玩转 DeepSeek-R1 本地部署+知识库搭建+多轮RAG,保姆级教程!
最近,深度求索开源的 DeepSeek-R1 系列模型火遍全球,但因为“服务器繁忙”劝退不少人。为了解决这个问题,我们将以 UltraRAG 框架为例,为大家介绍 DeepSeek-R1 的本地部署流程,同时带领大家熟悉 UltraRAG 的细节和功能。在成功跑通 VanillaRAG 后,我们还简单尝试了在 DeepSeek-R1 加持下的 Adaptive-Note,提出法律领域的问题,效果居
前言
最近,深度求索开源的 DeepSeek-R1 系列模型火遍全球,但因为“服务器繁忙”劝退不少人。为了解决这个问题,我们将以 UltraRAG 框架为例,为大家介绍 DeepSeek-R1 的本地部署流程,同时带领大家熟悉 UltraRAG 的细节和功能。在成功跑通 VanillaRAG 后,我们还简单尝试了在 DeepSeek-R1 加持下的 Adaptive-Note,提出法律领域的问题,效果居然出乎意料地好,有截图为证:
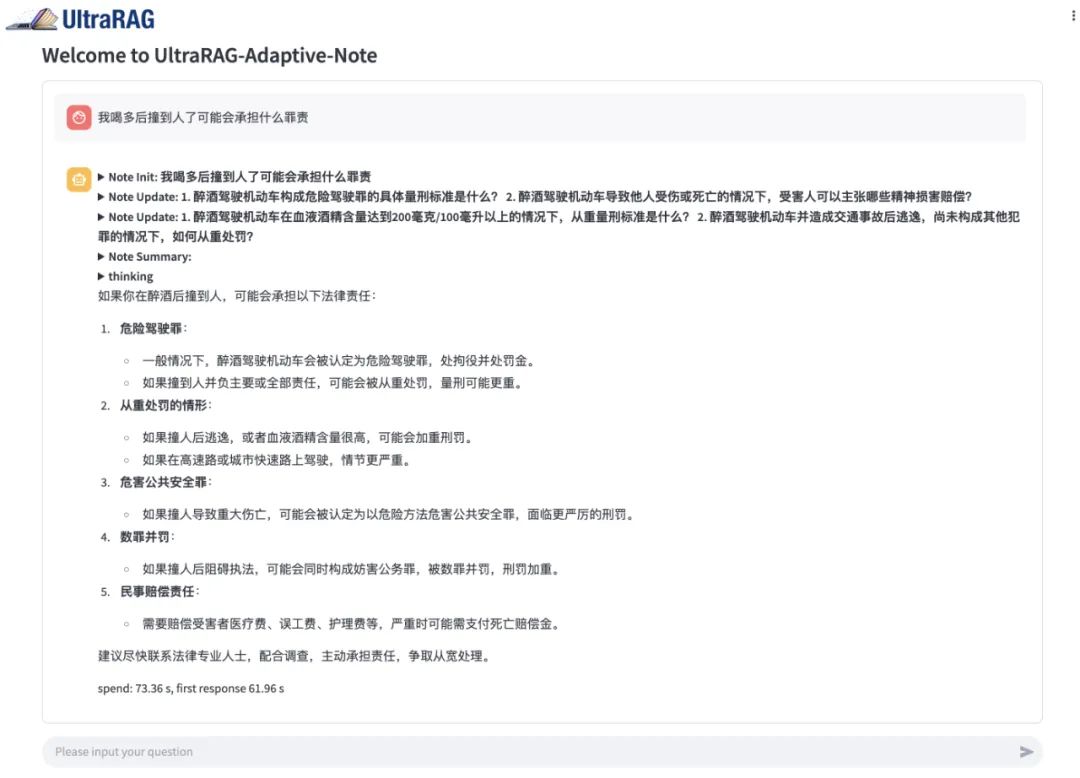
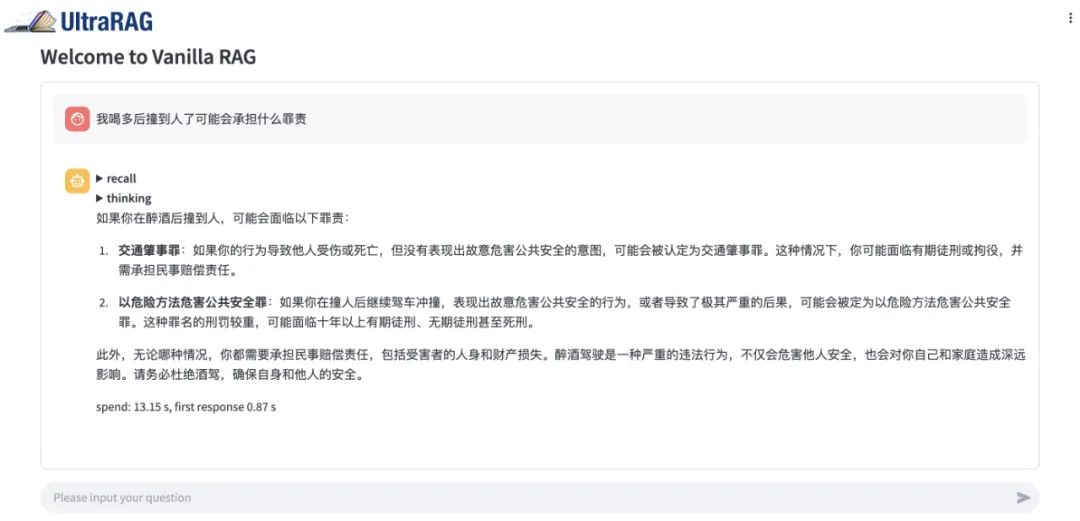
如上图,在 UltraRAG 上对 VanillaRAG 和 Adaptive-Note 分别提问“我喝多后撞了人可能会承担什么罪责?”VanillaRAG 简单直接,分别列出了罪名和建议,内容全面,但是稍微有点不够细致。再看看 Adaptive-Note 的回答,不光总结了可能的几点罪名,并且分析了酒精含量和事后处理态度对量刑和赔偿的影响,引经据典,令人信服。整体来看, Adaptive-Note 的回答更加可信。
VanillaRAG:是最基础的 RAG(Retrieval-Augmented Generation,检索增强生成)架构,通常指的是未经优化或改进的标准 RAG 方法。它的基本流程包括:查询构造(Query Formation)、检索(Retrieval)、生成(Generation)
Adaptive-Note: 一种用于复杂问答任务的自适应笔记增强 RAG 方法,采用 检索-记忆(Retriever-and-Memory) 机制, iteratively 收集和优化知识结构。它通过自适应记忆复审和任务导向生成提高知识交互质量,并采用基于笔记的探索终止策略确保信息充分获取,以提升答案质量。论文: https://arxiv.org/abs/2410.08821
看到这里,我猜大家已经迫不及待想要体验 UltraRAG 了,所以接下来我们将手把手详细介绍 UltraRAG 的部署流程。
硬件环境准备
DeepSeek-R1 的模型有多个蒸馏版本,分别是 7B、14B、70B 以及满血的 671B 版本。权衡了条件和效果后,我们选择 14B 的模型进行部署,以下是运行 UltraRAG 的基本硬件要求:

这里需要注意 nvidia 的显卡驱动需要和 cuda 版本兼容,否则 vllm 运行模型有可能出现报错的情况。如果你的显卡出现不兼容的情况,可以尝试重装驱动和 cuda。这里推荐一个简单好用的安装方法,可以有效避免 cuda 和驱动的不兼容问题:登录 nvidia 官方网站(https://developer.nvidia.com/cuda-toolkit-archive),选择适合 cuda-toolkit 版本安装和安装参数(推荐使用 runfile 方式安装,真的简单好用!)。
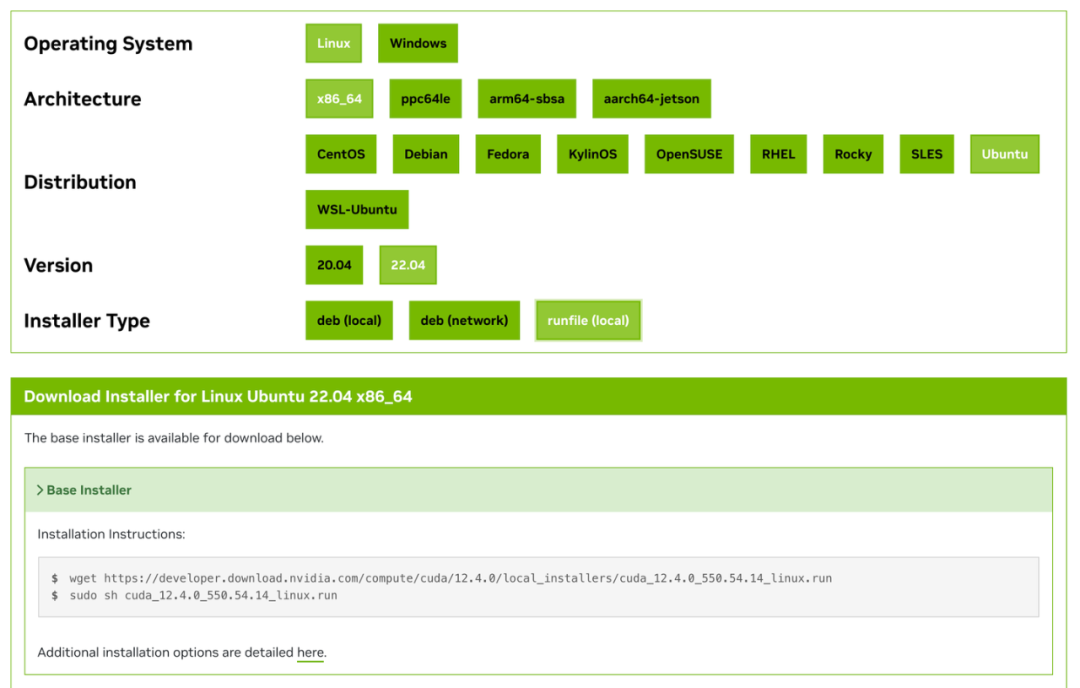 cuda-toolkit参数配置页面
cuda-toolkit参数配置页面
UltraRAG配置
好了,现在你已经拥有了一个稳定的运行环境,可以配置 UltraRAG 了。
运行 UltraRAG 有两种方法,一种通过 docker 运行,这种方式最简单,需要你的机器上已经安装配置好了 nvidia-docker ,并拥有它的运行的权限(一般情况下需要 root 权限)。这种情况下,你只需要执行这行代码就行了:
`docker-compose up --build -d`
如果你的机器上没有 nvidia-docker 也不要紧,可以配置 conda 环境来运行。
要确保你的本地机器安装了 conda,没有的话也可以在这个网址(https://docs.anaconda.com/miniconda/install/)中找到安装的方法,使用普通账户直接安装,几行代码很好执行~
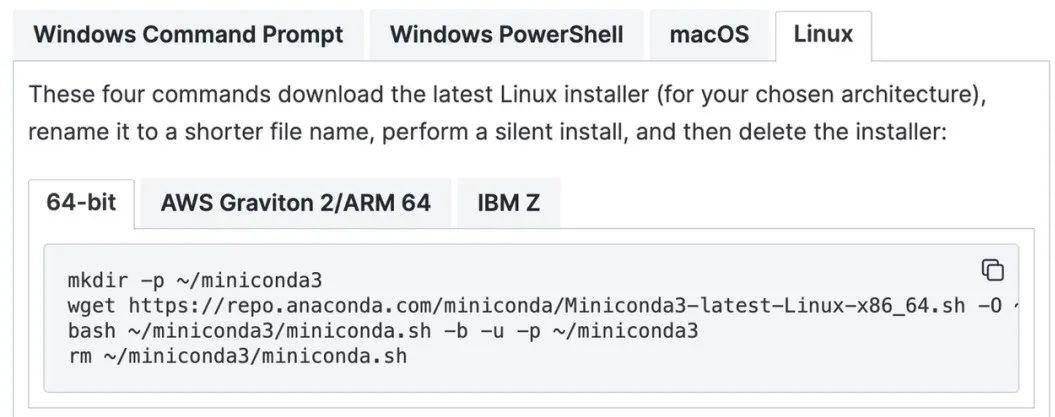
接着,就是在 conda 环境上安装 UltraRAG 的依赖,下面的代码依次执行就好了~
`#创建conda环境conda` `create -n ultrarag python=3.10#激活conda环境conda activate ultrarag安装相关依赖pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple`
以上步骤操作完成之后,环境依赖就准备好了。接下来开始下载模型。
我们需要下载以下 3 个模型,分别执行命令。
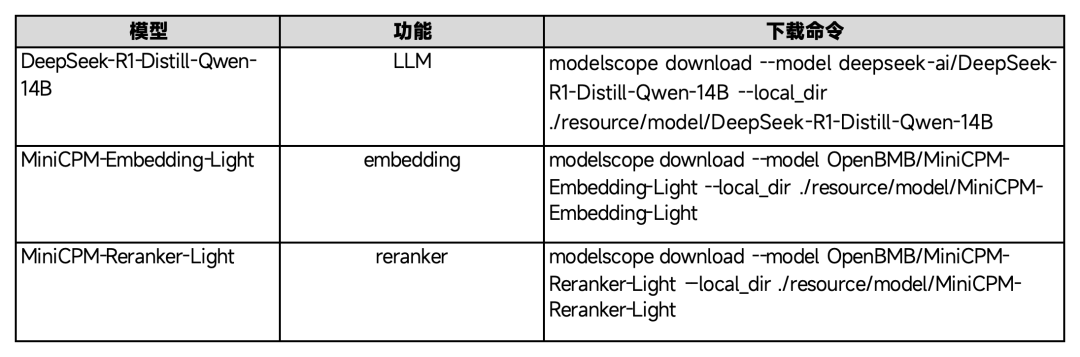
模型下载完成之后,紧接着运行 llm 服务,具体执行这个命令即可~
`vllm serve DeepSeek-R1-Distill-Qwen-14B --gpu-memory-utilization 0.8 --dtype auto --api-key token-abc123`
这里简单说明一下参数的含义:
–gpu-memory-utilization 0.8:表示 GPU 的占用率,显存 80G 时,0.8 意味着最大占用 64GB 的显存。
–dtype auto:表示 vllm 自动选择模型参数类型。
–api-key token-abc123:自定义模型 API 的密钥为 token-abc123。
vllm 服务部署完成后将会启动 OpenAI-Compatibly 的服务,默认参数为:

为了常驻后台,你也可以使用以下命令运行:
nohup vllm serve DeepSeek-R1-Distill-Qwen-14B --gpu-memory-utilization 0.8 --dtype auto --api-key token-abc123 &
好了,现在环境搭好了,模型也下载好了,我们现在来运行 UltraRAG :
`streamlit run ultrarag/webui/webui.py --server.fileWatcherType none`
如果一切顺利,我们会看到下图的结果。这意味着 WebUI 已经跑起来了,我们把 URL 复制到浏览器,应该就能访问页面了,你可以使用 3 个 URL 中的任何一个进行访问:

什么是 UltraRAG?

UltraRAG 框架由清华大学 THUNLP 联合东北大学 NEUIR 、面壁智能团队及 9#AISoft 团队共同提出,基于敏捷化部署与模块化构造,引入了自动化的“数据构建-模型微调-推理评测”知识适配技术体系,提供了一站式、科研与开发双重友好的 RAG 系统解决方案。UltraRAG 显著简化了 RAG 系统在领域适配过程中,从数据构建到模型微调的全流程,助力科研人员与开发者高效应对复杂任务:
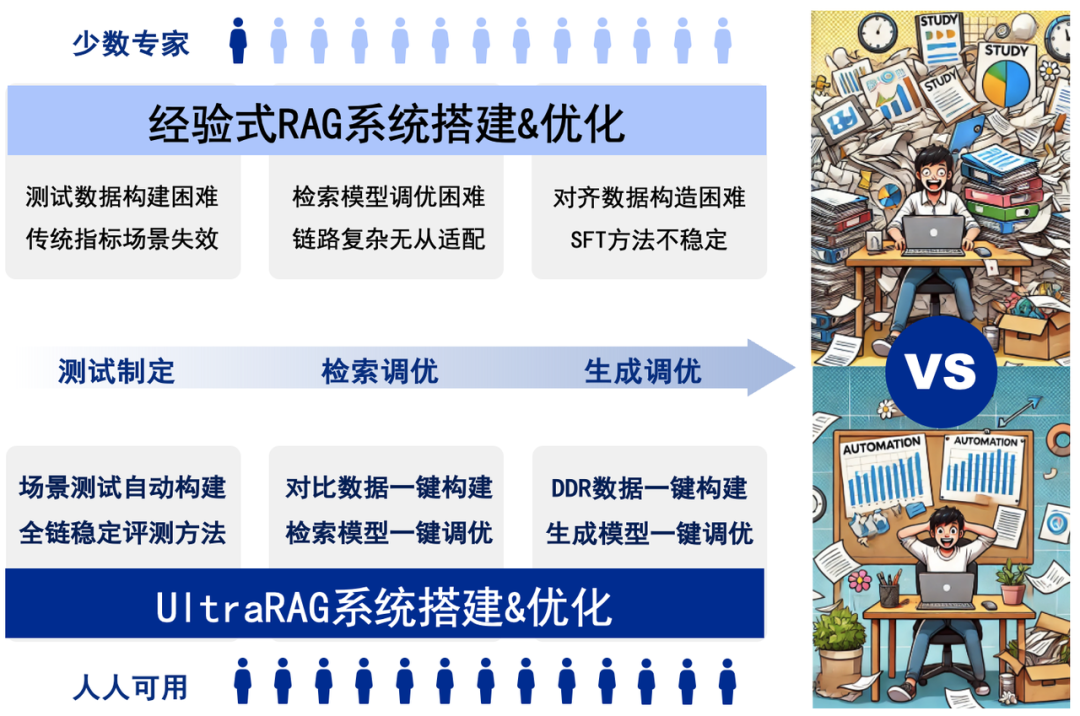
UltraRAG 框架具有以下优势:
零代码编程 WebUI 支持:零编程经验用户亦可上手操作全链路搭建和优化过程,包括多模态 RAG 方案 VisRAG ;
合成与微调一键式解决:以自研 KBAlign、RAG-DDR 等方法为核心,一键式系统化数据构建 + 检索、生成模型多样微调策略支持下的性能优化;
多维多阶段稳健式评估:以自研 RAGEval 方法为核心,融入面向有效/关键信息的多阶段评估方法,显著提升“模型评估”的稳健性;
科研友好探索工作集成:内置 THUNLP-RAG 组自研方法及其他前沿 RAG 方法,支持模块级持续探索与研发。
以上全部功能,都可以直接通过 web 前端快速实现。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
DeepSeek全套安装部署资料

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)