“deepseek”本地部署【学习笔记-不定期更新】
本文主要讲述Windows系统如何本地部署DeepSeek蒸馏模型(要求至少为win10系统第一部分为大模型的一些基础知识,可直接跳到第二部分开始部署答:蒸馏模型是将一个复杂的大模型(教师模型)的知识传授给一个相对简单的小模型(学生模型)。个人理解是用DeepSeek的结果来训练其他模型,如拿DeepSeek当数据集来训练千问的大模型,训练出的结果就是蒸馏模型。
前言
本文主要讲述Windows系统如何本地部署DeepSeek蒸馏模型(要求至少为win10系统)
第一部分为大模型的一些基础知识,可直接跳到第二部分开始部署
一、一些基础知识
1.DeepSeek-R1-32B、DeepSeek V3(671B)、Qwen2.5(72B)中的B是什么意思?
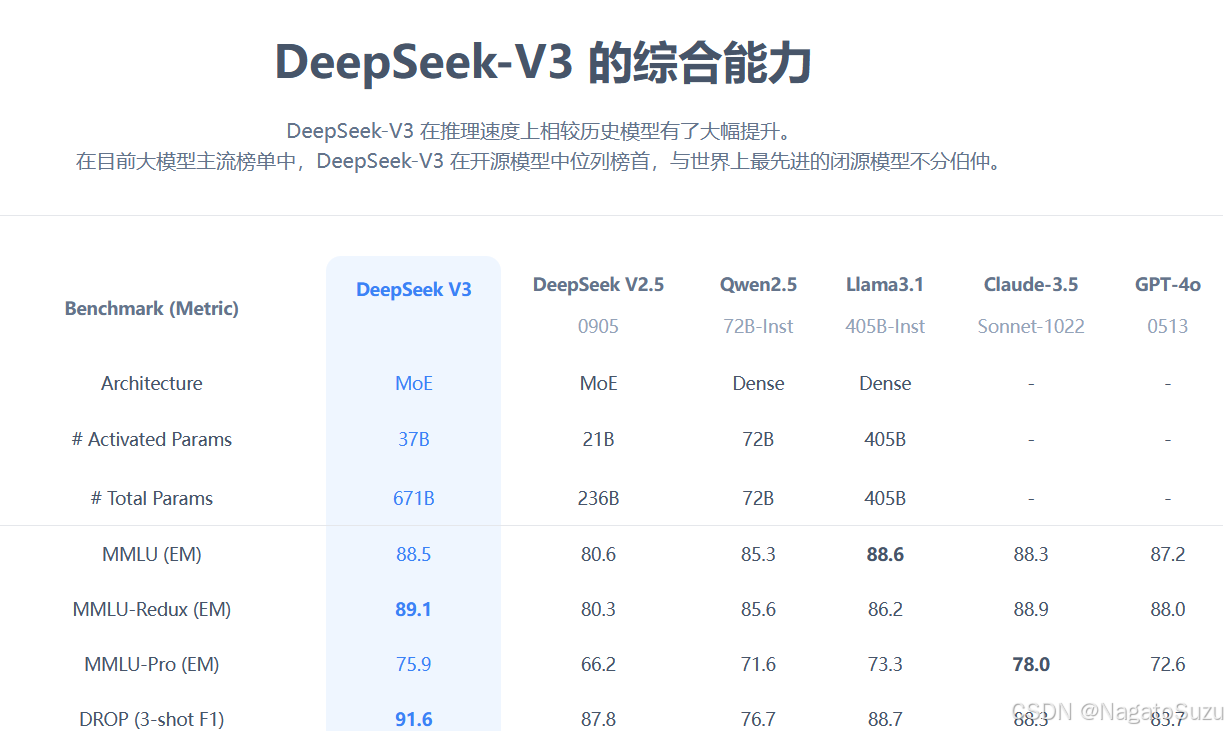
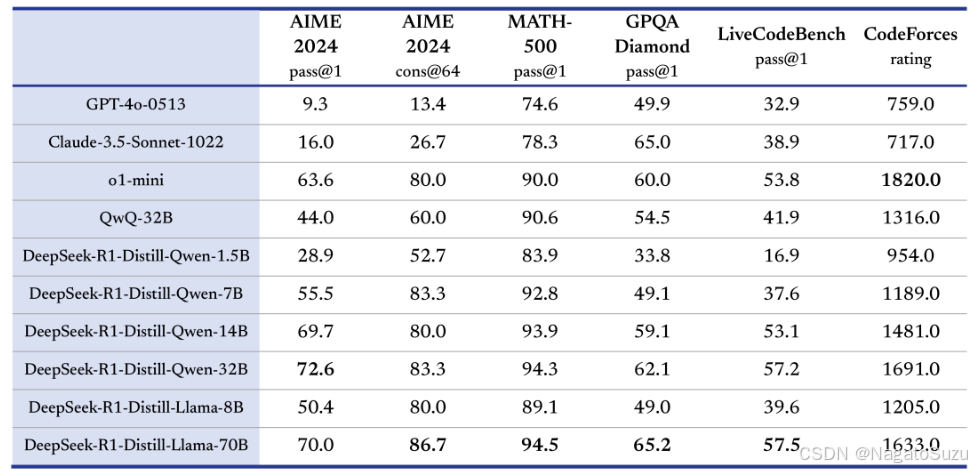
答:B 是 Billion(十亿)的缩写,代表模型的参数量。参数量越大对配置要求越高,回答问题也更精确。
2.什么是蒸馏模型?
答:蒸馏模型是将一个复杂的大模型(教师模型)的知识传授给一个相对简单的小模型(学生模型)。
个人理解是用DeepSeek的结果来训练其他模型,如拿DeepSeek当数据集来训练千问的大模型,训练出的结果(找出关键参数)就是蒸馏模型。
3.为什么说下载的是蒸馏模型
链接: ollama模型选择页面
ollama的模型下载界面明确提到:
“DeepSeek team has demonstrated that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models.
Below are the models created via fine-tuning against several dense models widely used in the research community using reasoning data generated by DeepSeek-R1. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks.”
百度翻译版本:
“DeepSeek团队已经证明,较大模型的推理模式可以被提炼成较小的模型,与通过RL在小模型上发现的推理模式相比,可以获得更好的性能。
以下是通过使用DeepSeek-R1生成的推理数据对研究界广泛使用的几个密集模型进行微调而创建的模型。评估结果表明,蒸馏出的较小密度模型在基准测试中表现出色。”
也就是说除了deepseek-r1:671b是原装的DeepSeek-R1大模型,其他所有模型都是蒸馏模型。
4.deepseek离线知识库数据截止日期
截至2025年5月1日,下载的deepseek7B模型,数据截止到2024年7月
5.RAG(检索增强生成)是什么(未完)
RAG(Retrieval-Augmented Generation,检索增强生成)
个人理解:增加一个本地的deepseek外部数据库
上传本地文件时,会先将文件转换为某些维度的向量
然后当提出问题时就触发了Retrieval(检索)操作,将问题转换为向量
然后系统通过向量与问题,在数据库中寻找结果生成答案
5.Embedding是什么
Embedding是RAG的核心
个人理解:Embedding类似已经训练好的神经网络,会将任何输入的东西分解成多维数据,变成一个黑匣子
二、deepseek模型部署(安装本地大语言模型部署工具)
DeepSeek的本地部署主要分为以下两个步骤:
一是使用本地大语言模型部署工具安装deepseek
二是 安装GUI(图形用户界面)——非必要步骤
本部分使用本地大语言模型部署工具安装deepseek,常见的本地大语言模型部署工具包括Ollama 和 LM Studio,本文选用Ollama进行安装
注: Ollama离线迁移模型,不联网从一台电脑复制到另一台电脑
(一)Ollama
开源
1.安装Ollama
Ollama软件要求至少为win10系统。
官网链接:Ollama软件官网链接
国内加速下载官网链接:Ollama国内加速下载官网链接
下载Ollama模型
软件运行默认C盘安装(C:\Users\用户名\AppData\Local ),如想安装到其他盘如D盘,请采取如下操作
(1)首先在想安装的位置创建一个文件目录(比如“D:\myAI\Ollama”),
(2)在安装程序所在文件夹,win11按下鼠标右键,选择在终端中打开;win10按下shift+鼠标右键打开powershell窗口
(3)输入“OllamaSetup.exe /DIR=“d:\myAI\Ollama””,如果显示无法识别"OllamaSetup.exe",则输入“ .\OllamaSetup.exe /DIR=“d:\myAI\Ollama””
(4)执行成功时会弹出安装界面,之后一路默认安装即可
安装完成后按下Win+R键,运行cmd或直接在开始菜单搜索命令提示符后
进入命令提示符界面,输入以下指令
ollama
显示出Usage、Available Commands、Flags等参数表明安装成功
2. Ollama常用指令
| 命令名 | 效果 |
|---|---|
| ollama serve | 启动ollama服务器,默认113. |
| ollama run <model-name> | 启动某个大模型,没有自动下载并启动 |
| ollama pull <model-name> | 下载某个大模型 |
| ollama list | 显示所有已下载的模型 |
| ollama serve | 启动ollama服务器,默认11434 |
| ollama serve stop | 关闭ollama服务器 |
3. DeepSeek模型的选择与下载
deepseek模型选取,最低配置参考信息
(1)1.5B模型
CPU:4核以上(需支持AVX2指令集)
内存(RAM):8GB以上
GPU(可选):显存>=4GB
存储:需3~5GB硬盘空间
(2)7B、8B模型
CPU:8核以上(需支持AVX2指令集)
内存(RAM):32GB以上
GPU(可选):显存>=16GB
存储:需15~20GB硬盘空间
可以使用CPU-Z应用,查看自己电脑的CPU是几核、内存大小、显存大小
演示电脑选择7B模型,从ollama模型选择页面中找出7B模型的下载指令(“ollama run deepseek-r1:7b”),然后在命令管理器输入相应指令,等待后如果显示sucess那么就下载成功了,可以随便问个问题测试是否可以正常运行
建议:同时下载一个Embedding模型
注:默认安装路径为C:\Users\用户名.ollama\models
如果模型想保存到指定位置,需要在系统变量中指定OLLAMA_MODELS = 模型保存路径,之后重启电脑再进行模型安装
下载模型后会在指定路径里生成两个文件夹:blobs保存模型文件。mainfests保存模型的版本号。
三、安装GUI(图形用户界面)
常见的GUI界面包括:Anything LLM、Open WebUI、Chatbox、Page Assist(这个是浏览器插件)
在终端输入以下指令可查看电脑处理器架构
echo %PROCESSOR_ARCHITECTURE%
(一)AnythingLLM(直接安装版)
开源
1.安装
官网链接:AnythingLLM软件官网链接
按处理器架构选择对应版本下载后点击安装
安装后一直点下一步,创建第一个工作区即可(部分页面下一步在右侧)
2.配置设置
界面左下角小钳子里:人工智能提供商——LLM首选项选择Ollama,选择已下载好的模型并保存配置;人工智能提供商——Embedder首选项也选择Ollama,模型可以从ollama模型选择页面选择一个embedding模型下载
左侧工作区右侧的齿轮:聊天设置——工作区 LLM 提供者选择Ollama,选择已下载好的模型并更新工作区
**注意:**建议将聊天设置——聊天提示改成中文
原文:Given the following conversation, relevant context, and a follow up question, reply with an answer to the current question the user is asking. Return only your response to the question given the above information following the users instructions as needed.
百度翻译版:根据以下对话、相关背景和后续问题,回答用户当前提出的问题。根据需要,按照用户说明,仅返回您对上述信息问题的回答。
3.建立本地知识库
点击一个工作区右侧的上传按钮
将想要上传的文章拉入左侧,在拉入右侧,保存
注:左侧是所有文档,右侧是当前工作区的文档
(二)Page Assist
开源的浏览器扩展程序
1.安装
以谷歌浏览器为例:
0.如果能进入Chrome 应用商店可以直接下载
1.提前准备好插件
2.打开谷歌浏览器右侧——设置——扩展程序——管理扩展程序
3.打开右上角开发者模式,将插件拉进来
2.配置设置
建议在详情将“固定到工具栏”实现快速访问
打开插件界面,在上方选择模型即可正常运行
(三)Chatbox
开源
1.安装
官网链接:Chatbox软件官网链接
网页上面下载界面可以选择为别的系统下载安装软件
下载后默认安装即可
2.配置设置
首次使用选择“使用自己的API Key或本地模型”
选择Ollama API
创建新对话即可
(四)Open WebUI
开源,必须用到Docker
四、局域网部署
创建两个用户变量
OLLAMA_HOST = “0.0.0.0”
OLLAMA_ORIGINS = “*”
理由, 引用——本地DeepSeek部署实战:局域网访问与API对外开放技巧:
OLLAMA_HOST 为默认值的情况下,Ollama仅监听127.0.0.1:11434,仅允许本机访问。通过设置OLLAMA_HOST=0.0.0.0:端口号,可将服务绑定到所有网络接口,实现局域网内多设备共享模型资源。
OLLAMA_ORIGINS为默认值的情况下,浏览器安全策略会阻止跨域请求,例如使用Open WebUI等前端工具时。配置OLLAMA_ORIGINS=*(允许所有来源)或指定域名列表(如http://localhost:3000),可解除跨域限制。
重启ollama服务后,使用page assist插件,在设置中将"Ollama 设置"的"Ollama URL"改成“http://服务器IP:11434”
五、建立本地知识库
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)