DeepSeek大模型API实战指南,python一键调用AI超能力打造多轮对话机器人!
本文分享了如何使用python 代码 编写 OpenAI 访问格式来请求DeepSeek大模型,并编写了一个简单的多轮对话机器人,帮助大家理解对话网站的基本原理。值得注意的是,大模型可不仅仅有对话功能,上面介绍过的参数还没使用呢,它与大模型的函数调用能力息息相关,能力可以帮助大模型调用工具函数获得更高阶能力,例如谷歌搜索,计算器,天气查询等功能,让大模型不只能对话更会“上天入地”!
在人工智能技术飞速发展的今天,大模型已经成为各行各业提升效率的利器。从会议记录撰写到代码编程,从数据分析到总结报告生成等各个领域都少不了大模型的参与。目前大家使用大模型的方法基本是在对话界面向大模型提出问题并得到解决方案。
然而,随着工作难度的进一步增强,如何快速、高效地使用这些强大的AI能力,创造更便捷的AI工具,成为了许多开发者和企业的痛点。大模型的API调用,正是解决这一问题的关键!
一、API调用的优势
相比传统的问答网站,API调用有如下便捷优势,是广大程序员发挥创造力的利器:
- 快速集成,降低开发成本: API调用允许开发者通过简单的接口,将DeepSeek大模型的强大能力嵌入到自己的应用或系统中。无论是文本生成、数据分析,还是智能客服,API都能快速实现功能集成,无需从头开发复杂的AI模型。
- 灵活扩展,满足多样化需求: 通过API调用,开发者可以根据业务需求灵活调整调用频率和规模。无论是小型项目还是大型企业级应用,API都能轻松应对,实现按需扩展。
- 高效稳定,提升用户体验: API调用基于云端服务,具备高可用性和低延迟的特点。用户无需担心本地硬件性能不足,也能享受到流畅的AI服务体验。
二、 大模型OpenAI调用格式
2.1 OpenAI调用格式详解
OpenAI 作为行业领军者,不仅开发出gpt-4, gpt-o1等知名大模型,还统一了大模型的API请求规范,分为如下三步:
-
实例化客户端,指定大模型的
base_url和api_key -
设置请求参数,其中
messages是必填参数,类型是列表,每个列表项由content和role字段组成,有system message,user message,assistant message,tool message四种:对于问答项目,一般只需要
system message,user message和assistant message三个字段,tool message一般用于设置大模型调用扩展函数的能力,是开发AI Agent的关键
-
system message:设置系统消息, 提供对话背景
-
user message:设置用户对话内容
-
assistant message:设置大模型输出内容和使用函数,除了
content和role字段外,还有tool_calls字段,是可选的列表类型,指定大模型要调用的函数(比如联网搜索函数,计算器函数等扩展大模型能力) -
tool message:在用户根据
assistant的tool_calls内容调用了某个函数后,用户可能还需要再把函数调用结果反馈给大模型,让大模型根据函数调用结果给出最终的总结性的答复。除了content和role字段外,还有tool_call_id字段,表示对指定函数反馈。
-
解析请求返回对象,非流式调用返回
chat completion object(大模型一次性输出全部回答), 包括流式调用(大模型一个词一个词输出, 问答网站的常见形式)返回
chat completion chunk object, 与chat completion object唯一不同的是choices对象, 流式调用choices对象中有delta字段,该字段中的content属性是渐变的,比如第一个chunk流的content是“Hel”,第二个chunk流的content是“Hello ”,第三个chunk流的content是“Hello wo”,第四个chunk流的content是“Hello world!
-
id:本次会话唯一标识符
-
choices:响应的内容列表, choices列表项中
message对象的content字段记录了大模型回答的内容 -
created: 聊天完成时间
-
model: 用于聊天的模型
-
usage: 本次聊天统计请求,包括生成token的数目等
2.2 构造OpenAI请求格式访问DeepSeek大模型
通过上面的介绍,想必大家已经详细了解了OpenAI大模型调用格式。我们的国产大模型之光—DeepSeek大模型也支持通过OpenAI格式调用。下面我们将详细介绍如何使用Python 结合 OpenAI 格式请求,调用DeepSeek API,并通过具体的代码示例帮助大家快速上手。
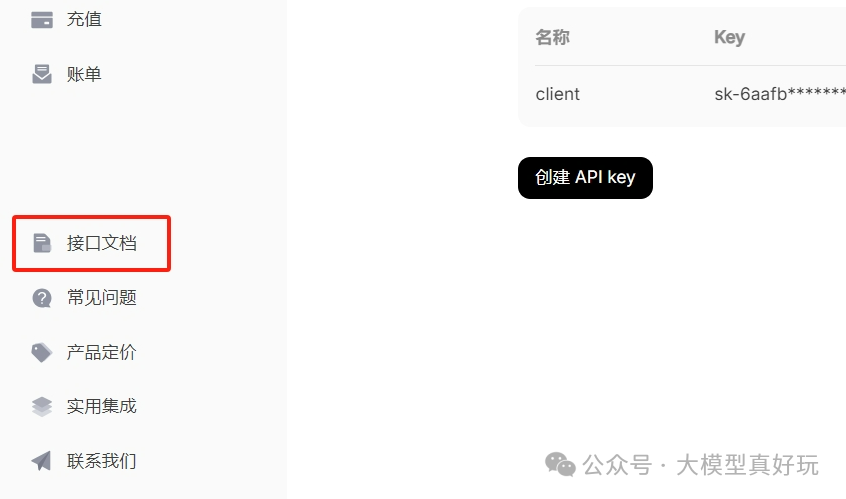
- 进入DeepSeek官网,并点击API开放平台:

- 注册DeepSeek开发者账号,并获取API密钥(API Key),使用API访问前要确保你的token余量充足。

- 这里使用python进行API调用演示,执行
pip install openai下载openai请求格式库,编写如下代码测试访问,可以看到请求参数包含了上面讲过的base_url,api_key以及两种message,返回结果保存在response对象的choice属性中。
from openai import OpenAI
client = OpenAI(api_key="你获得的API Key", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)

三、 使用DeepSeek API构建多轮对话机器人
熟悉DeepSeek API的调用过程后,下面通过一个小项目:构建多轮对话机器人帮助大家进一步玩转大模型编程,理解对话网站的逻辑。完整代码在: https://codecopy.cn/post/jgd6iw
- 导入openai格式包,并创建deepseek访问客户端:
from openai import OpenAI
client = OpenAI(api_key="填入你的api", base_url="https://api.deepseek.com")
- 创建请求体的
messages列表(列表包含多轮对话的历史信息),每个messages列表项包括role角色和content内容两个属性:
def create_message(role, content):
return {
"role": role,
"content": content
}
def process_user_input(input_text):
return create_message("user", input_text)
- 定义解析用户提问后大模型返回结果的函数:
def chat_with_DeepSeek(client, messages):
response = client.chat.completions.create(
model="deepseek-chat", # 使用 deepseek-chat 模型
messages=messages
)
# 提取并返回助手生成的回复内容
return response.choices[0].message.content
- 定义多轮对话的函数逻辑, 首先创建上下文
messages列表,设置背景system_message, 把每轮对话的用户输入处理为user_message,系统回复处理为assistant_message,统统添加到messages列表中,让大模型了解到历史对话背景:
def multi_round_chat():
# 初始化消息列表,包含系统消息
messages = []
# 创建系统消息,设置对话的上下文
system_message = create_message("system", "You are a helpful assistant.")
messages.append(system_message)
while True:
# 捕获用户输入
user_input = input("User: ")
# 处理用户输入并生成相应的消息
user_message = process_user_input(user_input)
messages.append(user_message)
# 调用 DeepSeek 模型进行回复
assistant_reply = chat_with_DeepSeek(client, messages)
print(assistant_reply)
# 将助手回复添加到消息列表, 多轮对话必备
messages.append(create_message("assistant", assistant_reply))
# 提供退出机制,用户可以输入 'exit' 退出对话
if user_input.lower() == 'exit':
print("对话结束。")
break
- 调用多轮对话函数
multi_round_chat(),开始与大模型对话吧~:

四、DeepSeek API 调用详细参数
除了常用的model和messages参数,DeepSeek模型 API调用还有其它许多别的参数,这里直接给大家列一个总表,大家按需传参:
| 参数名 | 类型 | 必填/可选 | 默认值 | 说明 |
|---|---|---|---|---|
| model | string | 必填 | 无 | 指定要使用的模型 ID,例如 deepseek-chat 或 deepseek-reasoner。 |
| store | boolean or null | 可选 | false | 是否存储本次对话的输出,供模型精炼或评估产品使用。 |
| metadata | object or null | 可选 | null | 开发者自定义的标签和值,用于过滤仪表盘中的补全结果。 |
| frequency_penalty | number or null | 可选 | 0 | 数值在 -2.0 到 2.0 之间,正值减少重复生成内容的可能性。 |
| logit_bias | map | 可选 | null | 调整某些特定 tokens 出现的可能性,值在 -100 到 100 之间。 |
| logprobs | boolean or null | 可选 | false | 是否返回生成的每个 token 的对数概率。 |
| top_logprobs | integer or null | 可选 | null | 指定返回最有可能出现的前几个 tokens 及其概率,需开启 logprobs。 |
| max_completion_tokens | integer or null | 可选 | null | 指定模型生成的最大 token 数,包括可见文本和推理 tokens。 |
| n | integer or null | 可选 | 1 | 每个输入生成的对话补全选项数量,值越大,生成的回复越多。 |
| presence_penalty | number or null | 可选 | 0 | 数值在 -2.0 到 2.0 之间,正值鼓励生成新的主题和内容。 |
| response_format | object | 可选 | null | 指定生成结果的格式,可以设置为 json_schema 以确保结构化输出,或 json_object 用于 JSON 格式。 |
| seed | integer or null | 可选 | null | 保持生成的一致性,重复相同请求将尽量生成相同的结果。 |
| service_tier | string or null | 可选 | auto | 指定服务延迟等级,适用于付费订阅用户,默认为 auto。 |
| stop | string / array / null | 可选 | null | 最多指定 4 个序列,API 遇到这些序列时会停止生成进一步的 tokens。 |
| stream | boolean or null | 可选 | false | 是否启用流式响应,若启用,生成的 tokens 将逐步返回。 |
| stream_options | object or null | 可选 | null | 流式响应的选项,仅当 stream 为 true 时设置。 |
| temperature | number or null | 可选 | 1 | 控制生成输出的随机性,值越高生成的文本越随机。建议调整此值或 top_p,而不是同时调整。 |
| top_p | number or null | 可选 | 1 | 使用核采样方法,选择最有可能的 tokens,总概率达到 top_p 百分比。建议与 temperature 二选一。 |
| tools | array | 可选 | null | 模型可以调用的工具列表,目前仅支持函数调用。 |
| user | string | 可选 | null | 表示最终用户的唯一标识符,用于监控和检测滥用行为。 |
五、总结
本文分享了如何使用python 代码 编写 OpenAI 访问格式来请求DeepSeek大模型,并编写了一个简单的多轮对话机器人,帮助大家理解对话网站的基本原理。
值得注意的是,大模型可不仅仅有对话功能,上面介绍过的tool message参数还没使用呢,它与大模型的函数调用Function Calling能力息息相关,Function Calling能力可以帮助大模型调用工具函数获得更高阶能力,例如谷歌搜索,计算器,天气查询等功能,让大模型不只能对话更会“上天入地”!
我的DeepSeek部署资料已打包好(自取↓)
https://pan.quark.cn/s/7e0fa45596e4
但如果你想知道这个工具为什么能“听懂人话”、写出代码 甚至预测市场趋势——答案就藏在大模型技术里!
❗️为什么你必须了解大模型?
1️⃣ 薪资爆炸:应届大模型工程师年薪40万起步,懂“Prompt调教”的带货主播收入翻3倍
2️⃣ 行业重构:金融、医疗、教育正在被AI重塑,不用大模型的公司3年内必淘汰
3️⃣ 零门槛上车:90%的进阶技巧不需写代码!会说话就能指挥AI
(附深度求索BOSS招聘信息)
⚠️警惕:当同事用DeepSeek 3小时干完你3天的工作时,淘汰倒计时就开始了。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?老师啊,我自学没有方向怎么办?老师,这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!当然这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
 29
29 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)