DeepSeek混合专家模型的基本结构
混合专家模型(MoE)是一种深度学习架构,它通过集成多个专家模型(即子模型)来提升整体模型的预测性能和效率。每个专家网络专门处理输入数据的一个子集或特定特征,而门控网络则负责根据输入动态地选择合适的专家模型进行处理,它们之间使用专门的负载平衡与优化对资源进行调配。混合专家模型通过动态地选择和组合多个专家模型来处理输入数据,实现了高效计算与优异性能的平衡。混合专家模型是一种深度学习中的集成学习方法,
DeepSeek大模型高性能核心技术与多模态融合开发 - 商品搜索 - 京东
混合专家模型(MoE)是一种深度学习架构,它通过集成多个专家模型(即子模型)来提升整体模型的预测性能和效率。这种架构主要由两部分组成:门控网络(路由器机制)和多个专家网络。每个专家网络专门处理输入数据的一个子集或特定特征,而门控网络则负责根据输入动态地选择合适的专家模型进行处理,它们之间使用专门的负载平衡与优化对资源进行调配。
MoE模型的优势包括提高模型的灵活性、性能以及计算资源的高效利用,尤其在处理复杂或多样化任务时表现突出。然而,设计和训练MoE模型也面临一些挑战,如平衡专家的数量和质量,以及优化门控网络的决策能力。MoE模型在自然语言处理、计算机视觉和推荐系统等领域有着广泛的应用前景。
混合专家模型是一种深度学习中的集成学习方法,它通过组合多个专家模型(即子模型)来形成一个整体模型,旨在实现高效计算与优异性能的平衡。混合专家模型的基本结构如图5-2所示。
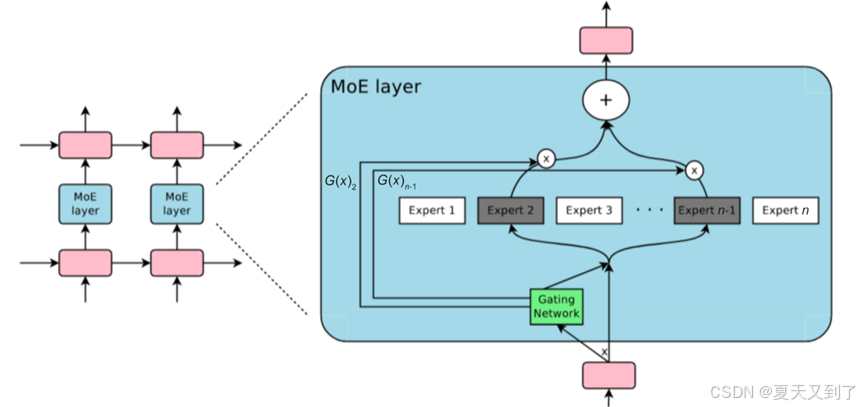
图5-2 混合专家模型的基本结构
其基本结构可以归纳为以下几个关键要点。
(1)专家网络(Expert Networks):
- MoE模型包含多个专家网络,每个专家网络都是一个独立的模型,负责处理某个特定的子任务。
- 这些专家网络可以是小型的多层感知机(MLP)或更复杂的结构,如Transformer等,各自在其擅长的领域内进行训练和优化。
(2)门控网络(Gating Network):
- 门控网络是MoE模型中的另一个关键组件,负责根据输入数据的特征动态地决定哪个专家模型应该被激活以生成最佳预测。
- 门控网络通常输出一个概率分布,表示每个专家模型被选中的概率。这个概率分布可以通过softmax函数来计算,确保所有专家的权重之和为1。
(3)稀疏性(Sparsity):
- 在MoE模型中,对于给定的输入,通常只有少数几个专家模型会被激活,这种特性使得MoE模型具有很高的稀疏性。
- 稀疏性带来了计算效率的提升,因为只有特定的专家模型对当前输入进行处理,减少了不必要的计算开销。
(4)输出组合(Output Combination):
- 被激活的专家模型会各自产生输出,这些输出随后会被加权求和,得到MoE模型的最终输出结果。
- 加权求和的过程根据门控网络输出的概率分布来进行,确保每个专家的贡献与其被选中的概率成正比。
混合专家模型通过动态地选择和组合多个专家模型来处理输入数据,实现了高效计算与优异性能的平衡。这种结构使得MoE模型能够根据不同的任务和数据,灵活地调整其计算复杂度和模型容量,从而在各种深度学习应用场景中展现出强大的潜力。



欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)