许多人说DeepSeek是从GPT蒸馏出来的,这是真的吗?
Transformer 是 Google 在 2017 年提出的神经网络架构(论文《Attention Is All You Need》),它基于自注意力(Self-Attention)机制,适用于序列建模任务(如机器翻译、文本生成等)。它本身不是一个具体的模型,而是一种技术框架。
Transformer 和 GPT 是两个不同的概念,许多人容易混淆它们。
Transformer 是一种架构
Transformer 是 Google 在 2017 年提出的神经网络架构(论文《Attention Is All You Need》),它基于自注意力(Self-Attention)机制,适用于序列建模任务(如机器翻译、文本生成等)。它本身不是一个具体的模型,而是一种技术框架。
Transformer 架构遵循编码器-解码器结构,但不依赖于循环和卷积来生成输出。
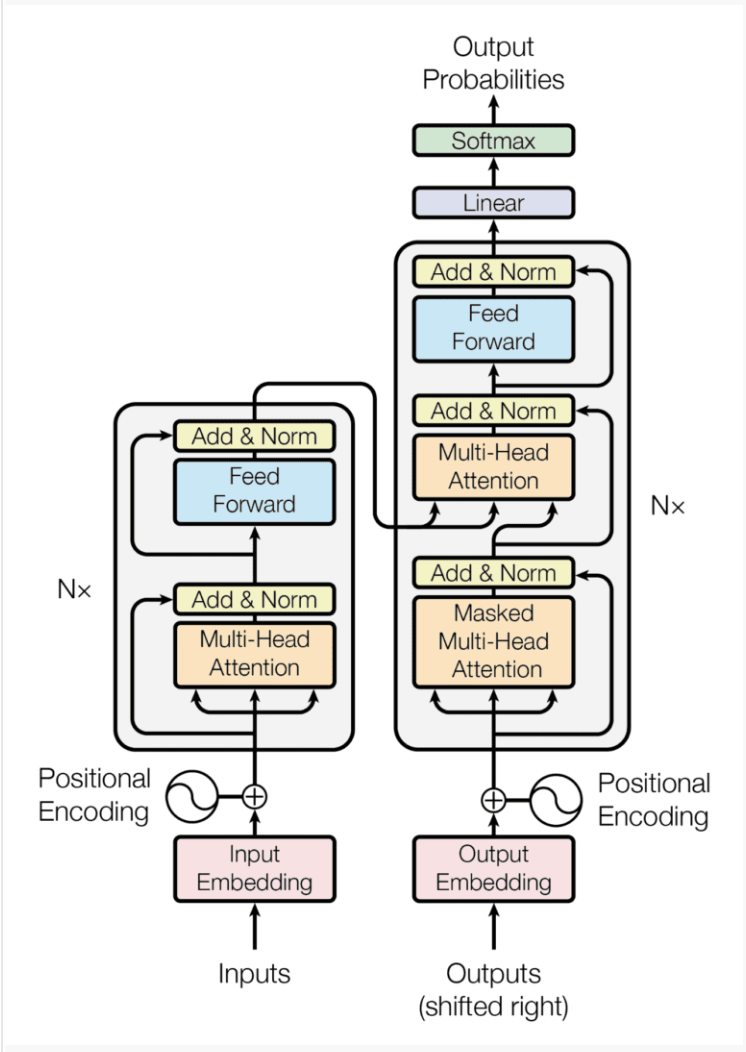
Transformer 架构的编码器-解码器结构
摘自“ Attention Is All You Need ”
简而言之,Transformer 架构左半部分的编码器的任务是将输入序列映射到连续表示序列,然后将其输入到解码器中。
解码器位于架构的右半部分,它接收编码器的输出以及前一时间步骤的解码器输出,以生成输出序列。
GPT 是基于 Transformer 的模型系列
GPT(Generative Pre-trained Transformer)是 OpenAI 基于 Transformer 解码器(Decoder-only)部分构建的一系列语言模型。GPT-1、GPT-2、GPT-3、ChatGPT(GPT-3.5)和 GPT-4 都属于这个系列。它们的特点是采用自回归(Auto-regressive)方式生成文本。
其他模型也基于 Transformer
像你提到的 LLaMA(Meta)、Qwen(阿里)、Gemini(Google)、Claude(Anthropic)等,都使用了 Transformer 架构,但它们在结构细节(如注意力机制、位置编码)、训练数据、优化目标等方面与 GPT 不同。例如:
- LLaMA 使用了 Grouped Query Attention(GQA)优化推理速度。
- Qwen 可能采用了不同的分词器和训练策略。
- Google 的原始 Transformer 论文甚至主要针对编码器-解码器结构(如 T5、BART),而 GPT 只用了解码器。
关于 DeepSeek 是否从 GPT 蒸馏
蒸馏(Knowledge Distillation)是指用小模型模仿大模型的行为(如输出概率分布)。目前没有官方证据表明 DeepSeek 直接从 GPT 蒸馏,原因包括:
- 技术路线差异:DeepSeek 公开的技术细节(如上下文长度、架构优化)与 GPT 系列有明显不同。
- 训练数据差异:如果 DeepSeek 主要用中文/多语言数据训练,而 GPT 以英语为主,直接蒸馏效果可能不佳。
- 开源与合规性:大模型蒸馏通常涉及版权问题,DeepSeek 作为正规机构更可能独立训练。
为什么有人会混淆 Transformer 和 GPT?
- 品牌效应:GPT 因 ChatGPT 变得家喻户晓,许多人误以为所有 Transformer 模型都是“GPT”。
- 术语滥用:媒体或非技术人员可能简化表述,导致概念泛化。
提示:作者新书《AI全能助手:人人都能玩转DeepSeek》出版,新书5折活动中,欢迎感兴趣的朋友点击下面链接购买~

一本书精通DeepSeek工作+学习+娱乐+本地化部署+私人知识库+底层原理!
《AI全能助手:人人都能玩转DeepSeek》![]() https://item.jd.com/14399943.html
https://item.jd.com/14399943.html
☆DeepSeeK+Kimi+Xmind+ Cline等10余种AI工具实操
☆本地部署(零基础教会DeepSeek本地部署)
☆搭建私有知识库(使用DeepSeek搭建个性化私有知识库)
☆办公、科研、生活、娱乐全场景覆盖
☆免费加入读者交流微信群。作者进行
购书即享四重福利DeepSeek“学习大礼包”
☆83集300分钟DeepSeek视频教程
☆508页DeepSeek高价值PPT
☆113个DeepSeek提示词模板
☆10余个AIGC工具详解电子书
为什么选择这本书
☆涵盖从DeepSeek入门到成为DeepSeek高手的核心知识、方法和技巧☆DeepSeek+10余款主流人工智能工具跨软件实操☆办公、生活、学习全场景覆盖☆特别讲解本地部署+搭建私人知识库

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)