基于Prometheus+Grafana的Deepseek性能监控实战
在/data/sda/deploy/vllm/prometheus 文件夹下面创建 prometheus.yml 文件。传统监控方案难以捕捉LLM服务特性,本文将展示如何构建针对vLLM的定制化监控体系。(这里用http://localhost:3008/login 貌似是有点问题的)访问 http://192.168.0.110:3008/login。连续批处理:动态合并请求,GPU利用率提升至
文章目录
1. 为什么需要专门的大模型监控?
大型语言模型(LLM)服务化面临独特挑战:
高显存消耗与GPU利用率波动
请求响应时间(Token生成速度)不稳定
批处理吞吐量动态变化
长文本场景下的OOM风险
多租户场景下的资源抢占
传统监控方案难以捕捉LLM服务特性,本文将展示如何构建针对vLLM的定制化监控体系。
2. 技术栈组成
2.1 vLLM(推理引擎层)
技术定位
UC Berkeley开源的LLM服务框架,专为GPU推理优化
核心特性:
PagedAttention算法:实现显存动态分页管理,提升3倍吞吐量
连续批处理:动态合并请求,GPU利用率提升至92%+
OpenAI兼容API:无缝对接LangChain等生态工具
多GPU自动分片:支持Tensor Parallelism分布式推理
2.2 Prometheus(监控采集层)
技术定位
云原生时序数据库,专为动态指标采集设计
关键实现:
多维数据模型:支持labels标记的时序存储
主动拉取机制:通过HTTP定期获取目标数据
高效压缩算法:1小时原始数据(1.3GB)压缩至65MB
预警规则引擎:基于PromQL的实时阈值判断
2.3 Grafana(数据可视化平台)
技术定位
跨平台指标可视化系统,支持动态仪表盘编排
高阶功能:
混合数据源:同时接入Prometheus+Elasticsearch
智能警报路由:支持分级通知(企业微信/邮件/短信)
版本化存储:仪表盘配置自动保存至Git仓库
权限联邦:集成LDAP/SSO统一认证
Deepseek:大语言模型(可替换本地大模型)
技术定位
国产高性能大语言模型,支持多模态扩展
3. 监控系统架构
[vLLM服务] --> [Prometheus Exporter]
↑ ↓
[Node Exporter] [Prometheus Server]
↑ ↓
[DCGM Exporter] <--> [Grafana Dashboard]
4. 实施步骤
4.1 启动DeepSeek-R1模型
之前文章也有介绍下载部署deekseek: 在Ubuntu 20上使用vLLM部署DeepSeek大模型的完整指南
启动命令:
vllm serve DeepSeekR1 --port 8000 --max-model-len 16384 --gpu-memory-utilization 0.9 > vllm.log 2>&1
查看日志: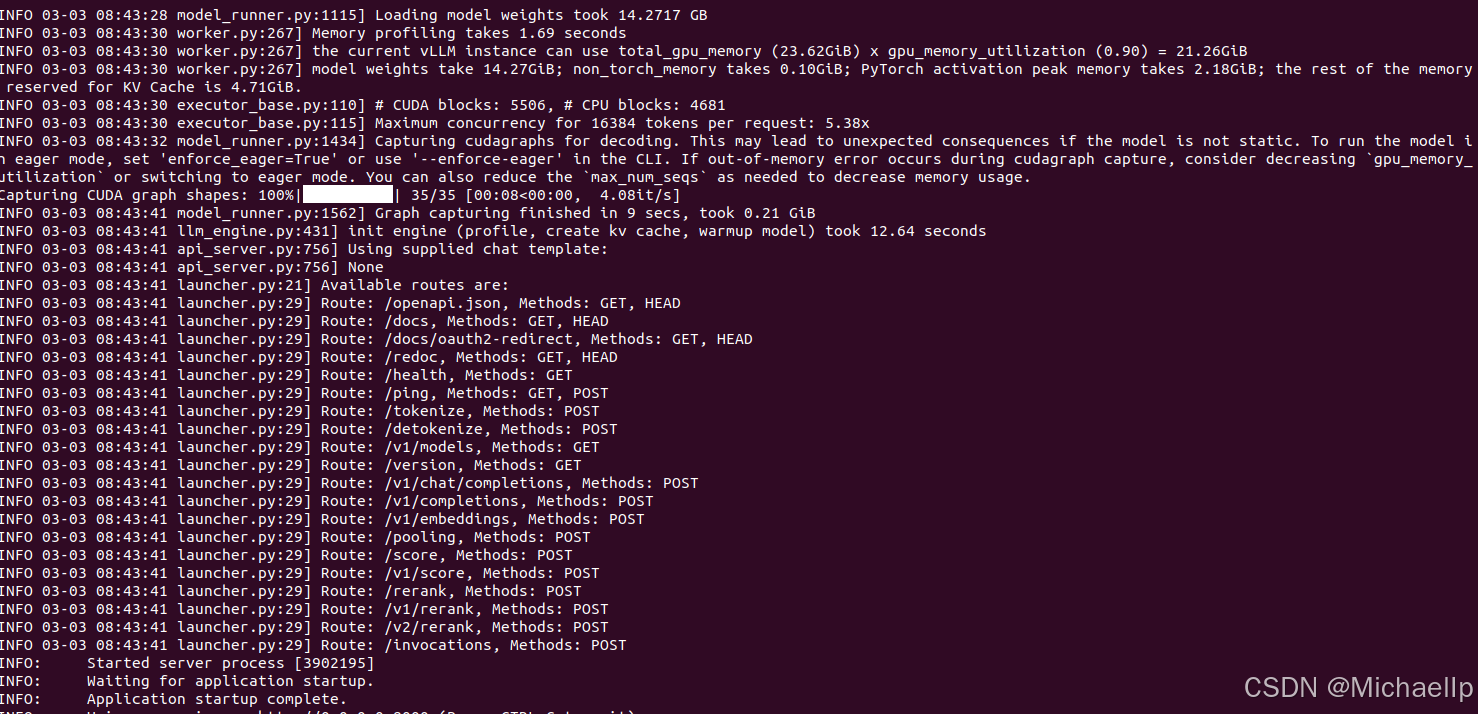
4.2 部署 Prometheus
4.2.1 拉取镜像
docker pull bitnami/prometheus:2.48.1

4.2.2 编写配置文件
创建目录:
mkdir -p /data/sda/deploy/vllm/prometheus/data
在/data/sda/deploy/vllm/prometheus 文件夹下面创建 prometheus.yml 文件
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'deepseek'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets:
- 'localhost:8000'
localhost:8000指向的是大模型的链接。
4.2.3 启动容器
sudo chown 1001:1001 /data/sda/deploy/vllm/prometheus/data
docker rm -f prometheus ; docker run -d --name prometheus --user 1001 -p 9090:9090 -v /data/sda/deploy/vllm/prometheus/data:/opt/bitnami/prometheus/data -v /data/sda/deploy/vllm/prometheus/prometheus.yml:/opt/bitnami/prometheus/conf/prometheus.yml bitnami/prometheus:2.48.1

4.3 部署 Grafana
4.3.1 拉取镜像
docker pull grafana/grafana:10.0.10
4.3.2 启动容器
$ docker rm -f vllm_grafana ; docker run -d --name vllm_grafana -p 3008:3000 grafana/grafana:10.0.10

4.3.3 接入 Prometheus 数据
访问 http://192.168.0.110:3008/login
(这里用http://localhost:3008/login 貌似是有点问题的)
设置初始化的账号密码,我这里账号密码都有admin
如下图所示点击“Data sources”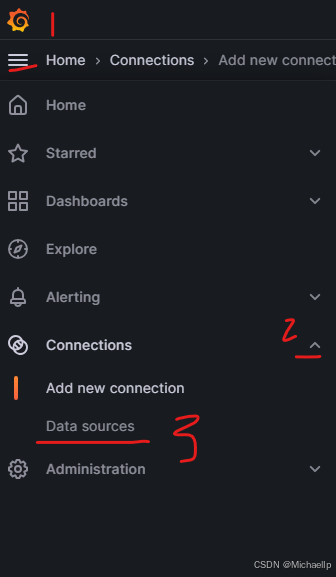
如下图所示点击“Add new data source”
选择 “Prometheus”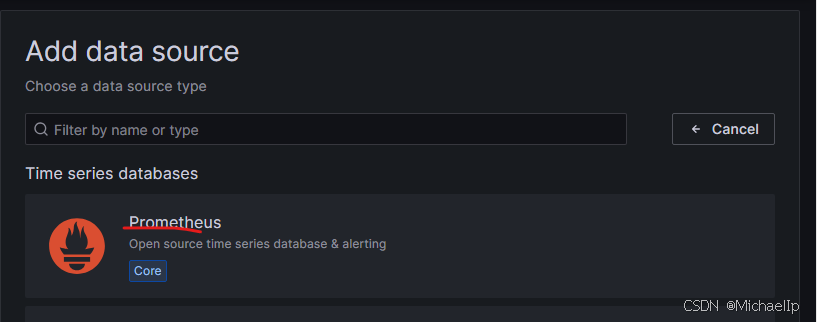
名字随便取,URL 用Prometheus server的URL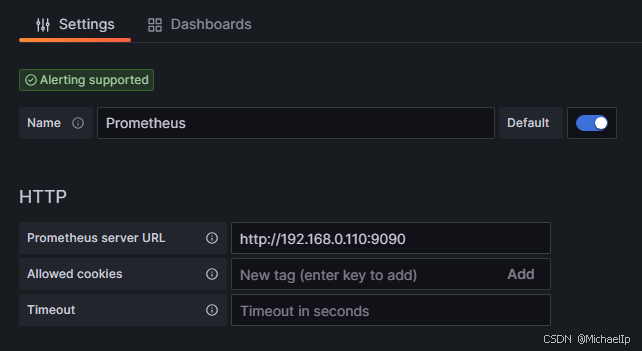
翻到最下面点击保存和测试 Save & test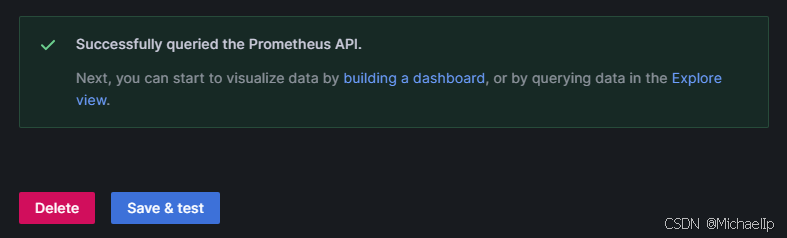
滚到最上,点击构建仪表盘 Build a dashboard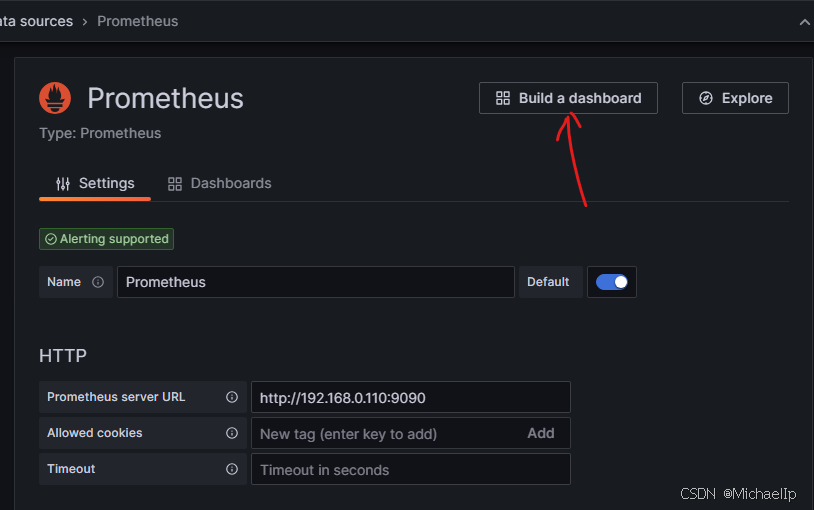
添加可视化 Add visualization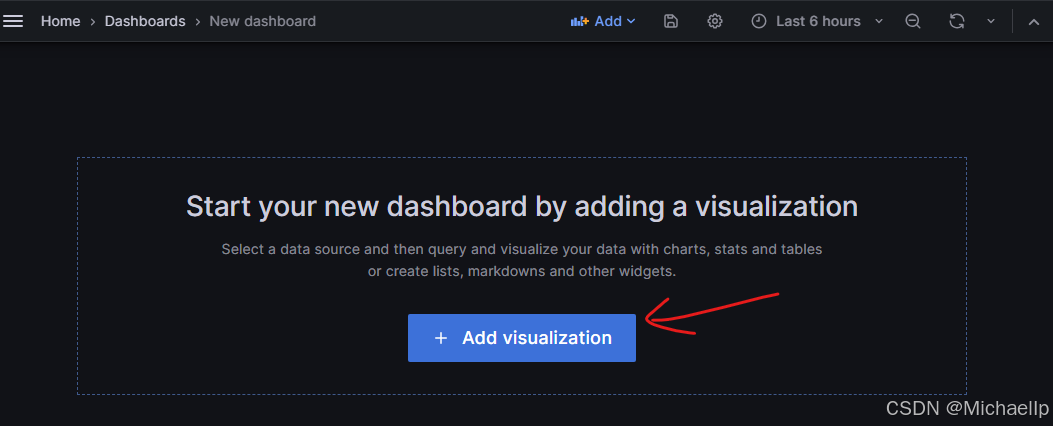
选择刚刚设置的data source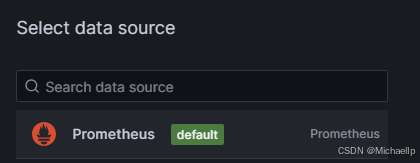
选择scrape_duration_seconds, 然后点击‘Run queries’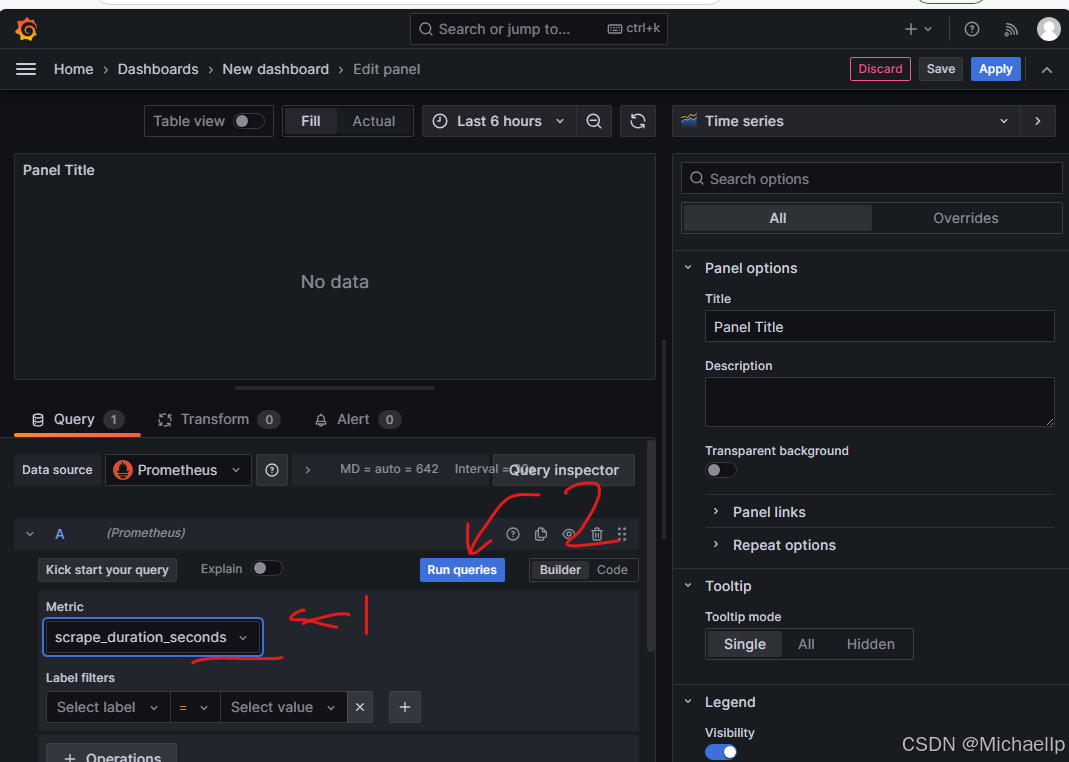
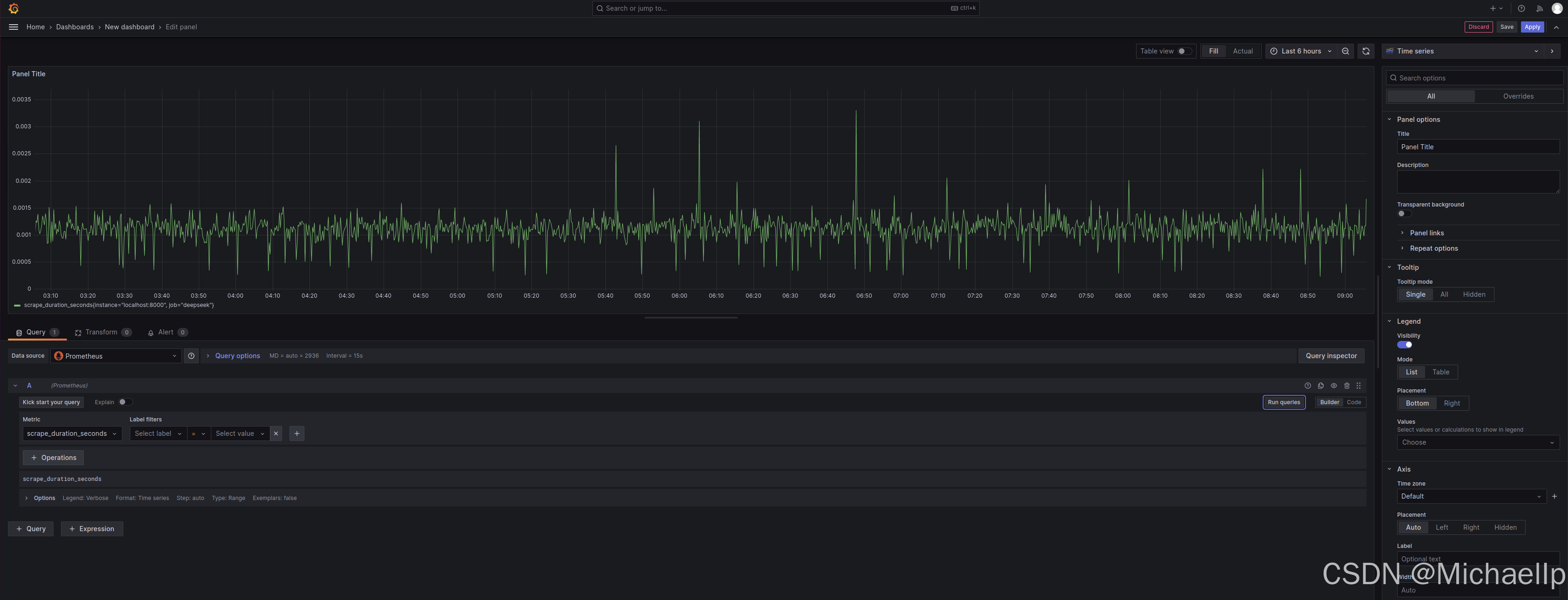
5. 延伸思考
基于监控数据的自动扩缩容(结合K8s HPA)
请求特征分析(Prompt长度 vs 资源消耗)
能效优化(Tokens/Watt指标构建)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)