深度解码 DeepSeek 实战价值:百度 Create 2025 分论坛技术干货全解析
分享DeepSeek 技术创新与产业实践的前沿成果。
在百度 Create 2025 “如何让 DeepSeek 发挥实战价值” 分论坛上,来自百度智能云、NVIDIA 及行业开发者的 10 位嘉宾围绕大模型落地的成本、场景、工程化三大核心难题,分享了 DeepSeek 技术创新与产业实践的前沿成果。
技术突破:从模型优化到基础设施协同

吴健民:DeepSeek 的效果与成本平衡之道
百度智能云千帆大模型研发负责人吴健民指出,DeepSeek 通过超稀疏 MoE 架构实现训练与推理成本的极致优化:训练端在MoE基础上,采用FP8 混合精度训练与高效流水线并行等,大幅降低了训练成本;推理端通过大规模专家并行与计算通信重叠,吞吐较默认方案提升 20 倍,延迟减半。效果方向,DeepSeek-R1 通过规则奖励驱动的强化学习方案,激发模型的推理能力,在解决数学、代码及复杂问题的生成准确性大幅提升。百度智能云千帆平台提供数据蒸馏、模型精调工具链,支持客户针对具体场景进行高效后训练实现模型定制;百舸平台提供训练推理加速方案,包括对DeepSeek模型的低成本训推,以及对国产芯片的深度优化,助力开发者构建 “效果好、成本低、速度快” 的解决方案。

黎世勇:软硬协同构建极致部署效率
百度智能云 AI 计算部黎世勇分享了 DeepSeek 与基础设施的协同创新:通过PD 分离式架构将首 token 生成(Prefill)与后续生成(Decode)分置不同 GPU 集群,结合动态负载均衡与 KV Cache 高速传输,使负载不均衡度从 20 + 降至 1.2-1.8。
针对 MoE 架构的专家负载不均问题,实现按层级的冗余专家调度,配合自研芯片 P800 的 CUDA 兼容优化,完成从单机到三万卡集群的全规格适配,推理吞吐提升近 20 倍。此外,MTP 投机推理优化使计算性能提升 50%,显著降低显存开销。

翟健(NVIDIA):SDK 工具链赋能高效开发
NVIDIA 资深架构师翟健介绍了 SDK 对 DeepSeek 的优化支持:NeMo 框架提供训练、蒸馏一站式方案,支持 MoE 模型的节点调度与量化加速;TensorRT-LLM 实现推理性能持续迭代,最新版本支持 PD 分离部署。
GTC 发布的 Dynamo 工具专门解决 Prefill/Decode 算力分配问题,通过智能路由与 KV Cache 管理,实现不同 GPU 资源的专职化加速,为开发者提供从容器化部署到 API 调用的全流程工具链。
产业落地:从工具链到场景化实践

李景秋:千帆平台加速企业级应用落地
百度智能云李景秋指出,千帆平台日均调用量达 16 亿,50% 的企业通过精调提升模型效果。针对企业痛点,平台推出推理日志挖掘工具,结合 RFT(奖励信号自动化生成)与一键蒸馏技术,在招聘领域实现人岗匹配准确率提升 28%,成本降低 30%。
平台支持 DeepSeek 全系列模型接入,提供内容安全监控、批量推理(成本降至在线服务 40%)及私有化部署方案(如千帆一体机),内置合同审核、文档抽取等开箱即用应用,助力企业快速落地。

李宁:企业级智能应用开发范式变革
百度智能云李宁提出,借助 DeepSeek 重构企业级智能应用的开发范式,在 AI 搜索、Agent 规划、工作流及企业级 RAG 等重点领域展现出显著价值。具体表现为:AI 搜索引入深度推理,实现“搜事实 + 深推理”融合;Agent 规划展示思考过程,提升执行路径的合理性;工作流升级智能编排,驱动复杂业务高效运转;企业级 RAG 架构深化多轮理解,增强深度问答能力。案例显示,智能菜谱助手通过图像识别 + DeepSeek 菜谱生成,实现结构化输出与配图能力;企业级 RAG 系统在金融、法律领域的RAG问答质量提升 15%,指令遵循度显著优化。

特工小鹏:手把手搭建私人版 DeepResearch
特工宇宙技术负责人特工小鹏分享了构建个人版 DeepResearch 的通用实践路径与关键细节:其核心逻辑为"需求搜集→循环检索→报告生成",通过需求确认机制精准捕捉用户意图,利用大模型的推理能力对信息进行验证,过滤无效内容,最后将整理后的信息撰写成报告。此外,他还介绍了选择同系列模型降低信息完备性误判、支持用户自定义检索策略与私有数据源等实践经验,并展示了基于 DeepSeek 与千帆平台构建的 DeepResearch 示例,作为通用构建思路的一种具体实现。
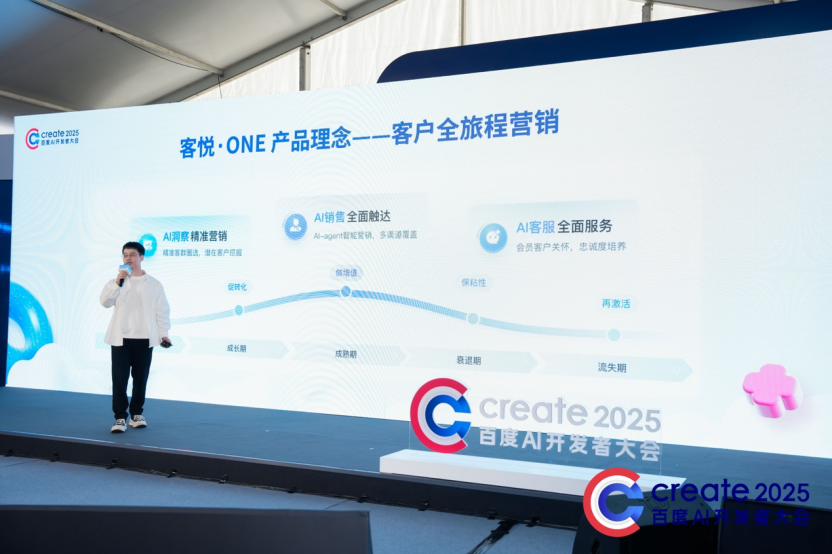
叶翔:百度智能云客悦·ONE 服务营销一体化平台实践分享和DeepSeek的深度融合实践
百度智能云叶翔介绍了客悦・ONE 平台如何通过动态多智能体框架落地 DeepSeek 能力:在客户全旅程营销过程中,利用 DeepSeek-R1 构建对话仿真自迭代系统,模拟不同用户群体与客服机器人对话,实现运营效率提升3倍+,营销转化率提升40%。 首次对外介绍端到端语音大模型并在客悦·ONE落地,实现预存预取、情感适配播报,解决传统 ASR+TTS 方案的时延与音色单一问题,结合多模态交互打造拟人化客服体验,目前客悦·ONE已全面开放公测。
圆桌洞察:从技术普惠到生态共建

圆桌对话中,极客公园创始人&总裁张鹏、百度主任研发架构师董大祥和TangibleFuture创始人&CEO张晓辉围绕 “用得起、用得稳” 核心,指出 DeepSeek 的开源与普惠特性,加速了硬件陪伴机器人(如 LOOI)、智能营销等新场景的发展,但工业级落地仍需解决时延优化(如首 token 生成加速)、模型组合策略(大小模型协同)及成本控制(蒸馏技术)等问题。百度智能云强调通过平台化能力(千帆 + 百舸)降低技术门槛,让开发者聚焦场景创新而非底层架构。
结语:实战价值的核心是 “场景穿透”
从技术创新到场景落地,DeepSeek 分论坛展现了百度在大模型工程化上的全栈能力 —— 通过模型架构优化降低成本、基础设施协同提升效率、工具链整合加速开发、行业场景深耕验证价值。对于开发者而言,核心启示在于:选择适配场景的模型能力(如 DeepSeek 的推理优势),善用平台工具链解决工程化难题,最终通过 “技术 + 场景” 的深度耦合实现商业价值突破。这或许正是大模型从 “能用” 走向 “好用” 的关键路径。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 10
10 0
0- 0



 已为社区贡献324条内容
已为社区贡献324条内容

所有评论(0)