从零开始搞懂大模型:Token、上下文长度和最大输出的故事
举个例子,当你打开 DeepSeek 的会话窗口,开启一个新的对话,然后输入内容,接着模型生成输出内容——这就是一次完整的 **单次推理过程**。在这个简单的一来一回中,所有内容(输入 + 输出)的总 token 数不能超过 64K(约 6 万多字)。在多轮对话中,每次交互的内容都会被累积到 **上下文** 中,作为后续对话的背景信息。这意味着,随着对话的进行,历史内容会占用更多的 token 空
什么是大模型中的 Token?
Token 是大语言模型(LLM)用于表示自然语言文本的基本单元,可以将其理解为“字”或“词”。
一般而言,1 个中文词语、1 个英文单词、1 个数字或 1 个符号均视为 1 个 token。
在大多数模型中,token 与字数的换算比例大致为:
1 个英文字符 ≈ 0.3 个 token;
1 个中文字符 ≈ 0.6 个 token。
因此,可以大致认为一个汉字对应一个 token。
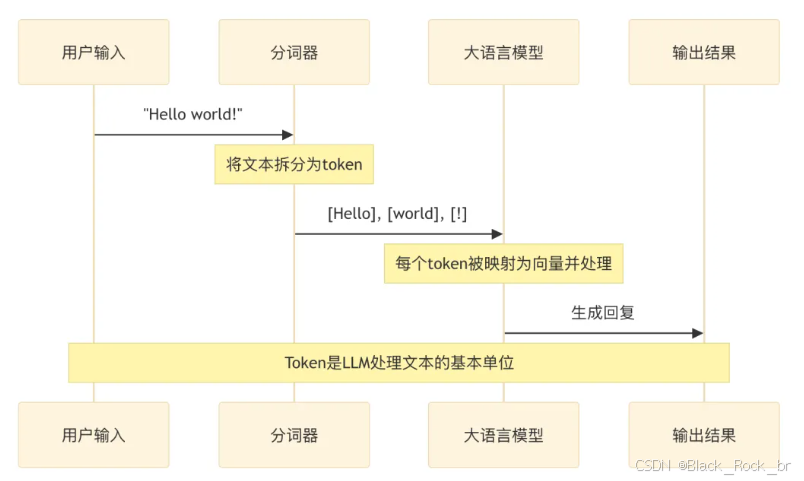
大模型处理输入的过程,首先是将文本转化为 token,接着再对其进行进一步的处理:

最大输出长度
- 为了更清楚地说明,这里以 DeepSeek 为例:
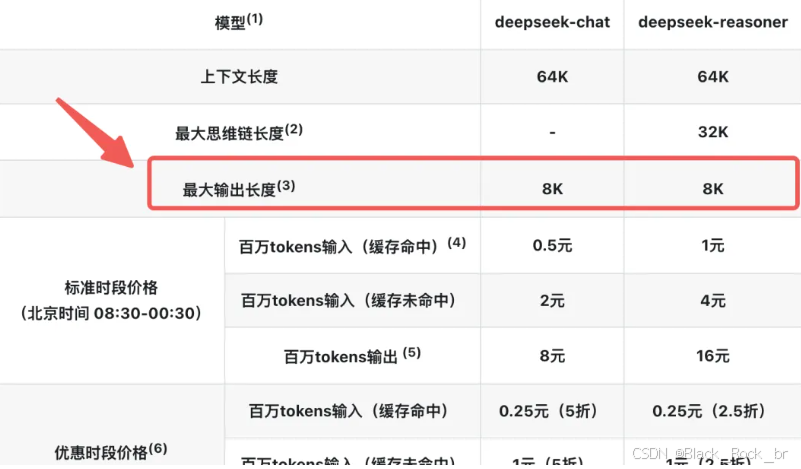
在上图中,DeepSeek 的对话模型 deepseek-chat 对应 DeepSeek-V3,推理模型 deepseek-reasoner 对应 DeepSeek-R1。这两个模型的最大输出长度均为 8K。
由于一个汉字近似等于一个 token,所以 8K 的最大输出长度可以理解为:模型一次输出最多不超过 8000 个字。
这个最大输出长度的概念非常明确,通俗易懂。简单来说,模型每次给出的输出最多 8000 个字,超过这个限制就无法实现了。
上下文长度
在技术领域,通常会用一个专门的术语来描述“上下文长度”,那就是“Context Window”。
以 DeepSeek 为例:
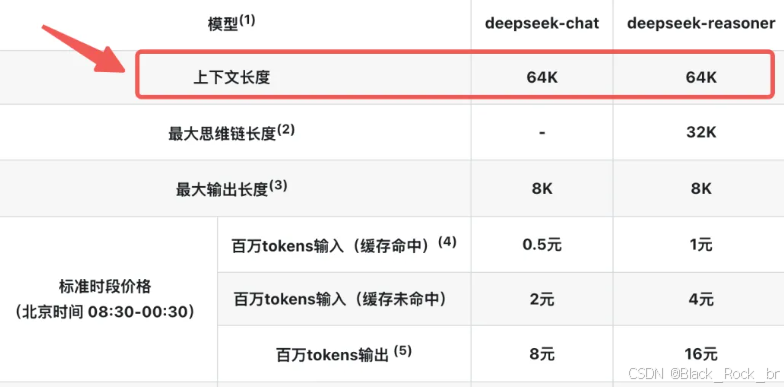
无论是推理模型还是对话模型,DeepSeek 的 **Context Window** 都是 64K。那么,这个 **64K** 到底意味着什么呢?让我们继续深入探讨。
什么是 Context Window?
如果要给 Context Window 下一个定义,可以这样描述:
Context Window** 是指在单次推理过程中,大模型能够处理的全部 token 序列的最大长度。它包括以下两部分:
1. 输入部分:用户提供的提示词、历史对话内容、附加文档等。
2. 输出部分:模型当前正在生成的响应内容。
举个例子,当你打开 DeepSeek 的会话窗口,开启一个新的对话,然后输入内容,接着模型生成输出内容——这就是一次完整的 **单次推理过程**。在这个简单的一来一回中,所有内容(输入 + 输出)的总 token 数不能超过 64K(约 6 万多字)。
输入内容有上限吗?
答案是肯定的。根据上文提到的 “上下文长度”,我们知道模型的最大输出长度为 **8K**。因此,输入内容的上限可以通过简单的计算得出:
64K - 8K = 56K
换句话说,在一次问答中:
- 用户最多可以输入 **5 万多字**(约 56K tokens)。
- 模型最多可以输出 **8 千多字**(约 8K tokens)。
多轮对话呢?每一轮都一样吗?
多轮对话的情况稍有不同。这里我们需要简单介绍一下多轮对话的原理。
在多轮对话中,每次交互的内容都会被累积到 **上下文** 中,作为后续对话的背景信息。这意味着,随着对话的进行,历史内容会占用更多的 token 空间。如果历史对话的 token 数量过多,就会挤占当前输入和输出的可用空间,甚至可能导致超出 **64K** 的限制。
因此,在多轮对话中,每一轮的输入和输出长度都需要动态调整,以确保总 token 数始终在 **64K** 的范围内。这也是为什么在实际使用中,过长的对话可能需要对历史内容进行压缩或截断。
通过以上分析可以看出,**Context Window** 的大小直接影响了模型的对话能力和处理复杂任务的能力。了解这一概念,有助于我们更好地设计输入内容,并充分利用大模型的强大功能。
多轮对话
以 DeepSeek 为例,假设我们通过 API 来调用模型。
在进行多轮对话时,服务器不会保存用户的对话上下文。因此,用户需要在每次请求时,将之前的所有对话历史整合在一起,然后传递给对话 API。
以下是一个示例代码,仅供示意,不必深究:
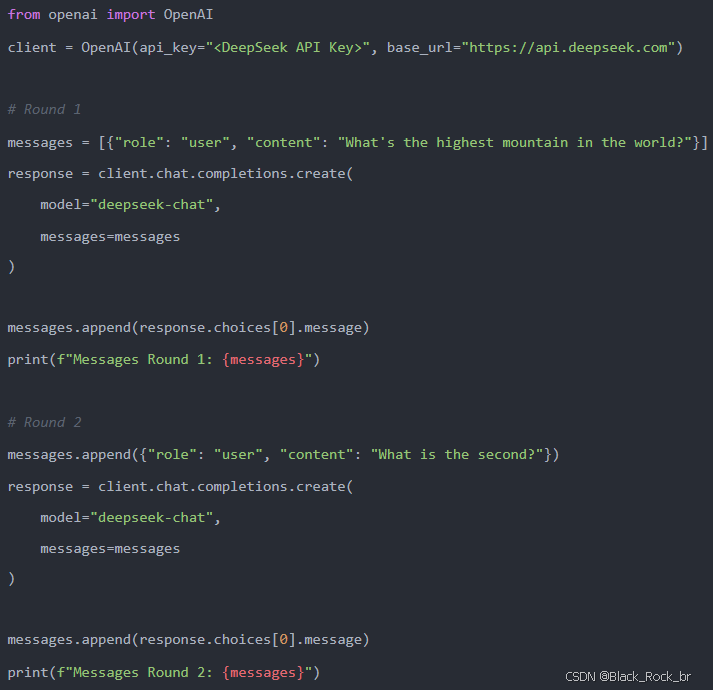
在第一轮请求时,传递给 API 的 messages 为:

当发起第二轮请求时:
- 把第一轮模型的输出结果加入到 messages 的最后。
- 接着,将用户的新增提问也添加到 messages 的末尾。
- 最终,传递给 API 的 messages 将包含前一轮的对话内容和当前的提问,确保上下文的完整性。
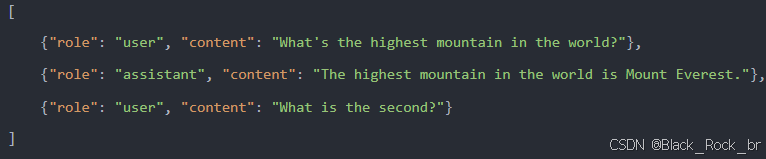
多轮对话的实现原理其实很简单:将历史对话记录(包括用户的输入和模型的输出)与最新的用户输入拼接在一起,然后整体提交给大模型进行处理。
然而,在多轮对话中,**Context Window** 并不是每一轮都能完全使用 64K。随着对话轮次的增加,历史记录会占用越来越多的 token 空间,导致可用的 **Context Window** 越来越小。例如,如果第一轮对话的输入和输出总共占用了 32K 的 token,那么第二轮对话就只剩下 32K 可用。这正是我们之前分析的逻辑。
到这里,你可能会提出一个疑问 🤔 :
按照这个逻辑,如果每轮对话的输入和输出都很长,岂不是很快就会超出模型的上下文长度限制,导致无法继续对话?但实际情况是,无论对话进行多少轮,模型似乎总能正常响应并生成内容。这是为什么呢?
这是一个非常棒的问题!答案涉及到另一个重要的概念——**上下文截断**。
上下文截断
用户并非直接面对硬性限制,而是通过“上下文截断”策略来实现“超长文本处理”。
举个例子,假设模型原生支持的最大上下文长度为 64K。当用户的累计输入加上输出已经达到了 64K,如果用户再次发起请求(比如输入了 2K 的内容),就会超出限制。此时,服务端会采取措施,仅保留最后 64K 的 tokens 供模型参考,而之前的 2K 内容则被丢弃。从用户的角度来看,他们最近输入的内容被保留了下来,而最早输入的内容(甚至包括之前的输出)则被丢弃了。
这就是为什么在进行多轮对话时,虽然模型仍然能够给出响应,但会出现“失忆”的情况。原因很简单,Context Window 的容量有限,模型只能记住后面的内容,而忘记前面的内容。
需要注意的是,“上下文截断”是一种工程层面的策略,而非模型本身具备的能力。我们在使用过程中感觉不到这个过程,是因为服务端隐藏了截断的具体操作。

上下文窗口(例如 64K)是模型处理单次请求时的硬性限制,输入和输出的总和不能超过这个数值;
服务端通过截断历史 tokens 来实现上下文窗口的扩展,从而允许用户在多轮对话中突破 Context Window 的限制,但这会牺牲模型的长期记忆能力。
上下文窗口的限制是服务端出于成本控制或风险考虑而设置的策略,与模型本身的能力无关。
不同模型的参数比较
不同厂商对模型的最大输出长度和上下文长度有不同的设计思路。下面,我们以 OpenAI 和 Anthropic 为例,对其参数设置进行简要分析:

在上图中,Context Tokens 指的是上下文长度,而 Output Tokens 则表示最大输出长度。
技术原理
这些限制的存在,从技术角度来看是由模型架构和计算资源的多方面因素决定的。虽然深入探讨其原理较为复杂,但我们可以用简单的语言来概述。如果你对某些关键词感兴趣,可以顺着这些线索进一步探索。
在模型架构层面,-上下文窗口- 是一个硬性约束,主要由以下几个关键因素决定:
1. 位置编码的范围:
Transformer 模型依赖位置编码(如 RoPE、ALiBi 等)为每个 token 分配位置信息。然而,位置编码的设计范围是有限的,这直接决定了模型能够处理的最大序列长度。如果序列长度超出位置编码的范围,模型将无法正确解析 token 的顺序信息。
2. 自注意力机制的计算开销:
在生成每个新 token 时,模型需要通过自注意力机制计算它与所有历史 token(包括输入和已生成的输出)之间的关系权重。随着序列长度的增加,这种计算的复杂度会迅速上升,显存占用也会成比例增长。一旦总序列长度超过上下文窗口的限制,就可能导致显存溢出或计算错误。
3. KV Cache 的显存占用:
在推理过程中,模型会使用 KV Cache(键值缓存)来存储历史 token 的注意力计算结果,以加速生成过程。然而,KV Cache 的显存占用与总序列长度成正比。如果序列过长,显存需求会急剧增加,超出硬件的承受能力,从而导致性能问题或失败。
综上所述,这些限制并非随意设定,而是由模型的核心架构和硬件资源的约束共同决定的。
常见场景及解决方法
既然我们已经了解了最大输出长度和上下文长度的概念,以及它们背后的逻辑和原理,那么在使用大模型工具时,就需要制定相应的使用策略,以提高效率和效果。
短输入 + 长输出
- 场景:输入 1K tokens,希望生成较长的内容。
- 配置:将 max_tokens 设置为 63,000(需确保 1K + 63K ≤ 64K)。
- 风险:生成的输出可能因内容质量检测(例如重复性、敏感词等)而提前终止。
长输入 + 短输出
- 场景:输入 60K tokens 的文档,要求生成摘要。
- 配置:将 max_tokens 设置为 4,000(60K + 4K ≤ 64K)。
- 风险:如果实际输出需要更多的 tokens,可能需要压缩输入(例如提取关键段落)。
多轮对话管理
- 规则:历史对话的累计输入 + 输出总和 ≤ 64K(超出部分将被截断)。
- 示例:
- 第1轮:输入 10K + 输出 10K → 累计 20K
- 第2轮:输入 30K + 输出 14K → 累计 64K
- 第3轮:新输入 5K → 服务端丢弃最早的 5K tokens,保留最后 59K 历史 + 新输入 5K = 64K。
通过这些策略,我们可以更好地利用大模型的能力,同时避免因超出限制而导致的问题。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 1
1- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)