#Paper Reading# DeepSeek Math-Shepherd
本文提出了一种面向过程的数学奖励模型Math-Shepherd。它通过自动给解题的每个步骤分配分数,来解决人工标注数据的依赖。从而使得模型不使用人工标注数据也能达到很好的效果。
论文题目: MATH-SHEPHERD: VERIFY AND REINFORCE LLMS STEP-BY-STEP WITHOUT HUMAN ANNOTATIONS
论文地址: https://arxiv.org/pdf/2312.08935
论文发表于: arXiv 2024年2月
论文所属单位: DeepSeek
论文大体内容
本文提出了一种面向过程的数学奖励模型Math-Shepherd。它通过自动给解题的每个步骤分配分数,来解决人工标注数据的依赖。从而使得模型不使用人工标注数据也能达到很好的效果。
Motivation
在推理模型的发展过程中,openai发表了一篇论文《let's verify step by step》[1],告诉大家「过程监督」对提升推理模型效果很重要。同时它提供了一个数据集PRM800K,使用人工标注了80万个步骤级的正确性标签,其中每个步骤都被标注了正向、负向、中性的分数,代表这个步骤在解决数学题目上是否有效。但是人工标注的数据很有限,因此本文提供了一种自动化标注的方法,去除人工标注的依赖。
Contribution
①本文提出了一个框架,自动构建步骤监督数据集,无需人工标注即可完成数学推理任务。
②本文做了广泛的验证工作,证明了Math-Shepherd的有效性。
③本文分析了训练奖励模型的关键因素,并阐述了未来的方向。
1. 数学推理是LLM中最有挑战性的任务之一,常用的优化方法有:
①预训练pre-training:直接使用数学问题预训练基座模型;
②SFT:对于基座模型,构建高质量的数学问题进行SFT,关键在于对思维链(CoT)的处理;
③Prompt:提示词,引导模型展示出数学推理能力;
2. 为了提升模型推理能力,常用2种类型的奖励模型去优化,包括:
①ORM(Outcome Reward Model):为整个解决方案分配一个分数;

②PRM(Process Reward Model):为推理过程中的每个步骤分配一个分数;

而最近的研究认为,PRM的效果会比ORM效果好。但是PRM依赖昂贵的人工标注数据集,限制了其进一步的优化。
3. 本文提出一种新的自动化标注框架,通过定义一个步骤能导致最后答案是正确的可能性来衡量步骤的分数。其中分为HE(hard estimation)和SE(soft estimation)共2种方式。PRM的训练是通过上图的交叉熵loss来实现的。
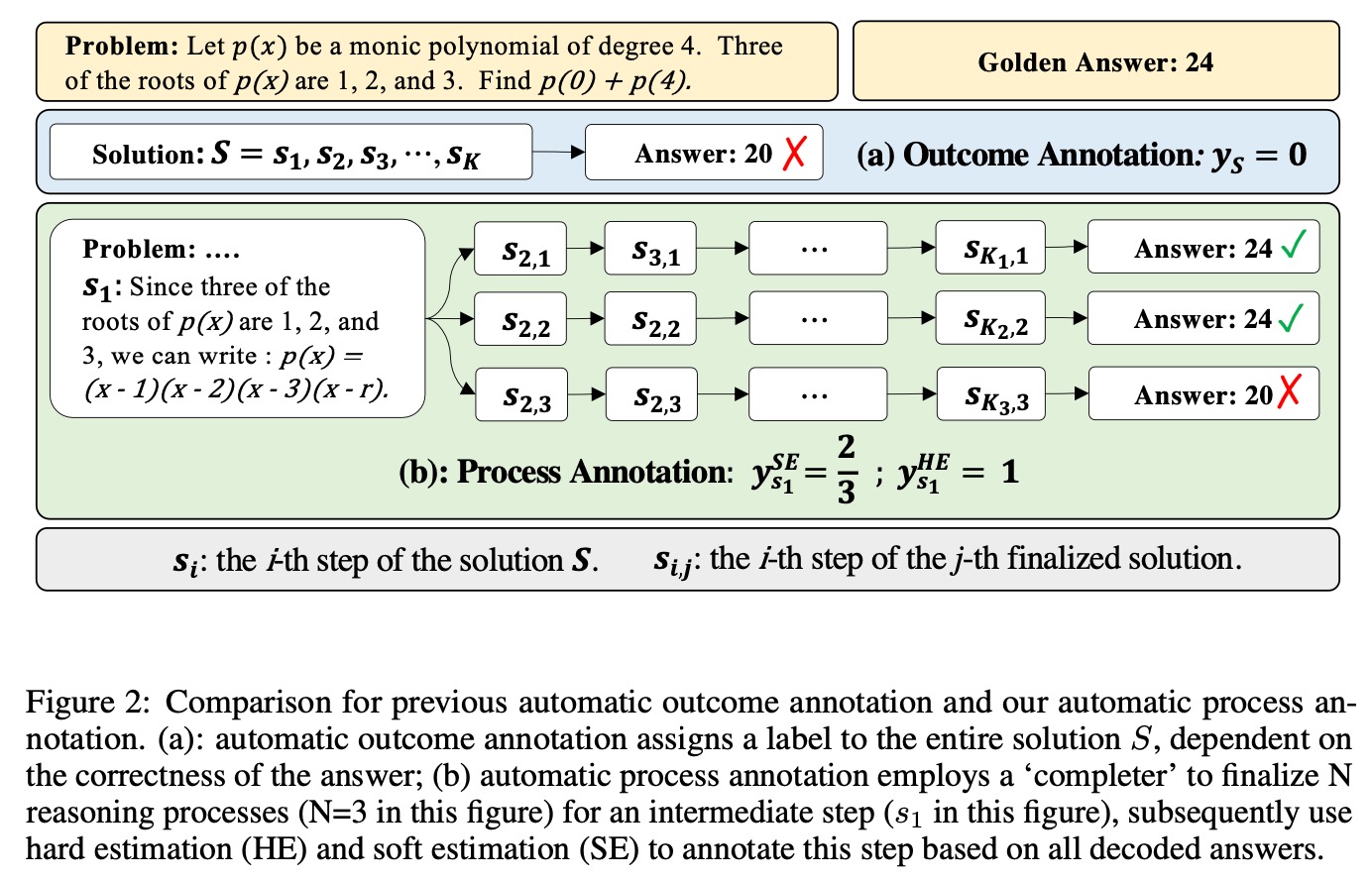

4. 使用上面的PRM方法,本文使用了step-by-step的PPO对大模型进行RL(强化学习),相比ORM仅在每个题目解答最后给出reward,PRM则是对每个步骤给出reward。
5. 评估数据集:评测数学Math的GSM8K、MATH
6. 评测结果
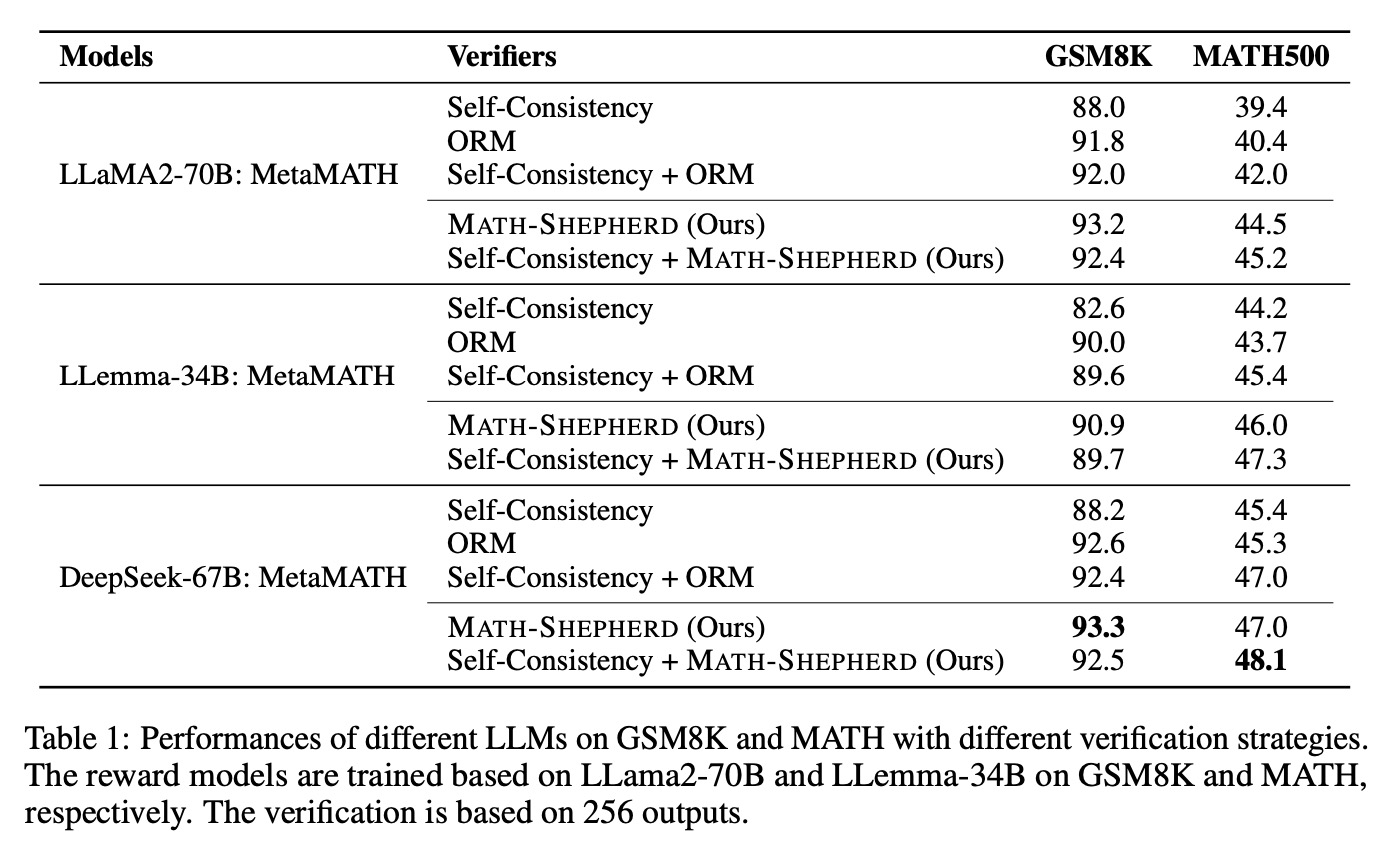
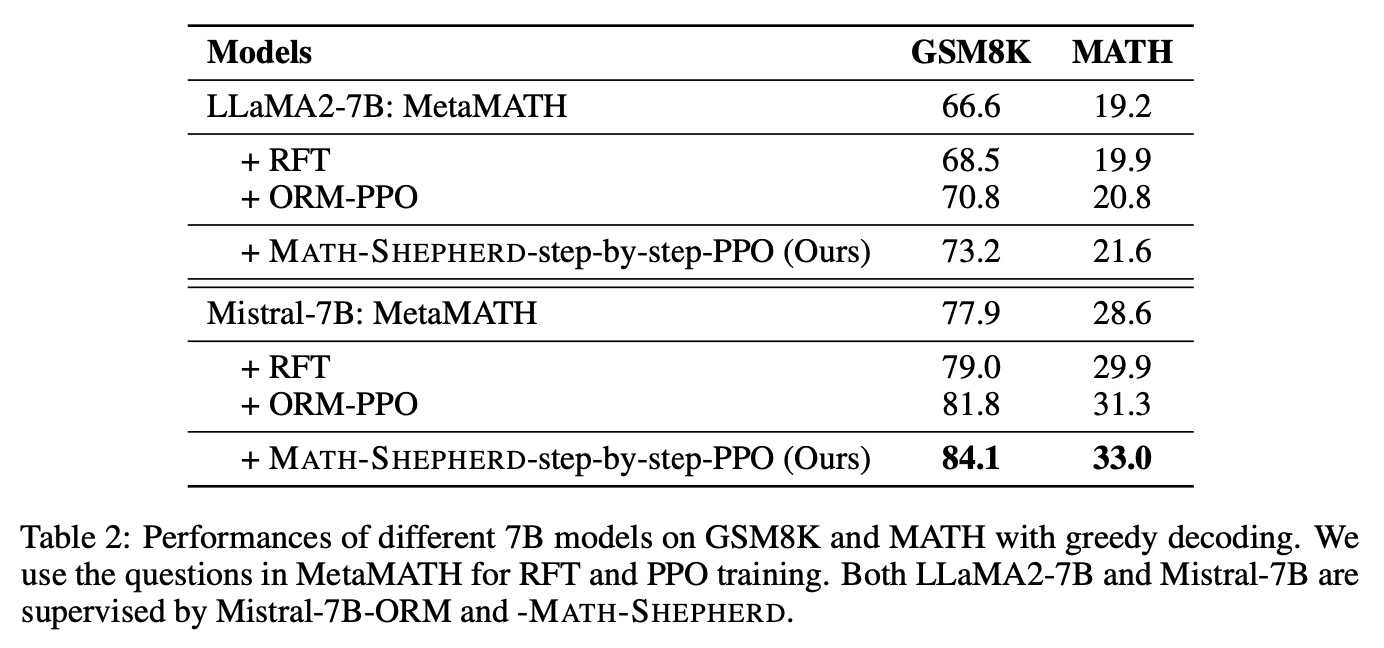

7. 详细消融各个影响因素
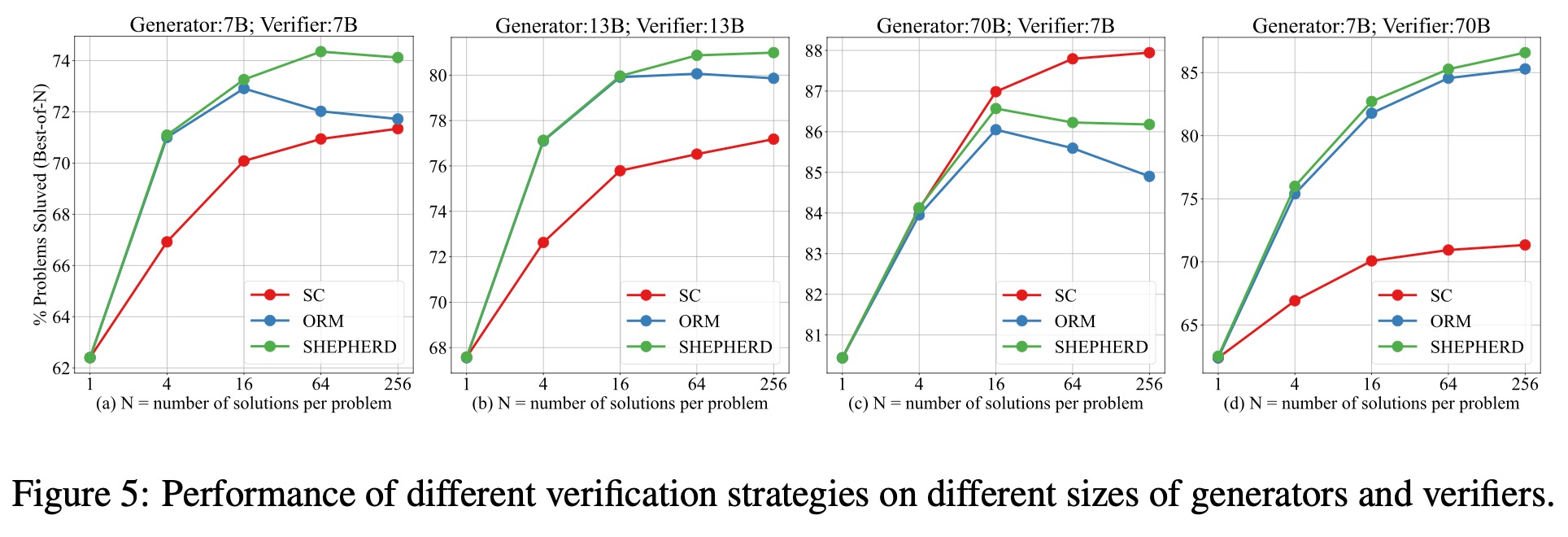
①每个问题的候选答案数量对结果的影响:随着候选答案数量增多,准确率会提升,且Math-Shepherd比人工标注数据集PRM800K好。
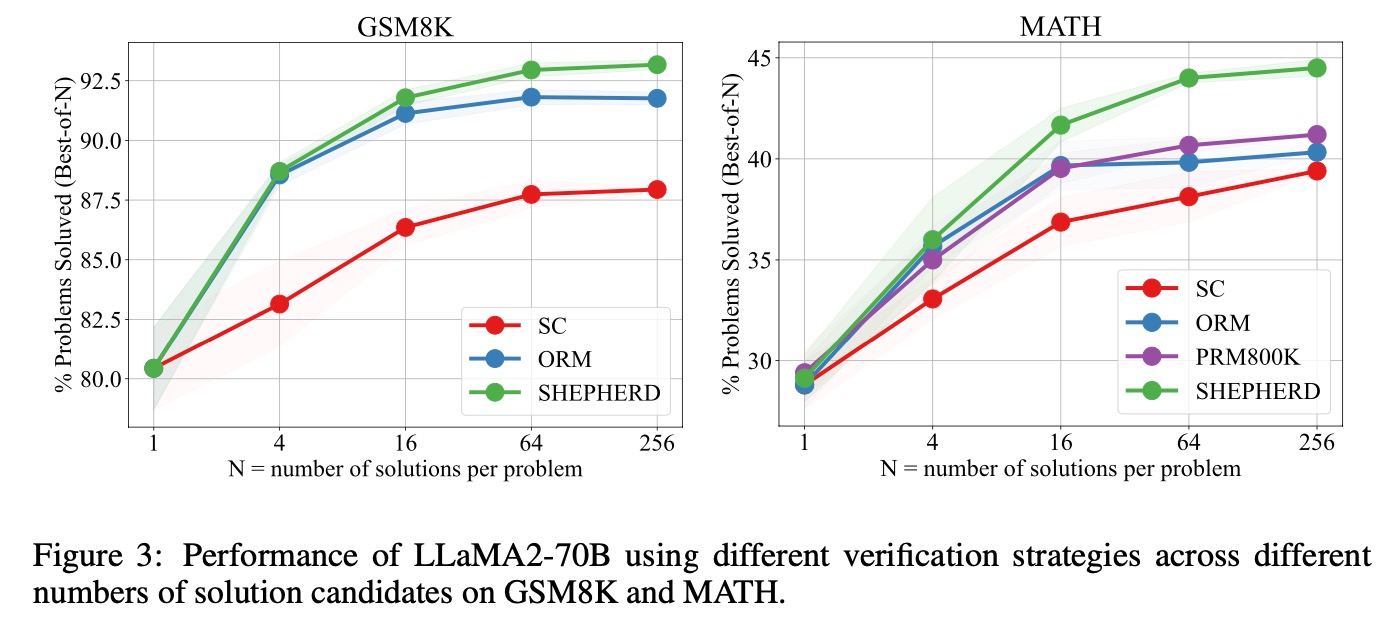
②自动标注的质量与人工标注相比:自动标注质量不错,准确率86%。
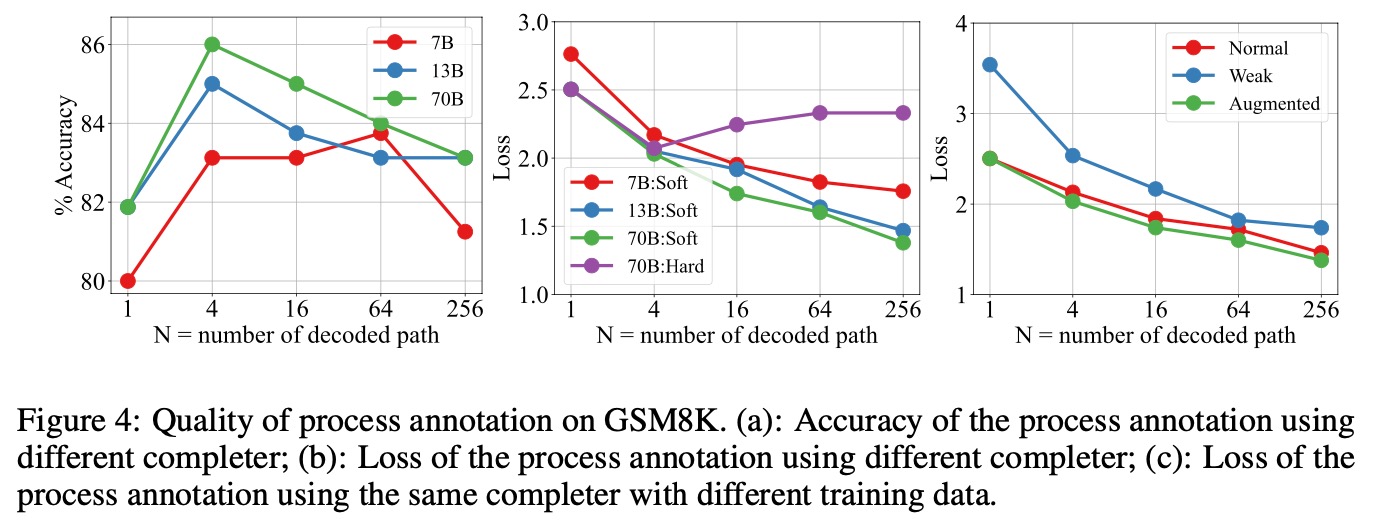
③对不同的基座模型的影响:大模型配小RL,效果会折损。这个代表着部署阶段test time增高(产生更多的候选结果),模型效果更更好。长思维链(O1和R1)也是往这个方向去发展的。
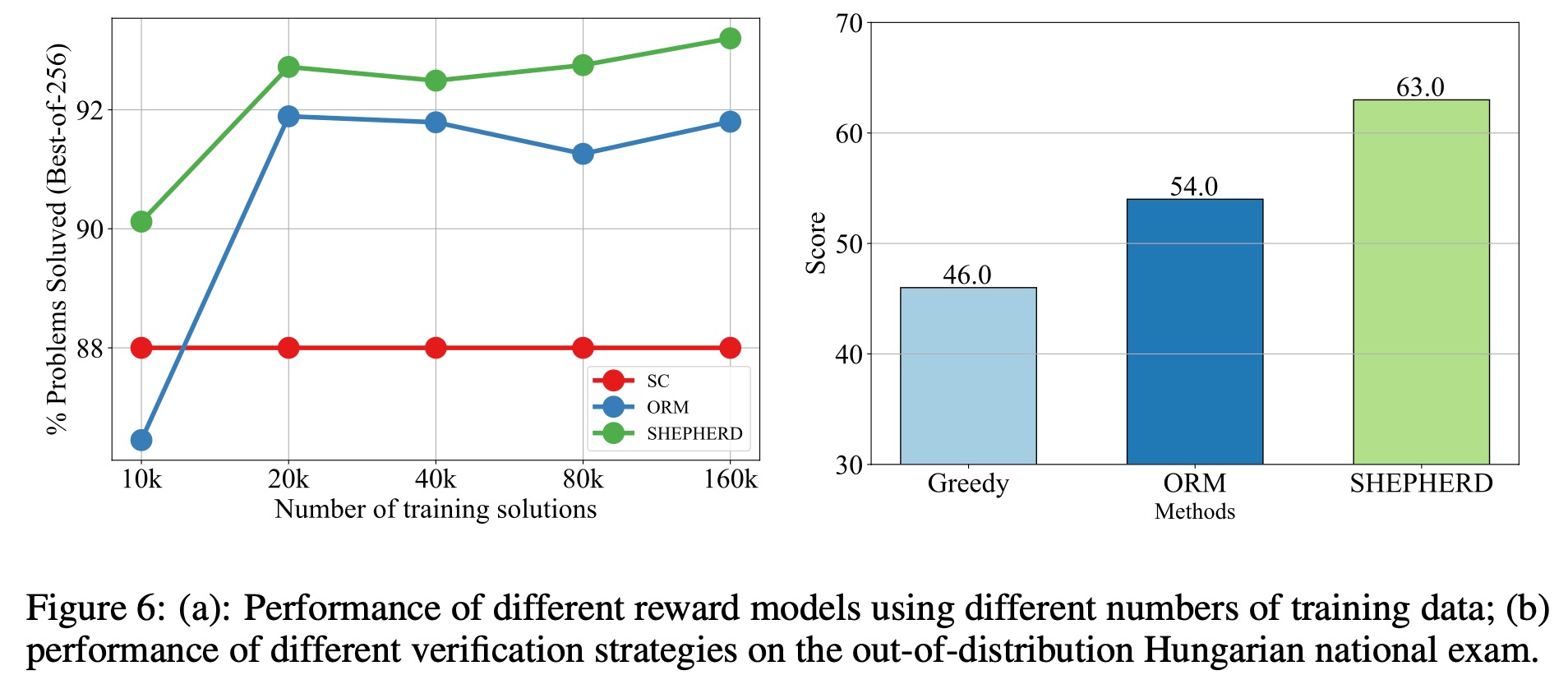
④训练数据量的影响
8. Math-Shepherd的缺点
①自动化标注需要较多的资源,虽然仍然优于人工标注。
②自动化标注存在噪声。
参考资料
[1] let's verify step by step:https://arxiv.org/pdf/2305.20050
[2] 推理能力提升self-consistency(自一致性):https://zhuanlan.zhihu.com/p/641370746
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)