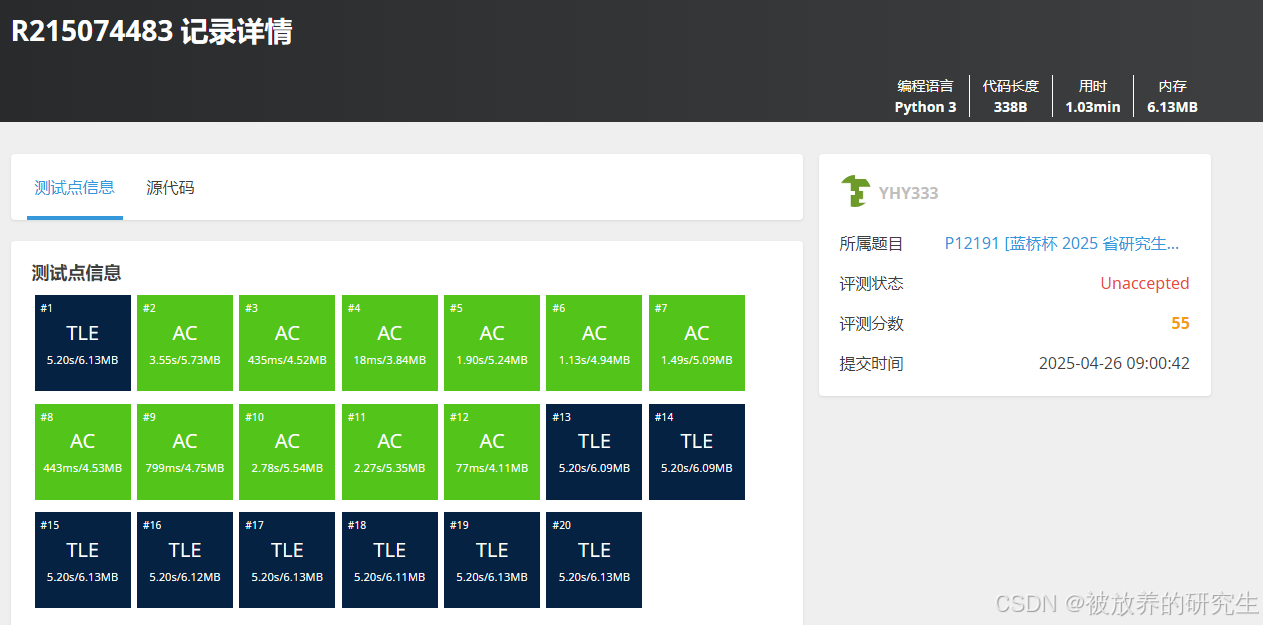
deepseek R1
-
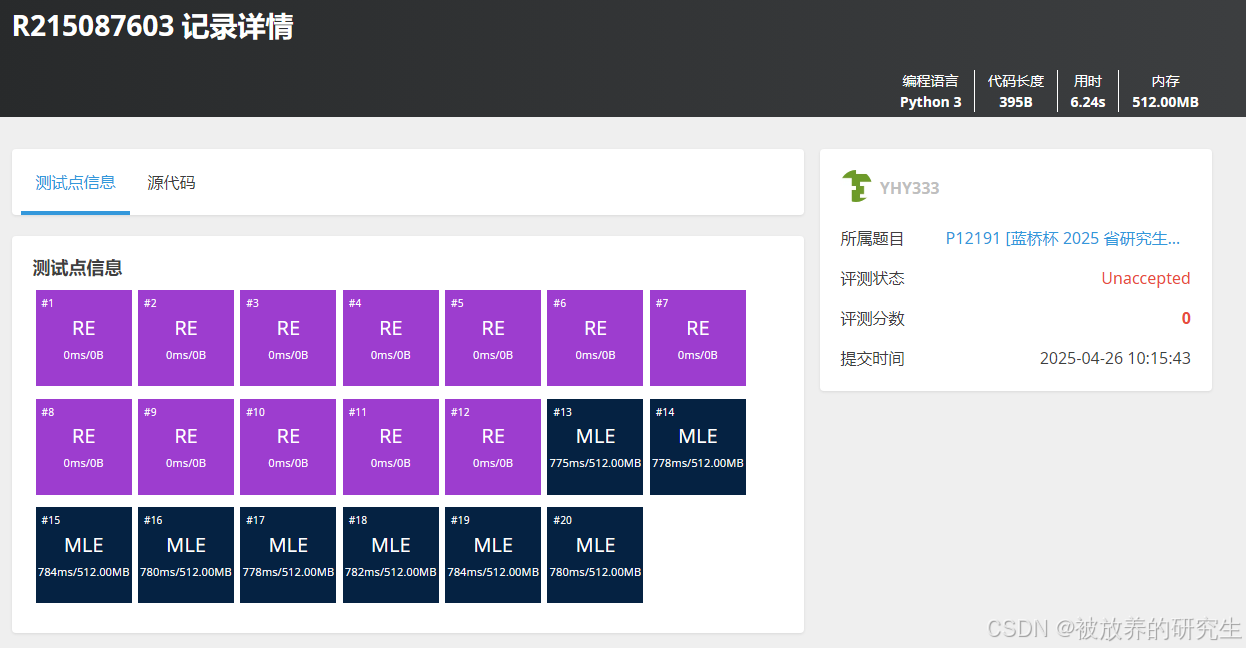
豆包
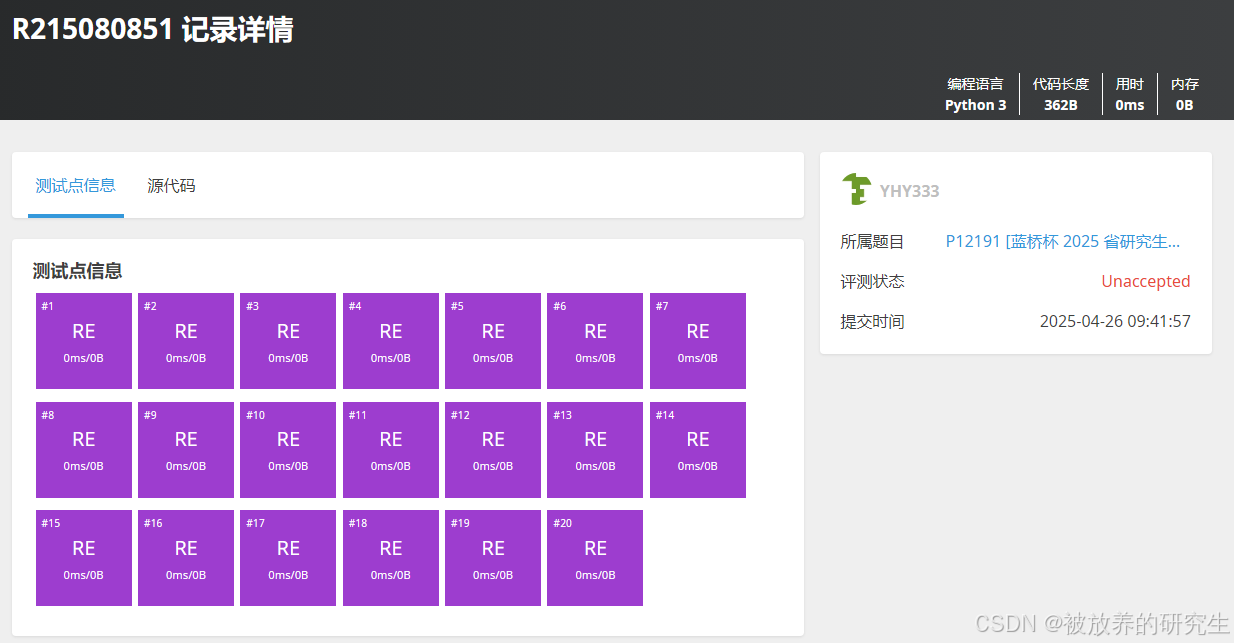
-
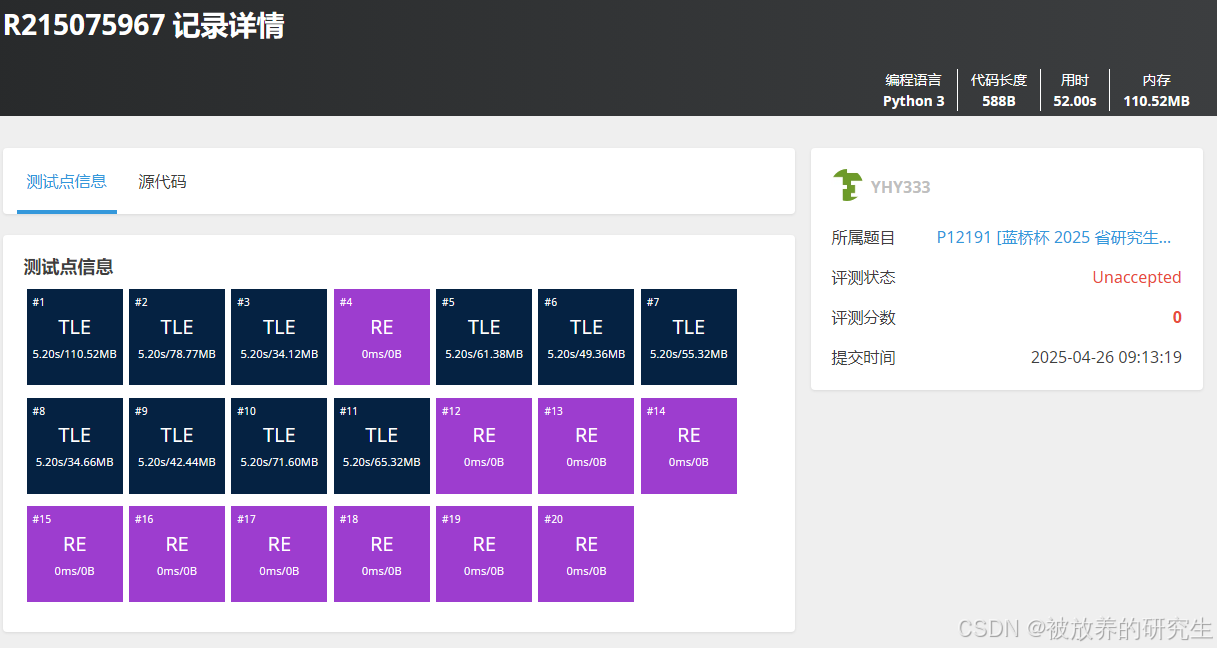
Kimi直接死循环
-
通义千问
-
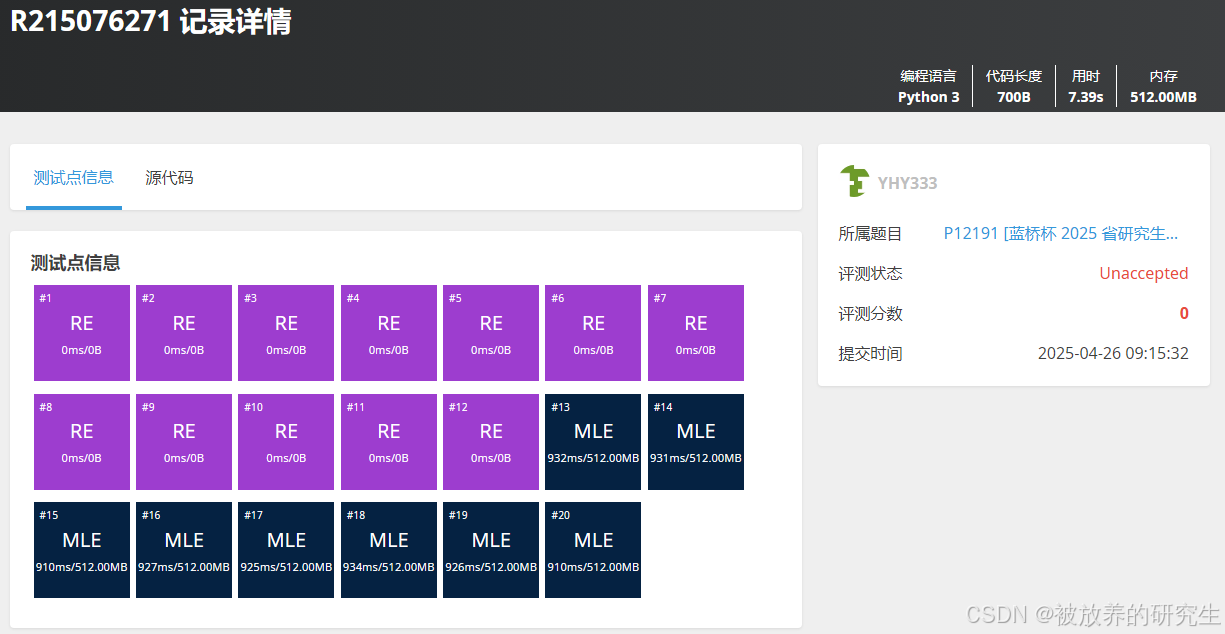
腾讯元宝deepseek模型R1
-
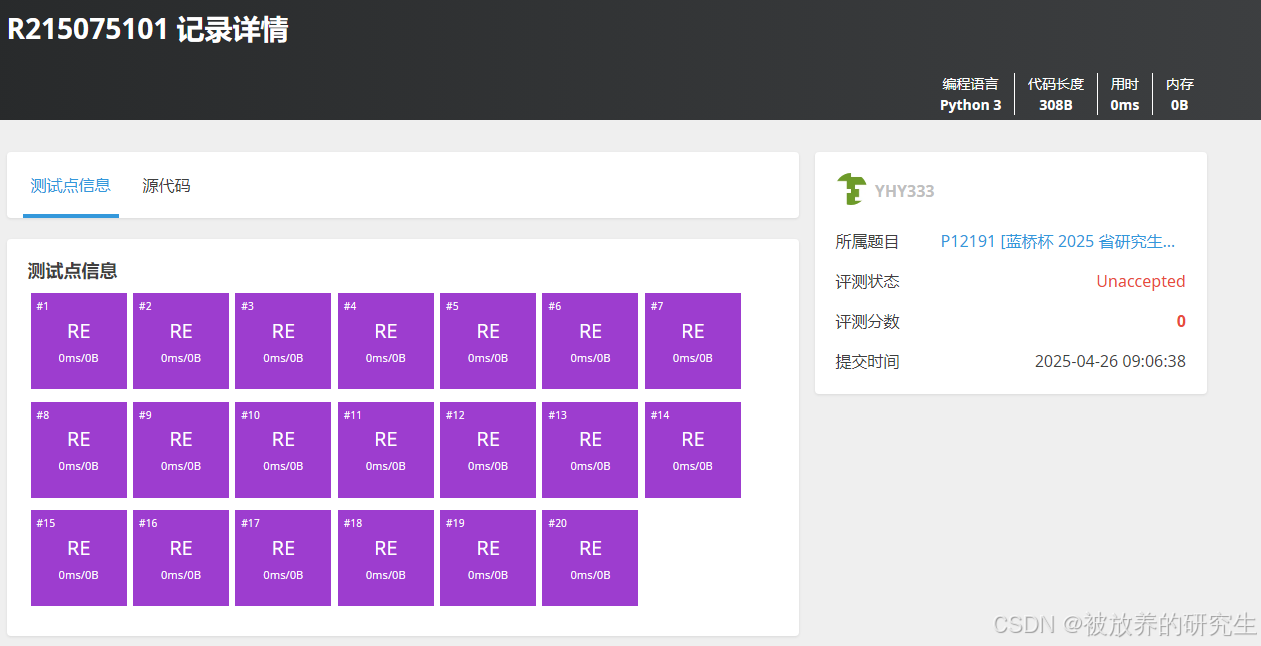
文心一言X1Turbo
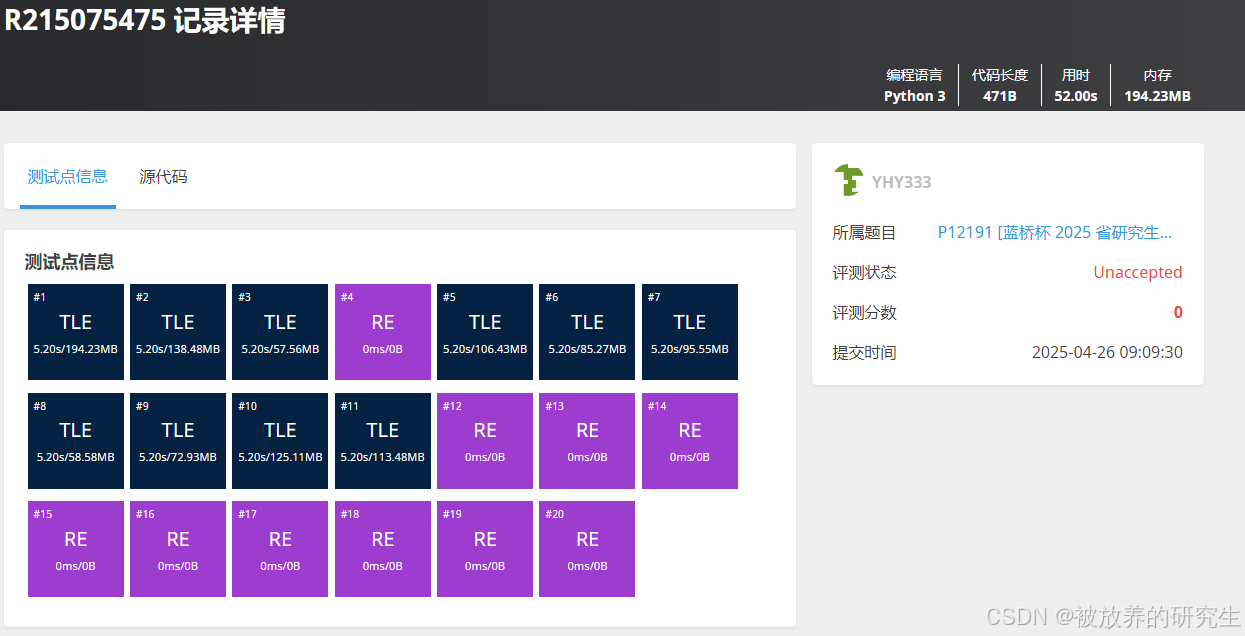
-
智谱清言直接死循环
题目二(非蓝桥杯题目)
上一题难度过大,所以降低难度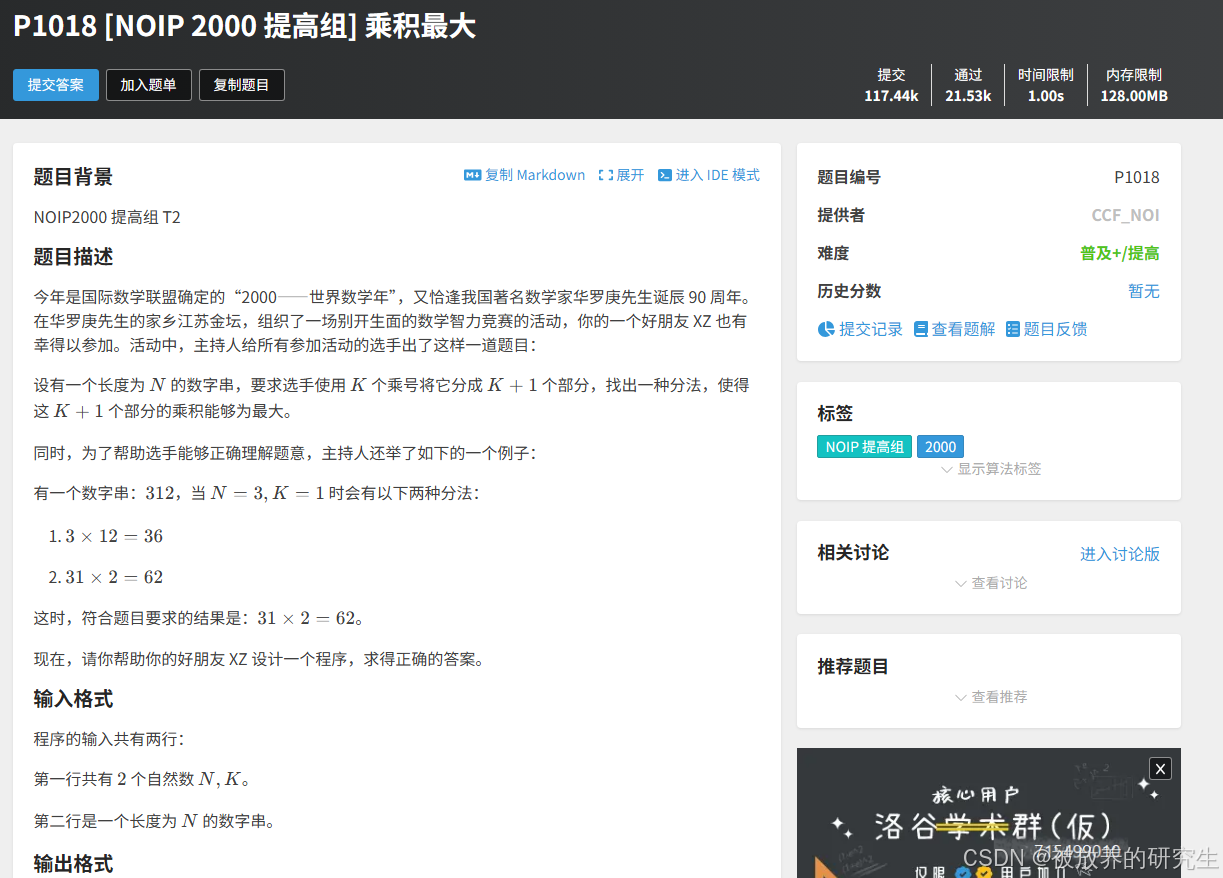
题目二解答
-
ChatGPT
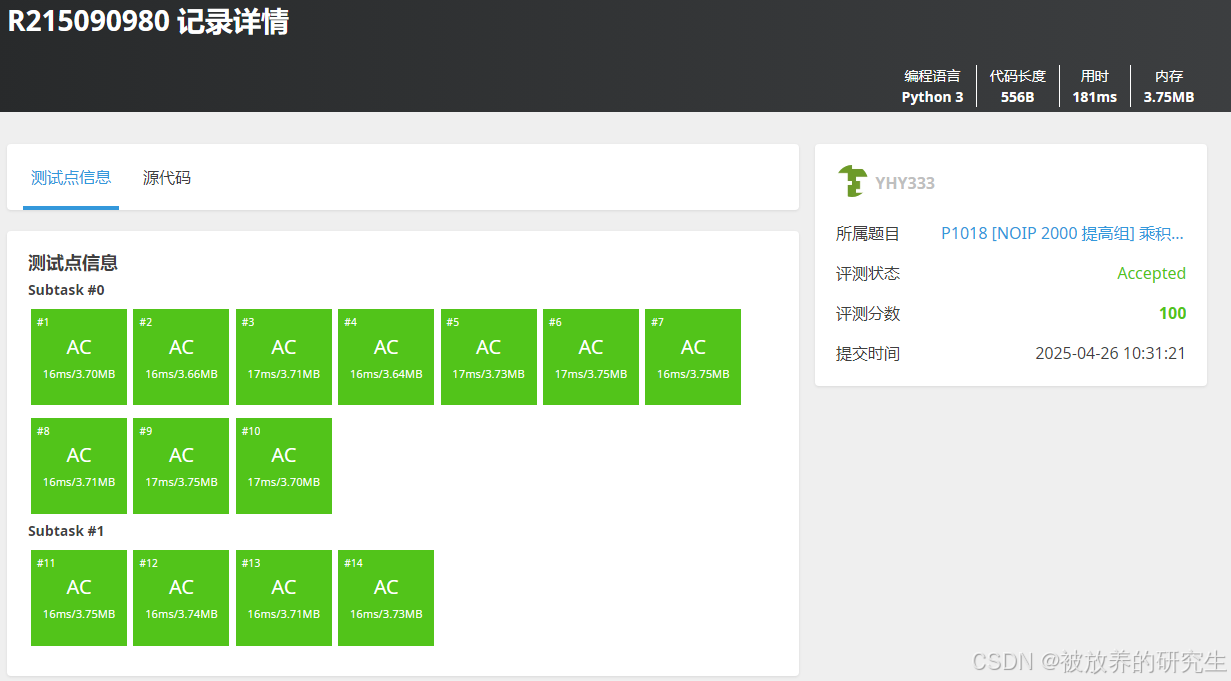
-
deepseekR1
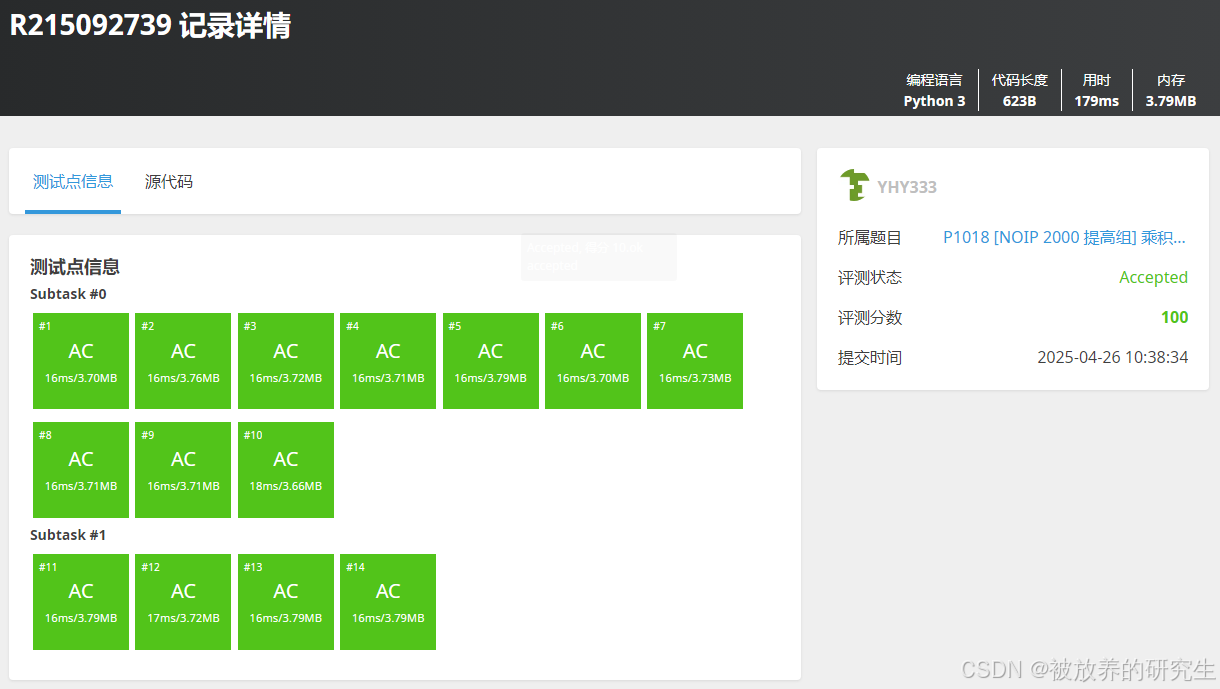
-
豆包
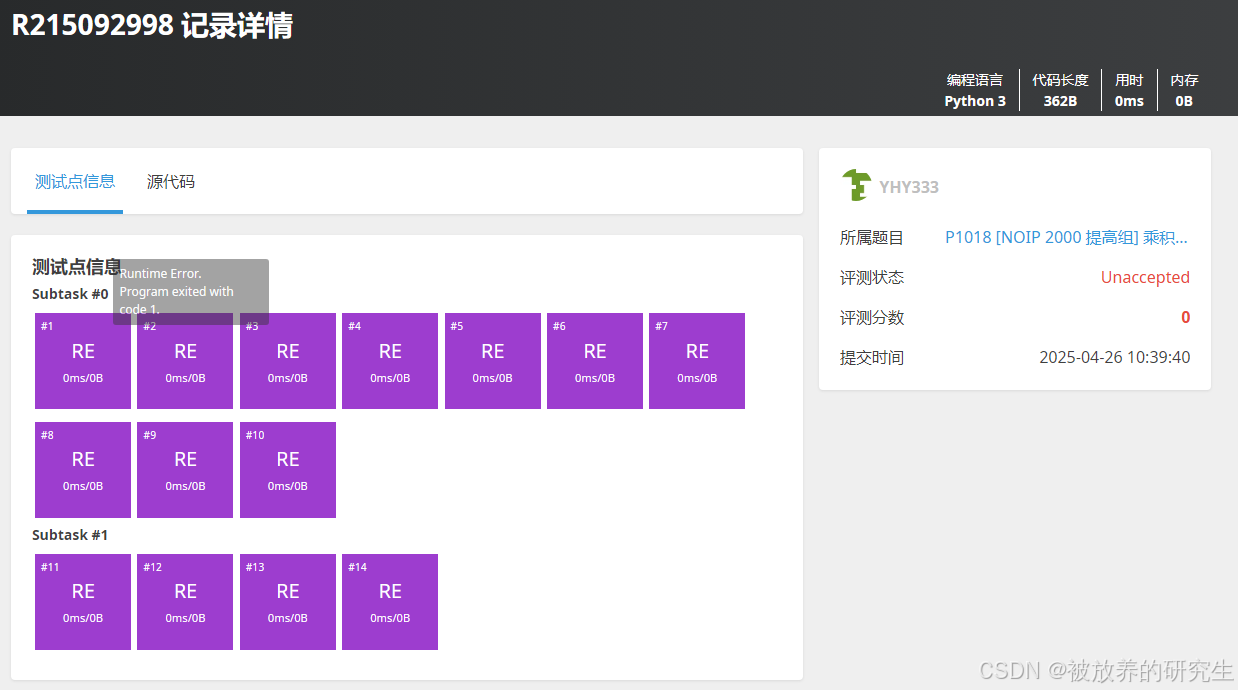
-
Kimi
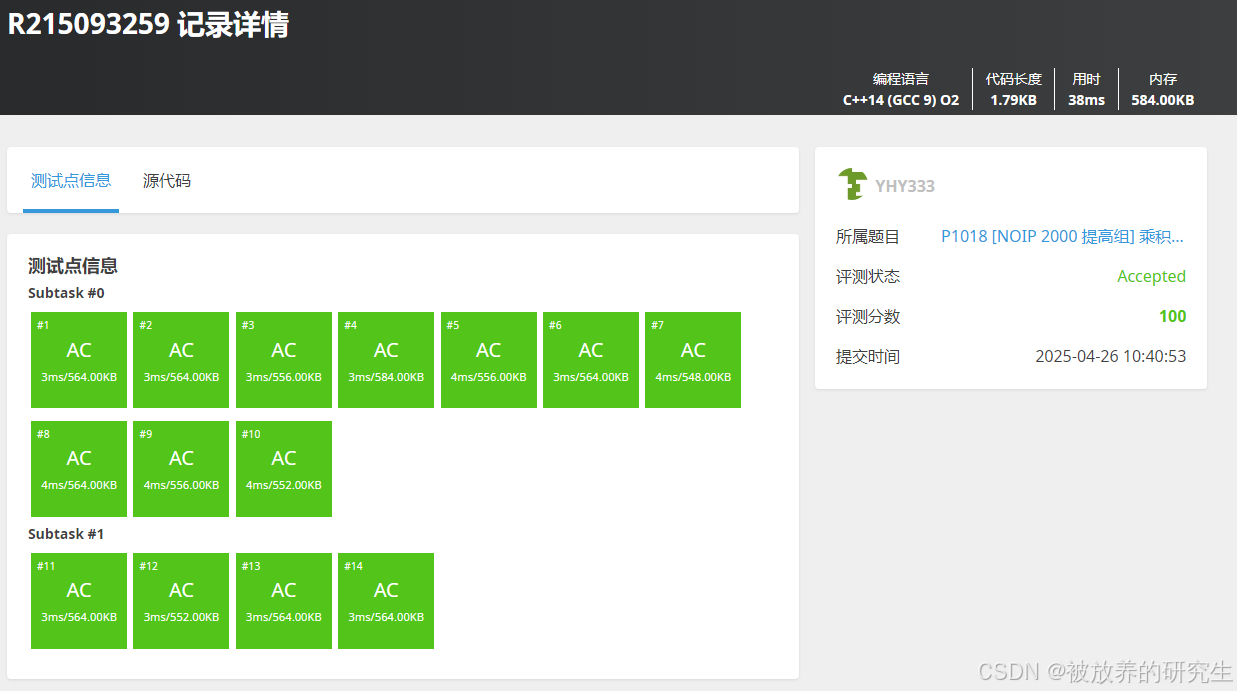
-
通义千问
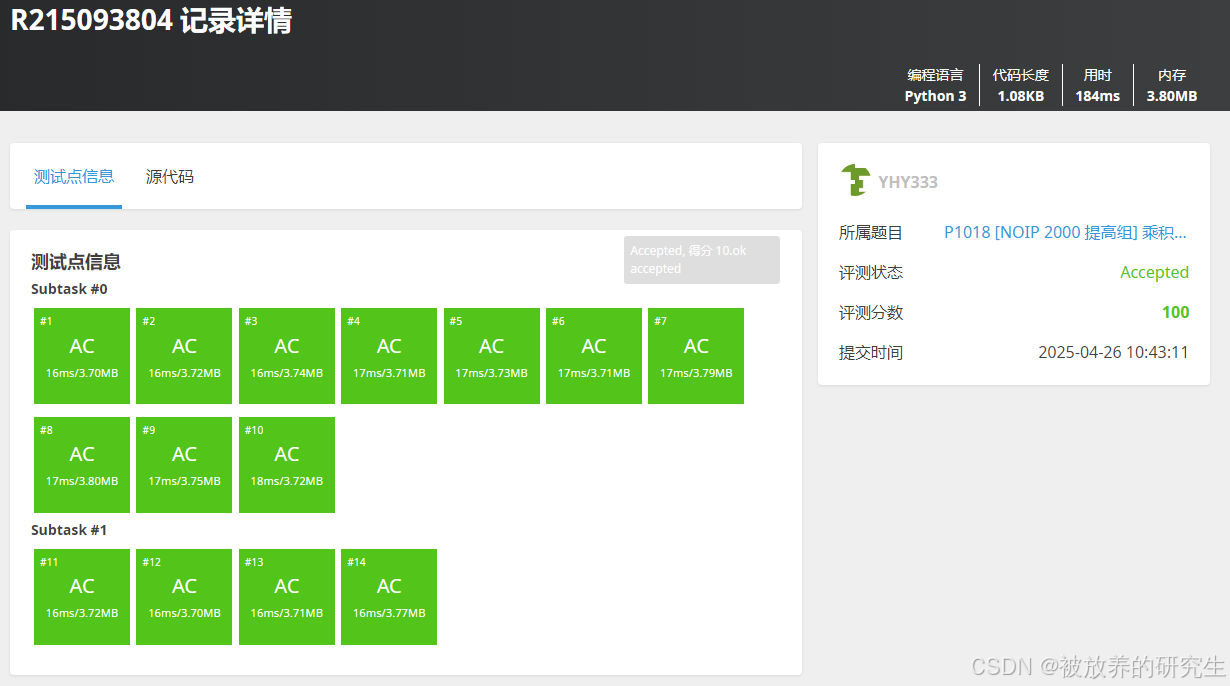
-
腾讯元宝deepseekR1
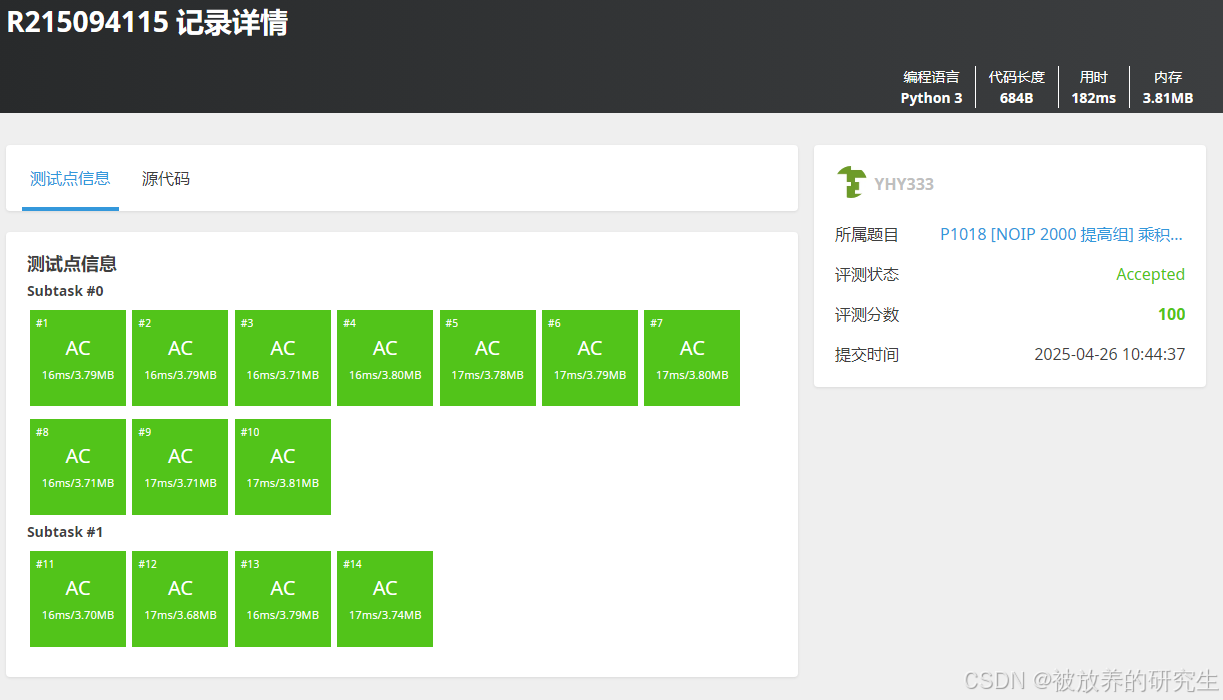
-
文心一言
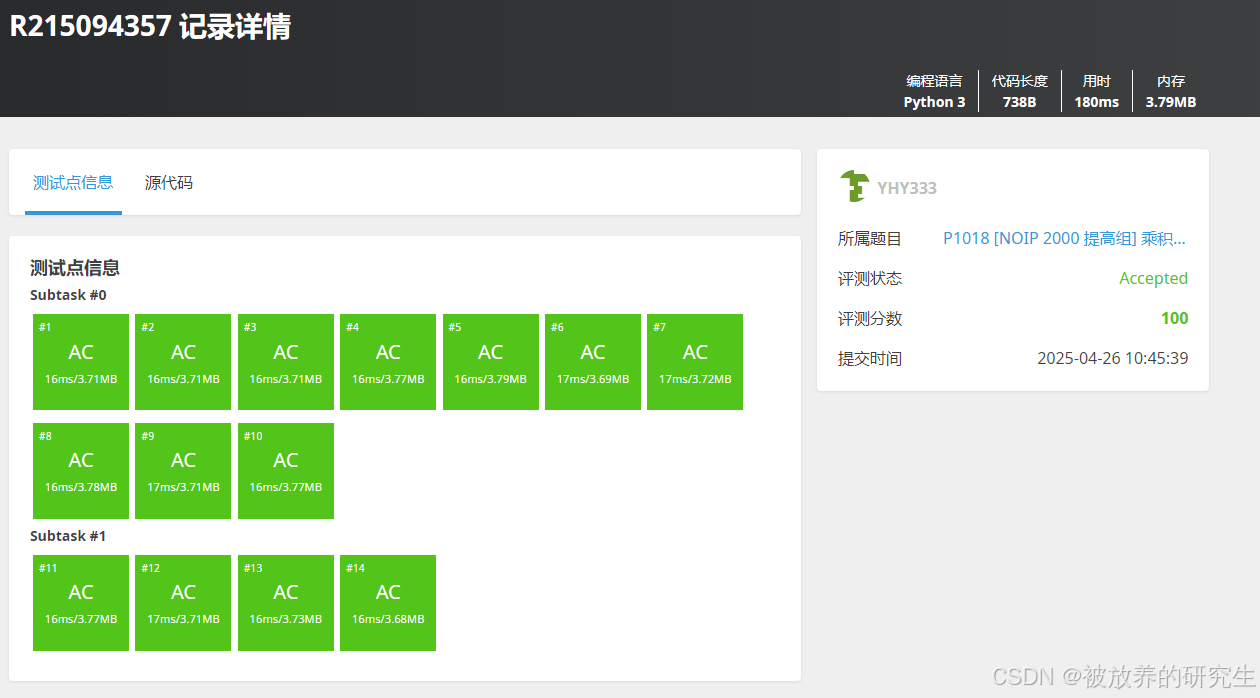
-
智谱清言再次死循环
问题三(P12142 [蓝桥杯 2025 省 A] 黑客)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)