3分钟读懂RAGFlow:从 0 到 1教你搭建RAG知识库
RAGFlow 的基础使用方法,从演示效果来看尚可。然而,在实际应用场景中,各类文件格式与结构各不相同,文件解析成为一大难题。一旦解析不准确,即便使用性能强劲的 Deepseek-R1 大模型(经亲测),也会出现分析错误的情况。因此,在 RAG 过程中,文件解析、Embedding 以及 LLM 是提升准确率的三大关键攻克点。
更多AI大模型应用开发学习内容,尽在聚客AI学院。
1. RAGFlow概述
RAGFlow是基于检索增强生成(Retrieval-Augmented Generation)技术的开源知识库解决方案,能够快速将非结构化文档(PDF、Word、Markdown等)转化为可检索的知识库,并通过大模型实现精准问答。其核心优势包括:
-
自动文本解析:支持复杂格式文档(表格、公式、代码块)的智能解析;
-
精准检索:结合语义匹配和关键词检索,提升上下文相关性;
-
可视化流程:从文档预处理到问答测试全流程图形化操作。
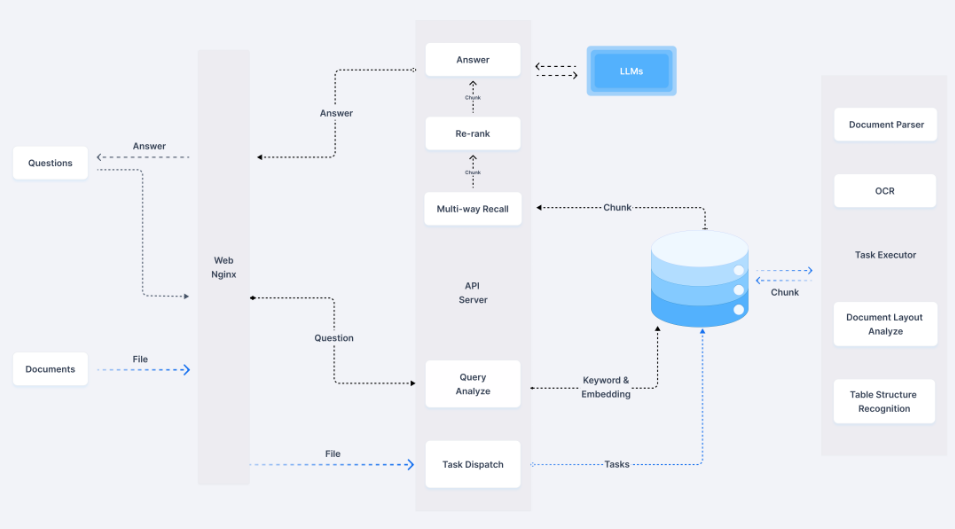
2. 环境准备与系统搭建
2.1 环境需求

2.2 安装
通过Docker一键部署:
# 拉取最新镜像
docker pull infiniflow/ragflow:latest
# 启动容器(GPU版本需附加--gpus all参数)
docker run -d --name ragflow \
-p 8000:8000 \
-v /data/ragflow:/var/ragflow \
infiniflow/ragflow访问 http://localhost:8000 进入登录界面
3. 应用实践
3.1 注册账号
-
点击首页"Sign Up"进入注册页面
-
输入邮箱、密码(需包含大小写字母+数字)
-
验证邮箱后完成注册
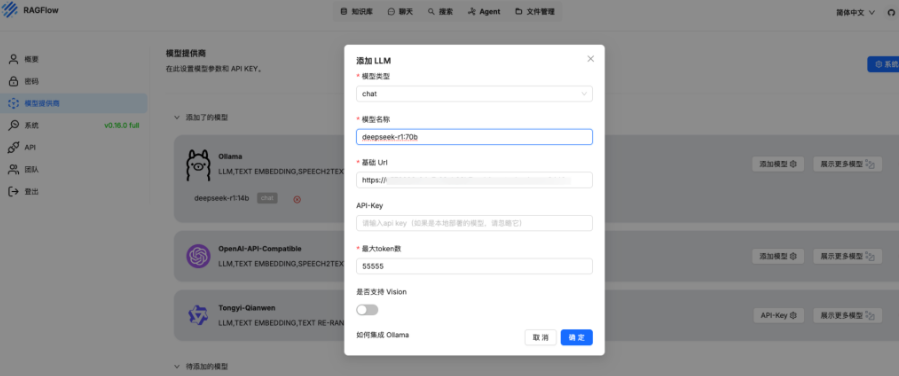
3.2 添加模型
进入模型管理 > 新增模型:
-
本地模型:指定模型路径(如/opt/llama2-13b)
-
API模型:填写OpenAI/Gemini等API密钥
-
参数设置:调整temperature、max_tokens等生成参数
-
-
3.3 创建知识库
-
点击知识库 > 新建知识库
-
上传文档(支持批量上传)
-
配置解析规则:
-
分块大小:建议512-1024 tokens
-
元数据提取:自动识别作者、日期等字段
-
-
启动文档解析(等待进度条完成)
4. 验证效果
检索分析
查看检索日志:
-
命中的文档片段
-
相关性评分
-
大模型改写后的查询语句
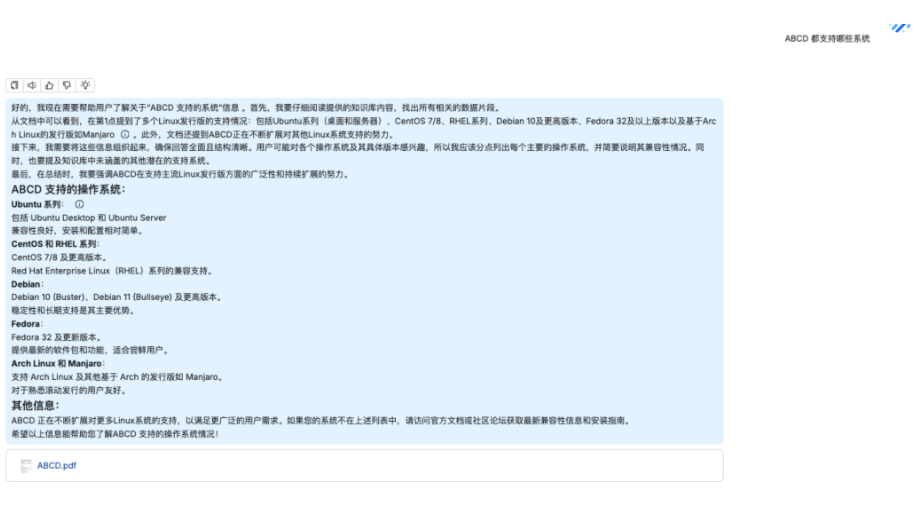
- 原文档:

- 本文介绍了 RAGFlow 的基础使用方法,从演示效果来看尚可。然而,在实际应用场景中,各类文件格式与结构各不相同,文件解析成为一大难题。一旦解析不准确,即便使用性能强劲的 Deepseek-R1 大模型(经亲测),也会出现分析错误的情况。因此,在 RAG 过程中,文件解析、Embedding 以及 LLM 是提升准确率的三大关键攻克点。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)