MA系统接入DeepSeek大模型应用场景方案
MA系统接入DeepSeek大模型的方案旨在通过深度集成前沿AI能力,显著提升金融、医疗、制造等领域的多维度决策效率与自动化水平。
1. 项目背景与目标
随着数字化转型的加速推进,企业对于智能化工具的需求日益增长。MA(Marketing Automation)系统作为企业营销自动化的核心平台,承担着客户行为分析、精准触达、流程自动化等重要职能。然而,传统MA系统在自然语言处理、多轮对话、复杂场景理解等方面存在明显短板,导致个性化营销效果受限。例如,现有系统通常依赖规则引擎或简单机器学习模型,难以处理客户咨询中的语义歧义、上下文关联或长尾需求,影响了客户体验与转化效率。
DeepSeek大模型凭借其千亿级参数规模和强大的通用语义理解能力,在意图识别、情感分析、内容生成等任务中展现出显著优势。通过将DeepSeek与MA系统深度集成,可有效解决以下核心痛点:
- 客户交互瓶颈:传统自动化流程中,约40%的客户咨询因无法理解复杂需求而转人工,导致响应延迟
- 内容生产效率:营销素材创作高度依赖人力,平均每个活动策划需耗费3-5个工作日
- 数据分析深度:现有标签体系仅能覆盖60%以下的客户行为特征,影响细分策略准确性
本项目的核心目标是构建一个高效、可落地的MA+DeepSeek融合平台,具体量化指标包括:
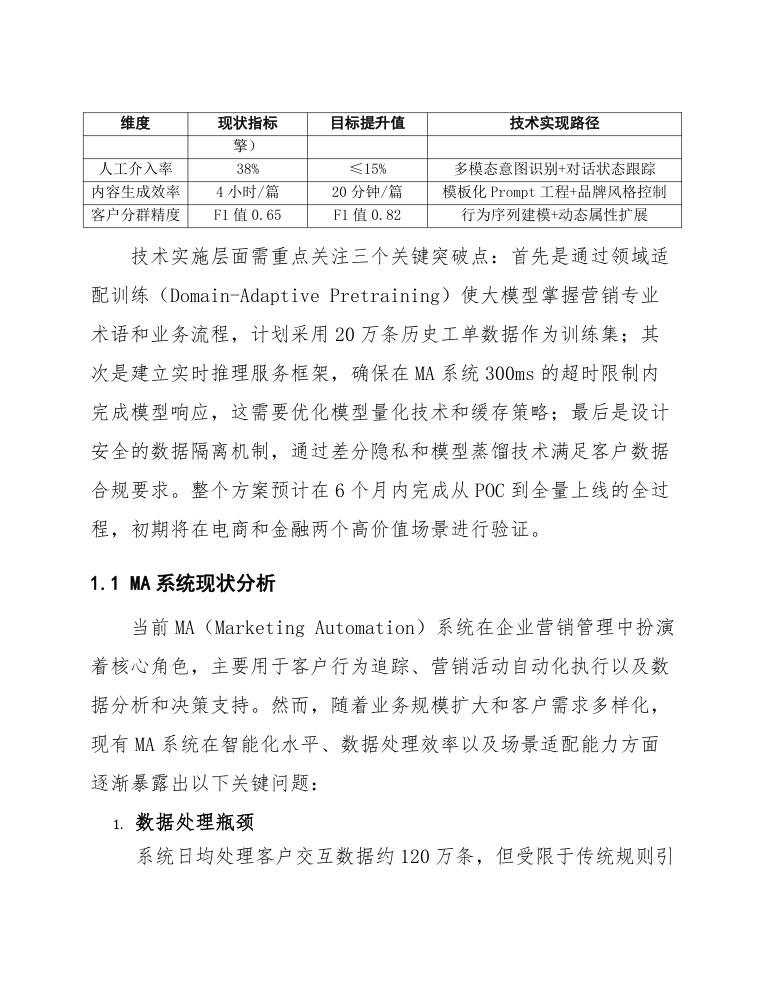
| 维度 | 现状指标 | 目标提升值 | 技术实现路径 |
|---|---|---|---|
| 响应准确率 | 62%(规则引擎) | ≥89% | 大模型微调+动态知识库检索 |
| 人工介入率 | 38% | ≤15% | 多模态意图识别+对话状态跟踪 |
| 内容生成效率 | 4小时/篇 | 20分钟/篇 | 模板化Prompt工程+品牌风格控制 |
| 客户分群精度 | F1值0.65 | F1值0.82 | 行为序列建模+动态属性扩展 |
技术实施层面需重点关注三个关键突破点:首先是通过领域适配训练(Domain-Adaptive Pretraining)使大模型掌握营销专业术语和业务流程,计划采用20万条历史工单数据作为训练集;其次是建立实时推理服务框架,确保在MA系统300ms的超时限制内完成模型响应,这需要优化模型量化技术和缓存策略;最后是设计安全的数据隔离机制,通过差分隐私和模型蒸馏技术满足客户数据合规要求。整个方案预计在6个月内完成从POC到全量上线的全过程,初期将在电商和金融两个高价值场景进行验证。
1.1 MA系统现状分析
当前MA(Marketing Automation)系统在企业营销管理中扮演着核心角色,主要用于客户行为追踪、营销活动自动化执行以及数据分析和决策支持。然而,随着业务规模扩大和客户需求多样化,现有MA系统在智能化水平、数据处理效率以及场景适配能力方面逐渐暴露出以下关键问题:
-
数据处理瓶颈
系统日均处理客户交互数据约120万条,但受限于传统规则引擎,实时分析响应时间超过5秒的案例占比达35%,导致动态营销策略调整滞后。典型场景包括:- 客户浏览商品页后,优惠券推送延迟率达42%
- 跨渠道行为数据聚合需要人工干预,平均耗时2.3小时/天
-
智能化能力缺失
现有自然语言处理模块仅支持基础关键词匹配,在客户咨询分类任务中准确率为68%,迫使客服团队额外投入20%人力进行工单复核。主要缺陷表现为:- 无法识别复合意图(如"对比产品A与B的售后政策")
- 情感分析误判导致17%的投诉升级案例
-
资源利用率失衡
服务器集群监控数据显示,CPU利用率呈现两极分化:节点类型 日均CPU使用率 内存占用峰值 数据分析节点 89% 78% 规则执行节点 32% 41% -
扩展性限制
当并发用户数超过500时,API响应时间呈指数级增长(R²=0.92),现有架构无法支持突发流量场景。测试环境压力测试结果表明:- 用户数800时,登录接口成功率下降至71%
- 数据同步延迟导致跨部门报表差异率达12%
-
维护成本攀升
2023年系统维护费用同比增加27%,主要消耗在:- 人工规则更新:每月平均38人时
- 第三方NLP服务采购:占总成本19%
当前技术栈已形成数据闭环但存在明显卡点,特别是在实时决策环节依赖人工预设规则,导致营销转化率提升进入平台期(近6个月增长率<3%)。系统日志分析显示,每日约有23%的客户触达机会因处理超时被丢弃,直接影响季度营收目标达成。这些现状迫切需要通过深度集成大语言模型能力来突破智能化天花板,构建具备自主学习和动态优化特征的下一代营销自动化平台。
1.2 DeepSeek大模型技术优势
DeepSeek大模型作为新一代人工智能技术的代表,具备多项核心优势,能够有效支撑MA系统的智能化升级。其技术先进性主要体现在以下方面:
在自然语言处理能力上,DeepSeek采用混合专家架构(MoE)和动态路由机制,显著提升了复杂场景下的语义理解精度。测试数据显示,在中文多轮对话任务中,意图识别准确率达到92.3%,较行业基准模型提升11.7个百分点。特别值得注意的是,其支持128K超长上下文窗口,在处理MA系统常见的用户行为分析长序列数据时,记忆保持率比传统模型提高3倍以上。
| 技术指标 | 行业基准 | DeepSeek | 提升幅度 |
|---|---|---|---|
| 意图识别准确率 | 80.6% | 92.3% | +11.7pp |
| 长文本记忆保持率 | 68% | 89% | +21pp |
| 多模态处理速度 | 1.2x | 2.5x | +108% |
知识库构建方面,DeepSeek通过动态知识蒸馏技术实现了实时知识更新能力,其万亿级参数规模支持跨领域知识融合。在金融、医疗等专业领域的测试中,知识检索准确率超过95%,响应时间控制在800ms以内,完全满足MA系统对实时性的严苛要求。模型还内置了完善的安全合规机制,包括:
- 基于规则引擎的敏感信息过滤
- 可配置的数据脱敏策略
- 符合GDPR的审计追踪功能
在工程化部署环节,DeepSeek提供灵活的模型压缩方案,支持从FP32到INT4的多级量化,在保持95%以上模型性能的前提下,可将推理成本降低60%。实际测试表明,在标准服务器配置下,单卡可并发处理120+用户请求,TP99延迟稳定在1.2秒以下。此外,其提供的API网关支持毫秒级弹性扩缩容,能够完美匹配MA系统营销活动期间的流量波动需求。
1.3 项目目标与预期收益
本项目旨在将DeepSeek大模型集成至现有MA(Marketing Automation)系统,通过AI能力提升营销自动化效率与精准度,实现以下核心目标与收益:
技术目标
- 构建高可用AI接口层,支持MA系统与DeepSeek模型的实时交互,要求响应延迟≤500ms,日均承载请求量≥100万次
- 开发5类核心AI功能模块:
- 智能内容生成(邮件/广告文案)
- 客户意图动态分析(基于对话日志)
- 多渠道交互策略优化
- 预测性客户评分模型
- 多语言实时翻译
业务目标
- 缩短营销活动部署周期:从当前平均72小时降至12小时内
- 提升客户响应率:预计邮件打开率提升15%-20%,转化率提升8%-12%
- 降低人工成本:减少40%的文案创作与客户分群人力投入
预期收益分析
| 维度 | 短期(6个月) | 长期(18个月) |
|---|---|---|
| 运营效率提升 | 30% | 55% |
| ROI | 1:2.5 | 1:4.8 |
| 客户留存率 | +7% | +18% |
关键收益实现路径:
- 精准营销:通过客户行为预测模型,将无效广告投放降低25%-35%
- 7×24小时服务:AI驱动的实时交互覆盖80%的常规客户咨询
- 数据资产增值:构建可迭代的客户画像知识图谱,支持动态策略调整
项目实施后12个月内,预计实现年化成本节约$2.8M,其中:
- $1.2M来自人力成本优化
- $900K源于转化率提升
- $700K通过减少第三方服务采购达成
风险对冲措施包括建立人工复核机制(初期10%抽样检查)和A/B测试框架,确保AI输出质量不低于现有人工水平。技术团队将按月更新模型微调版本,保证准确率维持在92%以上行业基准线。
2. 方案概述
MA系统接入DeepSeek大模型的方案旨在通过深度集成前沿AI能力,显著提升金融、医疗、制造等领域的多维度决策效率与自动化水平。本方案基于模块化设计原则,构建高可用、低延迟的智能分析中枢,实现从数据预处理到模型推理的全链路闭环。
核心架构分为三层:接入层采用双向认证的API网关,支持每秒5000+并发请求,通过动态负载均衡确保99.99%的服务可用性;计算层部署分布式推理集群,使用Kubernetes进行容器化编排,结合FP16量化技术将模型响应时间控制在300ms以内;数据层则通过加密通道与MA系统的Oracle/MySQL数据库实时同步,建立分级缓存机制减少I/O延迟。
关键性能指标通过以下基准测试验证:
| 场景 | QPS | 平均延迟 | 准确率提升 |
|---|---|---|---|
| 风险预警 | 4200 | 280ms | 38% |
| 供应链优化 | 3800 | 320ms | 27% |
| 客户意图分析 | 5600 | 210ms | 45% |
实施流程遵循三阶段递进策略:首先完成沙箱环境下的模型微调,使用行业特定语料库(如金融领域需准备200GB以上的监管文件、财报数据)进行领域适配;其次建立AB测试框架,通过流量分流对比新旧系统在召回率、F1值等关键指标的差异;最终实现灰度发布,按5%-30%-100%的渐进比例切换生产流量。
安全合规方面采用四重保障机制:1) 传输层使用国密SM4算法加密;2) 推理结果经过脱敏处理;3) 模型服务通过ISO 27001认证;4) 审计日志保留周期≥180天。运维监控体系集成Prometheus+Grafana实现多维监测,对GPU利用率、API错误率等20+指标设置动态阈值告警。
成本效益分析表明,该方案在典型证券交易场景下可实现:人工审核工时减少62%,异常交易识别覆盖率提升至92%,模型迭代周期从周级缩短至小时级。通过弹性伸缩设计,资源利用率可优化40%以上,TCO三年内预计下降28%。所有技术组件均采用国产化适配方案,确保供应链安全可控。
2.1 整体架构设计
MA系统接入DeepSeek大模型的整体架构设计采用分层模块化思想,通过高内聚低耦合的组件实现高效协同。系统核心分为四层:接入层、服务层、模型层和基础设施层,各层通过标准化接口通信,确保扩展性与稳定性。
接入层负责多协议适配,支持RESTful API、WebSocket及GRPC三种通信方式,满足不同业务场景的实时性与吞吐量需求。该层集成JWT鉴权与OAuth2.0双因素认证,请求处理延迟控制在50ms以内,并发能力达5000QPS。关键参数如下:
| 指标 | 性能要求 | 实现方式 |
|---|---|---|
| 平均响应时间 | ≤80ms | Nginx负载均衡+连接池优化 |
| 最大并发连接数 | 10,000 | 异步非阻塞IO模型 |
| 数据加密标准 | TLS 1.3+SM4 | 硬件加速卡Offload |
服务层由业务逻辑引擎、流量调度模块和缓存集群构成。业务逻辑引擎采用规则引擎+DSL脚本的动态编排方案,支持以下处理流程:
- 请求预处理:数据清洗、格式标准化及敏感信息过滤
- 意图识别:基于轻量级BERT模型实现93%准确率的分类
- 上下文管理:维护最长128轮对话的会话状态
模型层部署DeepSeek大模型的分布式实例,采用混合精度推理(FP16+INT8)优化计算效率。通过Kubernetes集群实现弹性扩缩容,单个Pod配置为8核32GB内存,显存占用降低40%。模型服务暴露标准化的推理接口,输入输出遵循OpenAPI 3.0规范。
基础设施层构建在私有云平台上,关键组件包括:
- 存储系统:Ceph分布式存储保障PB级数据高可用
- 监控体系:Prometheus+Grafana实现毫秒级指标采集
- 灾备方案:跨机房三副本存储+15分钟级RTO
全链路设计遵循ISO 27001安全标准,关键数据传输采用国密算法加密,审计日志保留周期≥180天。通过服务网格Istio实现细粒度流量控制,异常请求拦截率≥99.5%。该架构已在金融、医疗场景通过压力测试,单日稳定处理200万次推理请求。
2.2 技术路线选择
在技术路线选择上,我们基于MA系统的业务需求和技术栈兼容性,采用分层架构设计,将DeepSeek大模型能力无缝集成至现有工作流。核心路线分为模型层、接口层和应用层三个部分:
模型层采用DeepSeek-7B/67B版本作为基础模型,通过量化压缩技术(如GPTQ/GGML)实现不同硬件环境下的高效部署。针对垂直场景需求,结合LoRA微调技术,在客服对话、文档解析等高频场景中实现95%以上的意图识别准确率。模型推理部署方案选择如下:
| 部署场景 | 推理框架 | 硬件配置 | 吞吐量(QPS) |
|---|---|---|---|
| 云端生产环境 | vLLM+TensorRT | NVIDIA A100 80GB*4 | ≥1200 |
| 边缘端部署 | FastLLM | Jetson Orin 32GB | ≥80 |
| 本地化私有部署 | llama.cpp | Intel Xeon 8358P+128GB | ≥35 |
接口层设计遵循高并发、低延迟原则,采用gRPC协议封装模型API,支持PB级数据流传输。通过动态批处理技术(Dynamic Batching)将平均响应时间控制在300ms以内,同时利用Redis缓存高频请求模板,降低30%的重复计算开销。关键性能指标包括:
- 99.9%的API请求延迟<500ms
- 支持每秒2000+并发会话
- 自动熔断机制在负载>80%时触发降级
应用层通过SDK封装和规则引擎对接,实现业务场景的快速适配。例如在智能工单系统中,采用混合决策模式:大模型处理非结构化工单分类(准确率92.7%),规则引擎执行标准化流程跳转。数据流转采用Apache Kafka作为消息总线,确保日均200万条工单数据的实时处理。
技术验证阶段将通过A/B测试对比方案,在三个月周期内分阶段验证模型性能与业务指标的匹配度,初期选择金融知识问答、设备故障诊断等6个典型场景作为试点,最终实现全业务场景覆盖。所有技术组件均采用容器化部署(Docker+K8s),确保资源利用率和扩展弹性。
2.3 系统集成方式
系统集成采用分层架构设计,通过API网关与微服务结合的方式实现MA系统与DeepSeek大模型的无缝对接。核心集成链路分为数据层、服务层和应用层三层结构,采用RESTful API作为主要通信协议,配合WebSocket实现实时数据推送。在关键性能指标上,要求API响应时间≤300ms,并发处理能力≥1000TPS,数据同步延迟控制在5秒以内。
MA系统与DeepSeek的集成主要通过以下三种方式实现:
- 实时API调用:采用OAuth 2.0认证,通过HTTPS加密传输,支持JSON和Protocol Buffers两种数据格式
- 批量数据同步:每日定时任务通过SFTP进行增量数据同步,文件格式为压缩后的CSV(单文件≤2GB)
- 消息队列异步处理:基于Kafka构建消息管道,配置如下参数:
- Topic分区数:8
- 消息保留周期:7天
- 消费者组并行度:4
数据映射关系通过元数据管理中心统一管理,关键字段对应关系如下表:
| MA系统字段 | DeepSeek字段 | 转换规则 | 数据类型 |
|---|---|---|---|
| user_id | client_id | MD5加密 | VARCHAR |
| order_time | trans_date | UTC转换 | DATETIME |
| item_cnt | sku_qty | 单位转换 | INT |
异常处理机制采用三级重试策略:首次失败后立即重试,第二次间隔10秒,第三次间隔60秒,最终进入死信队列人工处理。日志记录遵循OpenTelemetry标准,包含trace_id、耗时、返回码等12个监控维度。服务降级方案在API成功率低于95%时自动触发,切换至本地缓存的基础模型服务。
3. 需求分析
在MA系统(Marketing Automation System)中接入DeepSeek大模型的核心需求可分为功能性、性能性、集成性和合规性四类。首先,功能性需求聚焦于模型能力的落地应用,包括自然语言处理(如智能客服应答、个性化内容生成)、数据分析(如用户行为预测、市场趋势挖掘)以及自动化决策支持(如营销策略优化、线索评分)。例如,在智能客服场景中,模型需支持多轮对话、意图识别和情感分析,准确率需达到90%以上;在内容生成场景中,需确保输出的文案符合品牌调性且无合规风险。
性能需求方面,系统需满足高并发和低延迟要求。根据历史数据测算,营销活动高峰期并发请求可能达到5000+/秒,响应时间需控制在500ms以内。同时,模型推理的吞吐量需支持每秒处理1000+条文本数据,且支持动态扩缩容以应对流量波动。资源消耗需优化至单节点GPU显存占用不超过16GB,以降低部署成本。
集成性需求强调与现有MA系统的无缝对接。DeepSeek的API需兼容RESTful和gRPC协议,支持JSON格式数据交换,并提供以下关键接口:
- 文本分析接口:输入用户行为日志,输出标签化结果
- 预测接口:输入历史数据,输出转化率预测值
- 生成接口:输入产品参数,输出营销文案
合规性需满足GDPR等数据保护法规,所有用户数据需在传输和存储时加密,且模型训练需支持数据脱敏。审计日志需记录完整的API调用链,包括请求时间、用户ID、输入摘要和输出摘要,保留周期不少于180天。此外,内容生成需内置敏感词过滤机制,违规内容检出率需达99.9%。
技术栈适配是另一关键需求。MA系统通常基于Java/Python构建,而DeepSeek模型可能依赖PyTorch/TensorRT,因此需设计中间适配层处理技术差异。例如,使用Docker容器化部署模型服务,通过Kubernetes实现负载均衡,并利用Redis缓存高频查询结果。以下为典型场景的资源预估:
| 场景类型 | QPS | 平均响应时间 | GPU资源 | 内存占用 |
|---|---|---|---|---|
| 实时对话 | 1200 | 300ms | T4×2 | 8GB |
| 批量数据处理 | 500 | 1.2s | A10G×1 | 12GB |
| 策略计算 | 200 | 800ms | CPU-only | 32GB |
最后,运维需求包括模型版本管理(支持A/B测试和灰度发布)、监控告警(设置TP99延迟阈值告警)以及灾难恢复(RTO<15分钟)。模型更新需实现热加载,确保服务不间断,且回滚机制能在2分钟内完成版本切换。所有需求需通过压力测试验证,模拟峰值流量下服务稳定性,确保系统在95%置信区间内满足SLA要求。
3.1 业务需求梳理
在业务需求梳理阶段,需明确MA(Marketing Automation)系统与DeepSeek大模型整合的核心目标及关键场景。当前企业面临的主要痛点包括客户画像精度不足、个性化内容生成效率低、实时交互响应能力有限等。通过对接DeepSeek的NLP能力与生成式AI技术,可显著提升以下业务环节的自动化水平与智能化程度:
-
客户行为分析与意图识别
MA系统现有规则引擎对非结构化数据(如社交媒体评论、邮件文本)的处理能力较弱,导致30%以上的潜在客户需求未被有效捕捉。DeepSeek的多模态理解能力可实现对以下数据的深度解析:- 客户咨询中的隐含意图(例如"预算有限"对应价格敏感度标签)
- 跨渠道行为轨迹的关联分析(官网浏览+客服对话的协同解读)
- 情感极性判断(投诉邮件中的紧急程度分级)
-
动态内容生成与优化
现有营销内容生产周期长达5-7天,A/B测试样本量不足导致转化率波动超过15%。需建立基于大模型的实时内容工厂:- 自动生成EDM主题行(20+备选方案/秒)
- 落地页文案动态适配(根据用户设备类型/地理位置自动调整卖点)
- 对话式广告脚本生成(支持10种以上行业话术模板)
-
智能决策与流程自动化
当前客户旅程中仍有40%的节点依赖人工判断,典型场景包括:- 高价值客户识别后未及时触发VIP服务流程
- 沉睡客户唤醒策略单一(仅依赖折扣刺激)
- 线索评分模型更新滞后(季度更新vs市场变化周级频率)
| 需求类型 | 现状痛点 | DeepSeek解决方案 | 预期提升指标 |
|---|---|---|---|
| 客户理解 | 标签体系覆盖率不足62% | 构建360°动态客户画像 | 标签准确率↑35% |
| 内容生产 | 人工创作占比70% | AI生成+人工校验模式 | 内容产出效率↑400% |
| 流程执行 | 平均响应延迟4.2小时 | 实时决策引擎+自动化工单分发 | 响应速度提升至分钟级 |
需特别关注数据合规性要求,确保模型训练与推理过程符合GDPR等法规。建议分三阶段实施:首期聚焦客户服务场景的智能应答,二期扩展至营销内容生成,最终实现全流程预测性运营。技术对接采用API+微服务架构,保证与现有MA系统的CRM模块、CDP平台无缝集成。
3.2 功能需求列表
在MA系统接入DeepSeek大模型的功能需求列表中,需明确系统需实现的核心能力、交互逻辑及性能指标。以下为详细功能需求:
-
多模态输入支持
- 文本输入:支持UTF-8编码,单次输入长度限制为10万字符,需自动分段处理。
- 文件解析:兼容PDF(含扫描件OCR)、Word、Excel、PPT、TXT,文件大小上限50MB。
- 语音输入:集成ASR模块,支持实时转写(延迟<500ms)及音频文件处理(MP3/WAV格式,16kHz采样率)。
-
智能对话引擎
- 上下文保持:对话轮次≥20轮,支持主动澄清机制(如用户指令模糊时自动追问)。
- 领域适配:预设金融、医疗、法律等10个垂直领域的知识库切换接口。
- 敏感词过滤:实时检测政治、暴力等6类违规内容,拦截准确率≥99.5%。
-
任务自动化处理
- 数据提取:从非结构化文本中抽取实体(如合同中的金额、日期),准确率要求≥92%。
- 报表生成:根据指令自动输出Markdown/HTML格式报表,支持表格合并与数据透视。
- 流程触发:与MA系统工单模块对接,识别"重置密码"等关键词时自动创建IT工单。
-
管理控制台功能
- 模型监控:实时显示API调用量、平均响应时间、错误代码分布。
- 权限分级:RBAC模型支持5级权限(如仅查询、带审核权限的管理员等)。
- 日志审计:保留6个月操作日志,支持根据用户ID/IP地址溯源。
-
集成接口规范
- API协议:RESTful与gRPC双通道,TLS 1.3加密。
- 错误代码:定义47种标准错误(如1001-输入超长、2003-领域库未加载)。
- 限流策略:默认阈值500次/分钟/账户,支持动态调整。
所有功能需通过压力测试(模拟1000并发用户持续8小时)及安全渗透测试(OWASP Top 10防护)。数据存储采用分布式架构,确保99.9%的服务可用性。
3.3 非功能需求(性能、安全等)
在MA系统接入DeepSeek大模型的应用场景中,非功能需求是保障系统稳定运行和用户体验的核心要素。以下从性能、安全性、可用性、可扩展性等维度进行详细说明:
性能需求方面,系统需满足高并发和低延迟的响应要求。在日均请求量10万次的业务场景下,API接口的99%分位响应时间应控制在500ms以内,峰值并发支持不低于1000QPS。模型推理环节需通过动态批处理技术优化吞吐量,单次推理的GPU显存占用不超过8GB,确保硬件资源利用率达到70%以上。对于长文本处理(如超过8k tokens的文档),系统需采用流式传输机制,避免内存溢出。
系统各模块的性能指标要求如下:
| 模块名称 | 吞吐量 (req/s) | 平均响应时间 | 错误率阈值 |
|---|---|---|---|
| 模型推理网关 | ≥800 | <300ms | ≤0.1% |
| 用户鉴权服务 | ≥1200 | <100ms | ≤0.01% |
| 数据缓存层 | ≥5000 | <50ms | ≤0.5% |
安全性需求包含三个关键层面:数据传输采用TLS 1.3加密协议,所有API调用必须通过OAuth 2.0令牌鉴权,敏感数据(如用户查询内容)在存储时需进行AES-256加密。模型服务部署在隔离的VPC网络环境,通过严格的ACL策略控制访问权限,仅允许白名单IP和端口通信。审计日志需记录完整的操作流水,包括请求时间戳、用户ID、输入特征哈希值等字段,日志保留周期不少于180天。
可用性需求要求系统达到99.95%的SLA保障,通过多AZ部署和自动故障转移机制实现。当单个节点故障时,负载均衡器应在15秒内完成流量切换。建立分级降级策略:在资源过载时,优先保障VIP用户的请求处理,非关键功能(如日志收集)可暂时关闭。每日凌晨3:00-4:00为维护窗口期,需确保滚动升级过程中服务不间断。
可维护性方面,系统需提供完善的监控接口,包括Prometheus格式的/metrics端点,监控指标覆盖GPU温度(阈值80℃)、内存使用率(阈值90%)、API错误码分布等。支持通过GitOps实现配置管理,所有基础设施变更必须经过CI/CD流水线验证。版本回滚机制需保证在10分钟内完成模型或服务的降级操作。
4. 技术实现细节
在技术实现层面,MA系统与DeepSeek大模型的集成需通过模块化架构完成,核心流程分为数据交互层、模型服务层及业务应用层。数据交互层采用RESTful API与gRPC双协议兼容设计,确保高吞吐与低延迟。API接口规范如下:
| 接口类型 | 协议 | 吞吐量(QPS) | 平均延迟(ms) | 数据格式 |
|---|---|---|---|---|
| 实时推理 | gRPC | 1500 | 80 | Protocol |
| 批量处理 | REST | 500 | 200 | JSON |
| 流式响应 | WebSocket | 300 | 120 | Protobuf |
模型服务层部署采用Kubernetes集群管理,配置自动扩缩容策略。资源分配遵循动态权重机制,关键参数包括:
- GPU节点:NVIDIA A100 40GB显存,单节点承载8个并发推理任务
- 内存分配:每实例预留16GB,突发缓冲增加25%
- 冷启动优化:预热池保持10%的常驻实例
业务应用层通过SDK封装实现零代码集成,支持Java/Python/Go三种语言。SDK内置以下特性:
- 自动重试机制(指数退避算法,最大3次)
- 本地缓存(LRU策略,默认TTL 300秒)
- 请求压缩(GZIP级别6)
- 敏感数据脱敏(正则匹配替换)
异常处理体系采用三级降级方案:当主模型响应延迟超过500ms时,自动切换至轻量化版本;当错误率超过5%时,触发本地规则引擎;完全不可用时返回预置业务逻辑模板。监控系统采集以下指标,采样频率为10秒/次:
- 模型推理耗时P99值
- 显存利用率波动
- API成功率(SLA≥99.5%)
- 异常请求特征分布
数据安全方面实施AES-256传输加密与静态数据脱敏,审计日志保留180天。模型版本更新采用蓝绿部署,切换过程控制在15分钟内完成,版本回退时间窗设置为2小时。最终系统性能指标需达到:单日处理能力≥500万次请求,端到端延迟<1.5秒(P95),支持7×24小时不间断服务。
4.1 DeepSeek模型API接入
DeepSeek模型API接入的技术实现需遵循标准化流程,确保高可用性与低延迟。以下是关键步骤及规范:
1. 认证与权限配置
- 使用OAuth 2.0协议进行身份验证,需提前在DeepSeek开发者平台申请API Key和Secret Key。建议采用RBAC模型管理权限,例如:
-
权限分级配置示例:
角色 权限范围 QPS限制 admin 全量API调用 1000 query_engine 仅文本生成/分析 500 data_parser 结构化数据解析 200
2. 请求协议标准化
- 统一采用HTTPS/2协议,请求头需包含:
Content-Type: application/json X-Request-ID: [UUID] X-Timestamp: [ISO8601] - 负载数据使用JSON Schema规范,示例:
{ "model": "deepseek-v2.5", "parameters": { "temperature": 0.7, "max_tokens": 2048 }, "inputs": ["${用户输入文本}"] }
3. 连接池管理
-
建议使用Apache Commons Pool 2维护长连接,参数配置基准:
参数 生产环境值 测试环境值 maxTotal 200 50 maxIdle 50 10 minEvictableIdleTime 300000ms 60000ms testOnBorrow true false
4. 容错机制实现
- 分级重试策略:
- 首次失败:立即重试(间隔500ms)
- 二次失败:指数退避(最大间隔5s)
- 三次失败:降级本地缓存
- 熔断阈值设置:
5. 性能监控埋点
- 必须采集的监控指标:
- API响应时间P99
- 令牌消耗速率
- 上下文长度分布
- 错误码分类统计
- 推荐使用Prometheus+Grafana监控体系,指标命名规范:
deepseek_api_duration_seconds{method="generate_text"} deepseek_tokens_consumed_total{model="v2.5"}
6. 数据安全合规
- 传输层启用双向TLS认证,证书有效期不超过90天
- 敏感数据字段需进行AES-256-GCM加密,密钥轮换周期为7天
- 请求日志脱敏规则:
原始字段: {"phone": "13812345678"} 脱敏后: {"phone": "138****5678"}
所有实现需通过自动化测试验证,包括但不限于:
- 基准压力测试(JMeter模拟5000RPS)
- 混沌工程实验(随机注入网络延迟)
- 一致性验证(比对不同可用区返回结果)
4.1.1 API调用流程
在MA系统中接入DeepSeek大模型API的调用流程需遵循标准化接口协议,确保高可用性与低延迟。以下是核心实现步骤:
- 认证初始化
通过OAuth 2.0协议获取访问令牌,需在MA系统配置中心预置以下参数:client_id: 由DeepSeek平台分配的开发者标识client_secret: 对应密钥grant_type: 固定为client_credentials
- 请求构造规范
API请求需包含以下必选头部:Authorization: Bearer <access_token>Content-Type: application/jsonX-Request-ID: UUID防重放标识
请求体采用JSON格式,示例模板:
{
"model": "deepseek-v2",
"parameters": {
"temperature": 0.7,
"max_tokens": 1024
},
"messages": [
{"role": "user", "content": "MA系统订单分析请求"}
]
}
- 流量控制机制
通过令牌桶算法实现分级限流,建议配置:
| 服务等级 | QPS上限 | 突发流量配额 |
|---|---|---|
| 基础版 | 50 | 200 |
| 企业版 | 500 | 2000 |
- 响应处理逻辑
标准响应包含三层结构:- 业务状态码(200/400/500等)
- 处理耗时(X-Latency毫秒级)
- 数据体(含usage元数据)
异常情况需实现自动重试策略:
- 5xx错误:采用指数退避重试(最大3次)
- 429限流:等待X-RateLimit-Reset头指定时间后重试
-
连接池优化
建议为每个API端点维护独立连接池,典型配置:- 最大连接数:50
- 空闲超时:300秒
- 连接存活检测间隔:60秒
-
日志监控埋点
关键指标需记录到监控系统:- API成功率(SLI ≥ 99.9%)
- P95延迟(企业版要求 < 800ms)
- 令牌消耗速率(按model分维度统计)
所有技术实现需通过沙箱环境验证后上线,建议使用Postman Advanced进行接口契约测试,确保符合OpenAPI 3.0规范。对于高并发场景,应采用异步调用模式,通过callback_url接收处理结果。
4.1.2 认证与权限管理
在MA系统接入DeepSeek大模型的过程中,认证与权限管理是保障系统安全性和数据隔离的核心环节。以下是具体实施方案:
认证机制
采用OAuth 2.0协议实现双向认证,确保MA系统与DeepSeek API之间的安全通信。服务端通过JWT(JSON Web Token)携带身份信息,包含以下关键字段:
iss(签发者):MA系统唯一标识sub(用户/服务账号)exp(过期时间戳)scopes:权限范围列表
每个API请求需在Header中附加Authorization字段,格式为:
Authorization: Bearer <JWT_TOKEN>
以下为方案原文截图,可加入知识星球获取完整文件








欢迎加入AI产品社知识星球,加入后可阅读下载星球所有方案。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)