大模型瓶颈之——大模型长文本处理问题以及解决方案
正如大家所知道的那样,大模型上下文窗口是有限制的,而上下文窗口大小是大模型的评价标准之一,越强大的大模型越有着更长的上下文窗口。而传说谷歌推出的Gemini 1.5 Pro模型将上下文长度刷新到了100万token,创下了最长上下文窗口的记录。那么大模型窗口上下文长度有哪些难点和问题,以及都是怎么解决的?01大模型长文本处理问题在现有的大模型体系中,上下文窗口是一个很重要的评判标准,越长的上下文窗
“大模型长文本处理,是大模型性能评价标准之一”
正如大家所知道的那样,大模型上下文窗口是有限制的,而上下文窗口大小是大模型的评价标准之一,越强大的大模型越有着更长的上下文窗口。
而传说谷歌推出的Gemini 1.5 Pro模型将上下文长度刷新到了100万token,创下了最长上下文窗口的记录。
那么大模型窗口上下文长度有哪些难点和问题,以及都是怎么解决的?
01
—
大模型长文本处理问题
在现有的大模型体系中,上下文窗口是一个很重要的评判标准,越长的上下文窗口意味着越强的性能;但同时,当上下文长度超过一定界限之后,大模型的性能会呈现断崖式下降。
当上下文长度达到一定限度之后,不论是大模型的输出质量,还是响应速度都会受到极大的影响。
其实上下文窗口问题说到底就是大模型的长文本处理问题,在大模型处理长文本问题时,面临着多个技术难点和问题。
上下文限制
问题
上下文窗口大小:大模型通常拥有一个固定的上下文窗口大小,这限制了模型能够同时处理的文本长度;当文本超出限制时,模型可能无法保持上下文的一致性和连贯性。
解决方案
分块处理:将长文本分成多个块进行处理,每个块大小在上下文窗口内;然后将处理结果合并或通过某种方法连接。
滑动窗口机制:使用滑动窗口技术逐步处理文本,将当前窗口中的内容与前一个窗口的内容进行结合,以保持上下文。
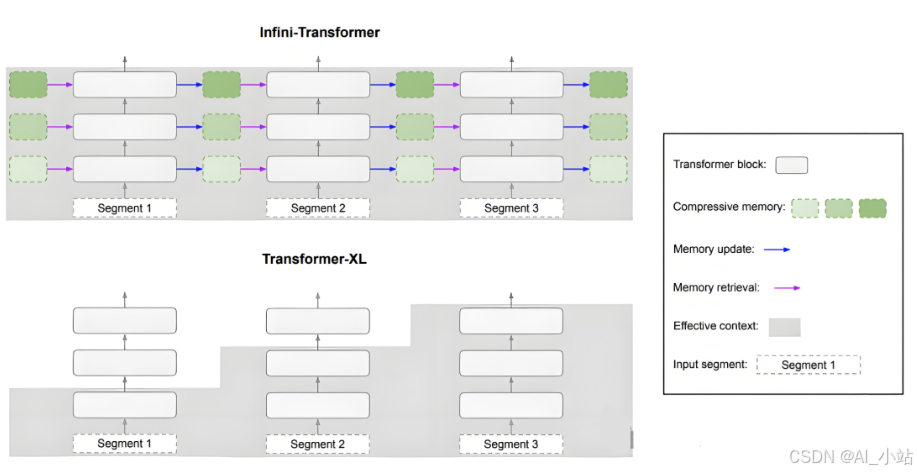
改进的上下文机制:引入像Transformer-XL和Reformer这样的模型,这些模型通过引入相对位置编码和记忆机制来扩展上下文长度。
长距离依赖
问题
长距离依赖:在长文本中,重要信息可能在文本的开始部分或中间部分,而当前的自注意力机制可能难以有效捕捉这些长距离的依赖关系。
解决方案
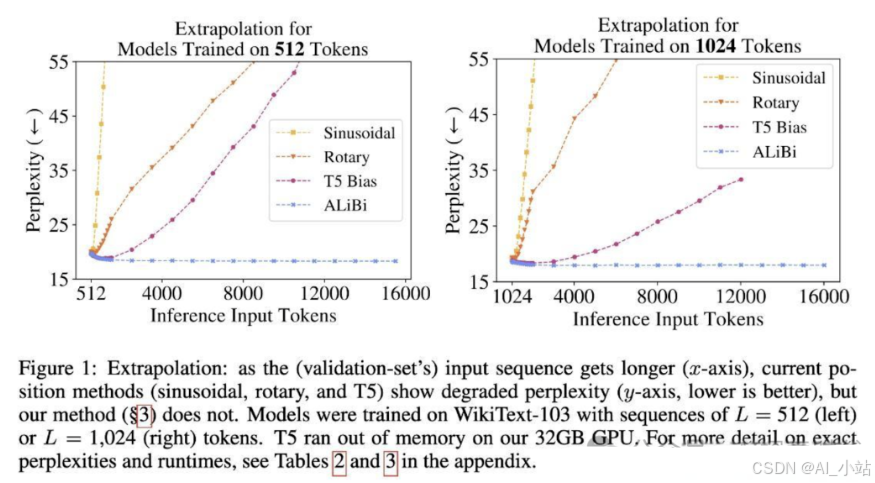
稀疏注意力机制:采用稀疏注意力机制(如Longformer, Big Bird),这些机制通过减少计算复杂度来处理长文本,并能有效捕捉长距离的依赖关系。
分层注意力机制:引入分层注意力机制(如Linformer),通过减少计算复杂度和调整注意力层的结构来提高对长文本的处理能力。
计算与内存开销
问题
计算复杂度:长文本会显著增加计算和内存开销,特别是在训练阶段,计算复杂度和内存需求是平方级别的。
内存消耗:处理长文本时,需要大量的内存来存储模型参数和中间计算结果。
解决方案
模型压缩:通过模型剪枝,量化和知识蒸馏等技术来减少模型的计算和内存需求。
分布式计算:利用分布式计算资源(如GPU集群,TPU)来处理长文本和大模型训练,提高计算效率和内存处理能力。
生成质量
问题
生成连贯性:在生成长文本时,保持文本的连贯性和一致性是一个挑战,特别是在长段落或章节中。
信息重复:长文本生成过程中可能会出现信息重复或冗余的问题。
解决方案
后处理和校正:使用文本生成的后处理技术来检测和修正重复信息,提高文本的连贯性。
生成策略优化:调整生成策略,如使用束搜索,温度控制和顶级采样等技术,来优化生成质量。
上下文更新和记忆
问题
上下文更新:在处理长文本时,如何有效地更新和维持上下文信息,特别是对长篇文章的多轮生成。
记忆机制:传统的Transformer模型没有内置记忆机制,导致在处理超长文本时,记忆能力有限。
解决方案
记忆增强机制:使用增强的记忆网络(如Transformer-XL)来保持长距离的信息,这些模型引入了持久的记忆机制,用于处理长期依赖。
交互式生成:在生成过程中逐步引入新的上下文信息,并结合之前的生成结果,进行连续的内容生成和更新。
任务适应性
问题
任务特定性:不同任务(如文章生成,对话生成,摘要等)对长文本的处理需求不同,模型需要适应这些特定任务的要求。
解决方案
任务特定微调:在特定任务的数据集上进行微调,以优化模型在特定任务上的表现。
适配模块:引入适配模块(如领域特定的提示或模板),帮助模型更好地适应不同类型的长文本生成任务。
数据质量和多样性
问题
数据质量:长文本的生成依赖于训练数据的质量,如果数据质量较差,生成的长文本可能不够准确或有偏差。
数据多样性:训练数据的多样性影响模型的生成能力,如果数据中缺乏多样性,模型可能在处理某些类型的长文本时表现不佳。
解决方案
数据增强:通过数据增强技术扩充训练数据的多样性,提高模型的生成能力。
数据清洗:对训练数据进行清洗和预处理,以提高数据质量,从而改善生成结果的准确性和可靠性。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 27
27 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)