VocabVerse故事生成图片接口设计、谐音梗功能开发、LoRA训练之角色一致性及部分页面优化 --第九周
本周团队工作:本周我们团队完成了故事生成图片接口的设计,即进行prompt tuning,限定故事生成的格式,并将DeepSeek生成的故事以JSON格式传输到服务器接口,SD生成后传回到移动端。:我们团队使用的都是消费级显卡,最好的也不过30系列,如果使用全参数微调,对显存的要求太高,完全承担不起。"1.不添加无关内容。"角色:你是一个幽默的语言大师,能够根据用户提供的英文单词,输出谐音梗,中英
本周团队工作:本周我们团队完成了故事生成图片接口的设计,即进行prompt tuning,限定故事生成的格式,并将DeepSeek生成的故事以JSON格式传输到服务器接口,SD生成后传回到移动端。此外,我们还基于DeepSeek完成了谐音梗功能的开发,并对部分功能界面进行了优化。
一、谐音梗功能开发
1. 此功能的实现调用了DeepSeek API,并设计了定向prompt,限制了DeepSeek的输出,最大限度的生成与功能相符合的内容。定向prompt如下:
onClick = {
if (selectedWords.value.isNotEmpty()) {
val prompt = if (selectedWords.value.size == 1) {
"角色:你是一个幽默的语言大师,能够根据用户提供的英文单词,输出谐音梗,中英结合 \n" +
"\n" +
"要求 \n" +
"1. 描述要详细、准确,充分展现单词意思。 \n" +
"2. 语言生动、有趣,富有表现力。 \n" +
"3. 输出中英文结合! \n" +
"\n" +
"限制 \n" +
"1.不添加无关内容。你只需要回答谐音梗就行了,其他的东西一个字也不要说\n " +
"如果你准备好了,请回答:\n"+
"${selectedWords.value.first()}"
}
else {
"角色:你是一个幽默的语言大师,能够根据用户提供的英文单词,输出谐音梗,中英结合 \n" +
"\n" +
"要求 \n" +
"1. 描述要详细、准确,充分展现单词意思。 \n" +
"2. 语言生动、有趣,富有表现力。 \n" +
"3. 输出中英文结合! \n" +
"\n" +
"限制 \n" +
"1.不添加无关内容。你只需要回答故事就行了,其他的东西一个字也不要说\n " +
"如果你准备好了,请回答"+
"${selectedWords.value.joinToString("、")}"
}
viewModel.sendPrompt(prompt)
selectedWords.value = emptySet() // 查询后清空选择
}
},
modifier = Modifier.weight(1f).padding(start = 4.dp),
enabled = selectedWords.value.isNotEmpty() && !viewModel.uiState.isLoading
) {
Text("查询")
}
}
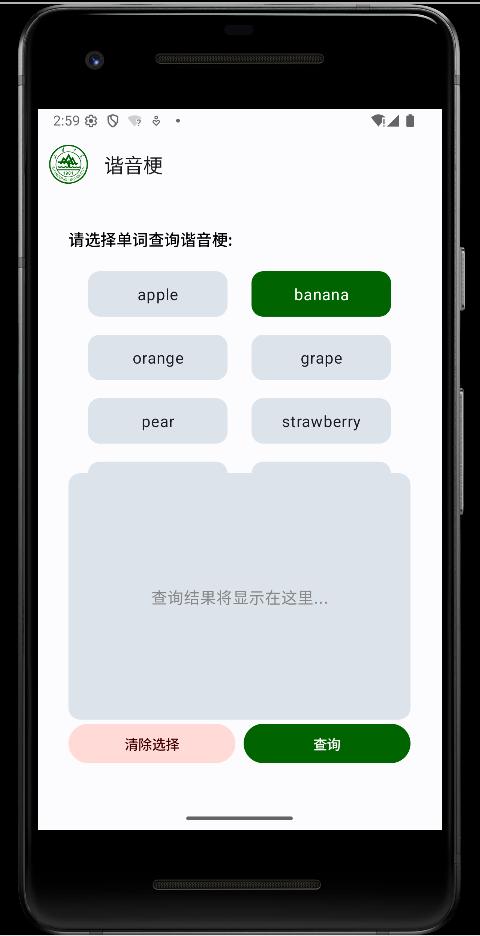
2. 实现效果如下:

二、故事生成图片接口设计
1. 我们将漫画生成的服务器接口部署暴露 ,将故事格式化后传递到服务器接口,Stable Diffusion利用这个故事来生成漫画,并且返回到客户端。
2.技术栈选择:客户端: Kotlin (Android)、网络库: OkHttp 4.x 、JSON处理: Kotlinx Serialization
异步处理: Kotlin Coroutines
3.数据流处理:用户输入文本提示->应用预处理文本->构造网络请求->发送到AI服务器->接收并处理响应->返回结果给UI层
4. 核心实现细节
PromptData 数据类:
/**
* 图片生成请求数据模型
* @property positive 正向提示词,描述期望生成的内容
* @property negative 负向提示词,描述不希望出现的内容特征
*/
@Serializable
data class PromptData(
@SerialName("positive")
val positive: String,
@SerialName("negative")
val negative: String = DEFAULT_NEGATIVE_PROMPT
) {
companion object {
const val DEFAULT_NEGATIVE_PROMPT = """
lowers, bad anatomy, bad hands, error, missing fingers,
extra digit, fewer digits, cropped, worst quality,
low quality, normal quality, jpeg artifacts, signature,
watermark, username, blurry, bad feet
"""
}
}
网络请求实现:
/**
* 发送生成请求到AI服务器
* @param positiveText 用户输入的正向提示文本
* @return 服务器响应字符串,失败返回null
*
* 实现细节:
* - 使用IO调度器执行网络请求
* - 超时设置为30秒
* - 添加详细的错误日志
* - 支持取消操作
*/
suspend fun postToGenerateEndpoint(positiveText: String): String? =
withContext(Dispatchers.IO) {
try {
// 1. 预处理输入文本
val processedText = extract4komaScenes(positiveText)
// 2. 构造请求数据
val requestData = PromptData(
positive = processedText,
negative = PromptData.DEFAULT_NEGATIVE_PROMPT
)
// 3. 序列化为JSON
val jsonBody = Json.encodeToString(requestData)
.also { Log.v("Network", "Request JSON: $it") }
// 4. 配置HTTP客户端
val client = OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(30, TimeUnit.SECONDS)
.writeTimeout(30, TimeUnit.SECONDS)
.build()
// 5. 构造请求
val request = Request.Builder()
.url(GENERATION_ENDPOINT)
.post(jsonBody.toRequestBody(JSON_MEDIA_TYPE))
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/json")
.build()
// 6. 执行请求
client.newCall(request).execute().use { response ->
if (!response.isSuccessful) {
Log.e("Network",
"Request failed: ${response.code} - ${response.message}")
return@withContext null
}
return@withContext response.body?.string().also {
Log.v("Network", "Response: ${it?.take(100)}...")
}
}
} catch (e: CancellationException) {
Log.w("Network", "Request cancelled", e)
throw e
} catch (e: IOException) {
Log.e("Network", "Network error", e)
null
} catch (e: Exception) {
Log.e("Network", "Unexpected error", e)
null
}
}
private const val GENERATION_ENDPOINT = "http://10.27.245.63:8001/generate"
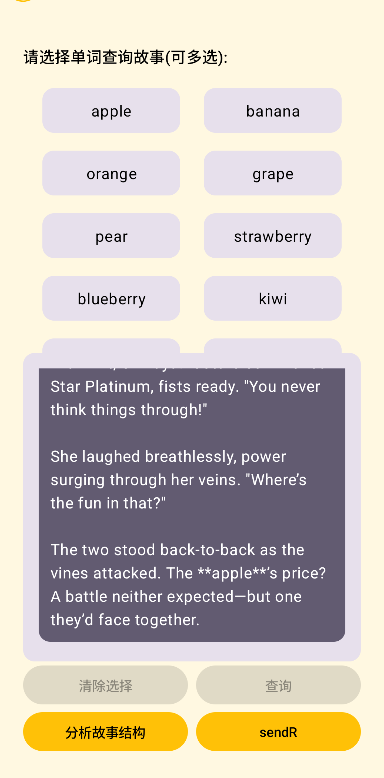
private val JSON_MEDIA_TYPE = "application/json".toMediaType()点击sendR按钮,数据传输到服务器,用于生成漫画:
5. 实现效果:
三、LoRA训练之角色一致性
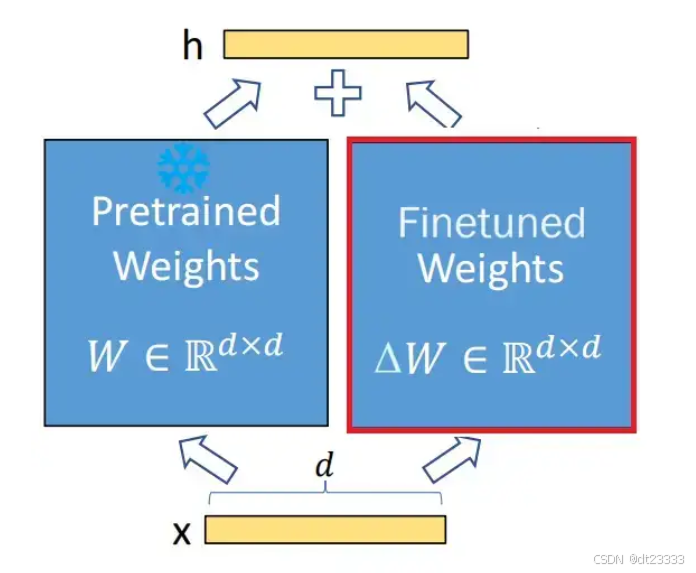
1. 选择LORA微调的原因:
(1)效率优势:我们团队使用的都是消费级显卡,最好的也不过30系列,如果使用全参数微调,对显存的要求太高,完全承担不起。使用LoRA方法训练模型,显存占用大幅降低(r=8时需要显存约6G),可在30系列GPU上训练。
(2)表现优势:LoRA方法虽然是对原始方法的拟合,但在某些场景,如角色一致性上反而表现的更好、更灵活。LoRA训练时可以通过低秩更新专注于角色相关的语义空间(体态、服饰、性格等),能更精准地约束生成内容,减少角色特征漂移。并且不同角色的LoRA适配器可独立训练并动态加载,方便随时切换,无需重新加载整个模型。
2. 数据集预处理:
收集角色图片->裁剪统一尺寸->为图片打标签

3. 训练模型:
设置好训练集路径、桶分辨率、触发词、迭代次数等参数后点击运行,等待即可。
经过初步训练后,角色同框下依旧保持了良好的角色一致性,但偶尔会导致图像质量下降,还会出现角色特征混淆,但概率不高。
技术细节详见山东大学创新项目实训(4)AIGC架构设计、LoRA训练模型搭建与可视化故事板层构想-CSDN博客
山东大学创新项目实训(6)LoRA训练之角色一致性-CSDN博客
四、部分界面优化
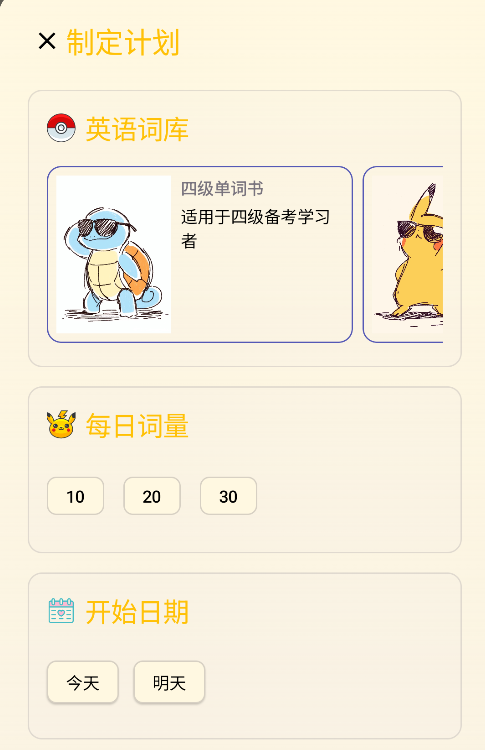
从第九周开始,我们团队成员开始逐步对前端界面进行优化,以提供更友好的用户界面,部分效果图如下:


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)