基于GRPO将QWEN训练为和deepseek一样的推理模型!
群体相对策略优化(GRPO)算法最初由deepseek团队提出,是近端策略优化(PPO)的一个变体。GRPO 是一种在线学习算法,它通过使用训练过程中已训练模型自身生成的数据进行迭代改进。GRPO 目标背后的逻辑是在确保模型与参考策略保持接近的同时,最大化生成的completion的优势。DeepSeek团队在使用纯强化学习 训练 R1-Zero 时观察到了一个“aha moment”。该模型学会
GRPO
群体相对策略优化(GRPO)算法最初由deepseek团队提出,是近端策略优化(PPO)的一个变体。
GRPO 是一种在线学习算法,它通过使用训练过程中已训练模型自身生成的数据进行迭代改进。GRPO 目标背后的逻辑是在确保模型与参考策略保持接近的同时,最大化生成的completion的优势。
DeepSeek团队在使用纯强化学习 训练 R1-Zero 时观察到了一个“aha moment”。该模型学会了通过重新评估其初始方法来延长其思考时间,而无需任何人工指导或预定义指令。
-
该模型将生成多个响应
-
每个响应都根据正确性或由某奖励函数而不是 LLM 奖励模型创建的另一个指标进行评分
-
计算该组的平均分数
-
将每个响应的分数与组平均值进行比较
-
该模型经过强化,有利于得分较高的响应
例如,假设我们想要一个模型来求解:
1+1=?>> 思维链/解决 >> 答案是 2.
2+2=?>> 思维链/解决 >> 答案是 4.
以前必须收集大量数据来填充锻炼/思维链过程。但是GRPO可以引导模型自动展示推理功能并创建推理跟踪。
构建聊天模板
提示模型在提供答案之前阐明其推理。需要先将提示和响应建立一个明确的格式。
# system prompt
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""数据集
选择OpenAI的 GSM8K 数据集,其中包含小学数学问题,每个答案都会有一个推理过程,并在 “####”后面附上最终答案。(该数据集在诸多论文中出现过)
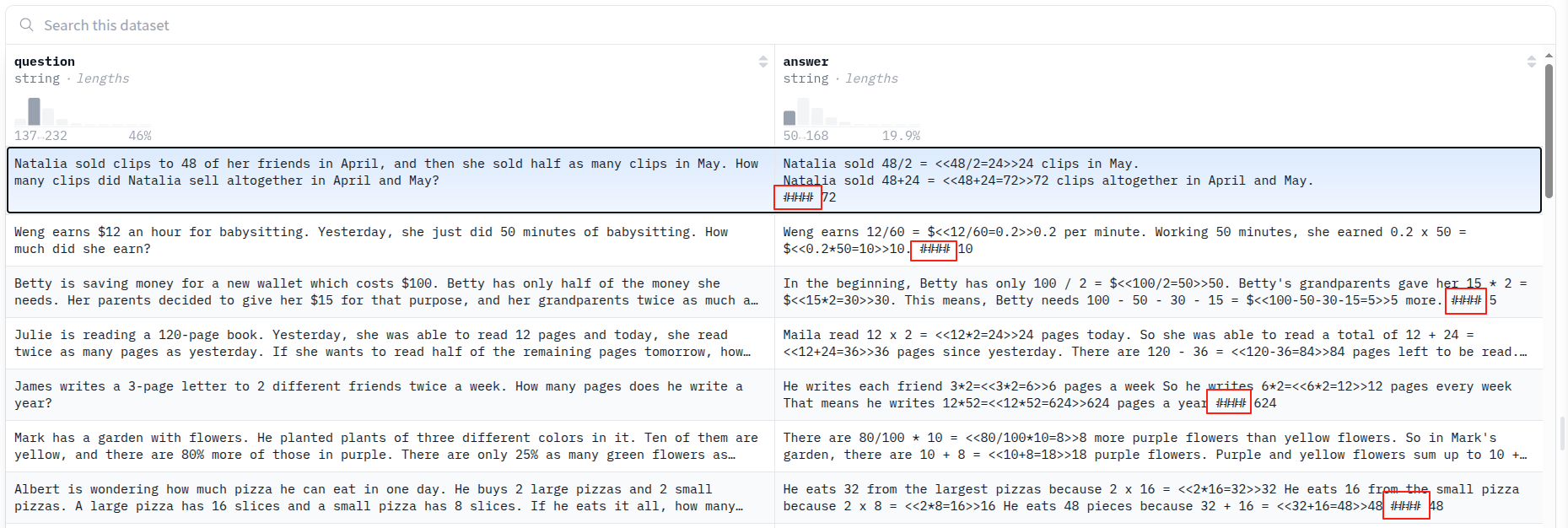
数据集是通过提取答案并将其格式化为结构化字符串来准备的
# 准备数据集
import re
from datasets import load_dataset, Dataset
# 提取推理过程
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
# 提取最终答案
def extract_hash_answer(text: str) -> str | None:
if "####" not in text:
return None
return text.split("####")[1].strip()
# 准备GSM8K数据集
def get_gsm8k_questions(split="train") -> Dataset:
data = load_dataset("openai/gsm8k", "main")[split]
data = data.map(
lambda x: {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": x["question"]},
],
"answer": extract_hash_answer(x["answer"]),
}
)
return data
dataset = get_gsm8k_questions()奖励函数
func1,依据模型生成的回复与标准答案的匹配状况来给出奖励分数。若回复和标准答案一致,就给予 2.0 的奖励;若不一致,则给予 0.0 的奖励
# 奖励标签完全匹配
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses = [extract_xml_answer(r) for r in responses]
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
func2,根据模型生成的回复是否为整数来给予奖励分数。若回复是一个整数形式的字符串,就给予 0.5 的奖励;若不是,则给予 0.0 的奖励
# 鼓励仅使用整数的答案
def int_reward_func(completions, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]func3,检查模型生成的回复是否符合特定的格式要求。如果回复符合格式要求,则给予 0.5 的奖励;如果不符合,则给予 0.0 的奖励。
# 确保响应结构与提示匹配,包括换行符
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]func4,检查模型生成的回复是否符合特定的格式要求。若回复符合格式,就给予 0.5 的奖励;若不符合,则给予 0.0 的奖励。与之前的 strict_format_reward_func 相比,它的格式匹配要求没那么严格。
# 检查结构,但允许轻微的换行符不匹配
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]func5,检查文本中 <reasoning>、</reasoning>、<answer> 和 </answer> 存在与否,并根据其出现情况进行控分;同时根据 </answer> 之后的文本长度扣分
# 确保响应中的每个 XML 标签中只有一个,同时根据长度扣分
def count_xml(text) -> float:
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1])*0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001
return count
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]加载模型
选择Qwen-2.5-3B-Instruct模型,非推理模型
from unsloth import FastLanguageModel, is_bfloat16_supported
import torch
max_seq_length = 1024 # Can increase for longer reasoning traces
lora_rank = 64 # Larger rank = smarter, but slower
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "Qwen/Qwen2.5-3B-Instruct",
max_seq_length = max_seq_length,
load_in_4bit = True, # False for LoRA 16bit
fast_inference = True, # Enable vLLM fast inference
max_lora_rank = lora_rank,
gpu_memory_utilization = 0.5, # Reduce if out of memory
)
LORA配置
model = FastLanguageModel.get_peft_model(
model,
r = lora_rank, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
], # Remove QKVO if out of memory
lora_alpha = lora_rank,
use_gradient_checkpointing = "unsloth", # Enable long context finetuning
random_state = 3407,
)GRPO配置
Transformer 强化学习(TRL)是一个全栈库,提供了一套工具,可使用诸如监督微调(SFT)、组相对策略优化(GRPO)、直接偏好优化(DPO)、奖励建模等方法来训练基于 Transformer 的语言模型。TRL已与Transformers库集成
use_vllm参数需要使用vllm库,vllm用于加速模型推理,其官方宣称吞吐量比HF的transformer 高 24 倍 ,无需更改任何模型架构。
from trl import GRPOConfig, GRPOTrainer
training_args = GRPOConfig(
use_vllm = True, # use vLLM for fast inference!
learning_rate = 5e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.1,
lr_scheduler_type = "cosine",
optim = "adamw_8bit",
logging_steps = 1,
bf16 = is_bfloat16_supported(),
fp16 = not is_bfloat16_supported(),
per_device_train_batch_size = 1,
gradient_accumulation_steps = 1, # Increase to 4 for smoother training
num_generations = 8, # Decrease if out of memory
max_prompt_length = 256,
max_completion_length = 200,
# num_train_epochs = 1, # Set to 1 for a full training run
max_steps = 250,
save_steps = 250,
max_grad_norm = 0.1,
report_to = "none", # Can use Weights & Biases
output_dir = "outputs",
)开始训练
一块Tesla T4 GPU的训练耗时为1h出头(博主实测)。
trainer = GRPOTrainer(
model = model,
processing_class = tokenizer,
reward_funcs = [
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func,
],
args = training_args,
train_dataset = dataset,
)
trainer.train()测试评估
先加载之前的模型
text = tokenizer.apply_chat_template([
{"role" : "user", "content" : "How many r's are in strawberry?"},
], tokenize = False, add_generation_prompt = True)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
[text],
sampling_params = sampling_params,
lora_request = None,
)[0].outputs[0].text
在加载训练后的模型
#
model.save_lora("grpo_saved_lora")
text = tokenizer.apply_chat_template([
{"role" : "system", "content" : SYSTEM_PROMPT},
{"role" : "user", "content" : "How many r's are in strawberry?"},
], tokenize = False, add_generation_prompt = True)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
text,
sampling_params = sampling_params,
lora_request = model.load_lora("grpo_saved_lora"),
)[0].outputs[0].text
print(output)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)