一文秒懂Transformer:拆解火爆大语言模型背后的秘密
Transformer架构以自注意力机制为核心,突破了传统序列模型的局限,极大提升了自然语言处理的能力。输入嵌入和位置编码解决了语义和顺序感的结合,多头自注意力、多层前馈网络等模块让模型可以捕捉复杂的全局关系和抽象表达。掩码自注意力则确保了模型生成时的信息封闭性和合理性。这些创新共同构建了强大而高效的底座,使Transformer成为近年来AI领域最火爆的模型框架,催生如GPT系列、DeepSee
Transformer架构概述
深度学习在2010年代初期迎来了快速发展,尤其是在自然语言处理(NLP)领域。那时,主流的序列建模方法大多依赖循环神经网络(RNN)及其变种如长短时记忆网络(LSTM)和门控循环单元(GRU),它们能够处理序列数据、捕捉基本的上下文信息。而卷积神经网络(CNN)则偶尔被用于文本的特征提取和句向量生成。
尽管这些模型推动了NLP进步,但仍存在突出短板。首先,它们难以捕获长距离依赖。例如,RNN要理解长句中首尾词汇的关联,信息需多层传递,极易导致梯度消失或爆炸。其次,这类模型对序列数据的操作方式天然受限于顺序处理,往往无法高效并行,训练效率不高。
2017年,Vaswani等人在论文《Attention is All You Need》中,正式提出了Transformer架构。这一创新采用完全基于注意力机制(尤其是自注意力)的新框架,摈弃了RNN和CNN等对数据顺序的刚性依赖,让模型可以在单步内关注输入序列中任意位置的元素,实现了高效并行训练,同时大幅提升了长距离依赖建模能力。
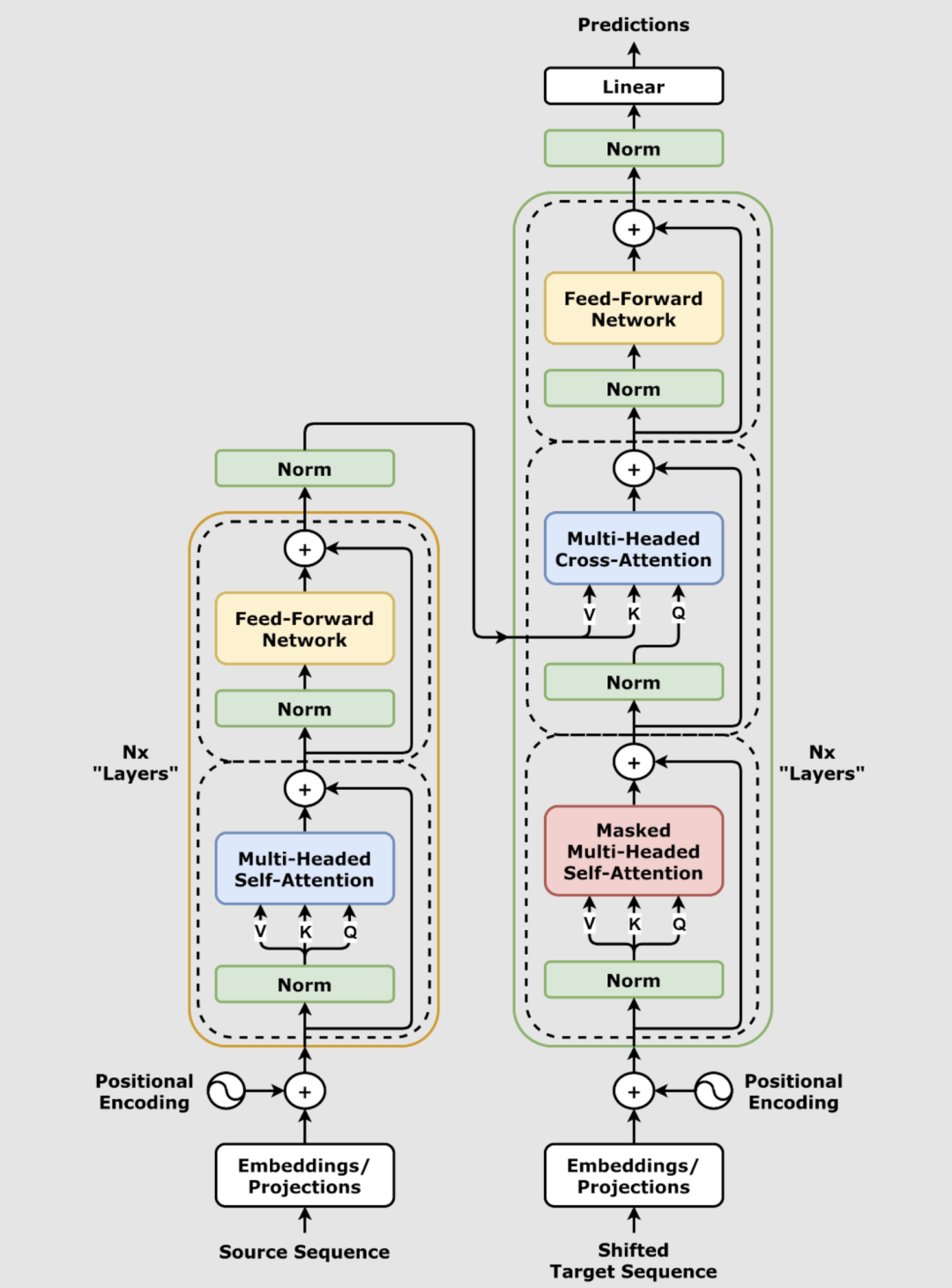
下面我们来详细解读Transformer的整体设计思路和核心模块。
Transformer整体架构由编码器(Encoder)和解码器(Decoder)两大主模块堆叠而成。每个模块内部又包含一套核心子结构,重复多层以构建深层网络。其中最重要的组成部分有:
-
输入嵌入与位置编码(Embedding & Positional Encoding):将文本token转化为高维向量,并将位置信息用特殊编码加入表征。
-
自注意力机制(Self-Attention):让序列中每个元素自由地“关注”序列其它所有元素,动态分配权重,建模复杂的词间关联。
-
多头注意力机制(Multi-Head Attention):并行设置多个注意力头,不同“头”各自专注不同的信息模式,合并后增强表示力。
-
前馈神经网络(Feed Forward Network):每层注意力之后的多层感知机,独立作用于每个序列位置,进一步抽象和组合特征。
-
残差连接与层归一化(Residual Connection & Layer Normalization):跨层跳连与特征标准化,确保梯度流畅和训练稳定。
输入嵌入与位置编码
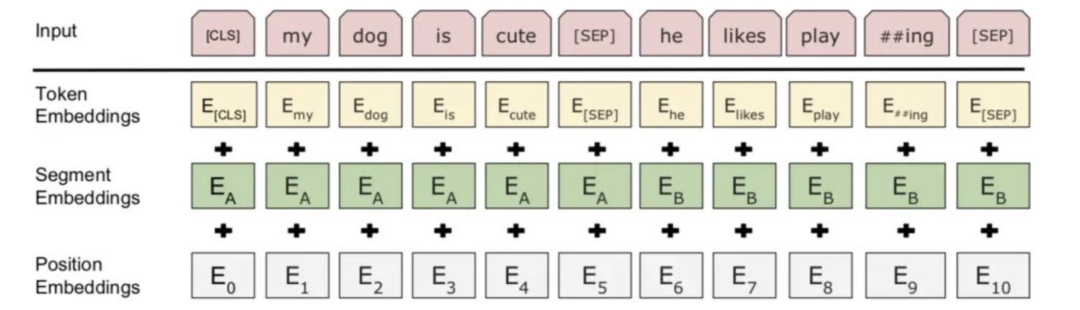
Transformer需要将文本转化为模型能理解的数字形式。
这首先涉及“嵌入”的概念:自然语言中的每个词(或更小的token)本质上是一个符号,对计算机而言必须转变为可计算的向量。嵌入(Embedding)就是将每个token通过查表或神经网络,映射为一个比原始词表小得多、但具有丰富语义信息的高维连续向量。这些向量经过训练后会捕捉到词语之间的相关性,比如“国王”与“皇后”向量距离接近、“苹果”与“香蕉”更相关,而与“桌子”距离更远。这样,模型可以基于向量的相似性处理不同的词语。举例:假设“猫”与“狗”有很小的欧氏距离而与“飞机”距离大,代表它们在语义空间更接近。
不过,仅有词嵌入还不够。Transformer不像RNN那样天然利用顺序,因此需要引入“位置编码”以理解词语顺序。“编码”这里指的是为每个token增加一组特征,明确表示该词在序列中的位置。一般做法是利用正弦、余弦函数或模型可学习参数,把每个位置映射成唯一向量,与原始词向量相加,从而赋予模型顺序感。比如“我爱你”和“你爱我”,位置编码可以让模型区分“我”的先后含义,而不仅是出现的词本身。
距离在这个概念体系下,既可以理解为词向量之间的相似度(如欧氏距离、余弦相似度),衡量语义接近程度,也可以指序列中词语的先后间隔(通过位置编码表现),两种距离共同作用帮助模型综合把握内容和结构。
自注意力、多头自注意力与掩码自注意力
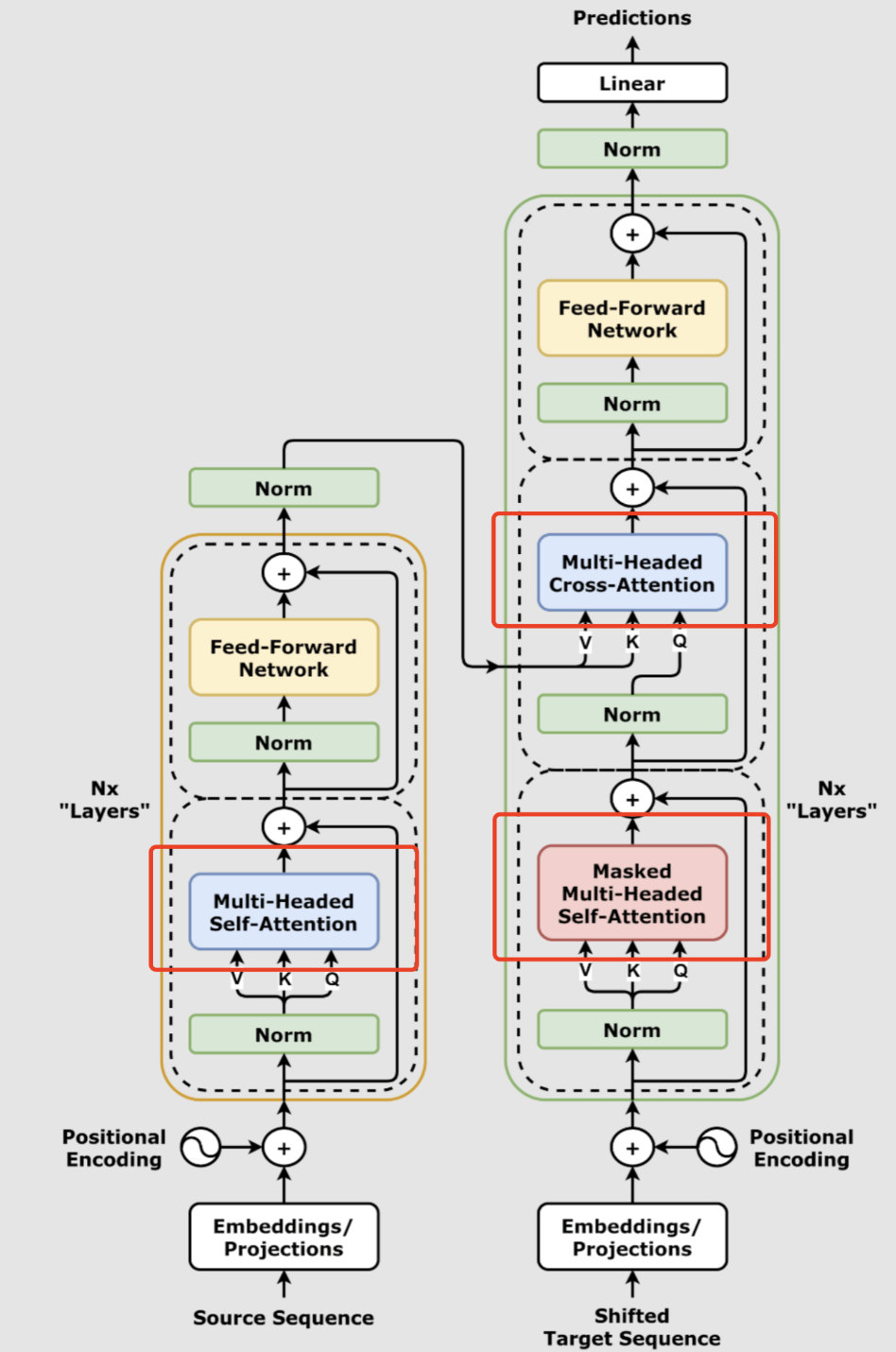
自注意力
自注意力机制是Transformer架构中最具革命性的发明之一,它赋予了模型“全局感知”输入序列各个部分之间复杂关联的能力。在传统的RNN或LSTM模型中,单词之间的联系依赖信息在序列中的逐步传递,这使得长距离依赖难以捕获。而自注意力机制突破这一限制,让每一个token都可以直接考虑序列中所有其它token的信息。
自注意力机制的精髓在于,输入序列中的每个元素都可以自由“查找”与自己相关的其它元素,建模全局依赖。那么具体它是如何实现的呢?
自注意力的核心操作涉及三组向量:查询(Query)、键(Key)和值(Value),也就是Q、K、V。每个token(比如一个单词或字符)都会通过乘以三组独立的权重矩阵,变换出自己的Q、K、V向量。我们可以这样理解:
-
查询Q代表这个词正在“提问”,关心自己要看哪些词;举例:
-
键K代表其它所有词“能不能被关注”,即提供信息的标签;
-
值V代表每个词被关注之后传递的具体内容。
接下来就是一个全局关联性“打分”流程:每个词的Q依次与所有词的K做点积计算(理论上越“对口”,点积越大),这样得到了一组注意力得分,代表“该词对其它每个词的关注度”。以概率的形式呈现,反映出它在当前词语表达中的重要性。随后,这些归一化的权重与对应的值V相乘并加权求和,形成了最终的注意力输出,明确每个词在当前上下文中所占的权重,确保模型能够有效聚焦于关键语义信息,从而提升理解和生成的准确性。
这些分数经过Softmax归一化——所谓Softmax,就是将所有关注度分数拉到0~1之间,并让它们的和为1。这样每个词最终分到的关注度,可以看作概率分布,也更容易解释和后续处理。
下面一个简单的例子说明自注意力机制的工作原理:
假设我们有这样一句中文:“小明把苹果给了小红,因为她很喜欢吃苹果。”
在理解“她”这个词时,人类会自然地将其与“小红”对应起来。那么,Transformer自注意力机制是如何让模型学会这个指代关系的呢?
-
在自注意力机制中,模型会为每个词构造一组查询(Q)、键(K)和值(V)向量。
-
当模型处理“她”时,就会用“她”的Q去与句中每个词的K做相似度打分。
-
打分结果会通过Softmax归一化,归一化后“她”与“小红”的相关性就会占很大比例,而其他词的权重则更小。
-
最后,模型会用这些权重加权求和所有词的V,得到“她”的最终表达,模型便能准确地捕捉到“她”最可能指代的是“小红”。
这种机制不仅适用于指代消解,还可以让模型自动发现长距离的语法和语义依赖(如“因为...所以...”结构下原因与结果内容的链接),大幅提升了序列理解的能力。
多头注意力
多头注意力其实是在上一节自注意力机制流程"复制"多份——每个注意力头其实就是自注意力的一份独立拷贝,只不过有各自独立的参数空间和映射方向。最终所有头的输出会被拼接,并统一送入后续网络进行整合和特征再抽象。
举个通俗的例子:就像在审阅同一篇中文作文时,一组老师分别从语法、立意、文笔、逻辑等不同角度给出打分和建议,最后汇总出一份更客观全面的评语。多头注意力让Transformer一次性获得多视角捕捉语言细节的能力,每一头都能自主发现、强化或忽略不同的信息,这正是它在大规模语言任务中表现卓越的关键。
在上一节自注意力机制中,我们看到每次通过Q、K、V打分后,模型会聚焦于与当前词关系最密切的那些词。但现实中的语言极其复杂,有时我们既要关注语法结构,比如主谓宾的关系,有时又要体会语义联系,如因果、指代、修饰等。单一注意力头其实难以兼顾所有维度。
这时,多头注意力机制登场了。它的基本思想是:事先将词向量“平行”分成多组,每组用独立的Q、K、V权重矩阵去做注意力计算。每个“头”相当于专注不同类型的信息提取,比如一个头习惯捕捉指代关系,另一个则擅长理解修饰语,剩下的头则关注时态、语义距离或句法成分。
将所有头各自得到的注意力输出拼接起来,再统一变换组合,模型就获得了多重角度综合后的精华表达,远比单一注意力头信息更丰富。这样做的好处在于:1)模型能同时学到多种类型的依赖关系,2)保证复杂长文本或多领域任务时不会遗漏重要信息。
举例来说,在一句复杂的中文句子里,比如“虽然天气很冷,但是大家还是坚持训练”,某个头或许专注在“虽然…但是…”之间的对比关系,另一个头则捕捉“天气——冷”之间直接修饰的关系,还有头关注“大家——坚持训练”之间的动作与主体。
最终,模型把这些多头的结果整合起来,既没有漏掉上下文之间复杂的联系,也保证同一句话能被多视角完整解析。这种设计,让Transformer具备了极强的语言理解与迁移能力,有力支撑了后续的庞大语言模型发展。
掩码自注意力
masked self attention 其实就是给自注意力机制加一道“遮挡”,让模型在处理当前词的时候,看不到后面还没生成的词。比如用在文本生成、机器翻译等场景,避免模型“提前看到答案”。在计算注意力权重时,通过给未来的位置加一个很大的负数,让它们的关注度变成0,相当于给这些词“打上遮罩”,模型就只能依赖前面已经出现的信息,从而实现一步一步地预测下一个词。这样保证了预测的“公平性”和正确流程。
前馈网络
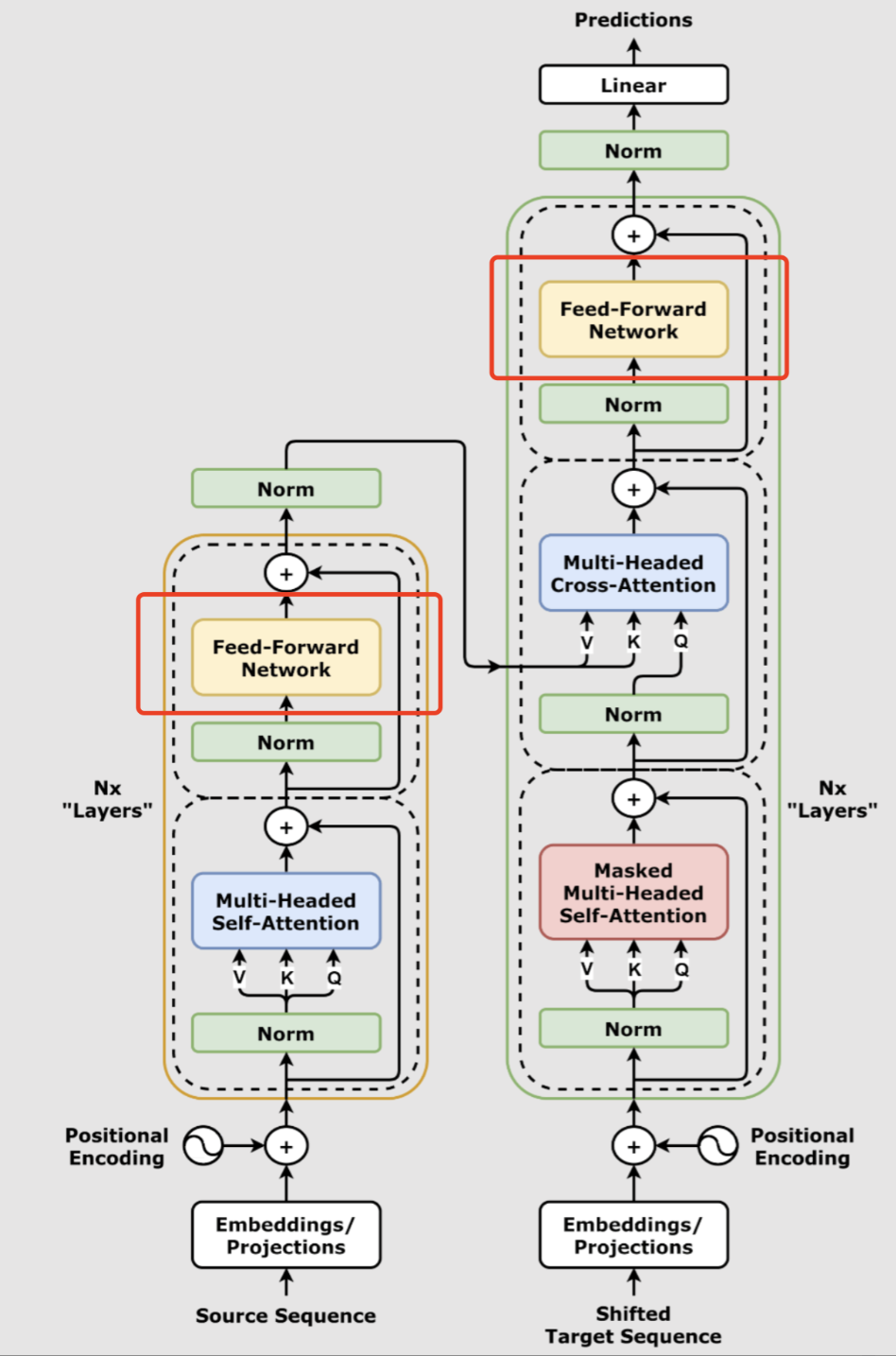
前馈网络(Feed Forward Network,简称FFN)是Transformer每一层的“加工厂”,紧跟在多头自注意力机制之后。可以把它理解成,在模型已经捕捉到谁和谁有关系之后,还需要把每个词的信息加工加深,变得更“聪明”或表达更丰富。换句话说,自注意力挖掘的是序列内部的信息联系,而前馈网络则是把这种联系进一步抽象、组合成高级特征。
前馈网络接收到的,是每个词汇(token)在经过多头自注意力机制初步处理后得到的特征向量。也就是说,这时候每个词的信息已经融合了全句上下文——像一团带有丰富背景的“泥”。
主要步骤:
-
第一层线性变化:把每个词的特征向量送进全连接层,相当于做一次“膨胀”,把特征空间拉长,产生更多新的可能表达。
-
第二层线性变化:再送进一个全连接层,这次是“压缩”,回到原有的特征维度,就像深加工后重新包装。
-
输出:每个词在这一轮加工后,都会拥有一套全新的、更丰富更抽象的表达。这些新的词向量会被交给下一层,继续“全局串门+局部打磨”的循环。
简单来说,前馈网络的作用主要有:
-
让每个词的表达更充分: 注意力机制帮模型搞懂了词与词的关系,前馈网络再帮每个词的信息“深加工”,变得更抽象,适应更复杂的理解和推理。
-
增强表达能力: 经过注意力模块捕捉到的上下文融合信息后,前馈网络就像一套局部深度加工设备,自动抓住词语组合之间更复杂的高阶特征。
最近有很多大语言模型(比如GPT-4、GLM、T5)把“前馈网络”升级成了“专家网络”(Mixture-of-Experts),前馈部分被拆分为多个子网络,每个可以聚焦于不同子任务或领域,最终自适应地合并输出结果。这样可以实现在参数量扩展的同时,不会显著增加推理难度。
QKV
QKV 分别代表 Query(查询)、Key(键)、Value(值)。这三个东西都来自原始输入信息,只是经过不同的“变换”得到。你可以把它们想象成某种智能邮递系统里的“信件内容”(Value)、“地址标签”(Key)和“收件人偏好”(Query)。
QKV 的核心作用是帮助模型决定在一堆信息里,哪些部分最值得关注。Transformer 等模型用 QKV 来做“注意力机制”,也就是为不同的信息分配不同的重要性,让模型能精准捕捉到上下文的微妙联系。这一机制已经广泛应用于文本理解、机器翻译、智能写作甚至图像识别等众多领域。
想象你在看一部推理剧,要找出凶手。你(Query)会带着某种偏好,去比对所有嫌疑人(每个人的信息就是 Key 和 Value)。有些嫌疑人的特征跟你的直觉很吻合(Key 和 Query 高度匹配),他们的举动(Value)就会被你格外关注。其他人则被你自动忽略。这就是 QKV 在大脑中的一种简化版,帮助你在大量线索中筛选出关键证据。
通俗的讲,QKV 就是模型用来自动“找重点”、决定何时该看哪里、看多深。
总结
Transformer架构以自注意力机制为核心,突破了传统序列模型的局限,极大提升了自然语言处理的能力。输入嵌入和位置编码解决了语义和顺序感的结合,多头自注意力、多层前馈网络等模块让模型可以捕捉复杂的全局关系和抽象表达。掩码自注意力则确保了模型生成时的信息封闭性和合理性。这些创新共同构建了强大而高效的底座,使Transformer成为近年来AI领域最火爆的模型框架,催生如GPT系列、DeepSeek 系列等众多的大模型产品。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)