
大模型相关 XSS等 漏洞事件深度剖析
DeepSeek大语言模型系以Transformer架构为基础,自主研发的深度神经网络模型。模型基于注意力机制,通过海量语料数据进行预训练,并经过监督微调、人类反馈的强化学习等进行对齐,构建形成深度神经网络,并增加审核、过滤等安全机制,使算法模型部署后能够根据人类的指令或者提示,实现语义分析、计算推理、问答对话、篇章生成、代码编写等任务。[2]应用于智能对话场景,服务于企业端客户,根据用户输入的文
大语言模型系以Transformer架构为基础,自主研发的深度神经网络模型。模型基于注意力机制,通过海量语料数据进行预训练,并经过监督微调、人类反馈的强化学习等进行对齐,构建形成深度神经网络,并增加审核、过滤等安全机制,使算法模型部署后能够根据人类的指令或者提示,实现语义分析、计算推理、问答对话、篇章生成、代码编写等任务。应用于智能对话场景,服务于企业端客户,根据用户输入的文本数据,通过大语言模型生成符合用户需求的文本、代码等内容。
安全事件回顾
国产大模型自问世以来,一系列由安全漏洞所触发的问题相继暴露,其严重性与潜在后果各不相同。以下,我们将依据严重程度从重到轻的顺序,逐一剖析这些安全事件:
▶︎ 分布式拒绝服务(DDoS)攻击:
2025年1月,大模型刚亮相,便遭遇了前所未有的猛烈DDoS攻击。此次攻击的规模高达3.2Tbps,相当于每秒传输130部4K电影的数据量。这场攻击导致大模型官网瘫痪长达48小时,用户无法完成注册与访问,全球范围内的客户和合作伙伴均受波及,经济损失高达数千万美元。
▶︎ 跨站脚本(XXS)攻击:
在DDoS攻击余波未平之际,大模型又陷入了严重的跨站脚本(XSS)攻击危机。2025年1月31日,研究人员在大模型的CDN端点上发现了一个基于DOM的XSS漏洞,该漏洞源于对postMessage事件处理不当,使得攻击者能够在未进行适当来源验证或输入清理的情况下,将恶意脚本注入文档上下文。这一漏洞可能使攻击者窃取用户敏感信息、破坏用户会话,甚至实施网络钓鱼攻击。
▶︎ ClickHouse数据库泄露:
安全研究人员发现大模型基础设施中的ClickHouse数据库存在重大安全漏洞,暴露了超过100万行包含敏感信息的日志流。
▶︎ 模型中毒攻击:
攻击者利用大模型 API中的漏洞注入对抗样本,意图操纵模型的行为和输出。此类攻击不仅可能产生长期的负面影响,降低模型性能,引入偏见,甚至可能使模型执行恶意代码。而大模型对大型公开数据集的依赖,更是加剧了这一风险,因为攻击者可能会将恶意数据注入这些数据源,从而“毒害”模型。
▶︎ 越狱攻击:
安全研究人员发现大模型的模型存在易受越狱攻击的弱点,模型容易被诱导产生违反其设计初衷或安全准则的输出,这不仅可能生成有害、不当的内容,甚至可能触犯法律。
大模型跨站脚本漏洞回顾
在科技飞速发展的当下,人工智能(AI)工具已深度融入人们的工作与生活,为大家带来诸多便利。大模型 作为一款颇受瞩目的 AI 产品,以其强大的功能赢得了众多用户的青睐。然而,在 2025 年,它却因一场 XSS 漏洞事件陷入舆论漩涡。
此次事件的关键人物是专业白帽黑客 Johann Rehberger。他一直专注于网络安全领域,凭借丰富的经验和敏锐的洞察力,在对 大模型 进行安全检测时,发现了一个严重的 XSS 漏洞。跨站脚本攻击(XSS)对于互联网安全而言,是一种常见且极具威胁的攻击方式。攻击者往往通过巧妙地将恶意脚本注入网页,一旦用户访问该网页,恶意脚本便会在用户浏览器中执行,进而可能窃取用户信息、控制用户设备等。
在 大模型 中,这个漏洞的危害极大。黑客能够利用该漏洞执行 JavaScript(JS)代码。JavaScript 在网页交互中起着核心作用,正常情况下,它能实现网页的各种动态功能,如表单验证、页面元素动态更新等。但在被恶意利用时,它也成为了黑客的有力工具。黑客借助这个 XSS 漏洞执行 JS 代码后,能够获取用户的 cookie。Cookie 对于用户的网络体验至关重要,它存储了用户在网站上的登录状态、偏好设置等关键信息。一旦黑客获取了用户的 cookie,就如同拿到了进入用户账户的钥匙,能够轻而易举地控制用户的账户。他们可以随意查看用户的个人信息、操作记录,甚至冒用用户身份进行各种恶意操作,比如发布不当言论、窃取账户内的虚拟资产等。
这一漏洞的发现,让整个 大模型 用户群体陷入担忧之中。许多用户对自己在 大模型 上的数据安全产生了极大的怀疑,担心个人隐私泄露,更害怕账户资金遭受损失。毕竟,在数字化时代,个人数据和账户安全是用户最为关注的核心问题。
幸运的是,大模型 团队在得知这一漏洞后,迅速做出反应。他们第一时间组织了专业的技术团队,对漏洞展开深入分析和紧急修复。技术人员仔细排查代码,寻找漏洞产生的根源,经过一系列紧张的工作,最终成功修复了该漏洞。这一举措虽然及时,但也让 大模型 团队深刻意识到安全防护工作的重要性和紧迫性。
预防措施
此次 大模型 XSS 漏洞事件,给整个 AI 行业敲响了警钟。随着 AI 技术的广泛应用,越来越多的服务和功能依赖于 AI 系统。然而,AI 系统并非坚不可摧,其安全性同样面临诸多挑战。这一事件提醒开发者,在追求 AI 技术创新和功能完善的同时,绝不能忽视系统的安全性。必须从代码编写的源头开始,加强安全规范,对用户输入进行严格验证和过滤,防止类似 XSS 漏洞的出现。同时,要建立健全的安全监测机制,及时发现并处理潜在的安全隐患,为用户提供一个安全可靠的 AI 使用环境。
其他方面
为防止安全漏洞,大模型 可多管齐下。在代码层面,建立严格的代码审查机制,定期对代码进行安全审计,及时发现并修复潜在漏洞;同时加强对用户输入的验证和过滤,采用白名单机制,只允许符合特定规则的输入,避免恶意脚本注入。在系统层面,及时更新和修补第三方组件和库,确保其处于安全版本;部署 Web 应用防火墙(WAF),实时监测和拦截可疑请求。此外,大模型 还应定期开展安全培训,提高团队成员的安全意识,制定完善的应急响应计划,以便在安全事件发生时能够迅速采取措施,将损失降到最低。
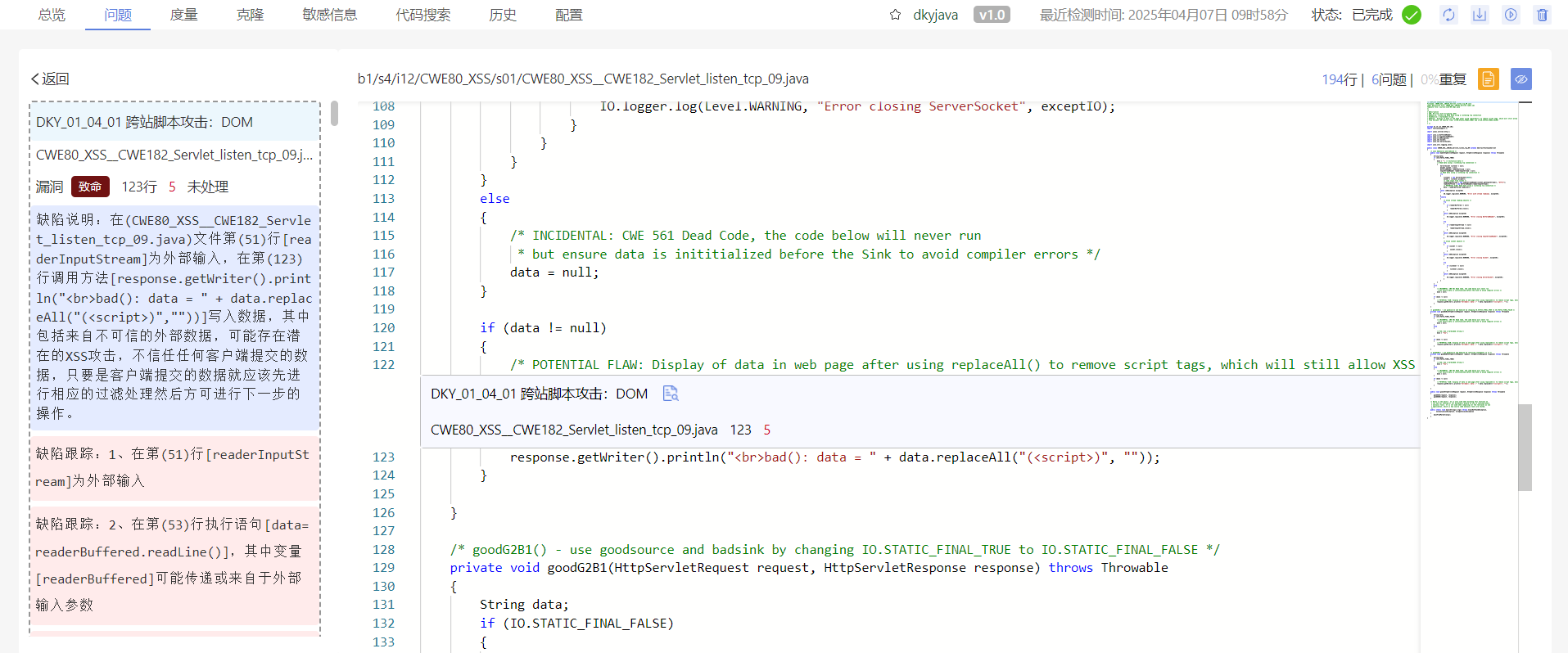
通过库博静态代码分析工具,及时发现软件中的跨站脚本攻击问题。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)