项目实训纪实(三)——DeepSeek云端部署+LoRA微调+FastAPI
一、简介
本期项目实训的核心目标是将LoRA微调技术与大模型相结合,实现在云端的部署,并通过FastAPI框架暴露API接口供Web前端调用。整个过程涵盖了从模型微调到API部署的各个环节,让模型能根据特定需求进行个性化调优,从而满足我们算法测试平台中的不同需求。
1. 需求和技术
随着人工智能技术的不断发展,尤其是在大模型(如GPT、BERT等)应用的广泛普及,企业对于大模型的定制需求也逐渐增多。在这个背景下,微调技术逐步成为了企业优化大模型的一个重要手段。
企业对大模型的个性化需求主要体现在三个方面:SFT(有监督微调)、RLHF(强化学习)、以及RAG(检索增强生成)。这些技术分别通过不同的方式优化模型的能力,以应对特定的任务或应用场景。
1.1 企业对于大模型的不同类型个性化需求
在实际应用中,不同的企业有不同的需求。在大模型的微调过程中,以下三种需求类型尤为重要:
| 需求类型 | 应用场景 | 适用技术 | 描述 |
|---|---|---|---|
| 提高对企业专有信息的理解 | 企业希望模型能够理解并生成基于公司内部信息的内容 | SFT(有监督微调) | 例如,企业想让模型理解公司文化、品牌风格等信息,从而更好地为客户提供支持。例如:蟹堡王的专有知识,如何制作汉堡。 |
| 提供个性化与互动性 | 企业希望根据顾客反馈调整模型生成的回答 | RLHF(强化学习) | 例如,顾客希望模型根据其喜好调整回答的风格,从二次元风格到学术风格。 |
| 获取和生成实时信息 | 企业需要根据实时数据生成答案,例如行业动态等 | RAG(检索增强生成) |
例如,模型需要实时查询公司促销信息、菜单更新等内容,并生成相关答案。 |
每个技术方案根据企业需求的不同进行选择,企业可以根据其目标选择合适的微调策略,最大化利用现有的大模型能力来实现更精准的个性化服务。
1.2 微调技术选择:SFT、RLHF、RAG
选择微调技术时,企业的需求将决定采用哪种方案。以下是对三种常见微调方法的详细描述:
| 技术名称 | 核心目标 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| SFT | 通过人工标注数据进行精细化调整 | 大量企业数据,提升模型对特定领域的理解 | 能显著提高特定任务的性能,效果持久稳定 | 需要大量标注数据和计算资源 |
| RLHF | 通过人类反馈对模型进行强化学习优化 | 需要动态调整模型行为的场景,如定制回答风格 | 适应性强,可以根据用户反馈快速调整模型行为 | 反馈信号的质量直接影响结果,训练过程较慢 |
| RAG | 增强模型的外部信息检索能力 | 数据量少,需要动态更新的领域 | 可以在信息量不足时生成高质量内容,适应实时数据 | 依赖外部检索系统,检索质量直接影响生成效果 |
1.2.1 SFT(有监督微调)
SFT(Supervised Fine-Tuning)是最常见的微调技术之一,通常用于拥有大量标注数据的场景。其基本思路是通过人工标注的数据对预训练模型进行进一步训练,使得模型能够更好地适应特定任务或领域。此方法能显著提升模型在特定领域上的性能,如在法律、医疗或金融领域的应用。
1.2.2 RLHF(强化学习)
RLHF(Reinforcement Learning from Human Feedback)通过人类反馈来优化生成模型的输出。用户通过选择两个生成内容中的一个(对比选择),为模型提供反馈。模型根据这些反馈进行策略调整,使得生成的内容更符合用户需求。RLHF的优势在于其灵活性,能够基于用户的即时反馈进行快速调整,适用于需要持续优化和个性化的场景。
1.2.3 RAG(检索增强生成)
RAG(Retrieval-Augmented Generation)将外部信息的检索与文本生成相结合。模型在生成回答时不仅依赖于其内部知识库,还能够实时从外部数据库或互联网中获取最新的信息。这种方法特别适用于信息量较少或需要动态更新的任务,能够显著提高生成内容的准确性和时效性。
二、整体步骤说明
在本项目中,我们将通过以下几个步骤实现DeepSeek模型的微调、部署和API暴露。下面是整个流程的详细步骤说明。
1. 准备硬件资源和环境
首先,我们需要为训练模型和部署服务准备云服务器。为了顺利进行模型微调,建议选择GPU实例以加速训练过程。在选择实例时,推荐选择具有较强GPU计算能力的机器,比如NVIDIA A100、V100等。
1.1 云平台资源选择
我们选择了AutoDL平台提供的云服务器实例,AutoDL提供了多种适用于深度学习任务的实例配置,支持GPU加速训练。通过该平台,用户可以快速获取云服务器资源,并且平台已经预装了相关的深度学习环境(如CUDA、TensorFlow、PyTorch等),便于模型训练。
-
AutoDL官网:https://www.autodl.com
在云平台上选择合适的实例后,我们可以使用SSH连接到服务器,进行后续的操作。
1.2 连接远程服务器
通过Visual Studio Code(VS Code)的Remote-SSH插件,我们可以远程连接到云服务器,进行文件操作、环境配置和模型训练。VS Code的Remote-SSH插件使得与云服务器的交互变得非常便捷。
连接步骤:
操作部分(Mac环境)
一、环境准备
1.安装VSCode
从官网下载并安装 VSCode.
2.检查 SSH 客户端
Mac 系统自带 OpenSSH 客户端,通过终端执行ssh-v确认是否可用。
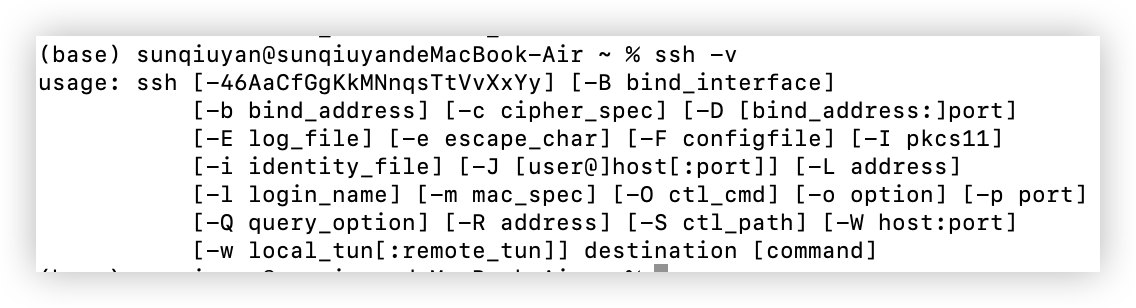
出现以上界面则为成功安装。
brew install openssh若无,可通过 Homebrew 安装
3.远程服务器要求(可以是学校的服务器)
确保服务器已开启 SSH 服务(默认端口 22)
二、安装与配置 Remote-SSH 插件
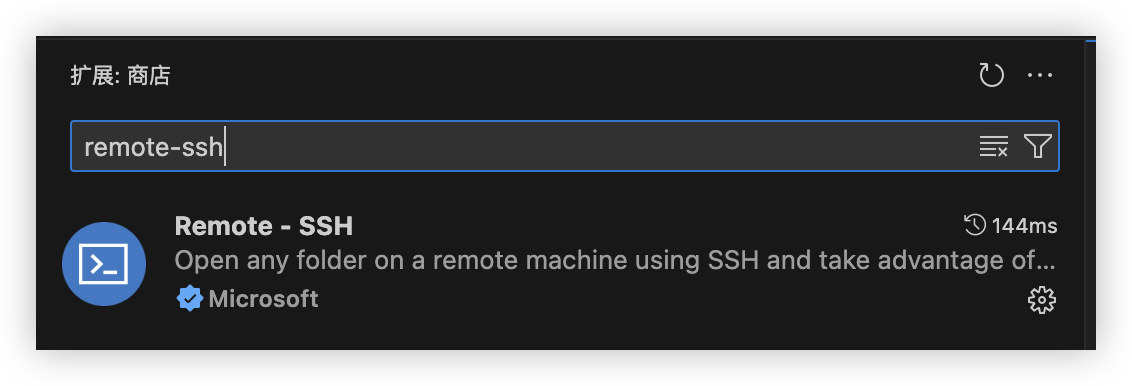
1.安装插件
打开 VSCode,进入扩展市场(Cmd+Shift+X),搜索 Remote - SSH 并安装
2.SSH连接并登录
 点击加号进入连接界面
点击加号进入连接界面
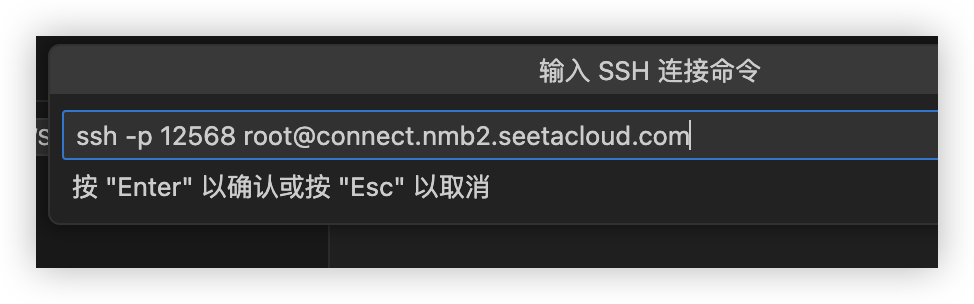
输入服务器地址和密钥进行连接
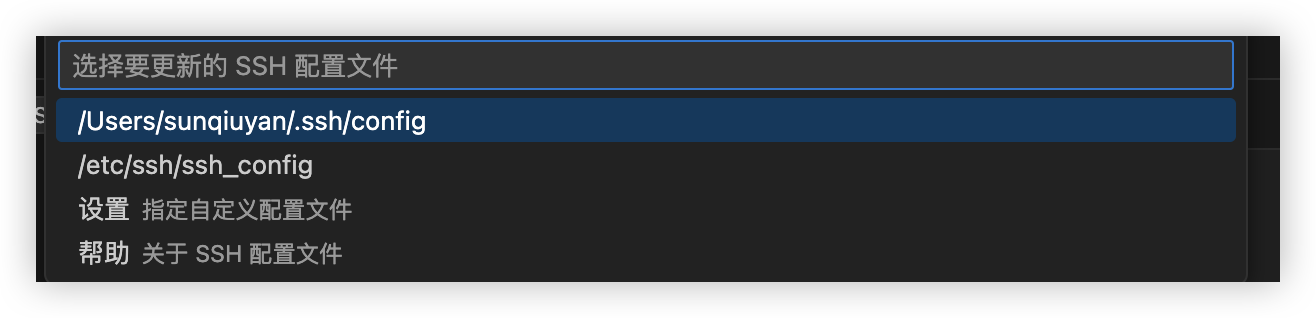
选择默认文件即可
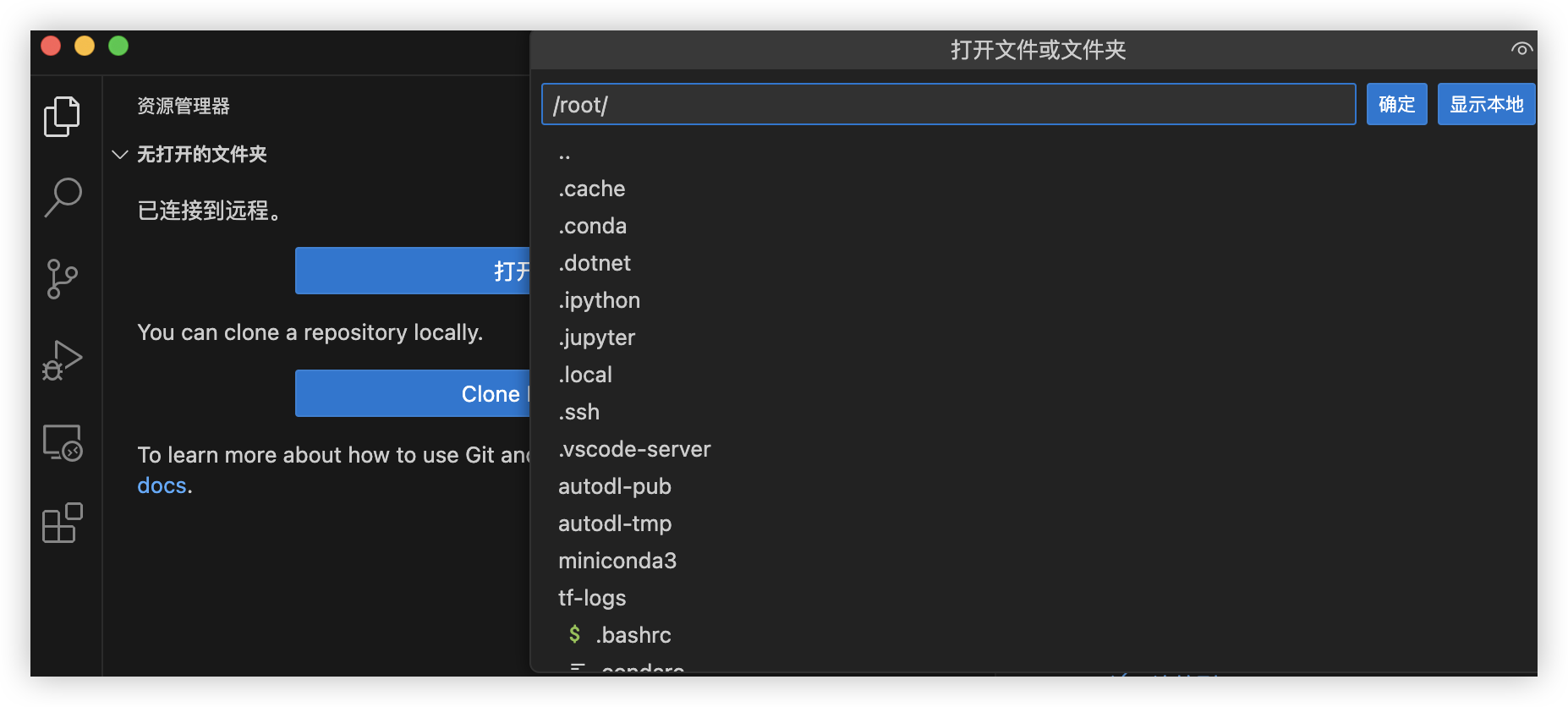
连接成功,可以看到服务器的文件列表
三、使用 SCP 命令拷贝文件
SCP是一种通过 SSH 协议进行文件传输的工具,它可以在本地计算机和远程服务器之间安全地传输文件。在开发过程中,使用 SCP 可以方便地将本地文件上传到远程服务器,或者将远程服务器上的文件下载到本地进行编辑。
1. 基本语法
SCP 的基本语法如下:
-
源路径:指要传输的文件或目录路径。 -
目标路径:指文件传输的目标位置,格式通常是username@hostname:/path。
scp [选项] [源路径] [目标路径]
2. 本地上传到远程服务器
假设你有一个本地文件 file.txt,并且希望将其上传到远程服务器的 /home/username/ 目录下,可以使用以下命令:
scp /path/to/local/file.txt username@remote_server:/home/username/
3. 远程服务器下载到本地
如果你想从远程服务器下载文件到本地,可以使用以下命令:
scp username@remote_server:/path/to/remote/file.txt /path/to/local/
4. 传输整个目录(递归)
若需要上传整个目录(包括子目录和文件),可以使用 -r 选项来递归复制目录:
scp -r /path/to/local/directory username@remote_server:/path/to/remote/
5. 指定 SSH 端口
如果远程服务器的 SSH 服务不使用默认端口(22),你可以通过 -P 选项指定端口号:
scp -P 2222 /path/to/local/file.txt username@remote_server:/path/to/remote/
1.3 环境搭建
在连接到服务器后,首先需要配置环境。我们使用Anaconda来管理Python虚拟环境。确保使用合适的Python版本(如3.10)来避免与LLaMA-Factory框架的兼容性问题。
-
安装Anaconda(如果未安装):
wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh
bash Anaconda3-2022.05-Linux-x86_64.sh-
完成安装后,执行以下命令来配置环境:
conda create -n llama-factory python=3.10
conda activate llama-factory
通过这种方式,我们能够确保在独立的环境中运行LLaMA-Factory,避免与其他库产生冲突。
2. 安装LLaMA-Factory框架
LLaMA-Factory是一个低代码大模型训练框架,它提供了简洁的API和可视化界面,适合初学者进行模型微调。LLaMA-Factory框架支持多种预训练模型的微调,包括但不限于DeepSeek-R1模型。
2.1 克隆LLaMA-Factory仓库
首先,我们需要将LLaMA-Factory的源代码克隆到云服务器上。
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git2.2 安装依赖
进入项目目录并安装所需的依赖:
cd LLaMA-Factory pip install -e ".[torch,metrics]"2.3 配置环境
LLaMA-Factory支持将conda虚拟环境配置到数据盘中,以便更好地管理资源。使用以下命令来配置虚拟环境:
mkdir -p /root/autodl-tmp/conda/pkgs conda config --add pkgs_dirs /root/autodl-tmp/conda/pkgs mkdir -p /root/autodl-tmp/conda/envs conda config --add envs_dirs /root/autodl-tmp/conda/envs然后,创建一个新的虚拟环境,并激活它:
conda create -n llama-factory python=3.10 conda activate llama-factory确保虚拟环境已成功激活后,我们可以继续进行框架的安装。
3. 下载并准备基座模型
为了进行微调,我们需要下载适用于训练的预训练模型。在这里,我们使用DeepSeek-R1-Distill-Qwen-1.5B模型,作为基座模型进行LoRA微调。
3.1 配置HuggingFace镜像源
为提高下载速度,我们可以通过配置HuggingFace镜像源来加速模型下载。
export HF_ENDPOINT=https://hf-mirror.com export HF_HOME=/root/autodl-tmp/Hugging-Face3.2 下载DeepSeek-R1模型
使用HuggingFace的官方命令行工具下载模型:
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B下载完成后,模型将存放在指定的目录中。
4. 配置训练数据集
为了进行LoRA微调,我们需要准备好用于训练的数据集。LLaMA-Factory支持JSON格式的训练数据集,数据集应该包含指令(instruction)、输入(input)和输出(output)。
4.1 数据集格式
以下是一个数据集样例,名为leetcode.json:
[ { "instruction": "请问你是谁", "input": "", "output": "您好,我是DeepSeek大语言模型,很高兴为您服务!" }, { "instruction": "怎么修复这个报错", "input": "我正在使用C++语言", "output": "根据您提供的错误信息,可能是因为系统没有加载正确的文件。您可以尝试以下步骤:\n1. 检查文件是否存在,并确保文件路径正确。\n2. 重新加载或文件。" } ]4.2 配置数据集
接下来,我们需要将数据集文件放置在LLaMA-Factory框架的data目录下,并在配置文件中添加数据集信息。
"leetcode": { "file_name": "leetcode.json" }5. 开始LoRA微调
通过LLaMA-Factory的可视化界面或命令行工具,我们可以开始LoRA微调。具体步骤如下:
5.1 配置训练参数
在LLaMA-Factory界面中,选择LoRA算法并添加我们的数据集。在设置训练参数时,常见的设置包括:
-
学习率(Learning Rate):决定模型每次更新时权重改变的幅度。
-
训练轮数(Epochs):训练过程中需要遍历数据的次数。
-
最大梯度范数(Max Gradient Norm):防止梯度爆炸。
-
截断长度(Truncation Length):长文本的处理长度限制。
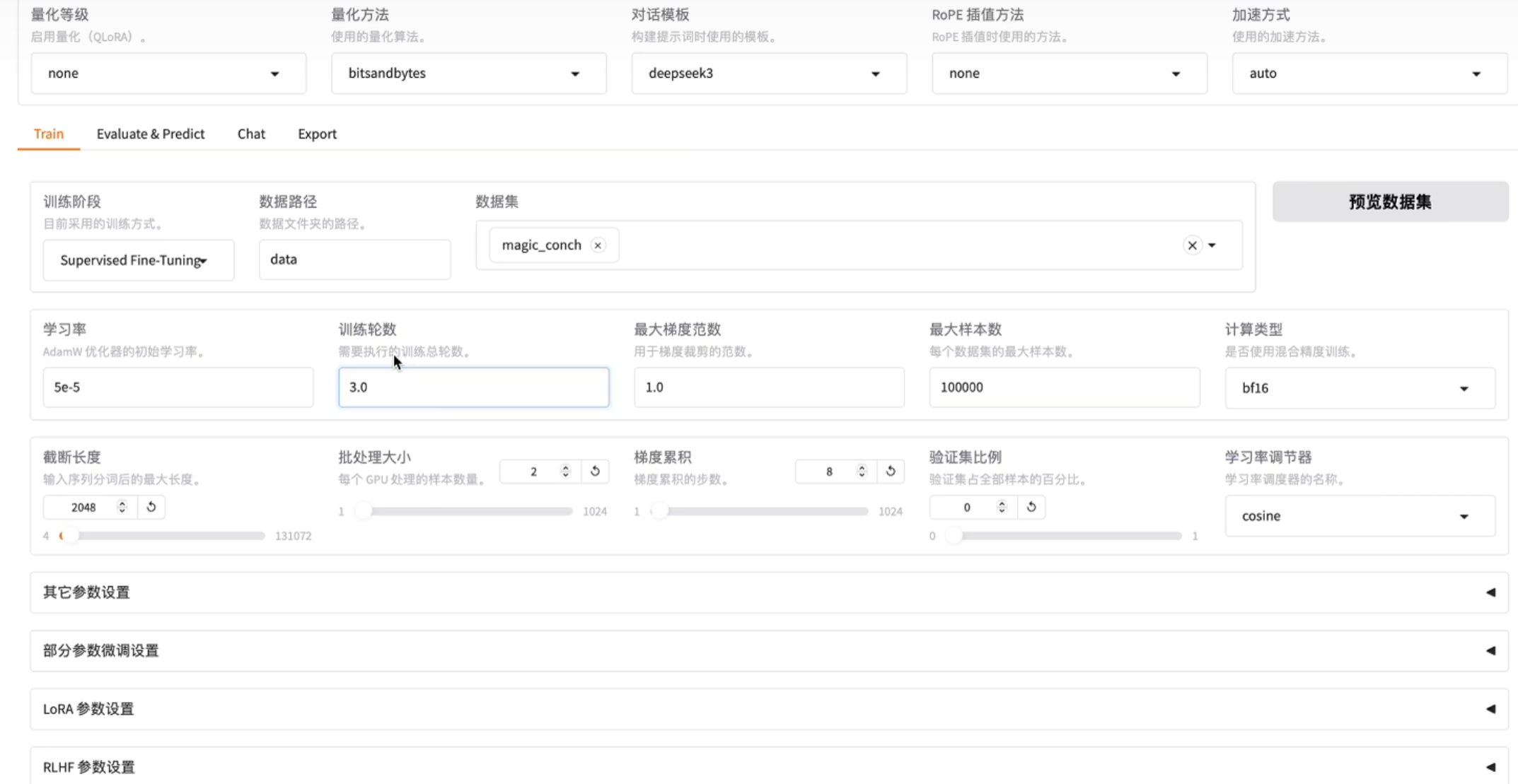
5.2 启动训练
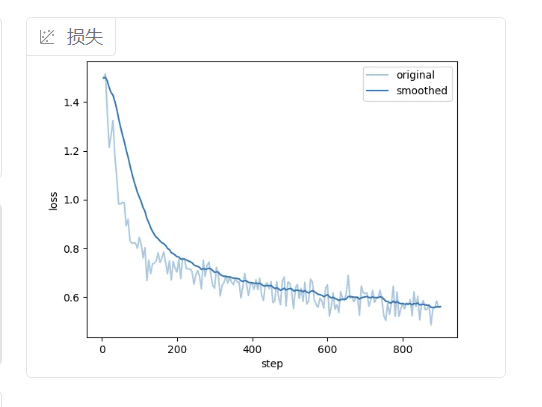
在配置好训练参数后,可以点击界面上的“启动训练”按钮,loss正常下降,训练成功。
五、模型部署和暴露接口
在完成LoRA微调后,下一步是将训练好的模型进行部署,并通过FastAPI框架暴露HTTP接口,以便Web后端能够调用模型进行推理。以下是详细的部署步骤。
1. 创建新的 Conda 虚拟环境用于部署模型
为了确保环境清洁并与微调环境隔离,我们为FastAPI部署创建了一个新的Conda虚拟环境。
1.1 创建环境
首先,使用以下命令创建一个新的虚拟环境,并激活该环境:
conda create -n fastApi python=3.10 conda activate fastApi1.2 安装部署所需依赖
在这个虚拟环境中,我们需要安装FastAPI、Uvicorn以及一些其他必要的依赖,如transformers和pytorch。
conda install -c conda-forge fastapi uvicorn transformers pytorch同时安装额外的依赖,确保模型可以正常加载:
pip install safetensors sentencepiece protobuf2. 通过 FastAPI 部署模型并暴露 HTTP 接口
FastAPI是一个轻量级的Web框架,可以快速地搭建API接口。我们将使用FastAPI来构建一个简单的Web服务,并通过该服务暴露模型的推理接口。
2.1 创建 App 文件夹
首先,创建一个名为App的文件夹用于存放FastAPI应用的代码:
mkdir App cd App2.2 创建 main.py 文件
在App文件夹内,创建一个名为main.py的文件,这是FastAPI应用的入口:
touch main.py2.3 编写 main.py 文件
在main.py文件中,我们将加载训练好的模型,并创建一个简单的接口供前端调用。以下是main.py的代码:
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 创建 FastAPI 实例
app = FastAPI()
# 模型路径
model_path = "/root/autodl-tmp/Models/deepseek-r1-1.5b-merged"
# 加载 tokenizer (分词器)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型并移动到可用设备(GPU/CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(model_path).to(device)
@app.get("/generate")
async def generate_text(prompt: str):
# 使用 tokenizer 编码输入的 prompt
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 使用模型生成文本
outputs = model.generate(inputs["input_ids"], max_length=150)
# 解码生成的输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"generated_text": generated_text}2.4 启动 FastAPI 应用
我们使用Uvicorn来运行FastAPI应用。以下命令将在本地启动FastAPI服务器:
uvicorn main:app --reload --host 0.0.0.0-
main是 Python 文件名(不带.py扩展名)。 -
app是 FastAPI 实例的变量名。 -
--reload开启开发模式,代码修改后自动重载。 -
--host 0.0.0.0使应用绑定到所有网络接口,可以通过内网穿透访问该服务。
3. 配置端口转发
为了使本地机器能够访问云服务器上的服务,我们需要配置端口转发。通过SSH隧道将云服务器的端口映射到本地机器:
ssh -CNg -L 7860:127.0.0.1:7860 root@123.125.240.150 -p 42151在本地机器上访问http://localhost:7860即可访问云端的FastAPI服务。
4. 测试服务是否启动成功
通过浏览器输入以下URL,测试FastAPI服务是否启动成功:
http://localhost:8000/docs这将自动生成FastAPI提供的Swagger UI界面,可以通过这个界面手动测试API接口。你也可以通过Postman来测试接口,使用以下URL:
http://localhost:8000/generate?prompt=你是谁?六、Web后端调用
在本部分中,我们将详细介绍如何通过后端代码调用FastAPI提供的HTTP接口,特别是在Java项目中如何发送HTTP请求并处理模型生成的文本。
1. 导入依赖
为了发送HTTP请求,我们需要使用Apache HttpClient库。以下是如何在Java项目中导入相关依赖的步骤。
1.1 在 pom.xml 中添加依赖
在你的Java项目的pom.xml文件中,添加以下依赖来引入httpclient5:
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.2.1</version>
</dependency>2. 自定义方法发送并处理 HTTP 请求
接下来,我们将创建一个服务类,在该类中通过发送HTTP请求来与FastAPI后端进行交互,并获取生成的文本。
2.1 创建服务类
以下是Java中调用FastAPI接口的服务类示例:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Service
public class ChatServiceImpl implements ChatService {
@Autowired
private RestTemplate restTemplate;
@Autowired
private AiServiceConfig aiServiceConfig;
@Override
public String callAiForOneReply(String prompt) {
// 获取基础URL http://localhost:8000
String baseUrl = aiServiceConfig.getBaseUrl();
// 构建完整的请求URL http://localhost:8000/generate?prompt=XXX
String url = String.format("%s/generate?prompt=%s", baseUrl, prompt);
// 发送GET请求并获取响应
GenerateResponse response = restTemplate.getForObject(url, GenerateResponse.class);
// 从响应中取出 generated_text 字段值返回
return response != null ? response.getGenerated_text() : "";
}
}
2.2 说明
-
restTemplate.getForObject(url, GenerateResponse.class):发送GET请求到FastAPI的/generate接口,并获取返回的文本数据。 -
GenerateResponse类:用来接收FastAPI返回的JSON数据,包括生成的文本内容。
七、总结
通过本项目,我们成功实现了DeepSeek模型的LoRA微调并通过FastAPI进行部署。项目中,我们使用LoRA算法有效地减少了计算资源消耗,部署后的FastAPI服务支持高并发请求,前端能够实时获取并展示生成的文本。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 42
42 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)