Dify部署流程
Dify 是一款开源的大语言模型(LLM)应用开发平台,支持快速搭建生成式 AI 应用,并提供类似 Assistants API 和 GPTs 的功能。通过 Docker 部署 Dify 的步骤包括:进入 Docker 目录、复制环境配置文件、启动 Docker 容器,并检查容器状态。部署完成后,可通过本地或服务器访问 Dify 进行管理员账户设置和主页面访问。Dify 支持自定义配置和模型 AP
Dify部署/使用流程
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用,
Dify拥有基于任何模型自部署类似 Assistants API 和 GPTs 的能力,在灵活的同时保持对数据的完全控制
Dify内置向量数据库
Docker部署:
启动 Dify
1.进入 Dify 源代码的 Docker 目录
cd dify/docker
2.复制环境配置文件
cp .env.example .env
3.启动Docker 容器
根据你系统上的 Docker Compose 版本,选择合适的命令来启动容器。可以通过 $ docker compose version 命令检查版本
- 如果版本是 Docker Compose V2,使用以下命令:
docker compose up -d
- 如果版本是 Docker Compose V1,使用以下命令:
docker-compose up -d
运行命令后,你应该会看到类似以下的输出,显示所有容器的状态和端口映射:
[+] Running 11/11
✔ Network docker_ssrf_proxy_network Created 0.1s
✔ Network docker_default Created 0.0s
✔ Container docker-redis-1 Started 2.4s
✔ Container docker-ssrf_proxy-1 Started 2.8s
✔ Container docker-sandbox-1 Started 2.7s
✔ Container docker-web-1 Started 2.7s
✔ Container docker-weaviate-1 Started 2.4s
✔ Container docker-db-1 Started 2.7s
✔ Container docker-api-1 Started 6.5s
✔ Container docker-worker-1 Started 6.4s
✔ Container docker-nginx-1 Started 7.1s
最后检查是否所有容器都正常运行:
docker compose ps
访问 Dify
你可以先前往管理员初始化页面设置设置管理员账户:
# 本地环境
http://localhost/install
# 服务器环境
http://your_server_ip/install
Dify 主页面:
# 本地环境
http://localhost
# 服务器环境
http://your_server_ip
自定义配置
编辑 .env 文件中的环境变量值。然后重新启动 Dify:
docker compose down
docker compose up -d
完整的环境变量集合可以在 docker/.env.example 中找到。
配置模型
安装 Dify 并不等同于下载了 AI 模型。
Dify 是一个运行在本地的 Web UI,它允许我们便捷地访问和使用各种大语言模型,但是需要注意的是,下载 Dify 并不等同于下载了这些模型本身,如果希望使用这些大模型,需要拿到相应的 API Key,这部分是需要自己额外付费或本地部署大模型使用。
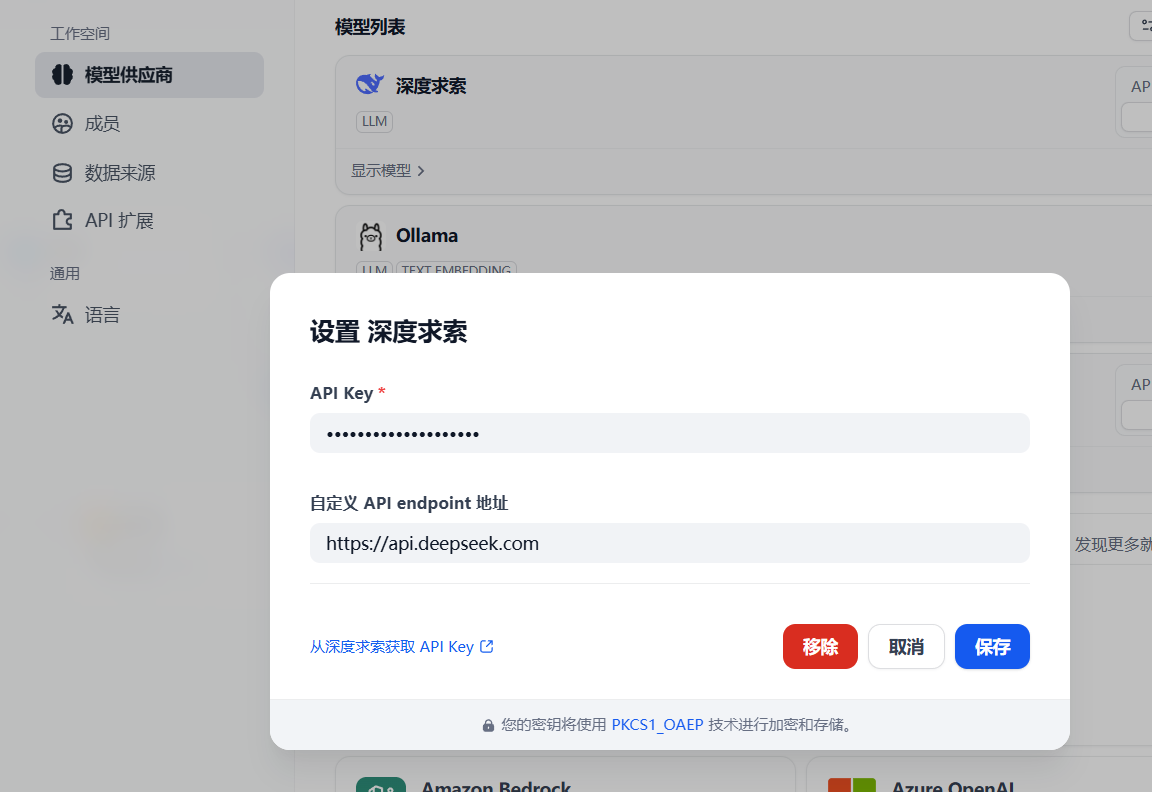
配置API Key,在设置页面中,点击「模型供应商」,选择您想使用的供应商,并点击设置。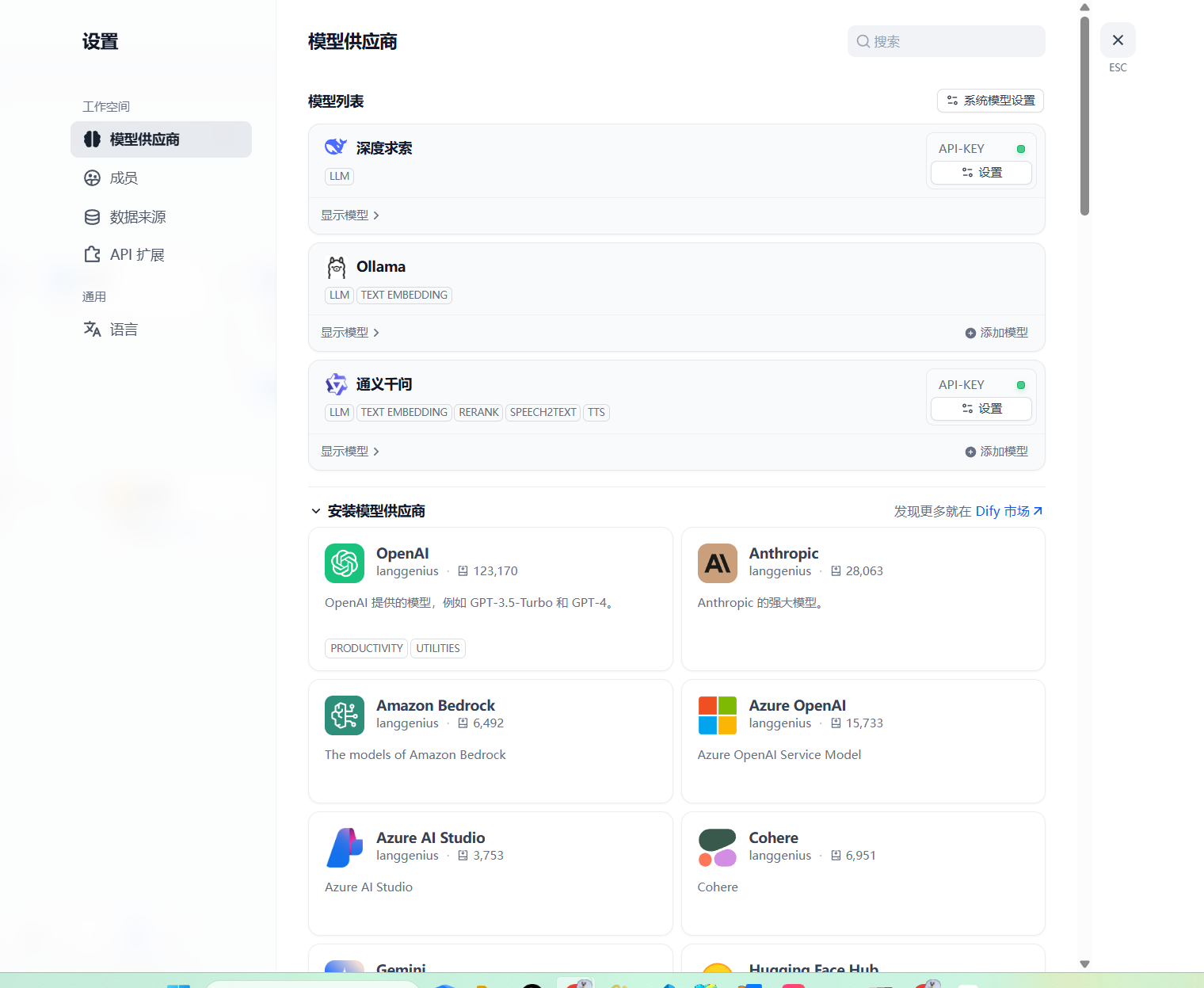
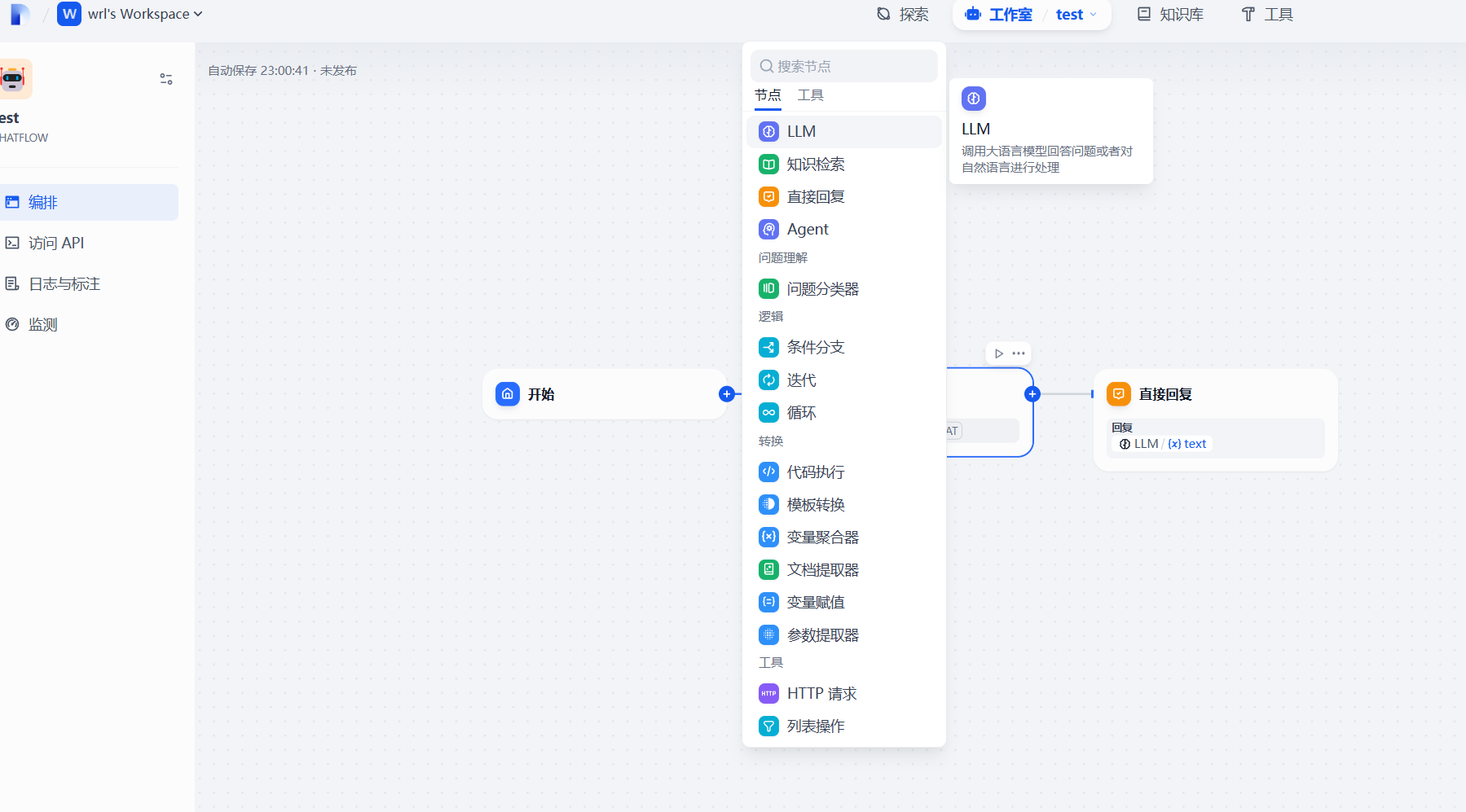
创建第一个应用
点击创建空白应用,使用Chatflow可以配置对话工作流,通过配置LLM大模型,流程和需要的工具插件,来实现完整的AiAgent
本地部署DeepSeek-R1
在硬件方面,运行 DeepSeek-R1 对设备有一定要求。不同版本的模型对硬件的需求有所差异,以常见的 7B 版本为例,推荐使用至少 8 核心的 CPU,如 Intel Core i7 或 AMD Ryzen 7 系列处理器,主频越高越好,这样在处理复杂任务时能更加高效。内存方面,建议配备 16GB 及以上的内存,以确保模型在运行过程中能够流畅地加载和处理数据。如果同时运行多个任务或者处理大规模数据,更大的内存会显著提升运行效率 。
基于 Ollama 部署
在部署 DeepSeek-R1 模型时,Ollama 是一个非常实用的工具,它可以帮助我们轻松地在本地运行和管理大语言模型
Ollama 提供了简洁的命令行接口,可以直接在命令行中,使用以下命令来下载 DeepSeek-R1 模型或其他模型(以DeepSeek-R1为例):
# 下载1.5B版本
ollama run deepseek-r1:1.5b
# 下载7B版本(默认指令,若不指定版本,会下载此版本)
ollama run deepseek-r1
# 下载8B版本
ollama run deepseek-r1:8b
# 下载14B版本
ollama run deepseek-r1:14b
# 下载32B版本
ollama run deepseek-r1:32b
# 下载70B版本
ollama run deepseek-r1:70b
当你执行上述命令时,Ollama 会首先检查本地是否已经存在该版本的模型,如果不存在,它会自动从远程仓库下载模型文件。模型的下载速度取决于你的网络状况,可能需要几分钟到几十分钟不等.
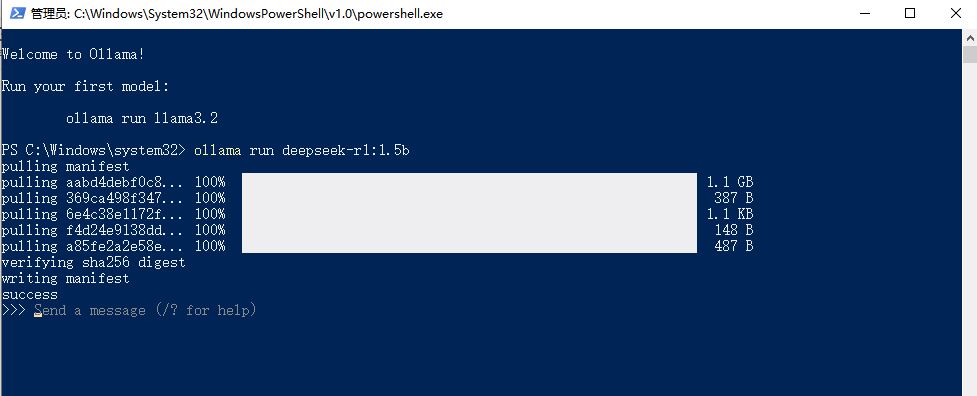
模型下载完成后,默认会存储在 Ollama 的模型存储目录中。如果你在安装 Ollama 后配置了环境变量 “OLLAMA_MODELS”,那么模型会存储在你指定的目录中;如果没有配置环境变量,模型会存储在默认的安装目录下,例如 “C:\Users\ 你的用户名.ollama\models” 。你可以通过 “ollama list” 命令来查看本地已经下载的模型列表,包括模型名称、ID、大小和修改时间等信息,确认 DeepSeek-R1 模型是否已经成功下载到本地.
Ollama使用
在dify使用Ollama时可以在模型供应商中下载Ollama进行模型配置,模型名称需与下载的模型对应,
url默认为:http://host.docker.internal:11434
Text2SQL使用
Text2SQL(或称NL2SQL)是一种自然语言处理技术,旨在将自然语言(Natural Language)问题转化为关系型数据库中可执行的结构化查询语言(Structured Query Language,SQL),从而实现对数据库的查询和交互。这项技术的核心目标是通过自然语言描述,无需用户具备SQL语法知识,即可完成复杂的数据库查询任务
Text2SQL的任务包括以下步骤:
1.输入分析:用户以自然语言形式输入问题,例如“查找平均工资高于整体平均工资的部门名称”。
2.语义解析:系统将输入的自然语言问题解析为数据库中的结构化查询语句。
3.SQL生成:根据解析结果生成对应的SQL语句,如“SELECT department_name FROM departments WHERE average_salary > (SELECT AVG(salary) FROM employees)”。
4.执行与反馈:系统执行SQL查询并返回结果,同时可能对结果进行进一步的解释或分析。
text2data配置使用
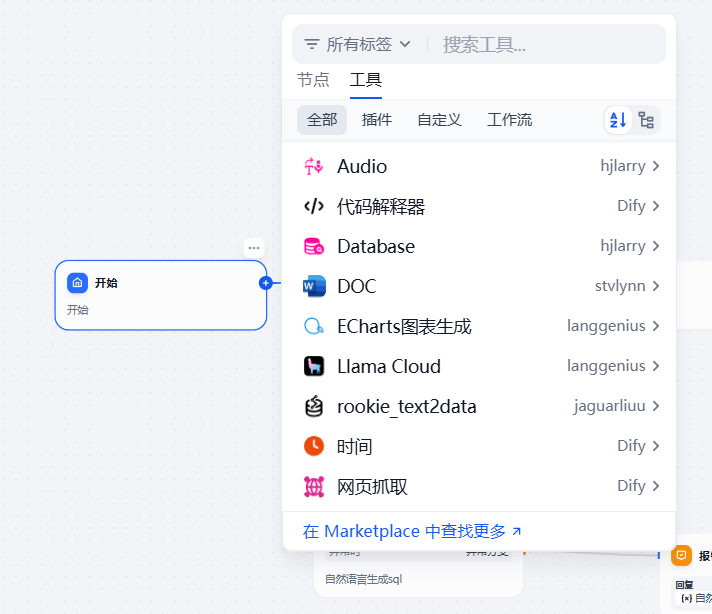
在dify中text2sql可以使用插件来进行简单使用,在Dify官方市场安装rookie-text2data(目前仅支持oracle和pg)
text2data插件 一共由两个Action组成,可以理解为两个插件,一个插件用来生成sql,一个插件用来sql执行;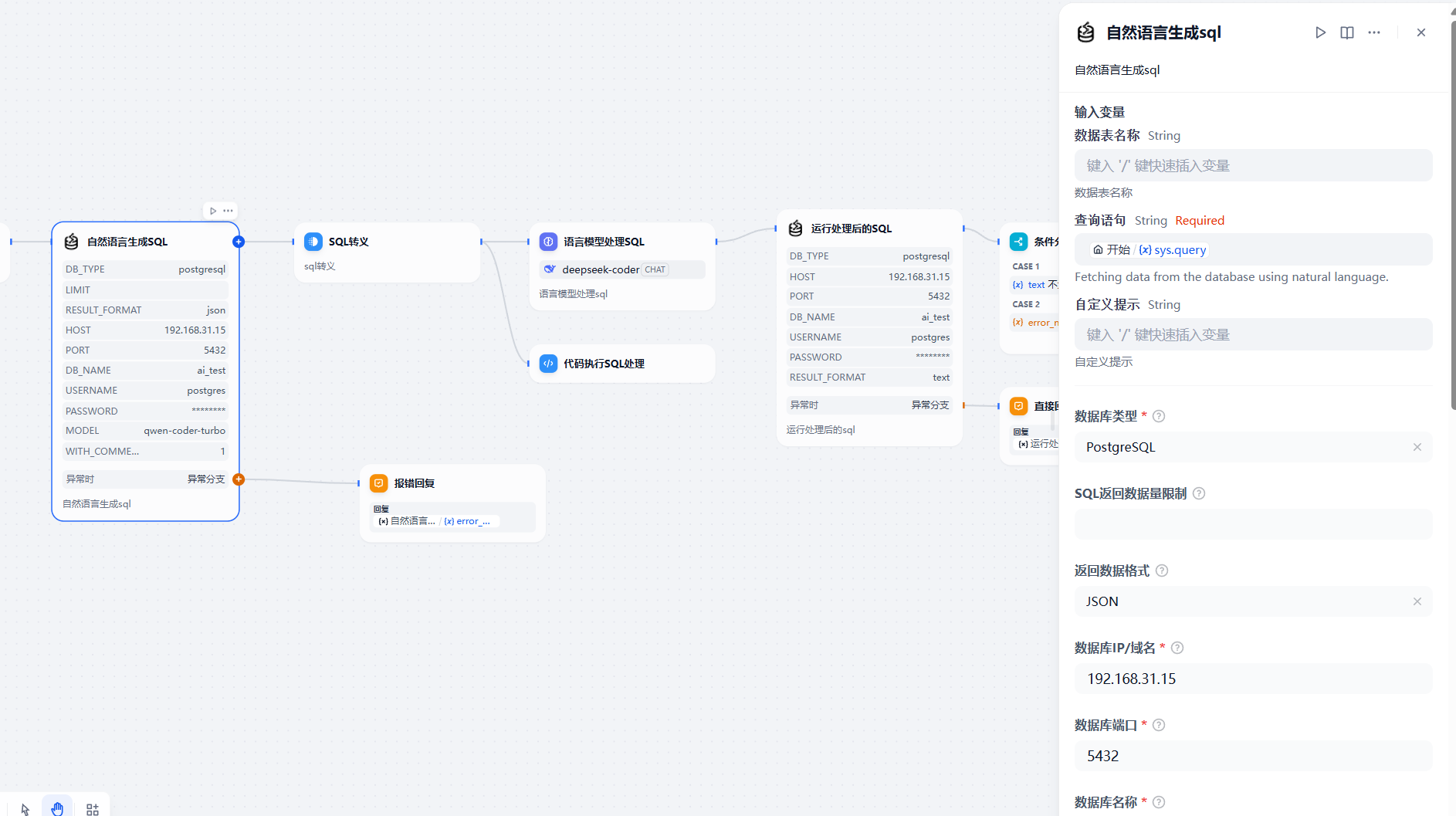
参数配置详解
-
数据表名称(非必填):
- 参数说明:生成SQL涉及到的表名称,用英文
,分隔 - 使用说明:
- 当你的数据库里的表过多的时候,如果直接使用插件,插件会将你所有的表元数据通通读取,有可能会超过上下文限制,而且太多内容不利于大模型理解,会对生成SQL语句质量产生影响。
- 数据库里除了业务表,还有敏感数据表,比如aksk之类的表,这些表不适合被大模型采集,因此需要忽略这些敏感数据表
- 参数说明:生成SQL涉及到的表名称,用英文
-
数据库Schema(选填):
- 参数说明:pgsql支持schema的方式组织和命名空间数据库对象,mysql用户可忽略此参数
-
查询语句(必填):
- 参数说明:这里就是你想要查询数据库的自然语言。
- 使用说明:不要太过简单,想要更好的结果,那就更好的给大模型描述清楚你的需求。
-
自定义提示(非必填):
- 参数说明:对于你库表字段,以及多表关系的进一步说明。
- 使用说明:
- 这里不要丢库表字段的解释,**不要!**因为插件会在运行的时候自己去获取并且压缩,不要在这里配置,增加大模型的心智负担。
- 这里的最优配置是,
- 比如你的库表字段不是标准的英文或者拼音,例如
aaaa、bbbb这样的,那你就需要在这里告诉大模型这些表的含义; - 比如你的查询需要涉及到你们的业务内容,你要在这里告诉大模型;
- 比如你有一个枚举字段,但是字段注释里没有写他都支持哪些,那你就需要在这里告诉大模型。
- 比如你需要生成一个联查的SQL,但是你的表和表之间没有明确的联系,那就告诉大模型你的表和表之间的关系。
- 比如你的库表字段不是标准的英文或者拼音,例如
-
数据库类型(必选):
- 参数说明:这就没啥好解释的,就是数据库类型
-
SQL返回数量限制(非必选):
- 参数说明:为了避免数据库一次性返回的数据量过大,以及为了安全和效率,插件返回的每条sql都会加上limit限制,默认是100,如果你觉得少或者多了,就在这里加减乘除,不填就是默认,默认就是100。
-
返回数据格式(必选):
- 参数说明:Dify的插件返回类型,一共有三种
text``/``files``/``json。在插件中,你可以切换返回值的形式, - 使用说明:
text格式的返回值,可以直接在直接回复,或者其他节点中使用json格式,就是标准json,可以直接在代码节点,或者模板转换节点中使用
- 参数说明:Dify的插件返回类型,一共有三种
-
数据库IP、域名(必填):
- 参数说明:这个参数没啥说的,就是IP或者HOST
- 使用说明:
- 不要加
http,要纯ip或者host,不要加HTTP或者****HTTPS,也不要加端口 - 如果你是本地Dify和本机数据库,请使用你自己的本机IP或者
host.docker.internal连接。
- 不要加
-
是否包含注释(必填):
- 参数说明:获取数据表元数据,表结构的时候,要不要包含表注释。默认为True。详情请看更新日志。
- 使用说明:这个开关呢,是用来进一步优化生成效率的。
- 如果你的库表字段设计很规范,通俗易懂,见名知意,那你可以配置false,配置为false的好处就是可以大幅度提高上下文宽度,容纳更多表结构
- 如果你的表结构字段不是很好理解,那最好开始配置为True
Database配置使用
如rookie_text2data不满足数据库需求,可使用Database插件来进行使用,目前这个项目支持的数据库有mysql, postgresql, sqlite, sqlserver, oracle,安装好后,需要对它配置。
参考:mysql+pymysql://root:zzz%40123@192.168.31.15:19030/test_db
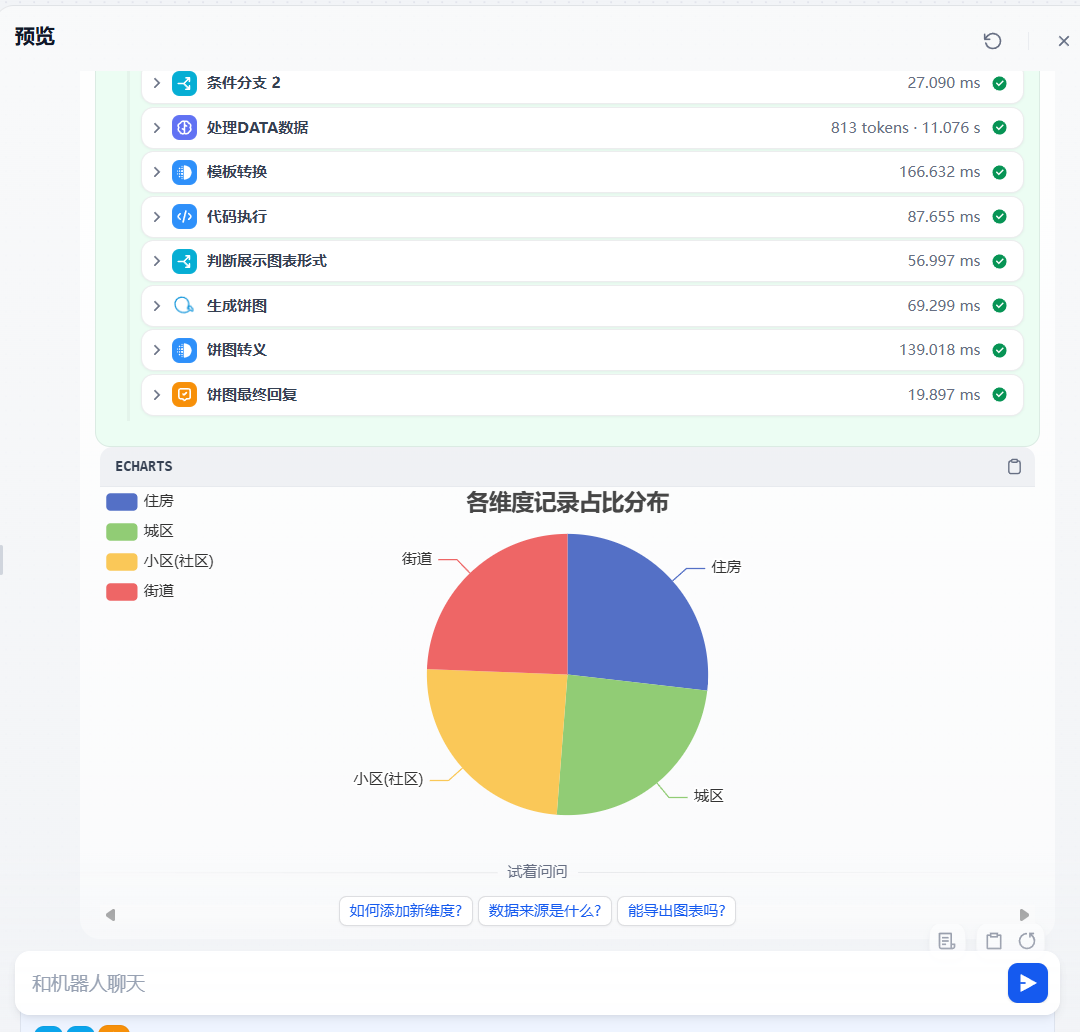
最终效果

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 42
42 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)