【一文读懂】替代DeepSeek成为国产第一大模型,阿里通义Qwen3发布,大模型们都在较什么劲?
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。从 MoE 厨房的“点菜制”,到”深度思考“按
1、国产冠军王座易主背后意味着什么?
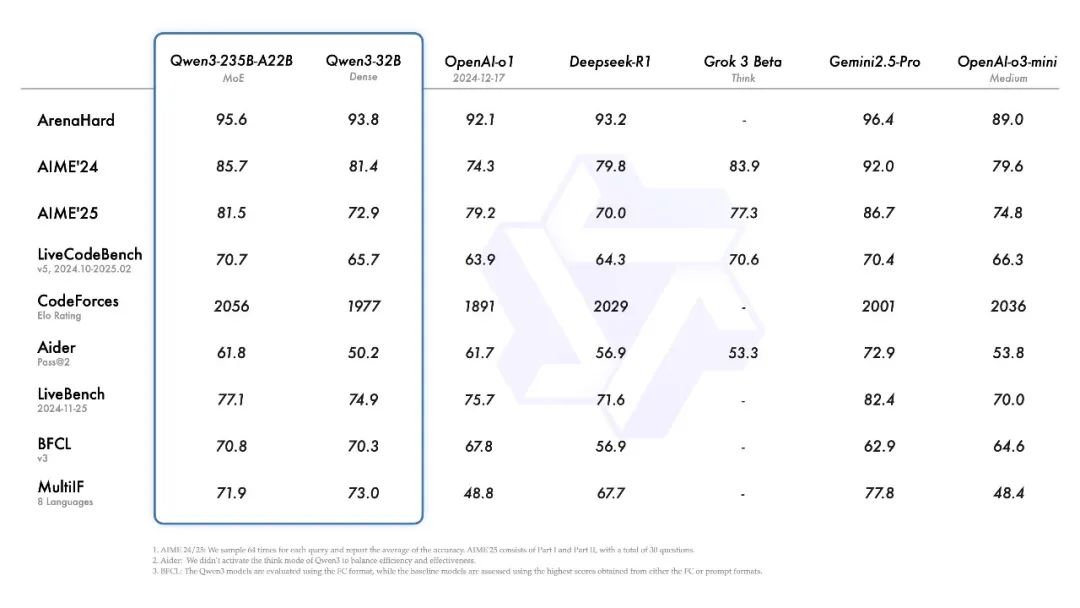
4 月 29 日凌晨,权威大模型基准测试 ARENA Hard 榜单更新:
阿里巴巴最新旗舰大模型 Qwen3-235B-A22B 得分 95.6,超越 DeepSeek-R1 的 93.2,刷新了开源模型最高分纪录。
这意味着,被 DeepSeek 统治了整整 3 个月的“国产第一”位置,正式易主。
Qwen3 在各项基准测试中超越一众国内外旗舰大模型
早在今年 1 月,DeepSeek-R1 依靠 6710 亿超大参数量和灵活的 MoE 架构成功“出圈”,引发一股国产 AI大模型热潮。
春节期间,阿里”被动发布“通义千问Qwen 2.5 系列模型,未能引发市场大规模关注。
直到昨天凌晨,阿里突发“大招”——Qwen 3系列一次性放出 8 个版本开源模型。依靠出色的评测数据,宣告新一波国产大模型之争正式开打。
2、核心技术三问:Qwen3 何以 “四两拨千斤”?
核心架构变更:从 Dense 走向 MoE
什么是 Dense架构,又为何走向 MoE?
想象你要开一家餐厅,面对不同的顾客订单。

Dense = 全员上阵,简单但浪费;
MoE = 挑对人干对活,高效但调度难
Dense 架构(稠密模型):
| 每当有一位顾客来点餐,全餐厅所有厨师(不管擅长啥)都一起动手做这道菜!
- 不管是烤肉师傅、甜品师傅、日料师傅、意大利厨师,全都被叫来一起做一个牛排……
- 这样做的好处是:保证每个人都参与,餐厅流程简单,所有厨师天天练习,水平稳定。
- 当然但问题也明显:超级浪费人力(做个小蛋糕也要一群人动手),成本高,速度慢。
MoE 架构(混合专家模型):
|顾客来了,只根据菜品选择最擅长的厨师,其他厨师就继续休息。
-
来点牛排?叫西餐厨师!
-
来碗麻婆豆腐?请川菜师傅上!
-
每次只有几位“专家厨师”同时上岗,其他人不必忙活,节省了大把资源,效率也快多了。
更进一步来说其实二者皆有使用场景:
- 当你的小餐厅只有几道菜、几个厨师时(比如小模型),Dense 很好用。
- 当你的餐厅有成百上千道菜、上万顾客时(比如大模型),MoE 能帮你节约大量的人力物力。
双模式混合:“思深” + “行速”
Qwen3 整合了两种模式,面对各种场景都游刃有余:
- 速记模式:遇到寒暄、摘要,直接给答案,延迟最低。
- 学霸模式:打开“深度思考”,模型自动添加链式推理,多加几步“打草稿”。
在实际测试中,一道 GSM8K 小学奥数题,速记 4 秒答错,学霸 32 秒答对。
效率与效果得以兼顾。

开启“学霸模式”,妈妈再也不用担心小知的数学成绩
数据 & 训练:36T Token 的“全科复习”
Qwen 官方博客给出的数据显示:
- 预训练语料扩增到 36 万亿 Token,是前代 2 倍,多语种覆盖 119 种语言!
- 四阶段微调:长链路冷启动 → RL 推理 → 双模融合 → 通用 RL,对应解决“记忆力 / 思考力 / 速度 / 安全性”四座大山。
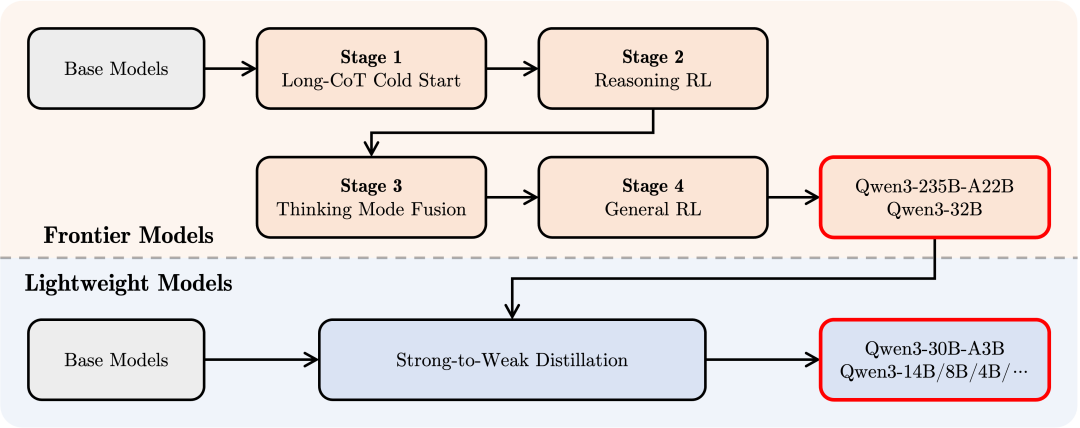
Qwen3 四阶段微调好比“十年磨一剑”
从前段时间大火的智能体 Manus 到如今的 Qwen3, RL(Reinforcement Learning,强化学习)技术被反复提及。
那么到底什么是 RL?我们来和机器学习中的另外一种机制“监督学习”来做对比:
监督学习(Supervised Learning):相当于老师给了“题目—标准答案”成对的训练集,模型只要学会一一对应,就能预测新题答案。
强化学习(RL):没有现成答案,只能给出“对”或“不对”的反馈(奖励信号),模型需要自己探索才能发现最优解。
所以,RL 更像是在野外自学技能,需要自己摸索哪种动作能换来更多好处。也正是不断变化的环境中持续学习,根据最新反馈调整策略,使得模型在需要连续决策、复杂推理、环境多变的场景中大放异彩。
这个极端对比的目的是想告诉知友们,不要一味的追求大参数数量,小尺寸模型对我们生活的影响可能更加深远。
3、硬件 / 成本视角:省到哪里、贵在何处?
阿里一口气放出 8 款 Qwen3 模型, 参数数量从 0.6B 到 225B 适配各种等级的硬件设备。
Qwen3:八仙过海,各显神通
“体重”差不多,饭量差一倍
Qwen3 的2350 亿参数看似“块头”不小,但因 MoE 架构一次只调度部分专家,所以推理时的显存占用与700 亿 Dense 模型接近,比 DeepSeek-V3 少了整整 3-4 张 英伟达A100。
对创业团队而言,直接省下 ¥150/小时的云计算费用,相当于一周多出一位工程师的薪水。
从“开发笔记本”到“生产集群”一条龙
从0.6B 到 32B Dense 的 Qwen3 小兄弟们能在消费级显卡甚至电脑 CPU 上跑 Demo(开发者狂喜)。
当你把原型搬上 8 卡服务器,只需换权重文件,Prompt、API 调用、代码逻辑 0 改动。
谁说“省钱”就一定“掉链子”?
内存省 ≠ 能力缩水。
公开实测显示,22 GB 显存下的 Qwen3-235B 推理速度≈ Dense-30B,但在 MMLU、LiveCodeBench 等基准分数却高出后者数十个百分点。
这意味着同一块显卡,你能让客服机器人答得更准、代码助手修 Bug 更快,从而把 GPU“每小时产值”拉满。
| 模型 | DeepSeek R1 满血版 | Qwen3****0.6B |
|---|---|---|
| 架构 | MoE | Dense |
| 参数数量 | 6710 亿 | 6 亿 |
| 显存需求 | 1342 GB | 8–16 GB |
| 部署设备 | 需企业级服务器、GPU 集群 | 可在高端笔记本或台式机上运行 |
极端对比感受到小模型在消费级硬件上的优势
4、产业落地:拥抱开源,利他利己
企业选择将技术“开源”(公开源代码)为何值得大书特书?
因为它不仅代表“免费使用”,更意味着 可改、可商用、可审计、可传承——这四个关键词直接决定一家公司使用 AI的 投产速度与风险成本。
Qwen 积极拥抱“开源”,与社区一起造福人类
####为什么 Apache-2.0 比“免费”更香?
虽说 Meta的 Llama 开启了大模型开源的风潮,但是 Qwen 选择的开源许可协议 Apache-2.0 有着更强的开放意义!
| 关键条款 | Apache 2.0 | Llama |
|---|---|---|
| 可修改/再分发 | 二次开发后仍可闭源出售 | 禁止“提供模型即服务” |
| 专利授权条款 | 防止日后被专利反诉 | 无显式专利保护 |
| 无地域/行业限制 | 金融、医疗、政府均可直接上线 | 不得“训练或改进其他模型” |
| 商用 0 费用 | 无额外授权金 | 需>7000万月活时签附加协议 |
简单来说,拿到源码=拿到产权:
- 创业公司可打包“Qwen3-财经版”直接卖 License。
- 大厂能够深度内嵌到自家云平台,做增值收费。
- 开发者则可以自由分叉出“自有版本”,可随意更改创作。
Qwen3 全面拥抱开源,使用 Apache 2.0 许可
正因如此,可预见不少团队会使用 Qwen3 实现超长上下文、MCP 支持等新特性,打造更加丰富的 AI产品。
形成 “取之于社区”,“回馈到社会” 的正向循环。
5、尾声 |未来造梦者
从 MoE 厨房的“点菜制”,到”深度思考“按钮下的“学霸模式”,再到 Apache-2.0 敞开的大门,大模型的应用成本一降再降。
Qwen3 们的故事其实讲的都是同一句话:当技术门槛被拆得够低,创新的上限就会被打开。
眼下,DeepSeek与Qwen的国产AI霸主之争还将继续,谁也无法预言三个月后的排行榜归属。
但可以肯定的是,下一次“爆款”不再只属于巨头—— 也属于每一个愿意用 AI 造福人类的好产品,把落地场景跑到用户身边的“造梦者”。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)