从零开始FastGPT本地部署-Windows
从零开始FastGPT本地部署|Windows一、配置Fast-GPT1.新建文件2.启动docker3.启动Fast-GPT二、FastAPI 部署国内大模型2.1 先领下API-KEY2.2 OneAPI 添加渠道和令牌2.3 修改fastgpt配置2.3.1 docker-compose.yaml 改和2.3.2 config.json修改对话模型和向量模型2.4 重启FastAPI一、配置
从零开始FastGPT本地部署|Windows
一、Windows 11 检查wsl环境
- 启用适用于 Linux 的 Windows 子系统
- 启用虚拟机功能
- 将 WSL 2 设置为默认版本
- 更新wsl内核
- 列出发行版本
- 安装默认Ubuntu
二、配置Fast-GPT
1.新建文件
2.启动docker
3.启动Fast-GPT
三、FastAPI 部署国内大模型
2.1 先领下API-KEY
2.2 OneAPI 添加渠道和令牌
2.3 修改fastgpt配置
2.3.1 docker-compose.yaml 改OPENAI_BASE_URL 和 CHAT_API_KEY
2.3.2 config.json修改对话模型和向量模型
2.4 重启FastAPI
一、Windows 11 检查wsl环境
8. 启用适用于 Linux 的 Windows 子系统
以管理员身份打开 PowerShell(“开始”菜单 >“PowerShell” >单击右键 >“以管理员身份运行”),然后输入以下命令:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
- 启用虚拟机功能
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
- 将 WSL 2 设置为默认版本
wsl --set-default-version 2
- 更新wsl内核
wsl --update
- 列出发行版本
wsl -l -o
- 安装默认Ubuntu
wsl --install
此命令将启用运行 WSL 并安装 Linux 的 Ubuntu 发行版所需的功能。
PS: 手动安装
微软提供了手动下载安装的方法: Manual installation steps for older versions of WSL
步骤为:
下载:
Invoke-WebRequest -Uri https://aka.ms/wslubuntu -OutFile Ubuntu.appx -UseBasicParsing
其中wslubuntu2004 为 需要下载安装的distribution名称,这个是Ubuntu-20.04,可以根据需要下载其他distribution( ubuntu-22.04 为wslubuntu2204)
所有distribute 分发名称:
Ubuntu
Ubuntu 22.04 LTS
Ubuntu 20.04
Ubuntu 20.04 ARM
Ubuntu 18.04
Ubuntu 18.04 ARM
Ubuntu 16.04
Debian GNU/Linux
Kali Linux
SUSE Linux Enterprise Server 12
SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP3
openSUSE Tumbleweed
openSUSE Leap 15.3
openSUSE Leap 15.2
Oracle Linux 8.5
Oracle Linux 7.9
Fedora Remix for WSL
安装:
Add-AppxPackage .\ubuntu.appx
二、配置Fast-GPT
1.新建文件
新建文件夹fastgpt
下载https://gitee.com/mirrors/FastGPT/repository/blazearchive/main.zip
在文件夹下,新建文件config.json,
新建文件docker-compose.yml
config.json如下,或Github链接
// 已使用 json5 进行解析,会自动去掉注释,无需手动去除
{
"feConfigs": {
"lafEnv": "https://laf.dev" // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。
},
"systemEnv": {
"vectorMaxProcess": 15,
"qaMaxProcess": 15,
"pgHNSWEfSearch": 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
},
"llmModels": [
{
"model": "gpt-4o-mini", // 模型名(对应OneAPI中渠道的模型名)
"name": "gpt-4o-mini", // 模型别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 125000, // 最大上下文
"maxResponse": 16000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
},
{
"model": "gpt-4o",
"name": "gpt-4o",
"avatar": "/imgs/model/openai.svg",
"maxContext": 125000,
"maxResponse": 4000,
"quoteMaxToken": 120000,
"maxTemperature": 1.2,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": false,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"model": "text-embedding-ada-002", // 模型名(与OneAPI对应)
"name": "Embedding-2", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
},
{
"model": "text-embedding-3-large",
"name": "text-embedding-3-large",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100,
"defaultConfig": {
"dimensions": 1024
}
},
{
"model": "text-embedding-3-small",
"name": "text-embedding-3-small",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100
}
],
"reRankModels": [],
"audioSpeechModels": [
{
"model": "tts-1",
"name": "OpenAI TTS1",
"charsPointsPrice": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"whisperModel": {
"model": "whisper-1",
"name": "Whisper1",
"charsPointsPrice": 0
}
}
docker-compose.yml如下,或Github链接
数据库的默认账号和密码仅首次运行时设置有效
如果修改了账号密码,记得改数据库和项目连接参数,别只改一处~
该配置文件只是给快速启动,测试使用。正式使用,记得务必修改账号密码,以及调整合适的知识库参数,共享内存等。
如何无法访问 dockerhub 和 git,可以用阿里云(阿里云没有arm包)
version: '3.3'
services:
# db
pg:
image: pgvector/pgvector:0.7.0-pg15 # docker hub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.7.0 # 阿里云
container_name: pg
restart: always
ports: # 生产环境建议不要暴露
- 5432:5432
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=postgres
volumes:
- ./pg/data:/var/lib/postgresql/data
mongo:
image: mongo:5.0.18 # dockerhub
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
# image: mongo:4.4.29 # cpu不支持AVX时候使用
container_name: mongo
restart: always
ports:
- 27017:27017
networks:
- fastgpt
command: mongod --keyFile /data/mongodb.key --replSet rs0
environment:
- MONGO_INITDB_ROOT_USERNAME=myusername
- MONGO_INITDB_ROOT_PASSWORD=mypassword
volumes:
- ./mongo/data:/data/db
entrypoint:
- bash
- -c
- |
openssl rand -base64 128 > /data/mongodb.key
chmod 400 /data/mongodb.key
chown 999:999 /data/mongodb.key
echo 'const isInited = rs.status().ok === 1
if(!isInited){
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
}' > /data/initReplicaSet.js
# 启动MongoDB服务
exec docker-entrypoint.sh "$$@" &
# 等待MongoDB服务启动
until mongo -u myusername -p mypassword --authenticationDatabase admin --eval "print('waited for connection')" > /dev/null 2>&1; do
echo "Waiting for MongoDB to start..."
sleep 2
done
# 执行初始化副本集的脚本
mongo -u myusername -p mypassword --authenticationDatabase admin /data/initReplicaSet.js
# 等待docker-entrypoint.sh脚本执行的MongoDB服务进程
wait $$!
# fastgpt
sandbox:
container_name: sandbox
image: ghcr.io/labring/fastgpt-sandbox:latest # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:latest # 阿里云
networks:
- fastgpt
restart: always
fastgpt:
container_name: fastgpt
image: ghcr.io/labring/fastgpt:v4.8.9 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.9 # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
- sandbox
restart: always
environment:
# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。
- DEFAULT_ROOT_PSW=1234
# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。
- OPENAI_BASE_URL=http://oneapi:3000/v1
# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)
- CHAT_API_KEY=sk-fastgpt
# 数据库最大连接数
- DB_MAX_LINK=30
# 登录凭证密钥
- TOKEN_KEY=any
# root的密钥,常用于升级时候的初始化请求
- ROOT_KEY=root_key
# 文件阅读加密
- FILE_TOKEN_KEY=filetoken
# MongoDB 连接参数. 用户名myusername,密码mypassword。
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
# pg 连接参数
- PG_URL=postgresql://username:password@pg:5432/postgres
# sandbox 地址
- SANDBOX_URL=http://sandbox:3000
# 日志等级: debug, info, warn, error
- LOG_LEVEL=info
- STORE_LOG_LEVEL=warn
volumes:
- ./config.json:/app/data/config.json
# oneapi
mysql:
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mysql:8.0.36 # 阿里云
image: mysql:8.0.36
container_name: mysql
restart: always
ports:
- 3306:3306
networks:
- fastgpt
command: --default-authentication-plugin=mysql_native_password
environment:
# 默认root密码,仅首次运行有效
MYSQL_ROOT_PASSWORD: oneapimmysql
MYSQL_DATABASE: oneapi
volumes:
- ./mysql:/var/lib/mysql
oneapi:
container_name: oneapi
image: ghcr.io/songquanpeng/one-api:v0.6.7
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/one-api:v0.6.6 # 阿里云
ports:
- 3001:3000
depends_on:
- mysql
networks:
- fastgpt
restart: always
environment:
# mysql 连接参数
- SQL_DSN=root:oneapimmysql@tcp(mysql:3306)/oneapi
# 登录凭证加密密钥
- SESSION_SECRET=oneapikey
# 内存缓存
- MEMORY_CACHE_ENABLED=true
# 启动聚合更新,减少数据交互频率
- BATCH_UPDATE_ENABLED=true
# 聚合更新时长
- BATCH_UPDATE_INTERVAL=10
# 初始化的 root 密钥(建议部署完后更改,否则容易泄露)
- INITIAL_ROOT_TOKEN=fastgpt
volumes:
- ./oneapi:/data
networks:
fastgpt:
2.启动docker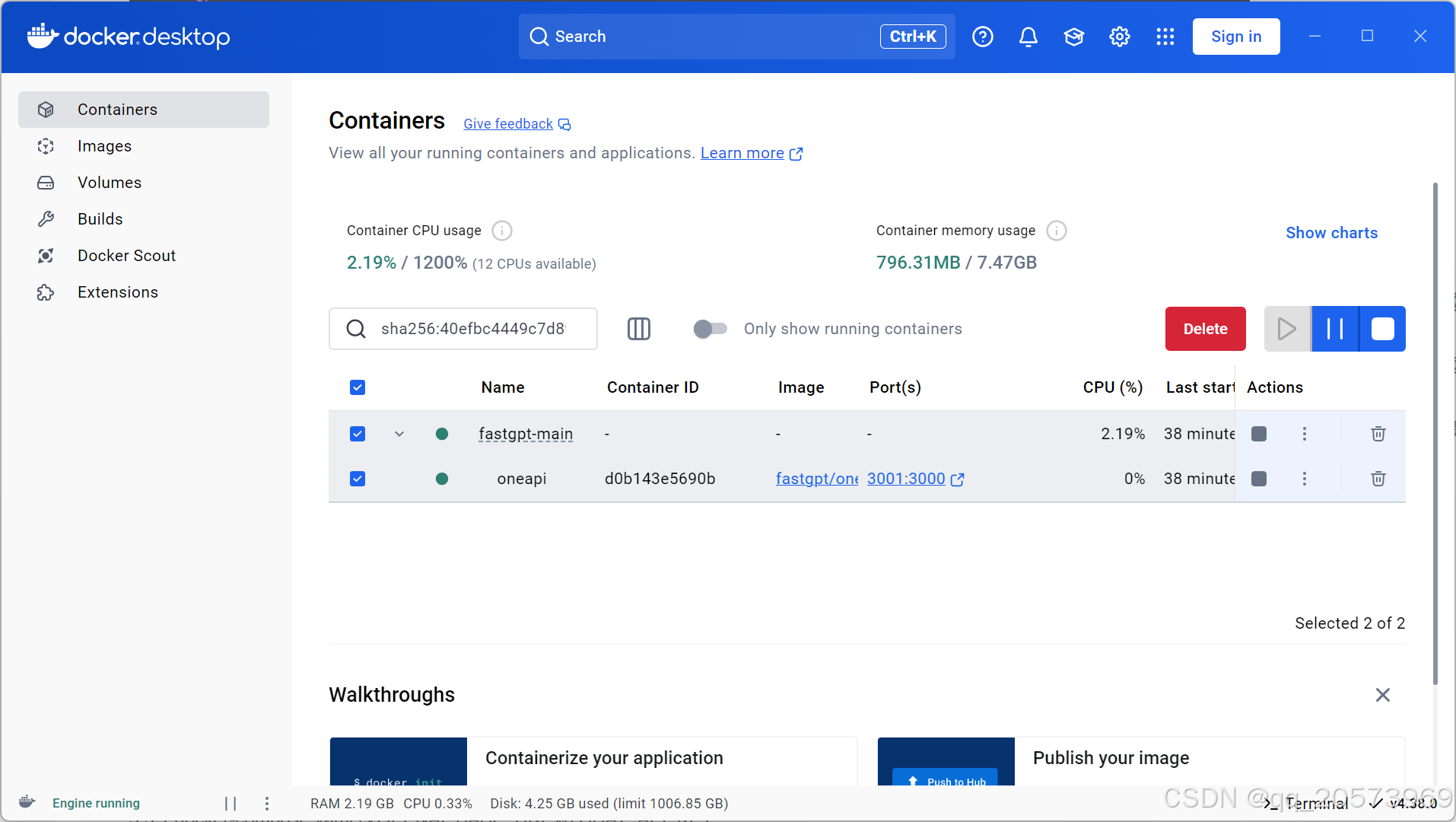
启动项目成功,依赖加载完成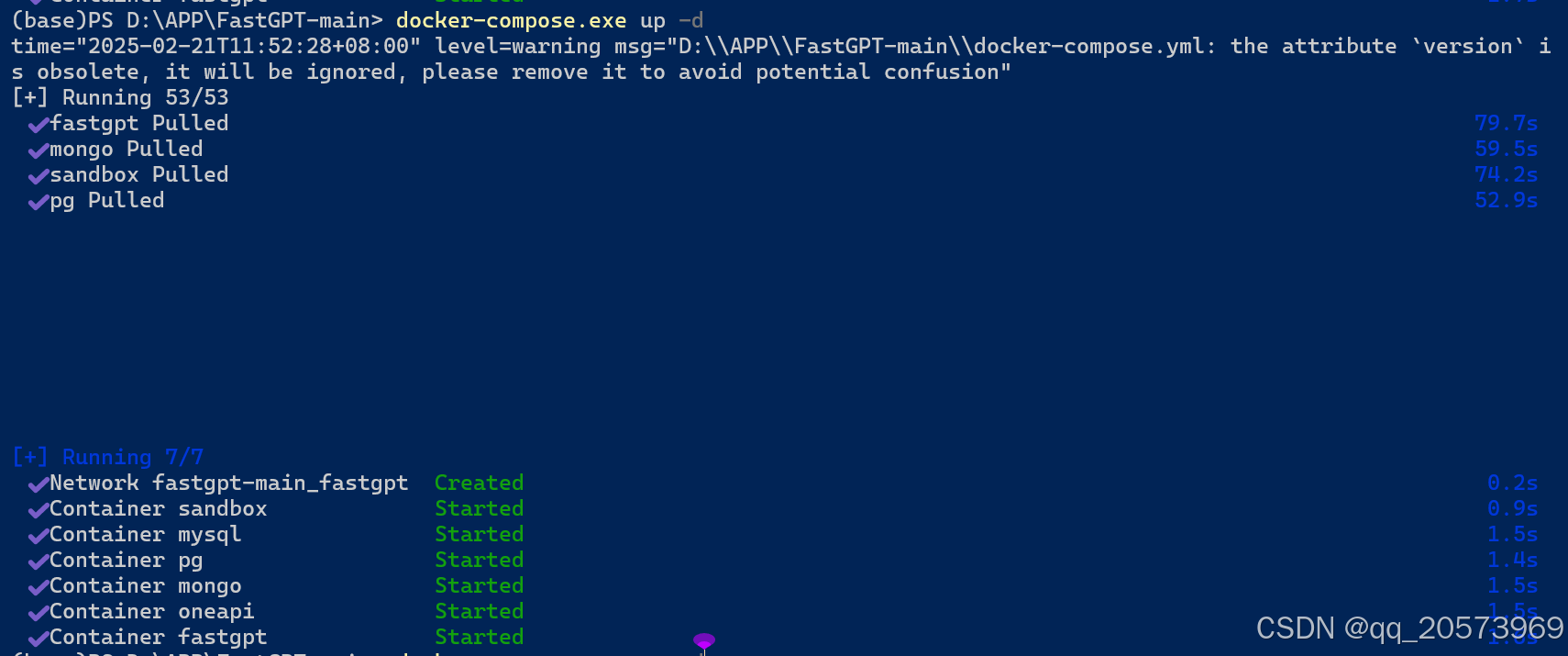
3.启动Fast-GPT
浏览器中输入127.0.0.1:3000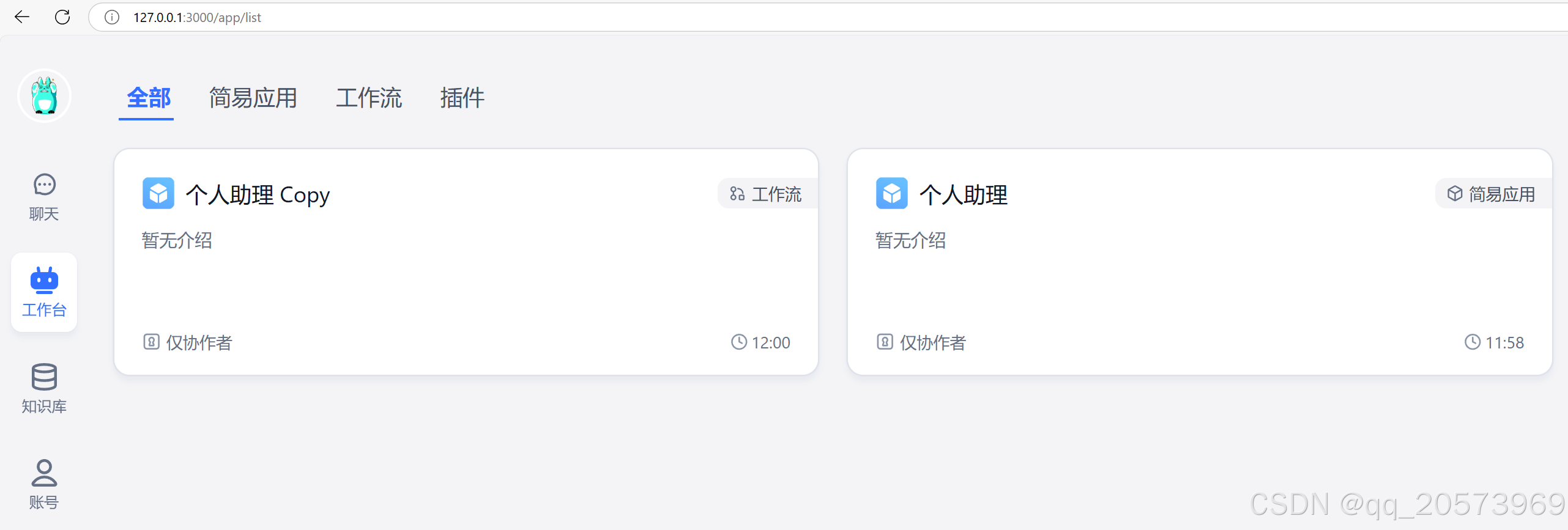
登录账号root,密码1234
4.启动One-API
浏览器中输入127.0.0.1:3001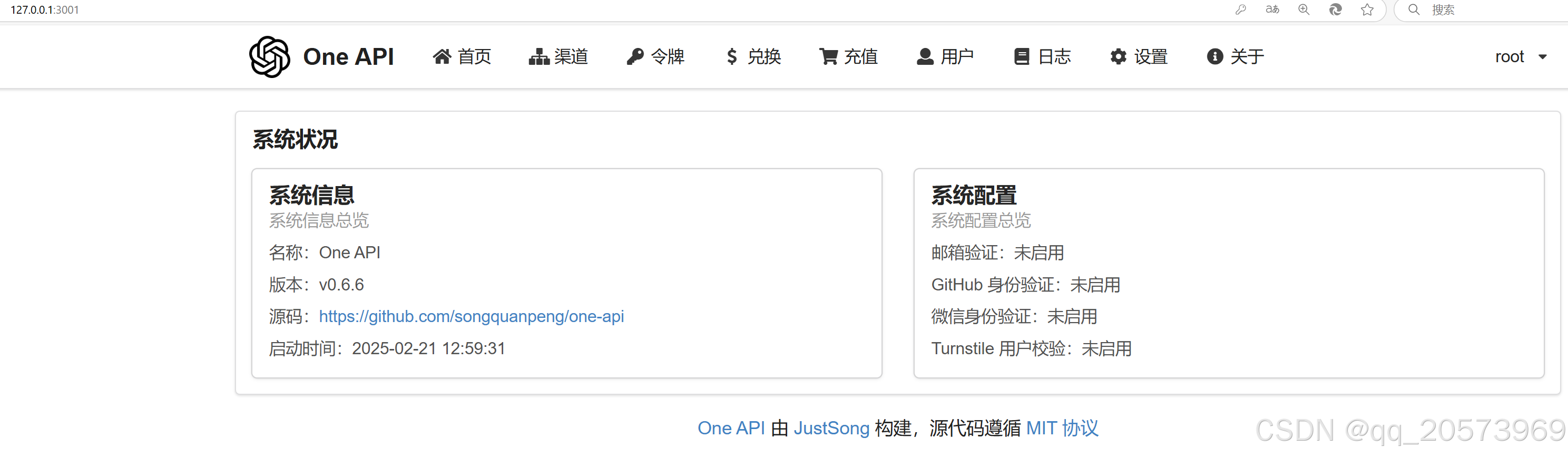
登录账号root,初始密码123456
一登录就要改密码,我的改为root123456
三、FastAPI 部署国内大模型
参考官方文档:使用 One API 接入 ollama、硅基流动 和本地模型
3. OneAPI 添加ollama渠道和令牌
添加渠道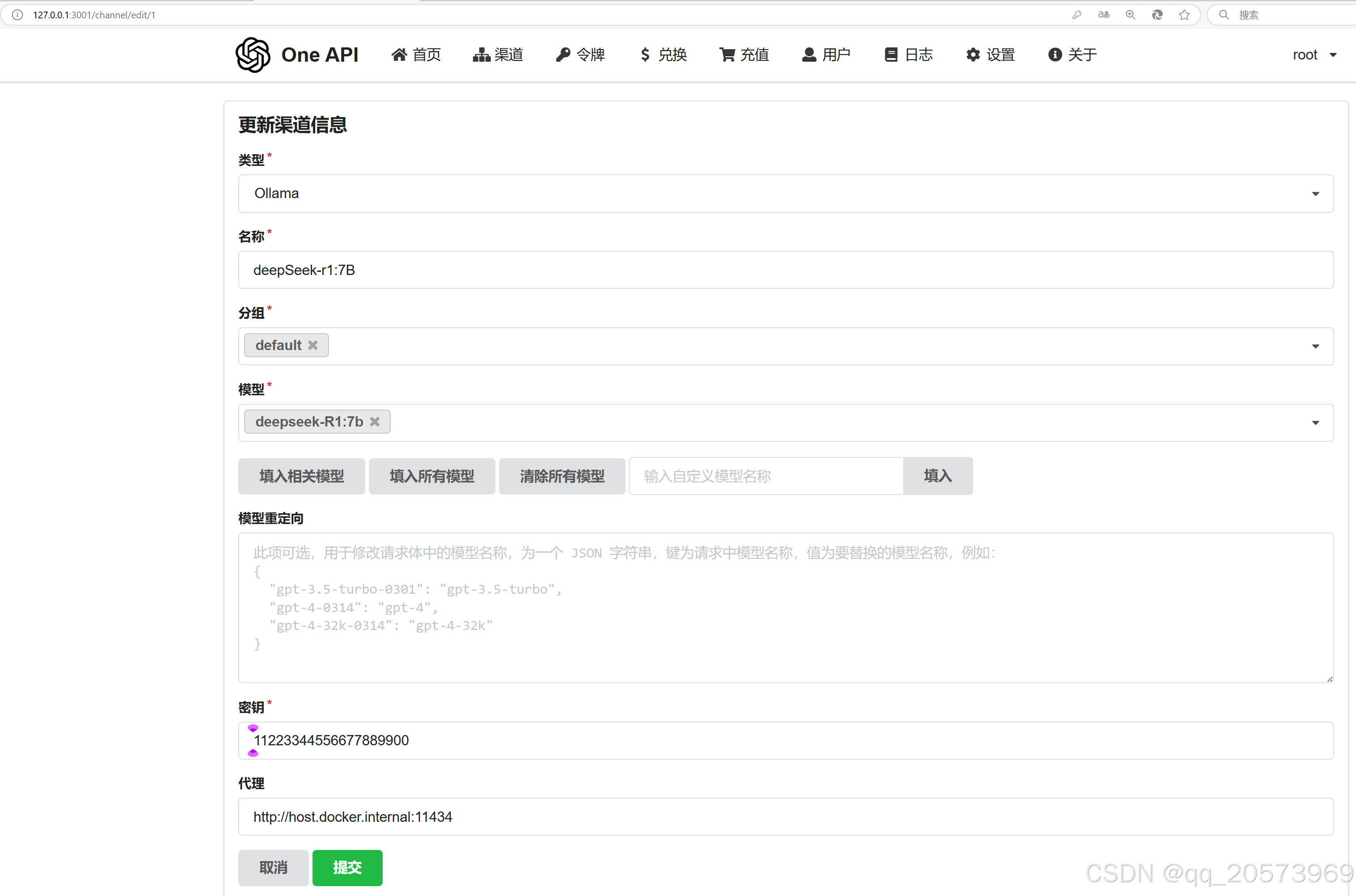
然后测试一下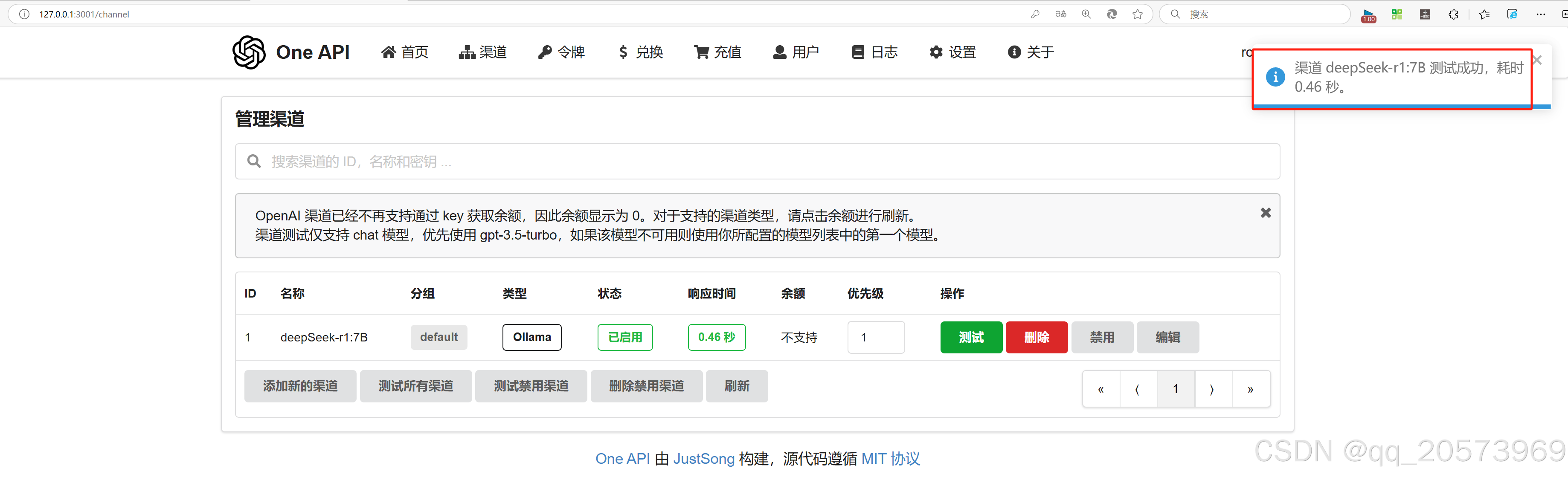
添加令牌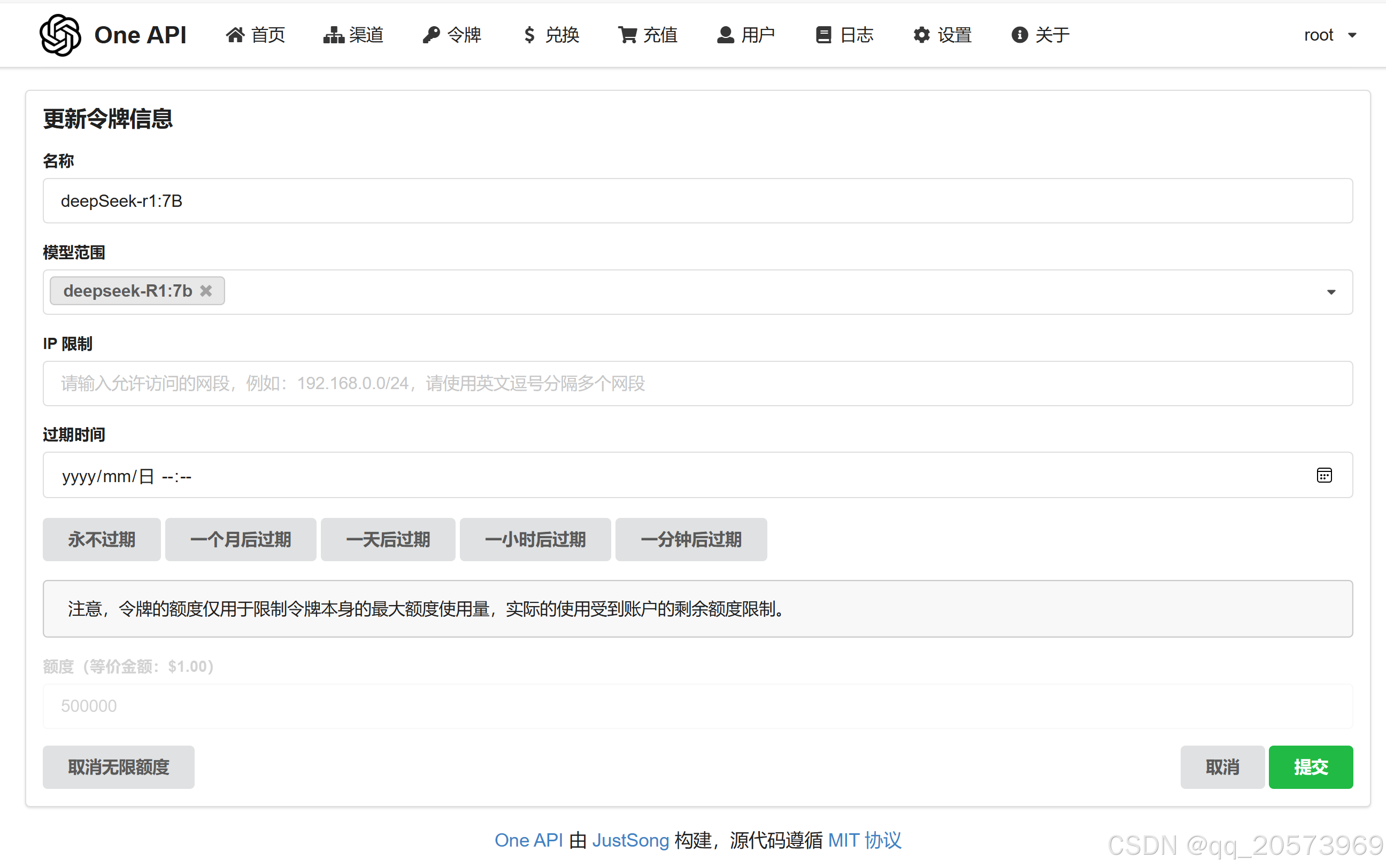
相同路数,添加硅基流动
3.3 修改fastgpt配置
3.3.1 docker-compose.yaml 改OPENAI_BASE_URL 和 CHAT_API_KEY
本地ollama地址
- OPENAI_BASE_URL=http://host.docker.internal:11434
API-KEY
- CHAT_API_KEY=sk-hcdVRKTpIzFnf11q0e5672105742450a801552779fC53942
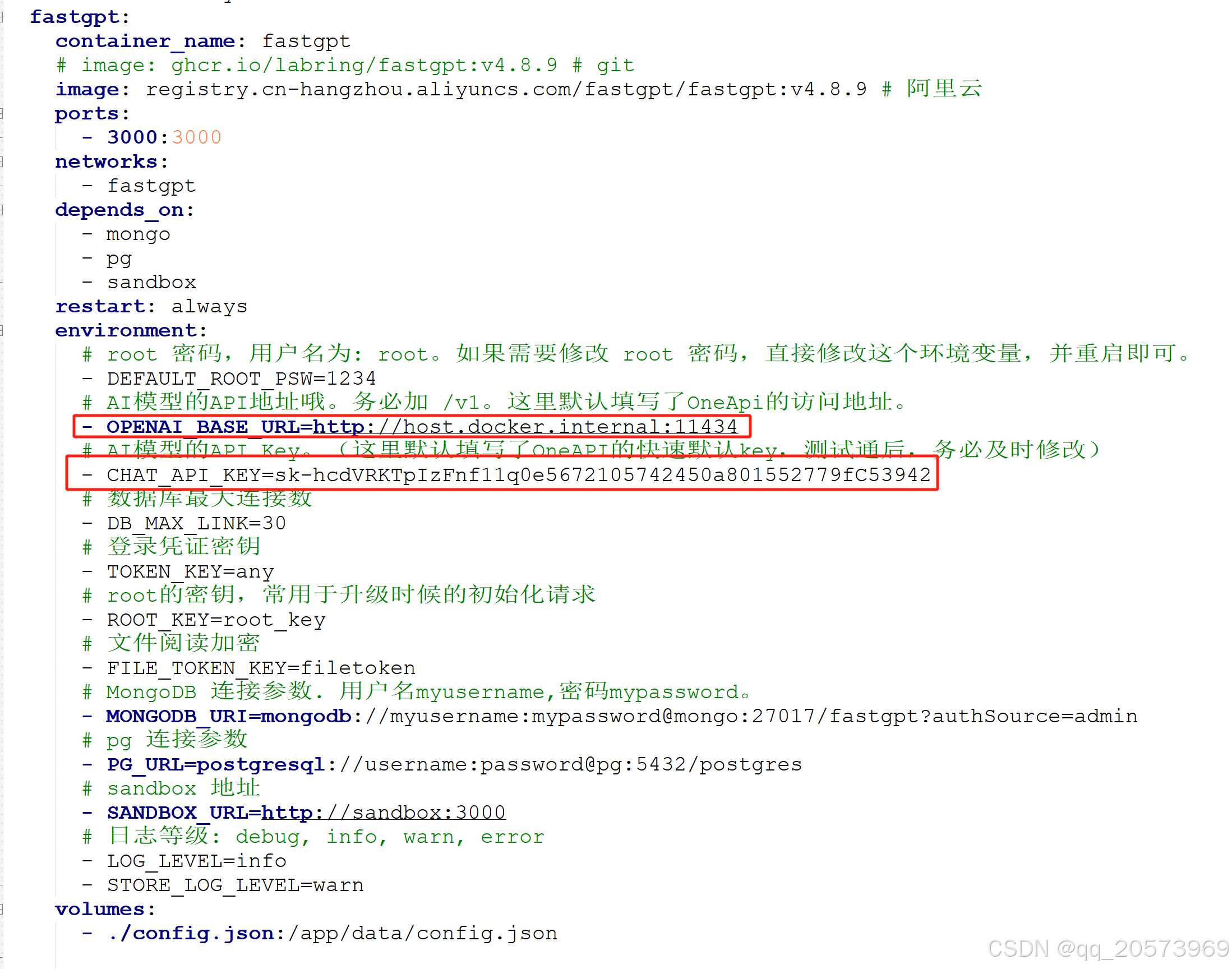
3.3.2 config.json修改对话模型和向量模型
修改对话模型的model和name
"llmModels": [
{
"model": "deepseek-r1:7B", // 模型名(对应OneAPI中渠道的模型名)
"name": "deepseek-r1-7B", // 模型别名-不能有冒号
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 125000, // 最大上下文
"maxResponse": 16000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
}
修改向量模型的model和name,才能跟数据库对话+语义检索
有以下4种可选,官网介绍
text-embedding-v1
text-embedding-async-v1
text-embedding-v2
text-embedding-async-v2
"vectorModels": [
{
"model": "text-embedding-v1", // 模型名(与OneAPI对应)
"name": "Embedding-1", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
},
{
"model": "text-embedding-v2",
"name": "Embedding-2",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 700,
"maxToken": 3000,
"weight": 100,
"defaultConfig": {
"dimensions": 1024
}
}
],
3.4 重启FastAPI
docker-compose down
docker-compose up -d

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)