DeepSeek王炸开源!数学推理之神刷新SOTA,中国AI模型再下一城
DeepSeek再次扔出“数学核弹”开源定理证明模型DeepSeek-Prover-V2:狂破88.9%正确率,横扫顶尖数学难题,7B小模型单卡可跑,671B巨兽刷新16项SOTA——数学推理的“上帝模式”正式开源。
五一假期第一天,AI圈又被DeepSeek刷屏了!
此前全网疯传的“DeepSeek-R2”虽未如约而至,但DeepSeek却扔出了一枚更重磅的数学推理王者——开源定理证明模型DeepSeek-Prover-V2,直指数学推理领域的顶尖难题。
此次发布的 V2 版本共开放 7B 和 671B 两个参数规模,其中 DeepSeek-Prover-V2-671B 在权威数学基准测试 MiniF2F 上以 88.9% 的通过率刷新纪录,甚至能解出普特南数学竞赛(PutnamBench)中49道地狱级考题。很多开发者直言:“奥数题从没这么简单过”。
思维革命:把奥数题拆成乐高积木
如果说大模型解决数学题是让AI模仿人类,那么DeepSeek-Prover-V2的突破在于——它建立了一套机器专属的数学语言体系。
传统数学大模型往往依赖大量标注数据,但 DeepSeek-Prover-V2 却走上一条自我进化的路径:
1. 递归拆题黑科技:用 DeepSeek-V3 将复杂问题拆解成可验证的子目标,如同把奥数题变成乐高积木。
2. 双脑协作模式:7B小模型专攻子问题,671B大模型统筹全局,既保证效率又提升精度。
3. 数学推理“双语训练”:同步学习人类自然语言推理和机器可执行的Lean4代码,实现从“直觉思考”到“严谨证明”的无缝衔接。
这种“分而治之”的策略,让模型在面对IMO级难题时,能像顶级教练一样拆解出20+个引理步骤,再逐一击破。
在MiniF2F 测试集上,DeepSeek-Prover-V2-671B以88.9%的通过率碾压群雄(此前SOTA模型仅为70.2%)。更惊人的是,它攻克了被学界视为“不可能任务”的PutnamBench中的49道题,而当前最优模型仅能解决12道。
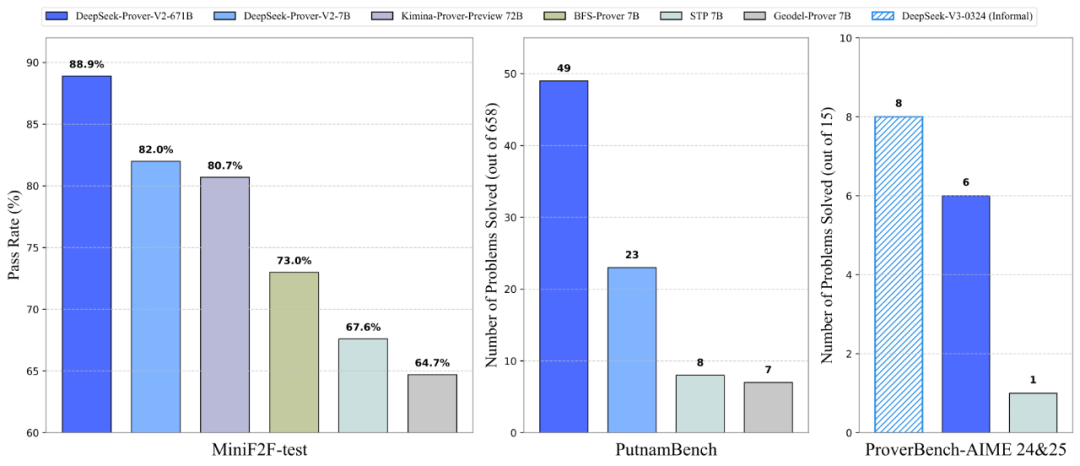
就连最考验综合能力的AIME数学竞赛题,其专门构建的评测集ProverBench也显示:V2模型对高中竞赛题的解决率超过80%,大学教材题更是达到92%。这意味着,从奥数集训到数学系作业,AI已经能覆盖多数场景。
DeepSeek此次仍然是诚意拉满:7B/671B双版本登录HuggingFace,支持32K长上下文推理 ,且证明过程全部公开。
开发者实测显示,用7B版本在消费级显卡上即可运行,且效果远超同规模模型。有网友用RTX4090测试,仅7B模型就秒杀了Grok-3、Claude-3等闭源巨头。
中国AI开源生态的再次跃升
DeepSeek的发布节奏向来精准且果断。在国内大模型热潮逐渐从“狂飙”走向“比拼内功”的当下,这家团队始终坚持“长期主义+实用性”路线:既在模型能力上追求极致,也在开放策略上尽可能放权科研与开发者。
此次发布的Prover-V2-671B不仅技术指标惊艳,而且全量模型权重、配置文件、说明文档一并放出,为国内AI研究、类比学习、开源社区发展提供了极其稀缺的基础资源。相较某些海外模型出于合规与市场考量采取“半开源”策略,DeepSeek的“真开源”态度更具长远影响力。
更重要的是,DeepSeek正将自身优势拓展至“科研工具链”中。数学证明类模型此前主要集中在OpenAI、Google DeepMind等机构手中,国内鲜有机构专攻此类“高冷领域”。而DeepSeek此举不仅补齐了国产模型在这一垂直方向的短板,也为推动“AI+科研”深度融合提供了重要基础。
此刻,所有目光再次聚焦中国AI团队——DeepSeek的下一张王牌,正在路上。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 3
3 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)