如何用ollama本地部署大模型(以deepseek为例)
Ollama 是一个开源工具,允许用户在 本地计算机 上轻松运行、管理和部署大型语言模型(LLMs),如 Llama 3、Mistral、Gemma、DeepSeek 等。它提供了简单的命令行界面(CLI),让开发者无需复杂配置即可在本地体验 AI 模型。2. Ollama 的核心特点开箱即用支持一键下载和运行模型(如 ollama run llama3)。自动处理依赖项(如 GPU 加速)。✅
1. 什么是 Ollama?
Ollama 是一个开源工具,允许用户在 本地计算机 上轻松运行、管理和部署大型语言模型(LLMs),如 Llama 3、Mistral、Gemma、DeepSeek 等。它提供了简单的命令行界面(CLI),让开发者无需复杂配置即可在本地体验 AI 模型。
2. Ollama 的核心特点
开箱即用
支持一键下载和运行模型(如 ollama run llama3)。
自动处理依赖项(如 GPU 加速)。
✅ 丰富的模型库
官方支持 Llama 3、Mistral、Gemma、Phi-3、DeepSeek 等热门开源模型。
社区提供大量微调版本(如代码专用、多语言优化等)。
✅ 跨平台支持
支持 macOS、Linux、Windows(需 WSL2)。
提供 REST API,方便集成到其他应用。
✅ 轻量化与高效
量化技术(如 4-bit 量化)降低硬件需求,可在消费级 GPU(甚至 CPU)上运行。
支持多模型并行加载和切换。
3.使用方法
首先去到官网进行安装ollamaOllama
安装好后再次进入官网选择你想本地部署的大模型
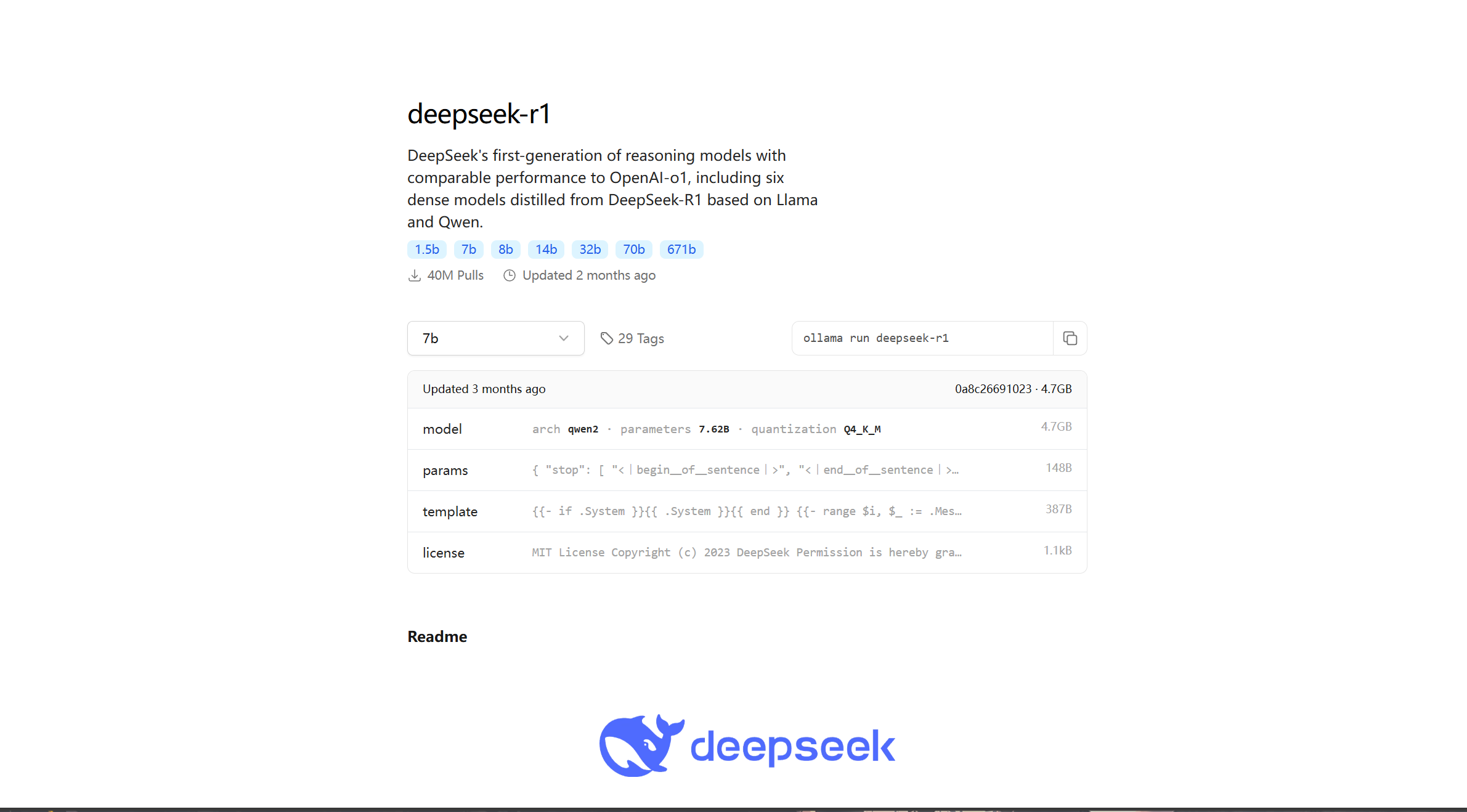
deepseek的话一般来说我们不会选择满血版部署因为过大,我们就先选择1.5版本来部署测试
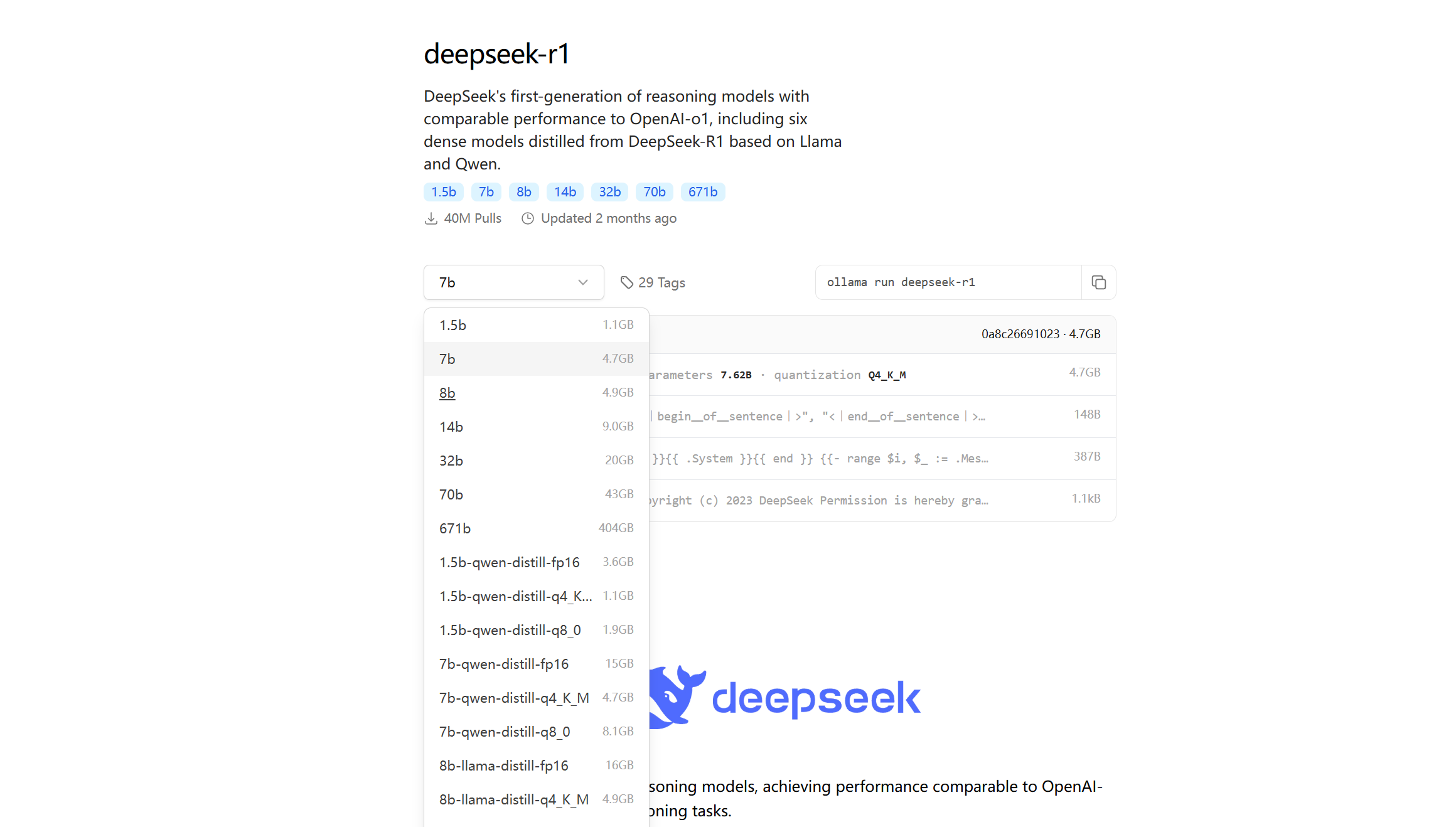
选择好后复制旁边的指令
ollama run deepseek-r1:1.5b
接下来打开命令行输入命令
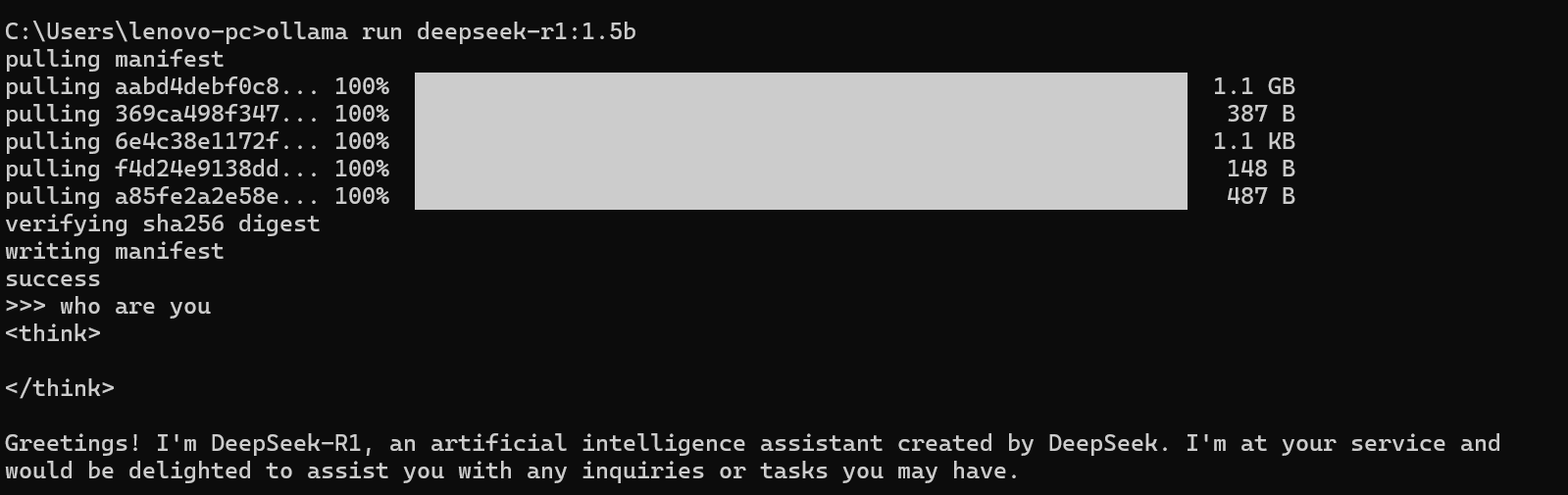
就开始本地部署了!部署完就可以与大模型进行对话了,第一次可能有点慢,因为要下载,后面如果要用的话也是同样的命令就比较快了

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)