【AI大模型】235B参数,119种语言,Qwen3却连“Strawberrrrry“都数不清?
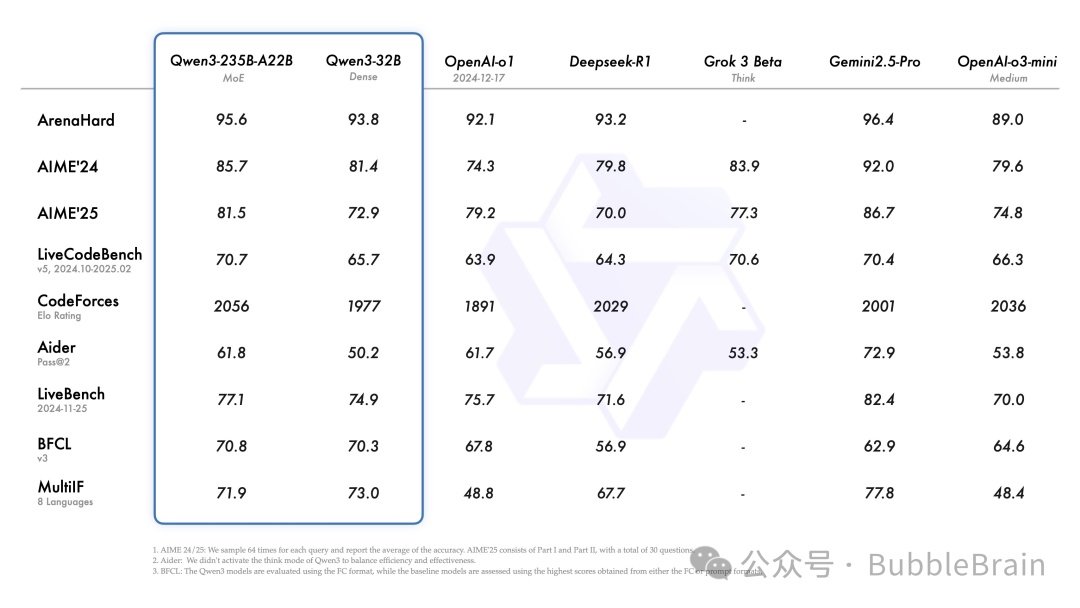
终于,千呼万唤中,Qwen 3 登场了。这次发布了2 个 MoE 模型,6 个 稠密(dense)模型,从 0.6B 到 235B,所有的尺寸都集全了。它们最顶尖的模型 Qwen3-235B-A22B 在 benchmark 上的表现达到了业界顶尖的水平,与 DeepSeek-R1,Gemini-2.5-Pro, Grok-3 水平相当。小模型方面,即使是 Qwen3-4B 的水平也基本超过了前一
介绍
终于,千呼万唤中,Qwen 3 登场了。
这次发布了2 个 MoE 模型,6 个 稠密(dense)模型,从 0.6B 到 235B,所有的尺寸都集全了。
它们最顶尖的模型 Qwen3-235B-A22B 在 benchmark 上的表现达到了业界顶尖的水平,与 DeepSeek-R1,Gemini-2.5-Pro, Grok-3 水平相当。
小模型方面,即使是 Qwen3-4B 的水平也基本超过了前一代的 Qwen2.5-72B。
详细的跑分成绩可以参考如下两张图:
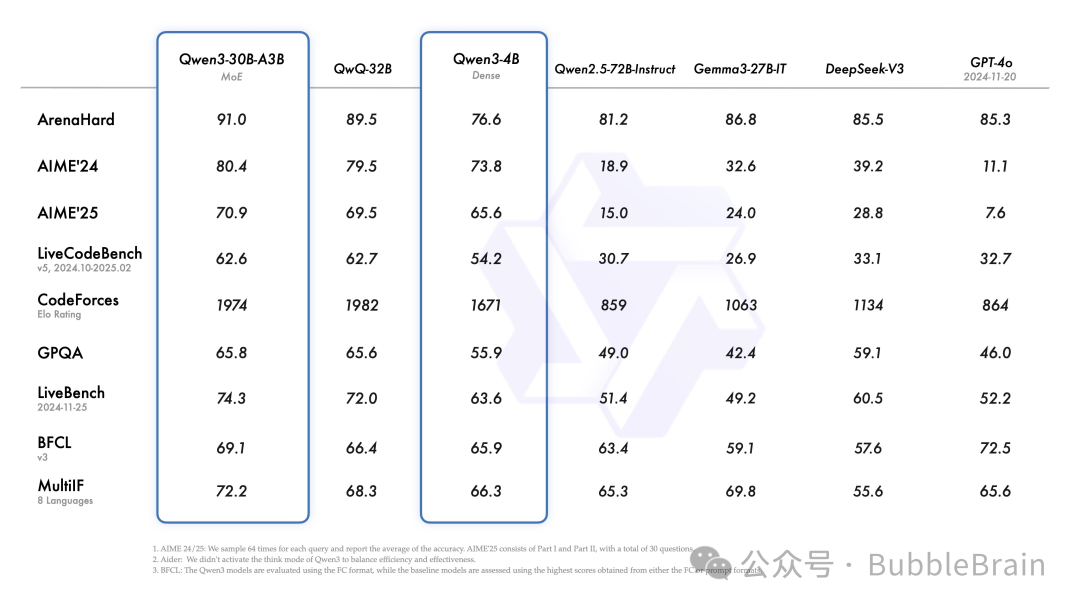
还有一些关键的特点:
👍
- Qwen 3 支持混合思考模式来解决问题;如果问题需要很复杂的思考,则模型会通过思考模式进行深度思考后再回答。如果问题相对比较简单,则模型会快速回答。(和 Claude 3-7 Sonnet, Gemini 2.5 Flash 实现的类似)
- 多语言的支持: Qwen 3 支持 多达119 种语言
- Qwen 3 不仅代码,推理方面的能力得到增强,对 MCP 支持也进一步得到优化。
下面分享一些测试 case,对开启 thinking 模式和关闭 thinking 模式都做了对比 ~
测试
推理能力
Prompt
一头被 10 米绳子拴住的老虎,要如何吃到 20 米外的草?
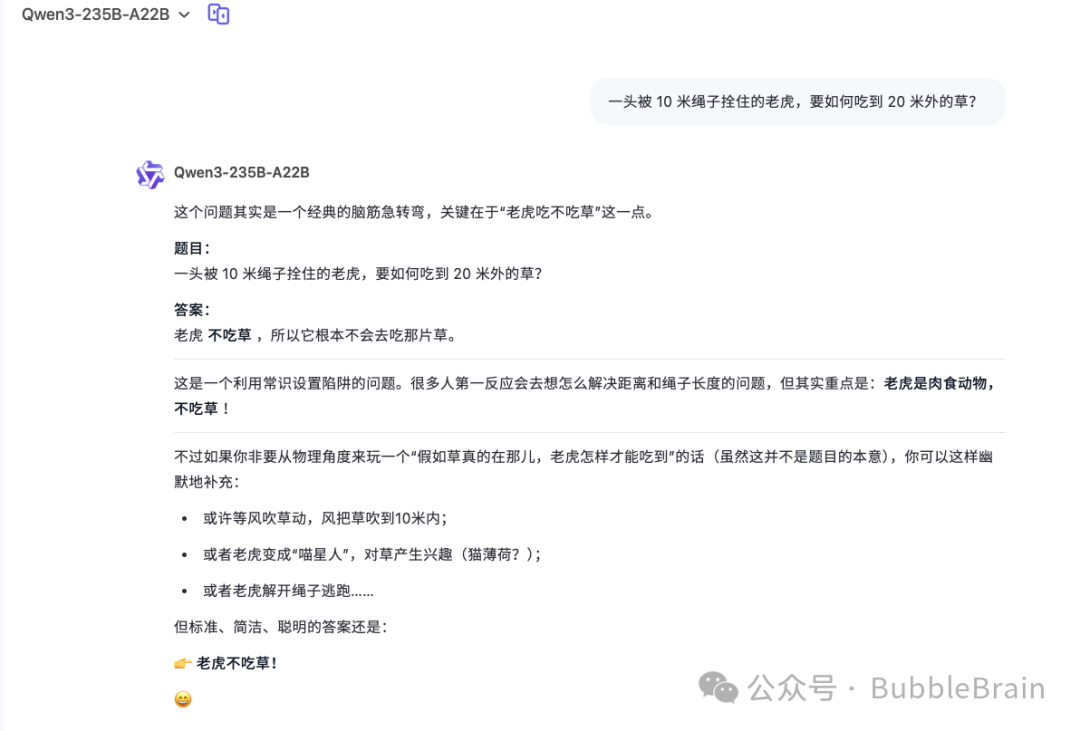
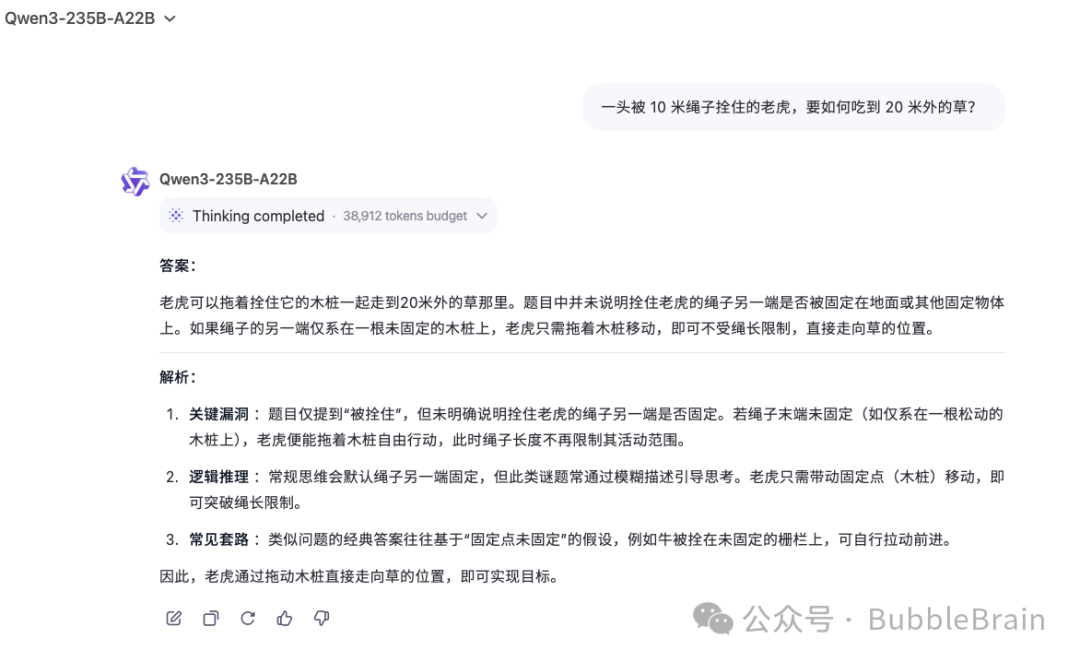
典型的thinking 模式下出现了过度思考的问题。查看 thinking 的过程,是可以发现,模型其实考虑到“老虎不吃草”这一点,但是最后仍然没回答出来。

Prompt
Strawberrrrry 有几个r
既然现在的模型能够正确回答“Strawberry有几个 r”这种问题,那我多加几个 r 试试呢?


两种模式下,模型都回答错了。感觉模型还是在背题,特别是我故意把“strawberry”这个词打错,它就分辨不出来了,它列举的时候都列举少了一个“r”。
Prompt
最小整数的平方在 15 到 30 之间,这个最小整数是几?
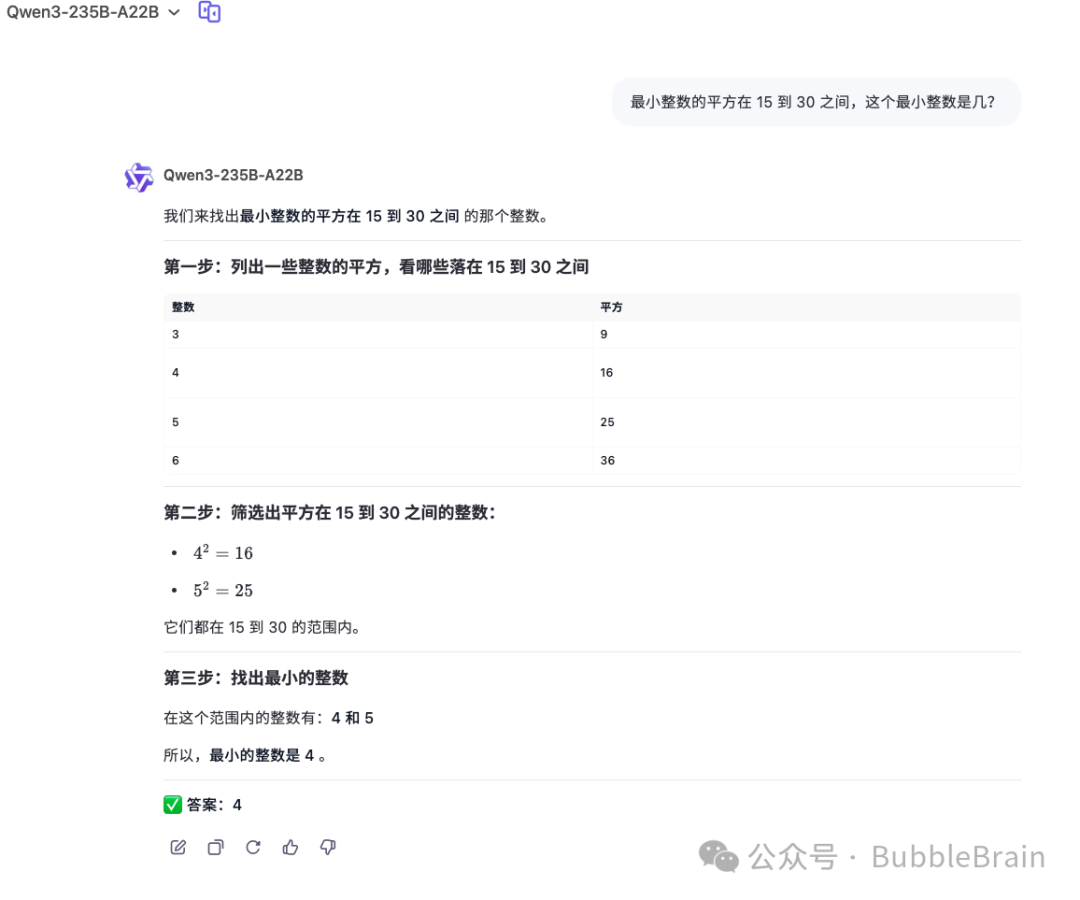

终于,有一个测试是在thinking 模式下回答正确,非 thinking 模式下回答错误的。正确答案是-5。 这个题目其实还是有难度的,测试过很多模型,哪怕是深度思考模型,也未必都能回答对。
Prompt
一个长五点五米的竹竿,能否穿过一扇高四米,宽三米的门?请考虑立体几何


这里,可以看到,对于这道非常经典的问题,thinking 模式 下是回答正确了,但是非 thinking 模式下回答错误的。说明开启 thinking 模式,对做难题还是有用的。
代码能力
先做一题经典的小球测试
Prompt
使用 p5.js(无需 HTML)创建 10 个彩色球在旋转六边形内弹跳的效果,考虑重力,弹性,摩擦和碰撞。
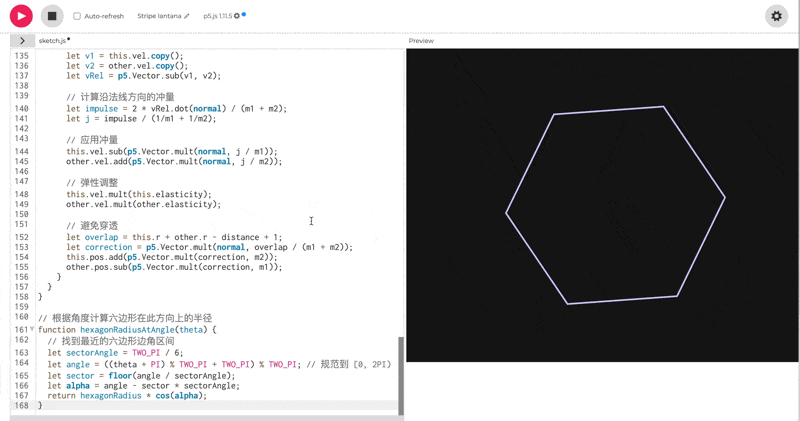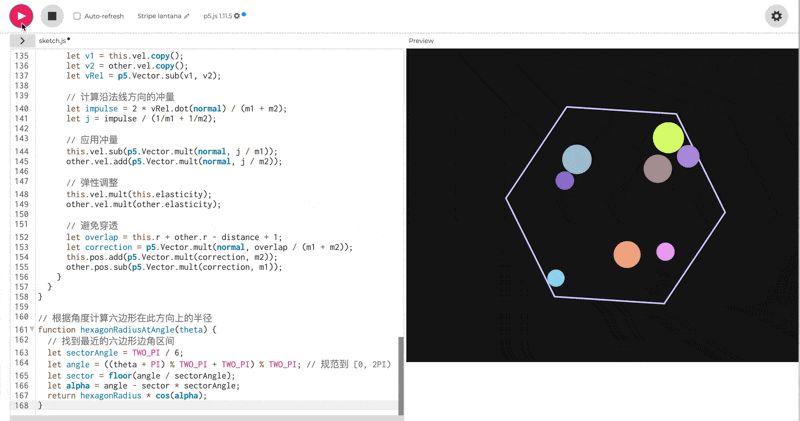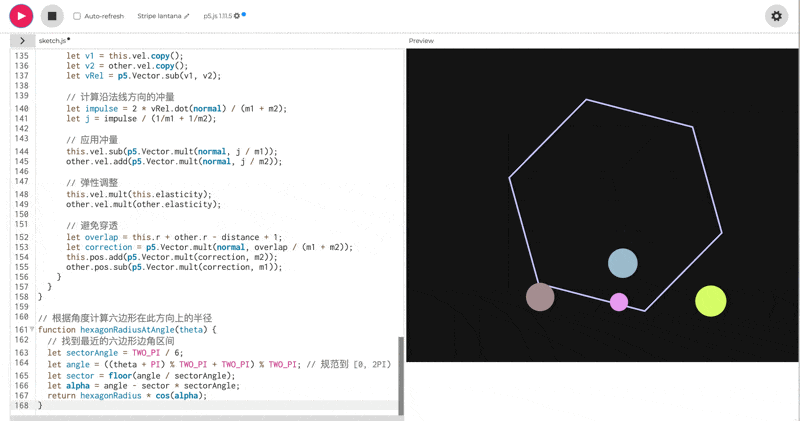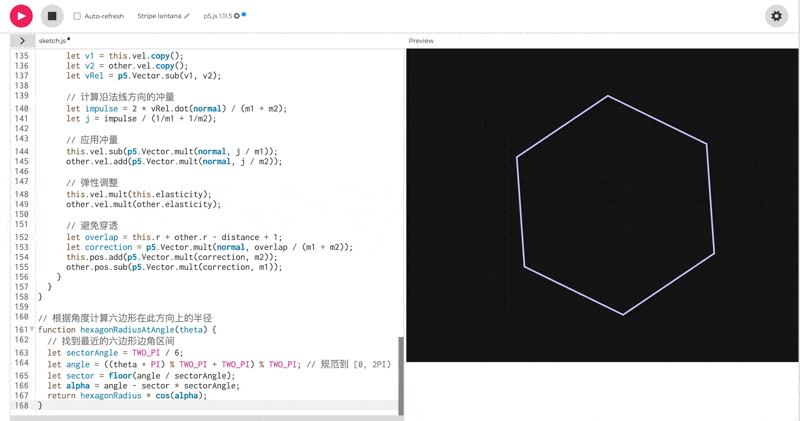
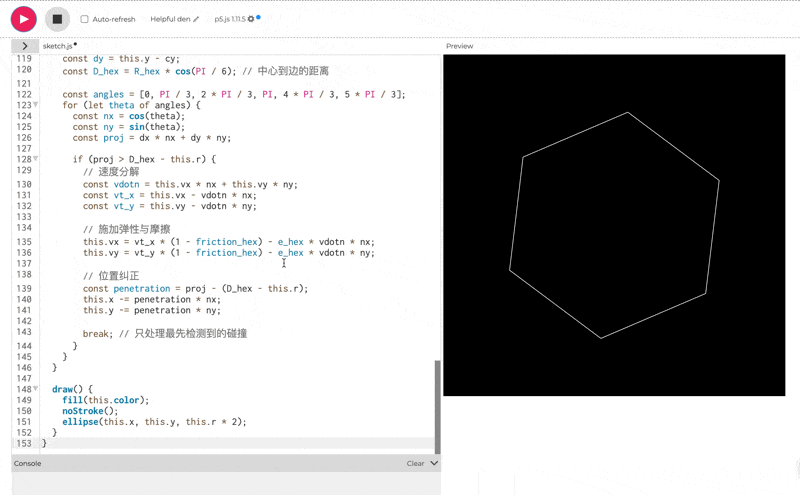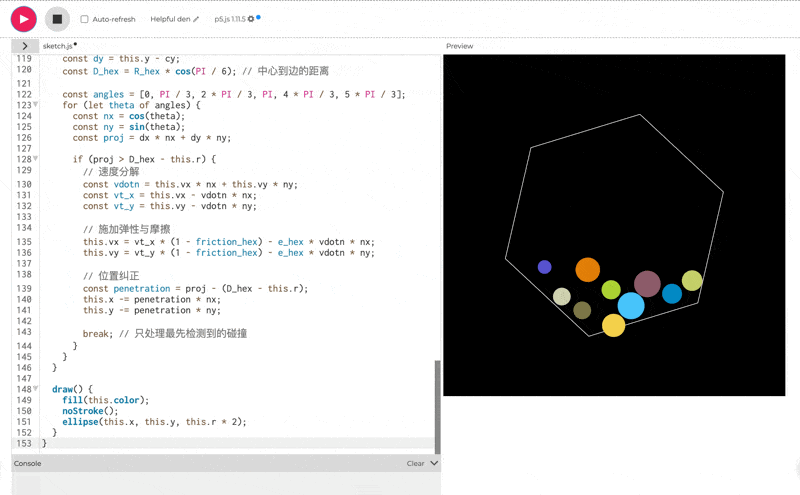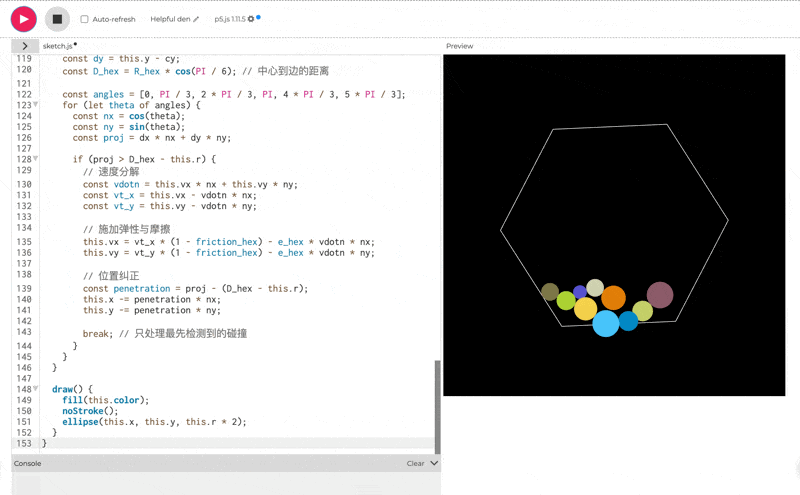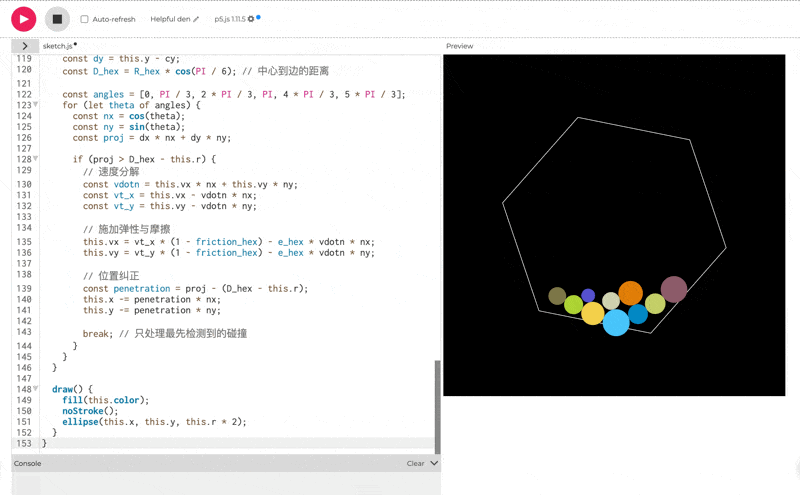
一眼看的出 thinking 模式下的效果会更好。但是, 这个效果吧,确实也一言难尽。整体的效果我觉得甚至不如之前出的豆包 Doubao-1.5-thinking-pro**。**我把豆包的测试效果放在下面了,可以对比一下看看:
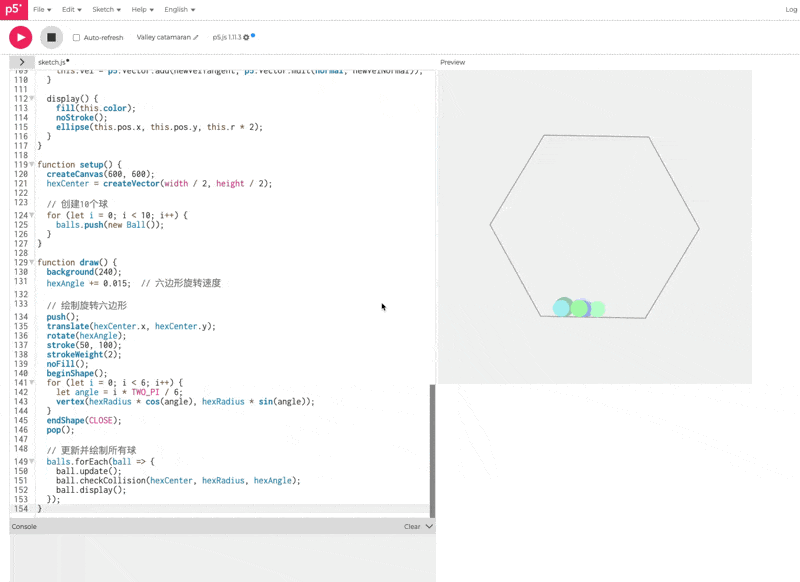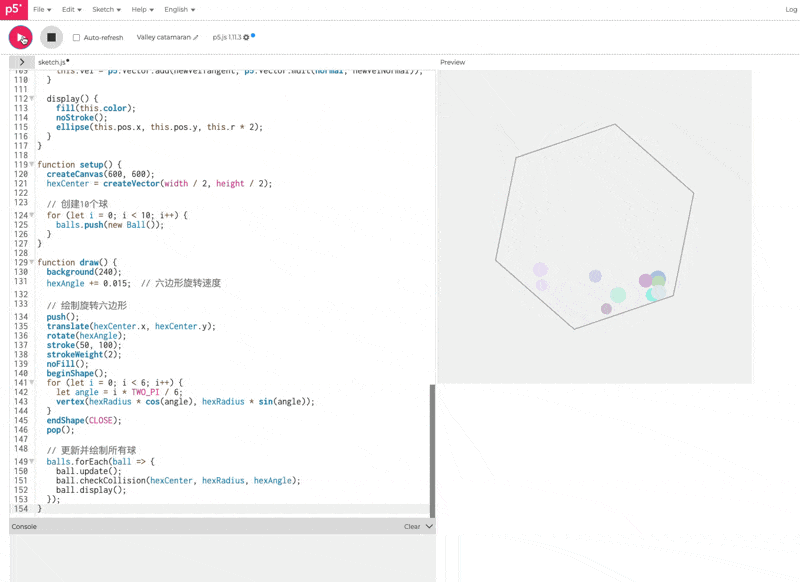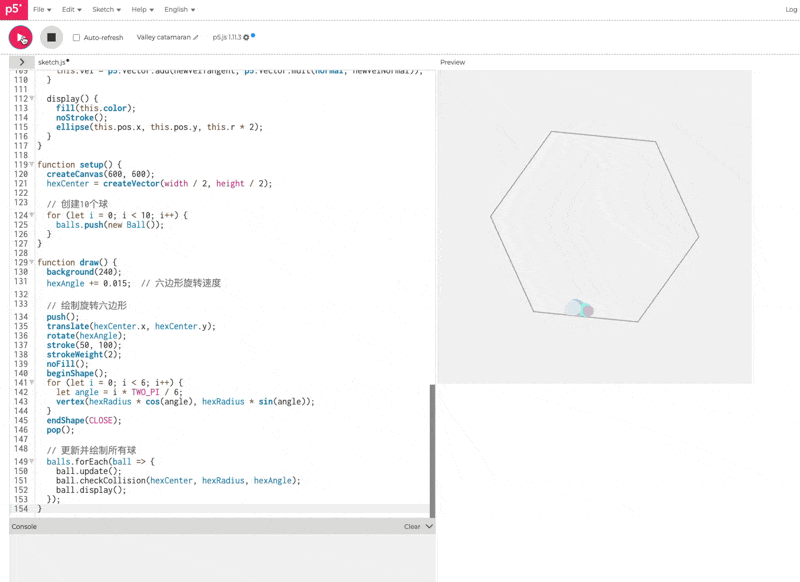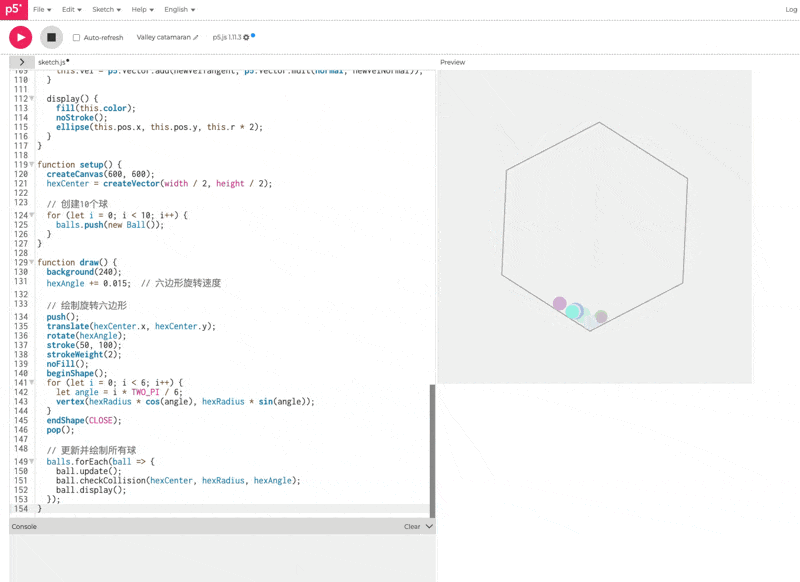
Prompt
创建一个贪吃蛇的网页游戏,实现玩家控制游戏。在游戏过程中,屏幕上需要清晰地显示玩家当前得分。
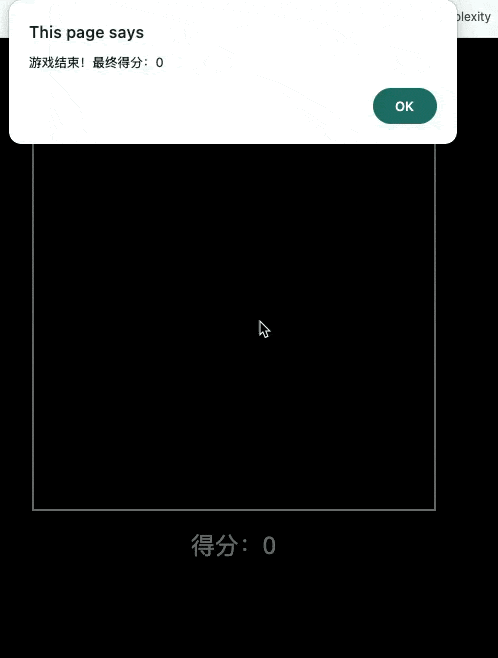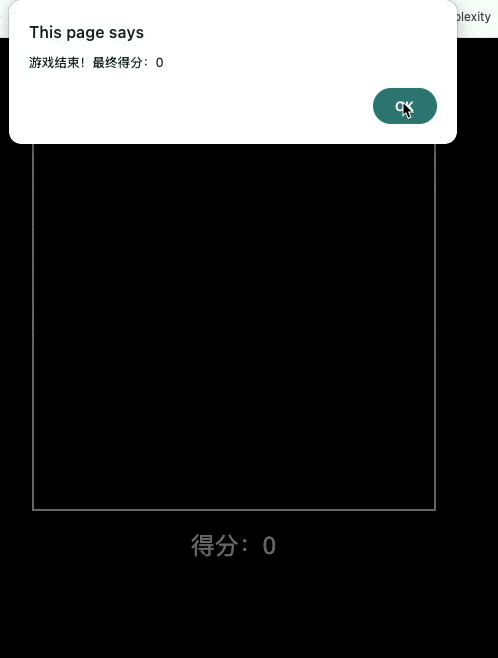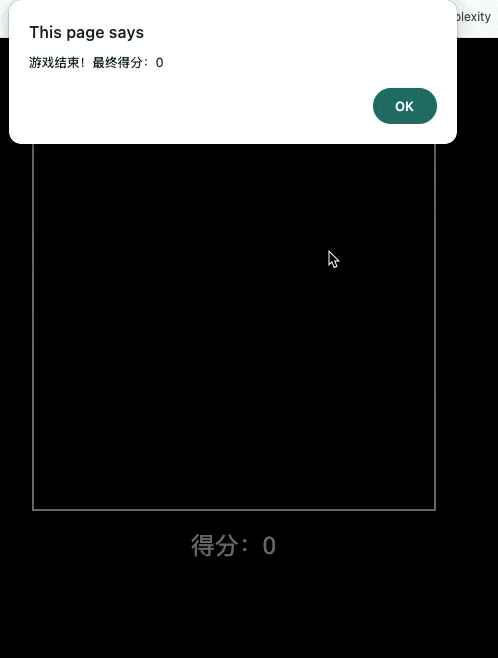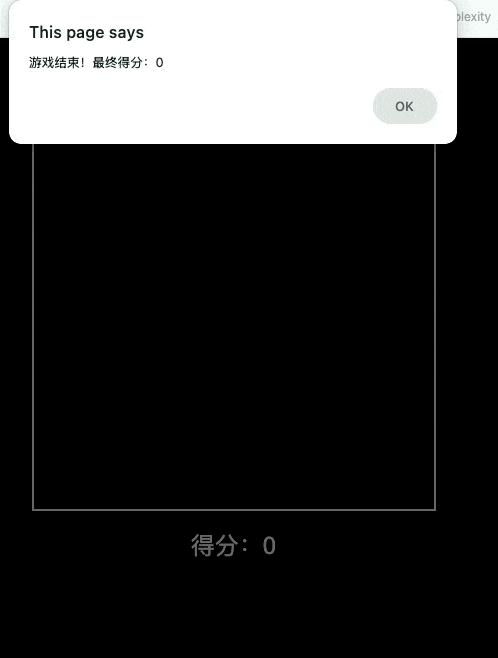

这个 case 表现的非常差,贪吃蛇的游戏是玩不了的水准。我把同样测试过的 Doubao-1.5-thinking-pro 的效果放在下面,可以对比看看,基本是被豆包爆杀的状态。

Prompt
在单个 HTML 文件中创建一个视觉效果惊艳的吃豆人游戏。
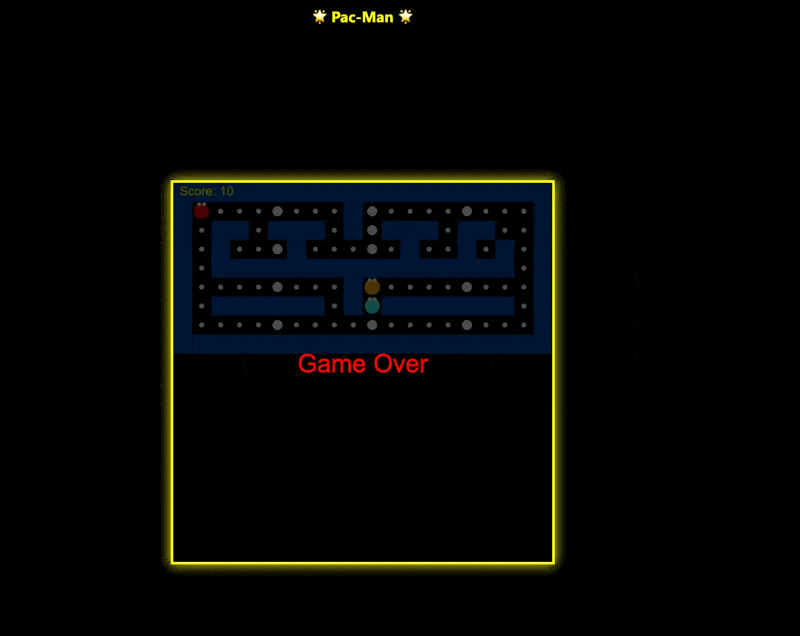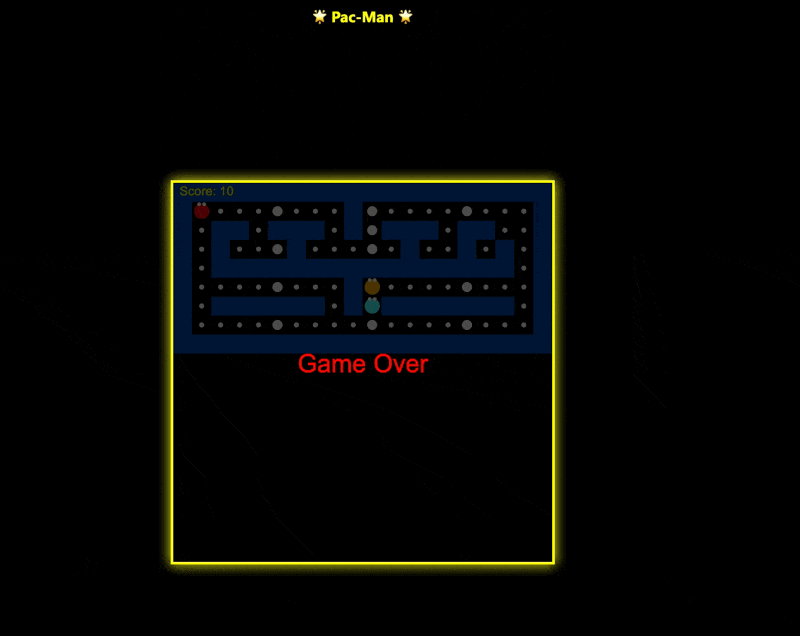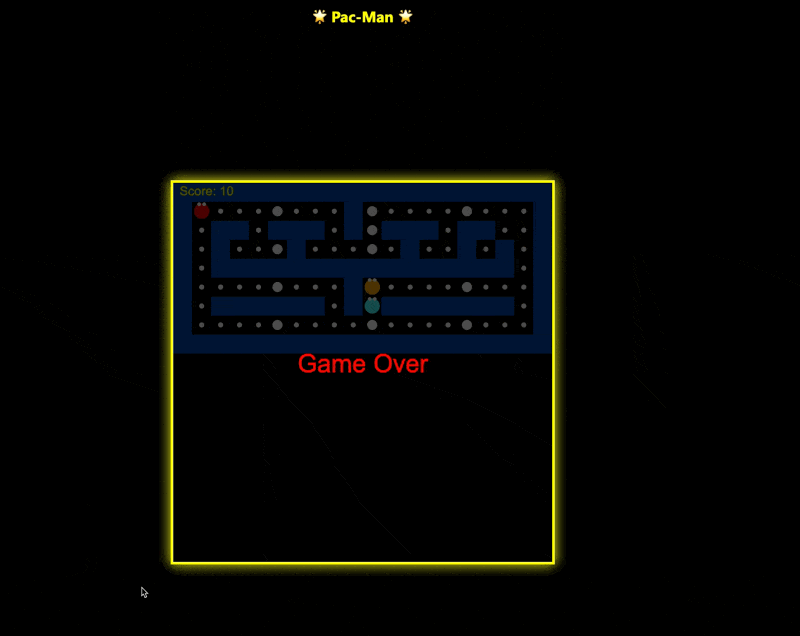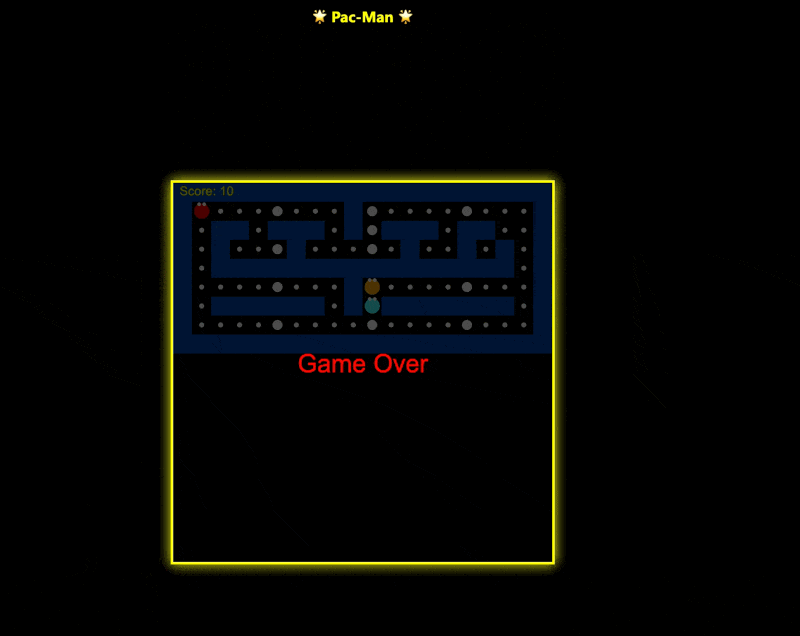

先说结论,thinking 模式 明显比非 thinking 模式 好,但确实也好的有限,存在很明显的bug。我在这个 case 里同样也拿豆包进行对比测试了一下:
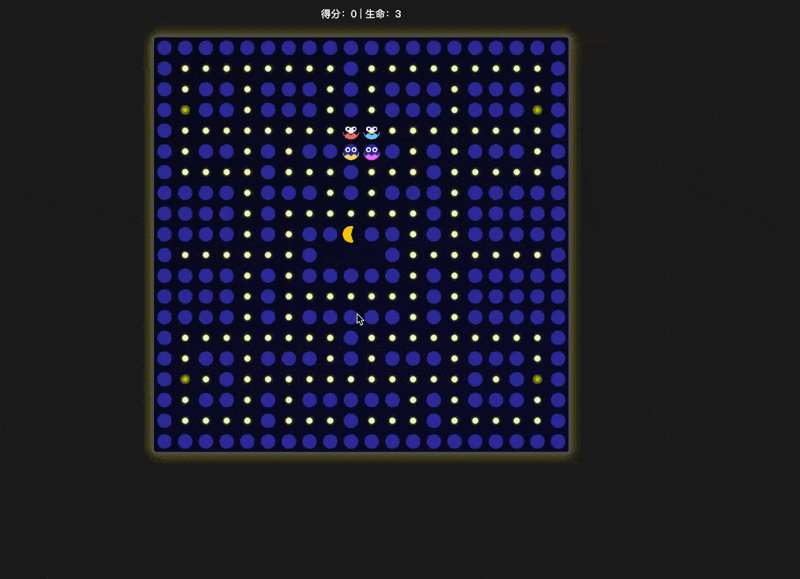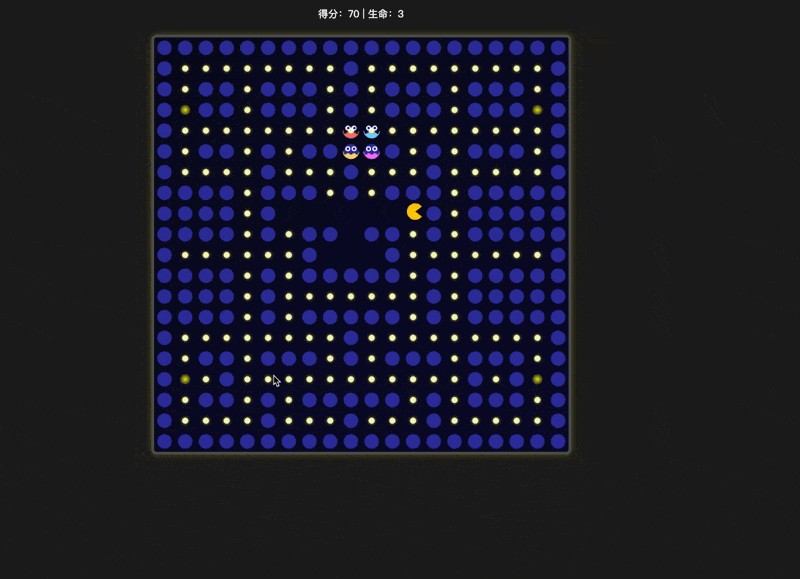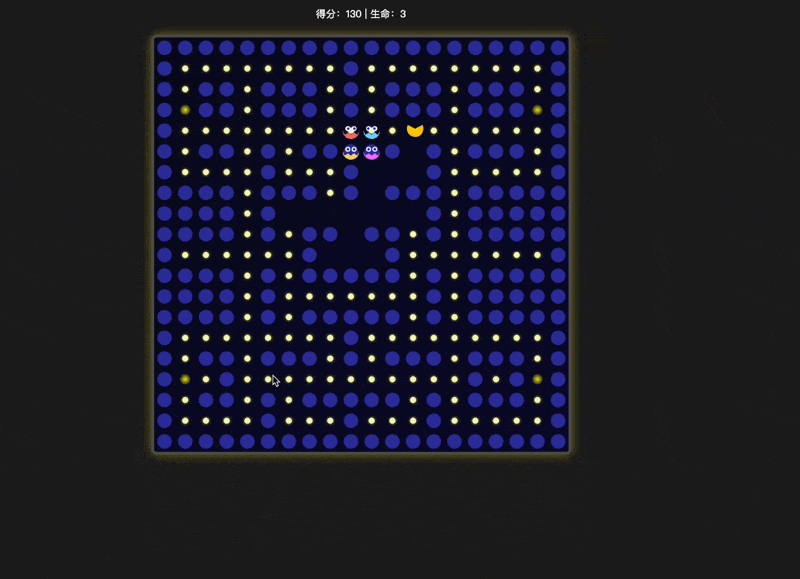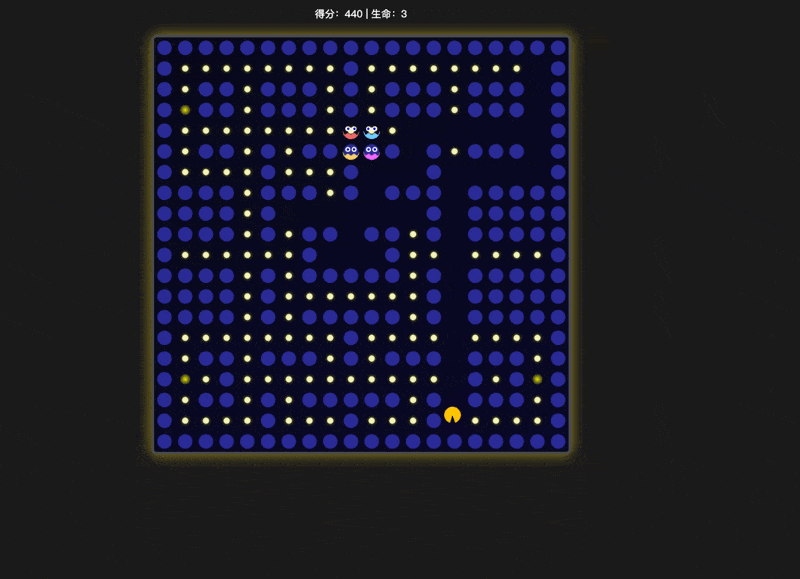
同样是 thinking 模型,明显豆包这个效果好太多,至少没有出现“能够穿墙而过”这种明显的错误,而且积分板摆放的位置也更加合理。
Prompt
创建一个梦幻的低多边形漂浮岛屿场景,包含动态照明和柔和的动画效果,并将其整合在一个单独的HTML文件中。
这个 case 里,我先说结论, Qwen3-235B-A22B在豆包和 DeepSeek-V3 的比较中,完败。
先放Qwen3-235B-A22B 的结果:

对,没错,纯纯两张什么都没有的图片。
再来看豆包的。

然后是 DeepSeek 的;

看到这个 case 真的不得不感叹一句,DeepSeek 还是太强了,越来越期待 R2的到来。
MCP 调用测试
现在 MCP 越来越火,但是大家可能潜意识里都认为所有模型调用 MCP 的效果是一样的,但其实不然。而且,这次 Qwen 3 又特意增强了模型 agent 的能力。所以,我也在 chatwise 上配置了 MiniMAX 和 Exa Search 的服务,来简单测试下 Qwen3 。
Prompt
请分析Sam Altman和Logan Kilpatrick在X(Twitter)上的15条最新推文。创建一份全面报告,重点突出这些推文中提到的OpenAI和Google的重要发展。将这些信息以交互式HTML页面的形式呈现,包含数据可视化,并嵌入一段讨论主要发现的音频摘要。
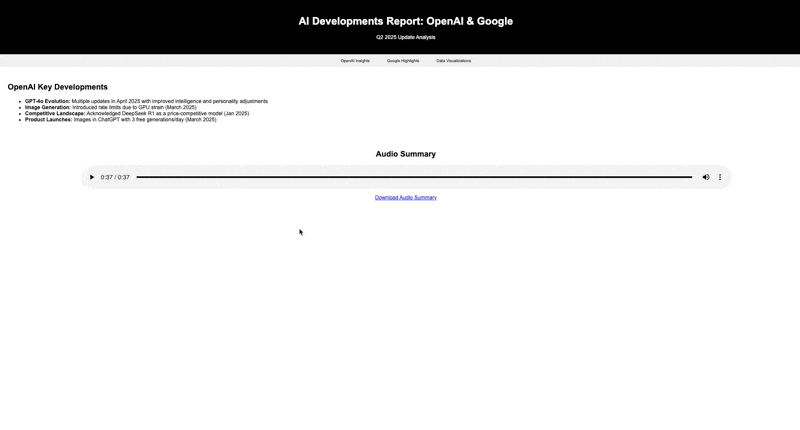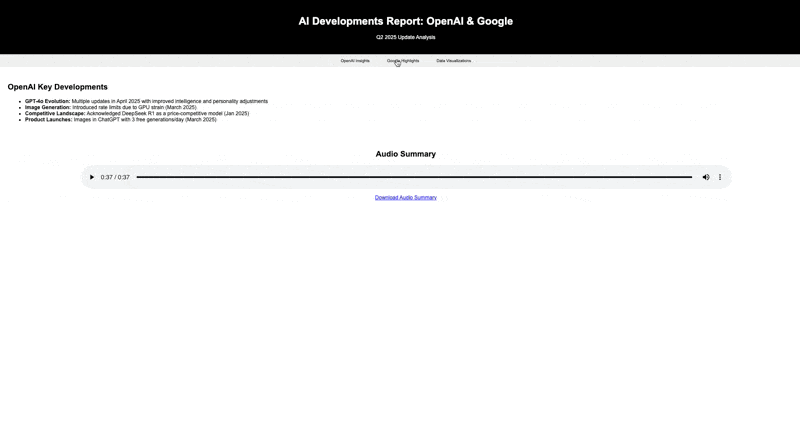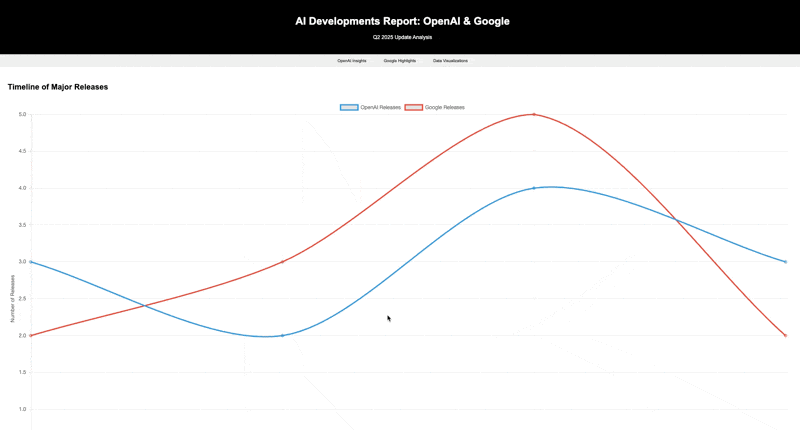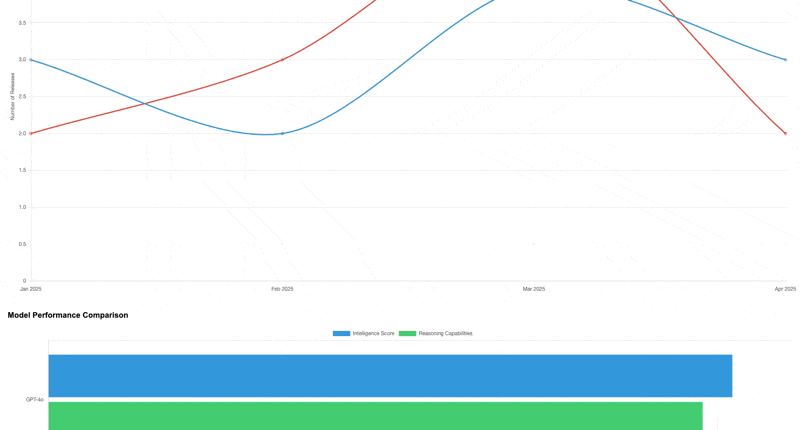
能够正确判断调用哪些工具,然后完成要求,这方面其实比我之前测试 DeepSeek 感觉要好一些。除了界面写的确实有点丑陋,也没啥毛病。(当然也可以说我的提示词写的很烂)
写在最后
本文着重探讨测试了 Qwen 3 的最新发布以及对它的旗舰模型进行了测试。从测试感受来看,我个人认为没有说的那么厉害。大家在应用到实际业务的时候,还是要谨慎选择呀~
当然,测试存在着一定的偏差,所以这个测试并不能完全说明 Qwen 3 的真实水平。
希望大家有机会也可以去多测试一下呀~
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)