【RAG 实战】用 StarRocks + DeepSeek 构建智能问答与企业知识库
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合外部知识检索与 AI 生成的技术,弥补了传统大模型知识静态、易编造信息的缺陷,使回答更加准确且基于实时信息。
一、RAG 和向量索引简介
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合外部知识检索与 AI 生成的技术,弥补了传统大模型知识静态、易编造信息的缺陷,使回答更加准确且基于实时信息。
1、 RAG 的核心流程
1.1 检索(Retrieval)
- 用户输入问题后,RAG 从外部数据库(如维基百科、企业文档、科研论文等)检索相关内容。
- 检索工具可以是向量数据库、搜索引擎或传统数据库。
1.2 生成(Generation)
- 将检索到的相关信息与用户输入一起输入生成模型(如 GPT、LLaMA 等),生成更准确的回答。
- 模型基于检索内容“增强”输出,而非仅依赖内部参数化知识。
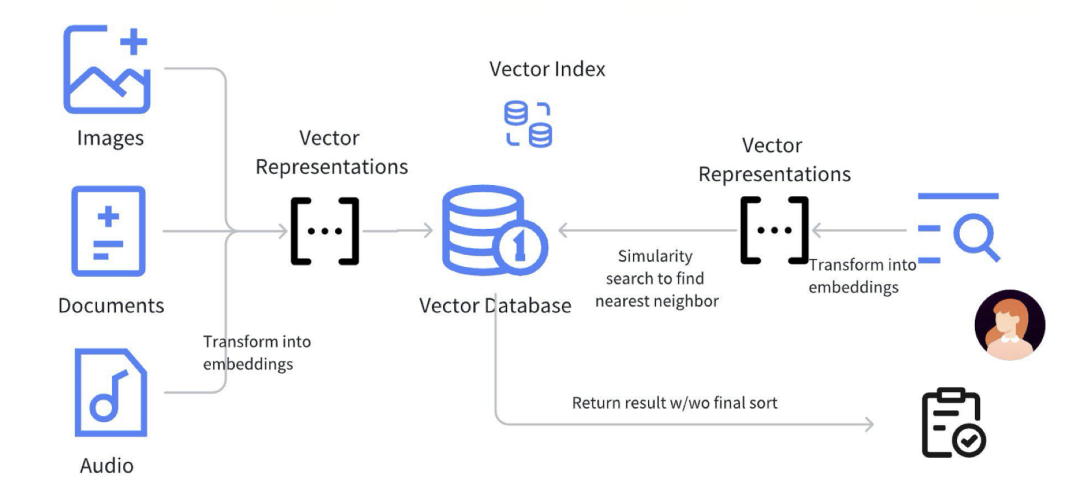
上图展示了 RAG 的标准流程。首先,图片、文档、视频和音频等数据经过预处理,转换为 Embedding 并存入向量数据库。Embedding 通常是高维 float 数组,借助向量索引(如 HNSW、IVF)进行相似性搜索,加速高效检索。
向量索引通过近似最近邻(ANN)算法优化查询效率,减少高维计算负担。语义搜索匹配用户问题与知识库中的相关内容,使回答基于真实信息,从而降低大模型的“幻觉”风险,提升回答的自然性和可靠性。
二、 StarRocks + DeepSeek 的典型 RAG 应用场景
DeepSeek 负责生成高质量 Embedding 和回答,StarRocks 提供实时高效的向量检索,二者结合可构建更智能、更精准的 AI 解决方案。
1、 企业级知识库
适用场景:
- 企业内部知识库(文档搜索、FAQ)
- 法律、金融、医药等专业领域问答
- 代码搜索、软件开发文档查询
方案:
-
文档嵌入(DeepSeek 负责): 将企业知识库、FAQ、技术文档等数据转换为向量。
-
存储+索引(StarRocks 负责): 使用 HNSW 或 IVFPQ 存储向量存储在 StarRocks 中,支持高效检索。
-
检索增强生成(RAG 负责): 用户输入问题 → DeepSeek 生成查询向量 → StarRocks 进行向量匹配 → 返回相关文档 → DeepSeek 结合文档生成最终回答。
2、 AI 客服与智能问答
适用场景:
- 智能客服(银行、证券、电商)
- 法律、医疗等专业咨询
- 技术支持自动问答
方案:
- 客户对话日志嵌入(DeepSeek 负责): 训练 LLM 处理用户意图,转换历史聊天记录为向量。
- 存储+索引(StarRocks 负责): 采用向量索引让客服系统能够高效查找相似案例。
- 检索增强(RAG 负责): 结合历史客服对话 + 知识库 + DeepSeek LLM 生成答案。
示例流程:
- 用户问:“我如何更改银行卡预留手机号?”
- StarRocks 检索到 3 个最相似的客户服务记录
- DeepSeek 结合这 3 条历史记录 + 预设 FAQ,生成精准回答
三、操作演示
1、 系统组成
- DeepSeek:提供文本向量化(embedding)和答案生成能力
- StarRocks:高效存储和检索向量数据(3.4+版本支持向量索引)
2、实现流程
| 步骤 | 负责组件 | 具体实现 |
|---|---|---|
| 1. 环境准备 | OllamaStarRocks | 用 Ollama 在本地机器上便捷地部署和运行大型语言模型 |
| 2. 数据向量化 | DeepSeek-Embedding | 文本 → 3584 维向量 |
| 3. 存储向量 | StarRocks | 创建表,存入向量 |
| 4. 近似最近邻搜索 | StarRocks 向量索引 | IVFPQ / HNSW 检索 |
| 5. 检索增强 | 模拟 RAG 逻辑 | 结合检索数据 |
| 6. 生成答案 | DeepSeek LLM | 生成基于真实数据的回答 |
3、环境准备
3.1 DeepSeek 本地部署
Tips: 以下内容使用的是 macbook 进行 demo 演示
3.1.1 使用 ollama 安装本地模型
在本地部署 DeepSeek 时,Ollama 主要起到模型管理和提供推理接口的作用,支持运行多个不同的 LLM,并允许用户在本地切换和管理不同的模型。
- 下载 ollama:https://ollama.com/
- 安装 deepseek-r1:7b
# 该命令会自动下载并加载模型
ollama run deepseek-r1:7b

Tips: 如果想使用云端 LLM(如 DeepSeek 的官方 API),需要获取并填写 API Key
访问 DeepSeek 官网(https://platform.deepseek.com)后注册账号并登录;在仪表盘中创建 API Key(通常在 “API Keys” 或 “Developer” 部分),复制生成的密钥(如 sk-xxxxxxxxxxxxxxxx)。
3.1.2 Deepseek 初步使用
启动 deepseek
执行 ollama run deepseek-r1:7b 直接进入交互模式
3.1.3 Deepseek 性能优化
直接在命令行设置参数:(参数单次生效)
OLLAMA_GPU_LAYERS=35 \
OLLAMA_CPU_THREADS=6 \
OLLAMA_BATCH_SIZE=128 \
OLLAMA_CONTEXT_SIZE=4096 \
ollama run deepseek-r1:7b
3.1.4 DeepSeek 使用

显而易见:直接使用 deepseek 进行问答,返回的答案是不符合预期的,需要对知识进行修正
3.2 StarRocks 准备工作
3.2.1 集群部署
版本需求:3.4 及以上
3.2.2 配置设置
打开 vector index
ADMIN SET FRONTEND CONFIG ("enable_experimental_vector" = "true");
3.2.3 建库建表
建库:
create database knowledge_base;
建表:存储知识库向量
CREATE TABLE enterprise_knowledge (
id BIGINT AUTO_INCREMENT,
content TEXT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX vec_idx (embedding) USING VECTOR (
"index_type" = "hnsw",
"dim" = "3584",
"metric_type" = "l2_distance",
"M" = "16",
"efconstruction" = "40"
Tips: DeepSeek 的 deepseek-r1:7b 模型(7B 参数版本)默认生成高维嵌入向量,通常是 3584 维
4、将文本转成向量
测试通过 deepseek 将文本转为 3584 维向量
curl -X POST http://localhost:11434/api/embeddings -d '{"model": "deepseek-r1:7b", "prompt": "产品保修期是一年。"}'
下面将转化的向量数据保存在 StarRocks 中
5、 知识存储(存储向量到 StarRocks)
import pymysql
import requests
def get_embedding(text):
url = "http://localhost:11434/api/embeddings"
payload = {"model": "deepseek-r1:7b", "prompt": text}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()["embedding"]
try:
content = "StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。"
embedding = get_embedding(content)
# 将 Python 列表转换为 StarRocks 的数组格式
embedding_str = "[" + ",".join(map(str, embedding)) + "]"# 例如:[0.1,0.2,0.3]
conn = pymysql.connect(
host='X.X.X.X',
port=9030,
user='root',
password='sr123456',
database='knowledge_base'
)
cursor = conn.cursor()
# 使用格式化的数组字符串
sql = "INSERT INTO enterprise_knowledge (content, embedding) VALUES (%s, %s)"
cursor.execute(sql, (content, embedding_str))
conn.commit()
print(f"Inserted: {content} with embedding {embedding[:5]}...")
except requests.RequestException as e:
print(f"Embedding API error: {e}")
except pymysql.Error as db_err:
print(f"Database error: {db_err}")
finally:
if'cursor'in locals():
cursor.close()
if'conn'in locals():
conn.close()
操作演示
6、 知识提取
import pymysql
import requests
# 获取嵌入向量的函数
def get_embedding(text):
url = "http://localhost:11434/api/embeddings"
payload = {"model": "deepseek-r1:7b", "prompt": text}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()["embedding"]
# 从 StarRocks 查询相似内容的函数
def search_knowledge_base(query_embedding):
try:
conn = pymysql.connect(
host='39.98.110.249',
port=9030,
user='root',
password='sr123456',
database='knowledge_base'
)
cursor = conn.cursor()
# 将查询向量转换为 StarRocks 的数组格式
embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"
# 使用 L2 距离搜索最相似的记录
sql = """
SELECT content, l2_distance(embedding, %s) AS distance
FROM enterprise_knowledge
ORDER BY distance ASC
LIMIT 1
"""
cursor.execute(sql, (embedding_str,))
result = cursor.fetchone()
if result:
return result[0] # 返回最匹配的 content
else:
return"未找到相关信息。"
except pymysql.Error as db_err:
print(f"Database error: {db_err}")
return"查询失败。"
finally:
if'cursor'in locals():
cursor.close()
if'conn'in locals():
conn.close()
# 主流程
try:
query = "StarRocks 的愿景是什么?"
query_embedding = get_embedding(query) # 将查询转化为向量
answer = search_knowledge_base(query_embedding) # 从知识库检索答案
print(f"问题: {query}")
print(f"回答: {answer}")
except requests.RequestException as e:
print(f"Embedding API error: {e}")
except Exception as e:
print(f"Error: {e}")
执行效果

补充说明:到目前为止的流程仅依赖 StarRocks 进行向量检索,未利用 DeepSeek LLM 进行生成,导致回答生硬且缺乏上下文整合,影响自然性和准确性。为提升效果,应引入 RAG 机制,使检索结果与生成模型深度融合,从而优化回答质量并减少幻觉问题。
7、 加入 RAG 增强
7.1 将查询知识库的结果,返回给 DeepSeek LLM ,优化回答质量
# 构造 RAG Prompt
def build_rag_prompt(query, retrieved_content):
prompt = f"""
[系统指令] 你是企业智能客服,基于以下知识回答用户问题:
[知识上下文] {retrieved_content}
[用户问题] {query}
"""
return prompt
# 调用 DeepSeek 生成回答
def generate_answer(prompt):
url = "http://localhost:11434/api/generate"
payload = {"model": "deepseek-r1:7b", "prompt": prompt}
try:
response = requests.post(url, json=payload)
response.raise_for_status()
full_response = ""
for line in response.text.splitlines():
if line.strip(): # 过滤空行
try:
json_obj = json.loads(line)
if"response"in json_obj:
full_response += json_obj["response"] # 只提取答案
if json_obj.get("done", False):
break
except json.JSONDecodeError as e:
print(f"JSON 解析错误: {e}, line: {line}")
return clean_response(full_response.strip()) # 处理并去掉 <think>XXX</think>
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return"生成失败。"
7.2 创建 RAG 过程表:
用于记录用户问题、检索结果和生成回答,保存上下文,方便进行长对话,至于长对话,用户可自行探索。
customer_service_log 表建表语句如下:
CREATE TABLE customer_service_log (
id BIGINT AUTO_INCREMENT,
user_id VARCHAR(50),
question TEXT NOT NULL,
question_embedding ARRAY<FLOAT> NOT NULL,
retrieved_content TEXT,
generated_answer TEXT,
timestamp DATETIME NOT NULL,
feedback TINYINT DEFAULT NULL
) ENGINE=OLAP
PRIMARY KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
我的DeepSeek部署资料已打包好(自取↓)
https://pan.quark.cn/s/7e0fa45596e4
但如果你想知道这个工具为什么能“听懂人话”、写出代码 甚至预测市场趋势——答案就藏在大模型技术里!
❗️为什么你必须了解大模型?
1️⃣ 薪资爆炸:应届大模型工程师年薪40万起步,懂“Prompt调教”的带货主播收入翻3倍
2️⃣ 行业重构:金融、医疗、教育正在被AI重塑,不用大模型的公司3年内必淘汰
3️⃣ 零门槛上车:90%的进阶技巧不需写代码!会说话就能指挥AI
(附深度求索BOSS招聘信息)
⚠️警惕:当同事用DeepSeek 3小时干完你3天的工作时,淘汰倒计时就开始了。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?老师啊,我自学没有方向怎么办?老师,这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!当然这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 24
24 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

所有评论(0)